Data Modeling Examples and Types You Need to Know

Data modeling is the process of conceptualizing and visualizing how data is captured, stored, and used by an organization. There are many distinct types of data modeling, each serving a different purpose in the process of database development.
What is data modeling?
In data modeling, you typically define entities (such as objects, people, or concepts), their attributes (characteristics or properties), and the relationships between these entities. This is often done using diagrams like entity-relationship diagrams (ER diagrams) or Unified Modeling Language (UML) diagrams.
Data modeling has huge advantages. It helps ensure that data is organized efficiently, accurately reflects the real-world entities it represents, and meets the requirements of the systems that use it.
3 Levels of data modeling
There are three basic stages of data modeling: conceptual, logical, and physical.
- Conceptual data models: Often the first stage of data modeling, a conceptual data model represents high-level concepts and relationships between them in a simplified manner. It is concerned with the scope of a new database, and its goal is to improve communication between stakeholders and to establish a common understanding of the domain.
- Logical data models: A logical data model provides a more detailed representation of the data than a conceptual model. It focuses on entities, attributes, relationships, and constraints. It describes the structure of the data at a conceptual level without the technical details of database construction. Logical data models are often used as a blueprint for designing the database schema.
- Physical data models: Unlike a logical data model, a physical data model is closely tied to the technical aspects of database design. It includes details such as data types, indexes, storage structures, and optimization considerations. At this stage, you’re ready for the actual implementation of a database.
Types of data models
There are many types of data models, including but not limited to conceptual, logical, and physical. Various data models serve different but essential purposes in the data management process.
Relational data model
Used solely for relational databases, the relational data model defines data in terms of tables, rows, and columns. It's the foundation of relational database management systems like MySQL, PostgreSQL, and Oracle. In a relational data model, entities are represented as tables, attributes as columns, and relationships as foreign keys.
Entity-Relationship (ER) data model
A conceptual and visual representation used to describe the data and relationships within a system or organization, ER models are particularly useful in database design. In an ER model, entities represent real-world objects or concepts (e.g., a person, a product, a company) and are depicted as rectangles. Relationships between entities are shown with lines connecting them to indicate how entities are related to each other.
Attributes are also a key component of an ER model. They describe properties or characteristics of entities and are typically listed within the entity rectangles.
ER models help stakeholders, including database designers, developers, and business analysts, to communicate effectively about data requirements and system structure before implementing it. They provide a high-level overview of the database schema, facilitating the design process and ensuring that the resulting database meets the organization's needs.
Dimensional data model
Used primarily in data warehousing and business intelligence applications, dimensional data modeling focuses on organizing data into fact tables (containing numerical measures) and dimension tables (containing descriptive attributes). Dimensional models are optimized for querying and analysis, typically using online analytical processing techniques.
Hierarchical data model
Often used in early database management systems, a hierarchical data model organizes data into a tree-like structure. In this model, data is represented as a tree structure with records connected through parent-child relationships. Each node (record) has one parent and can have multiple children, but children can only have one parent. The top node of this hierarchy is called the root, and it does not have a parent.
Hierarchical data models use single-path navigation. To access a particular record, you start from the root and traverse through the tree following a single path.
The relationships between records are predefined, meaning the structure is fixed and cannot be changed without significant redesign. This rigidity impairs scalability and adaptation.
Object-oriented data model
Used in an object-oriented setting, this data model represents data is represented as objects with properties (attributes) and methods. Typical programming languages used are Java and C++, and object-oriented database management systems (OODBMS).
Network data model
A Network data model is a graph structure, specifically a network of interconnected records or nodes. In a network data model, data is organized as collections of records (nodes) and the relationships between them. These relationships can be of different types and can link records in a non-hierarchical manner. The key components of a network data model are nodes (records), edges (relationships), schema, and traversal (navigation).
Network data gives you great flexibility in representing complex relationships between entities and efficient traversal for certain types of queries. However, they also have limitations, including model complexity and the need for specialized query languages.
