Drivers in Focus: Data Files and File Storage Solutions – Part 2

In the first part of our Drivers in Focus series featuring connectivity solutions for data files and file storage solutions, we provided a brief comparison of our data format connectors and our data storage connectors.
In our second article, we take a deeper dive into how CData connectivity solutions provide real-time access to files and file storage solutions. As in the previous article, we’ll focus on JSON and Parquet files, but the principles apply to any of the file formats we support.
Real-Time Access to Data Storage Applications
CData solutions for data storage applications provide a relational model of the storage application (Amazon S3, Dropbox, Google Drive, Microsoft OneDrive, etc) itself. The data model exposed by CData includes information about buckets, drives, folders, users, permissions and information about the files (but not the data in the files).
Understanding Your Data Storage Applications
With CData data storage connectors, you can analyze your usage by querying file size, determine the staleness of your repositories by querying last modified dates for files and folders, and even perform actions like creating new buckets or folders. SQL stored procedures even allow you to upload new files into your system.
Administrating Your Data Storage Applications
In addition to providing information about how files are stored, the CData connectivity solutions for data storage applications also allow you to easily get admin information about your applications. You can query to find users in your organization, view (and sometimes modify) their permissions, and even share and unshare folders – all through simple SQL queries.
Access File Data, No Matter Where It Is
When it comes to file storage and file format connectivity solutions, most of our customers are using CData solutions to find value from the data stored in their files. Our file format solutions (JSON, XML, CSV, Parquet, SAS Data Set & SAS xpt) allow you to connect to your files no matter where they're stored. Each connector provides options for authenticating with any of our 250+ supported platforms.
Relational Models of File Data
Once you have access to your files, CData connectors create a relation model of the data stored in those files. The available techniques and options vary depending on how your data is being stored. For CSV documents, this means using the first row to determine column names and then using row scanning or custom schemas to determine the types for each column. The process is richer for the more complex storage formats.
Below, we briefly dive into what it looks like to build a relational model for JSON data and for Parquet data.
Modeling JSON Data
As we discussed in the previous blog, JSON data is a common way to store nested data. The nested structure allows you to easily store related information in a single file. For example, we could have a JSON document that represents nested data for an automotive repair shop (see the image below).
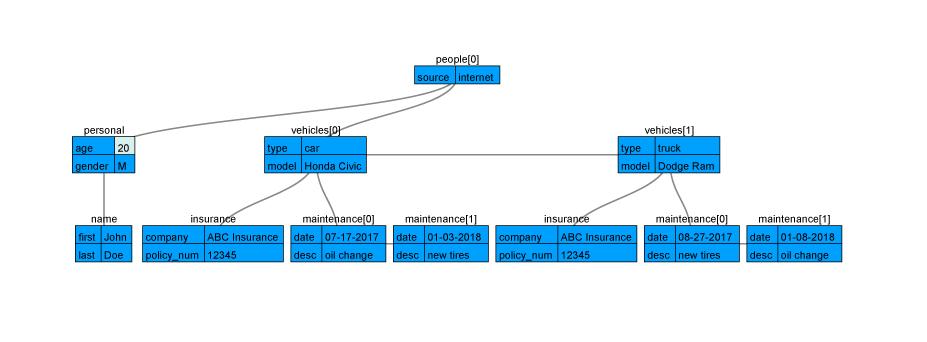
There are a variety of ways to model this data relationally but in short, CData allows you to easily drill down into the attributes for each entry in a JSON document. You can build a data model to suit your needs from a single table with all the data, or multiple related tables representing the nested objects and arrays in the JSON document.
For an even deeper dive into all the options available for building a data model from JSON documents, including specific examples based on the data pictured above, check out our Knowledge Base article.
Modeling Parquet Data
Parquet is quickly growing in popularity as a data storage format. Because the data stored is columnar and is typically compressed when written, Parquet files are generally faster to create and cheaper to store than other file formats. Like JSON, you have a lot of flexibility in the kinds of data stored, including nested objects and lists. Read more about Parquet file format in the official documentation.
When the data stored in Parquet files is simple (not structured or nested), reporting on the stored data is straightforward. Native libraries and connectors for Parquet files can read simple, columnar data quickly and process it for visualizations, dashboards, and analysis. When the data is stored in Parquet files is nested, representing either a list or an object with multiple attributes, developers and data engineers need to take extra steps to get meaning from the data. Fortunately, that's not the case with CData's Parquet connectivity solutions.
