各製品の資料を入手。
詳細はこちら →CData


こんにちは!プロダクトスペシャリストの宮本です。
本記事では、CX プラットフォームのKARTE でIBM Cloud Data Engine にある顧客データを活用する方法として、KARTE Datahub が外部参照するBigQuery にIBM Cloud Data Engine のデータを定期的にレプリケーションする方法をご紹介します。
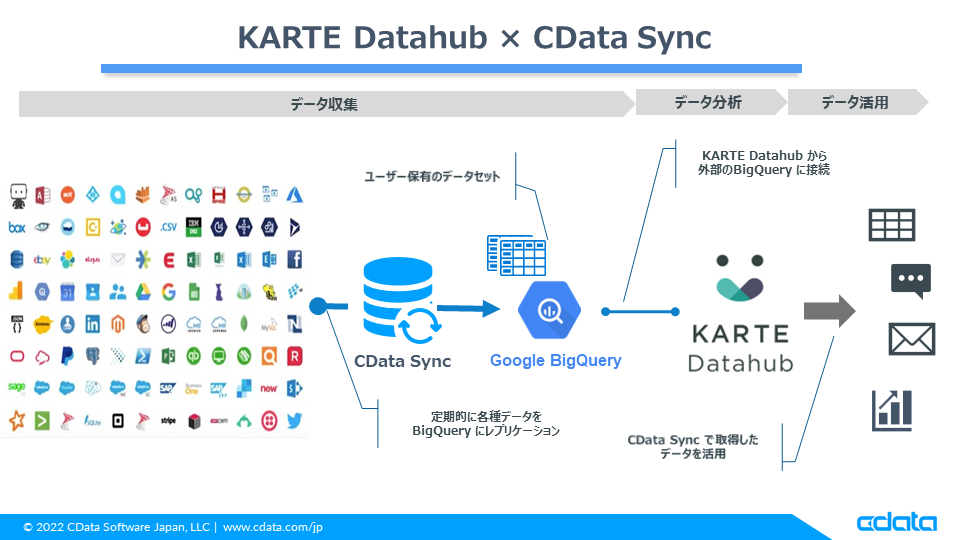
本記事では、ETL ツールのCData Sync を使ってIBM Cloud Data Engine に格納されている顧客データをユーザー所有のBigQuery にレプリケーションし、最終的にはKARTE Datahub からそのデータセットにアクセスしてIBM Cloud Data Engine のデータを利用できるようにする、というところまでをご紹介します。
CData Sync 自体はセルフホスティング型のツールなので、ローカルマシンやクラウド上のVM インスタンス上でもご利用いただけますが、本記事ではGoogle Compute Engine の CentOS 上にインストールします。
KARTE はWeb サイトやアプリにアクセスしてきた顧客をリアルタイムに解析して、一人ひとりに最適な情報を提供するWeb 接客が可能なCX プラットフォームです。
そしてこのKARTE と連携可能なプロダクトとして、KARTE Datahub があります。