NoSQL data models
NoSQL databases use various data models that are different from the relational model. Examples include document-oriented (e.g., MongoDB), key-value (e.g., Redis), column-family (e.g., Cassandra), and graph (e.g., Neo4j) data models. These models are optimized for specific use cases and may offer advantages in terms of scalability, flexibility, and performance.
5 Examples of data modeling
Relational data model
A basic example of a relational data model is the "Employee" database. This is its basic structure:
Tables
- Employees: Contains information about each employee.
- Columns: EmployeeID (Primary Key), FirstName, LastName, BirthDate, HireDate, DepartmentID (Foreign Key), etc.
Departments
Contains information about different departments.
Columns
- DepartmentID (Primary Key)
- DepartmentName
- ManagerID (Foreign Key)
- Location
Relationships
How employees’ data relates to DepartmentID:
- Each employee belongs to exactly one department. This is represented by the "DepartmentID" column in the Employees table, which is a foreign key referencing the DepartmentID in the Departments table.
- Each department can have multiple employees. This is depicted by the relationship between the DepartmentID in the Departments table and the corresponding employees in the Employees table.
This relational data model structures storage of data where information about employees and departments is organized into tables, with relationships defined between them using primary and foreign keys. It's a fundamental concept in database design and management, providing a flexible and efficient way to manage and query data.
Entity-Relationship (ER) data model
Let's consider a simplified example of an entity-relationship data model for a library management system. In this system, we'll have entities such as Book, Author, and Member, along with relationships between them.
Entities
- Book: This entity represents individual books in the library. It might have attributes like BookID, Title, ISBN, and PublicationYear.
- Author: Represents authors of the books. Attributes could include AuthorID, Name, and Nationality.
- Member: Represents library members who borrow books. Attributes might include MemberID, Name, and Address.
Relationships
- Authored By: This relationship connects Book and Author entities, indicating which authors wrote which books. It is a many-to-many relationship because one book can have multiple authors, and one author can write multiple books.
- Borrowed By: Connects Member and Book entities, indicating which members borrowed which books and when. This is a one-to-many relationship because one member can borrow multiple books, but each book can be borrowed by only one member at a time.
ER models are visually oriented. The easiest way to understand them is to look at a diagram showing entities and the relationships between them. Here's how our entity-relationship model might look in an ER diagram:
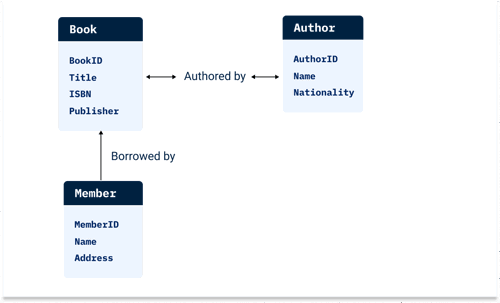
In this diagram:
- Headers (names above lists) are entities.
- The lists under each entity are attributes.
- Lines indicate relationships between entities. An arrow means multiple; no arrow means singular.
This model provides a clear visualization of the structure of the library management system, showing how books, authors, and members are related to each other. The model is particularly suited to designing the database schema and implementing the system.
Hierarchical model
A hierarchical data model is a tree-like structure with parent-child relationships. Each parent can have multiple children, but each child has only one parent, which is the defining feature of the model. One common example of a hierarchical data model is a file system. Let's consider a simple example of a hierarchical data model representing a file system:
Root
- Blogs
- Work
- Personal
- Restaurant reviews
- Italian.docx
- Thai.docx
In this hierarchical data model:
- The root node represents the top-level directory of the file system.
- Each directory (e.g., Work) is a parent node.
- Each file (e.g., Thai.docx) is a leaf node or child node.
- Each directory can contain multiple files and subdirectories.
Subdirectories can contain files and additional subdirectories.
This hierarchical structure reflects the organization of a typical file system, where directories contain files and other directories, creating a nested hierarchy.