CData Parquet Modeling Options
CData allows you to easily access individual pieces of data in Parquet files, no matter how that data is stored. You have three options for drilling into nested Parquet files: Using Document modeling to view the entire file contents (which aggregates any lists as single columns), Flattened Documents (which JOINs lists to their parent object), or a Relational model (which separates your nested data into individual tables). You can follow along with the different data model options using the sample object below.
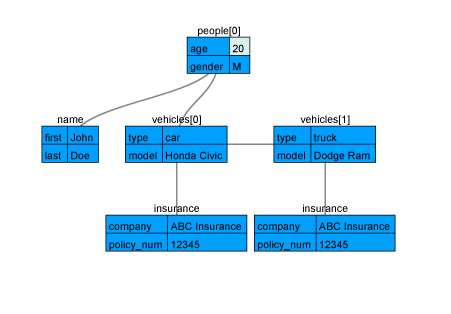
Document Data Model
If you opt for the Document model, the data shown above would result in the following single table, which includes aggregates for the "vehicles" columns.
| people |
| Column |
Type |
| age |
Integer |
| gender |
String |
| name |
String |
| vehicles |
String |
The Document model lets you use a query like the following:
SELECT
[age],
[gender],
[name],
[vehicles]
FROM
[people]
Which results in this output:
| age |
gender |
name |
vehicles |
| 20 |
M |
{
first: “John”,
last: “Doe”
} |
[
{
"type": "car",
"model": "Honda Civic",
"insurance": {
"company": "ABC Insurance",
"policy_num": "12345"
}
},
{
"type": "truck",
"model": "Dodge Ram",
"insurance": {
"company": "ABC Insurance",
"policy_num": "12345"
}
}
] |
*Note that the “name” and “vehicles” columns are String aggregates of the objects.
FlattenedDocuments Data Model
If you opt for FlattenedDocuments, the data from the sample above would still be represented by a single table, but the nested data is drilled into and the data points are JOINed to each row.
| people |
| Column |
Type |
| age |
Integer |
| gender |
String |
| name.first |
String |
| name.last |
String |
| type |
String |
| modal |
String |
| insurance.company |
String |
| insurance.policy_num |
String |
The FlattenedDocuments model lets you use a query like the following:
SELECT
[age],
[gender],
[name.first],
[name.last],
[type],
[model],
[insurance.company],
[insurance.policy_num]
FROM
[people]
Which results in this output:
| age |
gender |
name.first |
name.last |
type |
model |
insurance.company |
insurance.policy_num |
| 20 |
M |
John |
Doe |
car |
Honda Civic |
ABC Insurance |
12345 |
| 20 |
M |
John |
Doe |
truck |
Dodge Ram |
ABC Insurance |
12345 |
Relational Data Model
If you opt for the Relational data model, your Parquet file is represented as two tables, one for each nested list in the file.
| people |
| Column |
Type |
| _id |
String |
| age |
Integer |
| gender |
String |
| name |
String |
| vehicles |
| Column |
Type |
| _id |
String |
| people_id |
String |
| type |
String |
| model |
String |
| insurance.company |
String |
| insurance.policy_num |
String |
The Relational model lets you use a JOIN query like the following:
SELECT
[people.age],
[people.[gender],
[people].[name.first],
[people].[name.last],
[vehicles].[type],
[vehicles].[model],
[vehicles].[insurance.company],
[vehicles].[insurance.policy_num]
FROM
[people]
JOIN
[vehicles]
ON
[people._id] = [vehicles.people_id]
Which results in this output (the same as the FlattenDocuments model):
| age |
gender |
name.first |
name.last |
type |
model |
insurance.company |
insurance.policy_num |
| 20 |
M |
John |
Doe |
car |
Honda Civic |
ABC Insurance |
12345 |
| 20 |
M |
John |
Doe |
truck |
Dodge Ram |
ABC Insurance |
12345 |
Once you decide on a data model, you can easily work with your Parquet file data in your preferred data tools and applications.
The CData Difference
With self-service solutions and real-time connectivity for data storage applications and popular file formats, CData empowers organizations to get deep, actionable insights into their systems and their data files. Learn more about our connectivity solutions and download a free trial to see the results for yourself.
Get in touch with the CData team to get a personalized demo!