データ蓄積と活用の分断を解消する | KARTE Datahub
機能としては、社内外に存在する多種・⼤量のデータ(顧客情報・商品情報・店舗情報 等)をKARTE に統合し、より⾼度なセグメンテーションやアクションの実⾏に加えて、ビジネス上の迅速な意思決定を⽀援する「データ統合・利活⽤プラットフォーム」です。
KARTE Datahub はGoogle Cloud Platform(GCP)を技術基盤として採用しており、Google BigQuery を中心にデータを集約していますが、参照先はKARTE で保持しているデータセットだけでなく、KARTE ユーザーが保持している外部のデータセットも利用可能になっています。今回は、外部のIBM Cloud Data Engine のデータをCData Sync 経由でBigQuery に同期して、そのデータをKARTE Datahub に連携します。
CData Sync はセルフホスティング or AWS からご利用いただけるETL ツールになります。
同期ジョブを実行するまでのステップが少なく、エンジニアでなくても容易にSaaS データを同期先DB にレプリケートすることができます。
それではさっそく、CData Sync のホスティングから実行しましょう。
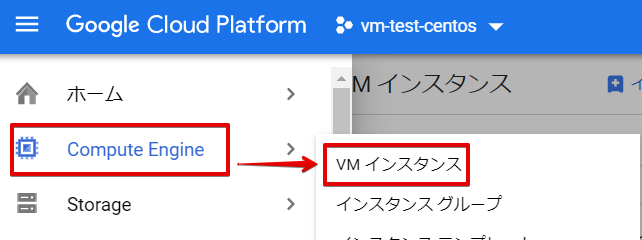
サイドメニューから「Compute Engine」→「VMインスタンス」をクリックします。