Network data model
Network data models represent data in a graph structure, specifically a network of interconnected records or nodes. In a network data model, data is organized as collections of records (nodes) and the relationships between them. These relationships can be of different types and can link records in a non-hierarchical manner.
The key components of a network data model are:
- Nodes (records): Fundamental units of data in the model. Each node typically represents an entity (such as a person, place, or thing) with attributes that describe it.
- Edges (relationships): Represent the connections or relationships between nodes. Unlike hierarchical models, where relationships are typically parent-child, in a network model, relationships can be many-to-many. Each edge has a type and can have attributes associated with it.
- Schema: Defines the structure of the data by specifying the types of nodes, the types of relationships, and the attributes associated with each node and relationship type.
- Traversal: Traversal refers to the process of navigating through the network from one node to another along the edges. This traversal allows for efficient querying and retrieval of data.
Network data models have certain advantages, such as flexibility in representing complex relationships between entities and efficient traversal for certain types of queries. However, they also have limitations, including complexity in modeling certain types of data and the need for specialized query languages.
Dimensional data modeling
Examples of dimensional data modeling often arise from data warehousing requirements, where the focus is on facilitating efficient querying and analysis of large volumes of data. A simple example is the "Sales" data model, commonly used in retail businesses.
Example of a Fact table
A Sales table is very common example of a Fact table. This example contains:
- SalesID (Primary Key)
- DateKey (Foreign Key)
- ProductKey (Foreign Key)
- CustomerKey (Foreign Key)
- QuantitySold,
- TotalSales
Each row in the Fact table contains data about a specific sales transaction. You can see how this table can be easily extended to include more refined breakdowns of sales, revenue, etc.
Dimension Tables
Although there’s only one Fact table, given that this is a “dimension” model, there is more than one dimension (or else it’s not much of a model!):
- Date Dimension: Contains details about dates such as DateKey (Primary Key), Date, DayOfWeek, Month, Quarter, Year, or whatever durations you need. You can use this dimension to analyze sales trends over time.
- Product Dimension: Contains data about products, including a ProductKey (Primary Key), ProductName, Category, Brand, or any other pertinent data about your products. This dimension captures attributes of your products.
- Customer Dimension: Stores data about customers, including CustomerKey (Primary Key), CustomerName, Address, Phone, etc. This dimension gives you the ability to analyze sales by customer demographics.
Relationships
The Fact table (Sales) connects to each Dimension table (Date, Product, Customer) through foreign key relationships (DateKey, ProductKey, CustomerKey).
These relationships give you tools for querying the Fact table for sales data and easily retrieving related details from your Dimension tables, including things like the date of sale, the product sold, and customer information. Dimensional data modeling organizes data sets into easily understandable dimensions and facts, giving you tools for efficient querying and reporting.
Comprehensive data modeling with CData Connect Cloud
CData Connect Cloud is a comprehensive service platform that simplifies data connectivity and integration across multiple sources. When it comes to data modeling with CData Connect Cloud, among many other features, you can expect:
- Unified data connectivity: Use a single interface to connect to a wide range of data sources including databases, cloud applications, files, and APIs. That way, you end up with a single, centralized location for modeling and analysis.
- Schema discovery and mapping: Discover schemas from connected data sources. Connect Cloud has simple, easy-to-use tools to map these schemas to a unified model.
- Modeling flexibility: Model data according to your specific requirements. Whether you need to create star schemas, snowflake schemas, or custom data models, the platform provides tools and features to support diverse modeling needs.
- Scalability and performance: CData Connect Cloud manages large volumes of data and supports high-performance data modeling processes. The Connect Cloud platform scales to whatever data requirement you have.
CData Connect Cloud offers a comprehensive solution for data modeling, giving your organization the tools to derive insights from diverse data sources. Using its features for connectivity and modeling, you can make better, more informed decisions based on a unified view of your data ecosystem.
Try Connect Cloud today
Get a free 30-day free trial of CData Connect Cloud to experience the power of a cloud-hosted data connectivity platform.