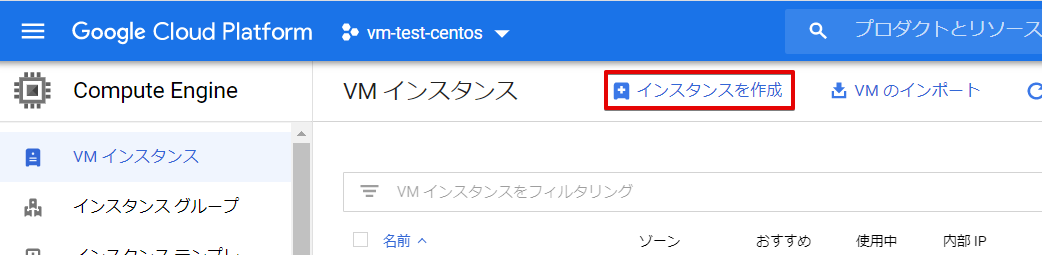
「インスタンスを作成」をクリックします。
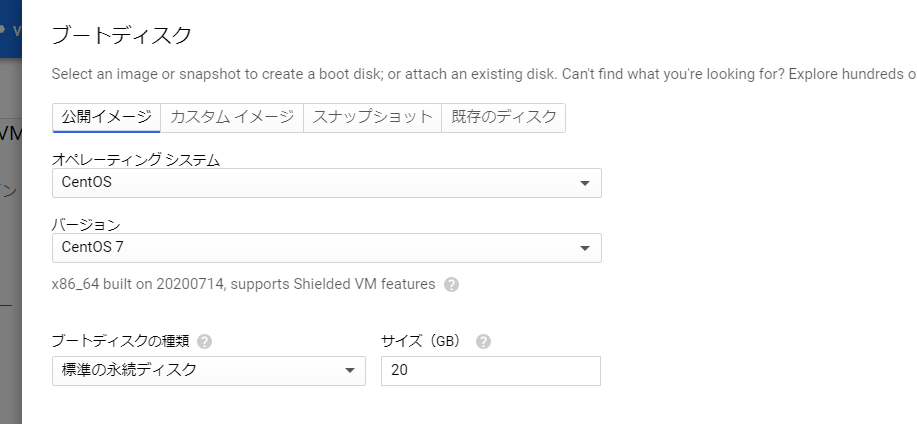
今回はCentOS で使用します。
HTTP、HTTPS にチェックをつけます。
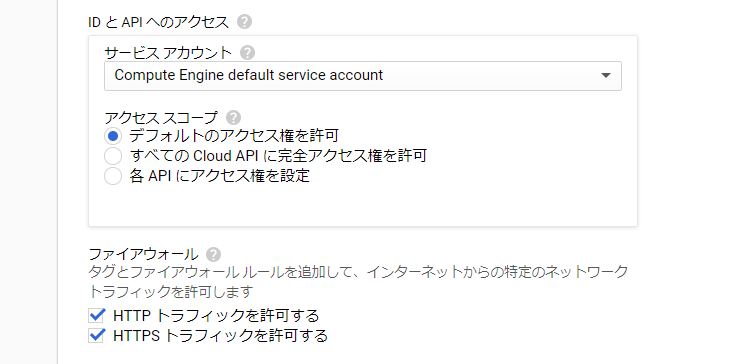
ここでは外部用のIP アドレスを設定します。
HTTP だけの利用であればデフォルト設定だけで良いのですが、HTTPS での接続の場合、インスタンスの起動停止ごとにIP
アドレスが毎回変わってしまうと接続できなくなってしまうため、ここで静的IP アドレスを取得し、「完了」ボタンをクリックします。
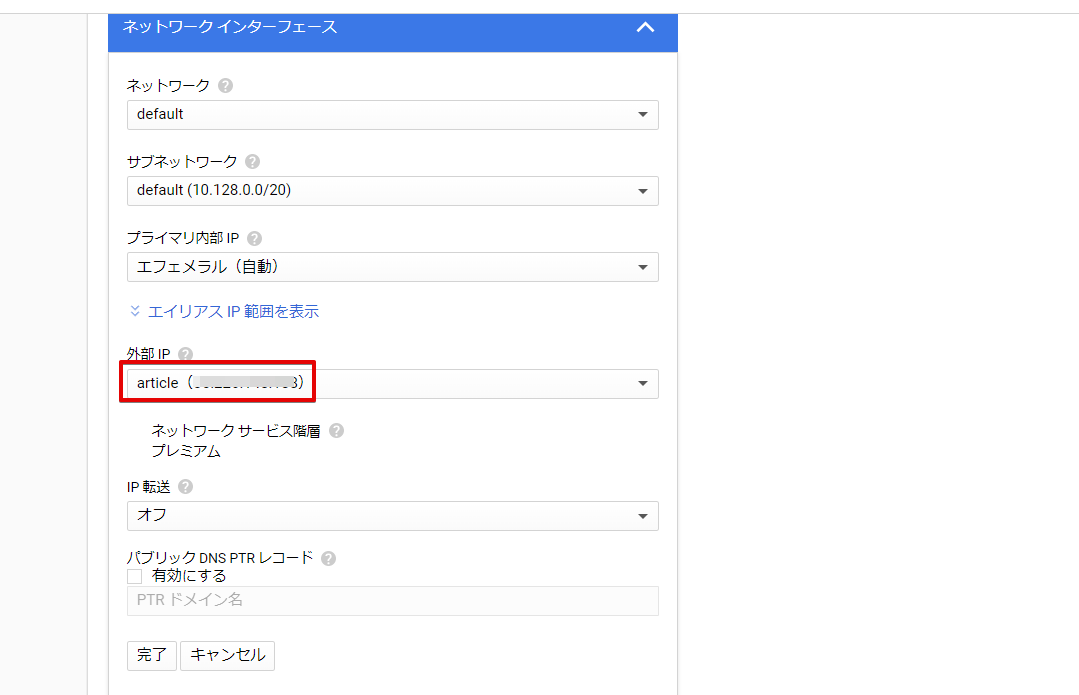
ひと通り設定したら、画面下部にある「保存」ボタンをクリックして、インスタンスを作成します。
次にCData Sync のポートを開放します。
HTTP での接続には8181、HTTPS での接続には8443 を使用するようデフォルトでは設定されているので、今回はそのまま流用していきます。
ではさっそくポートを開放しましょう。
GCP のメニューから「VPCネットワーク」 → 「ファイアウォール」の順にクリックします。
「ファイアウォール ルールを作成」をクリックします。
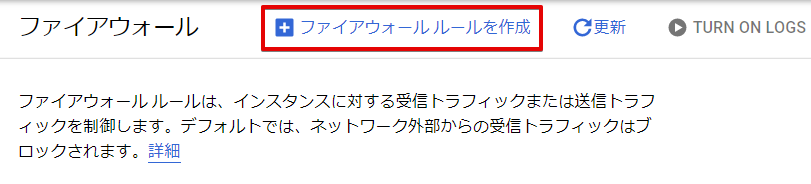
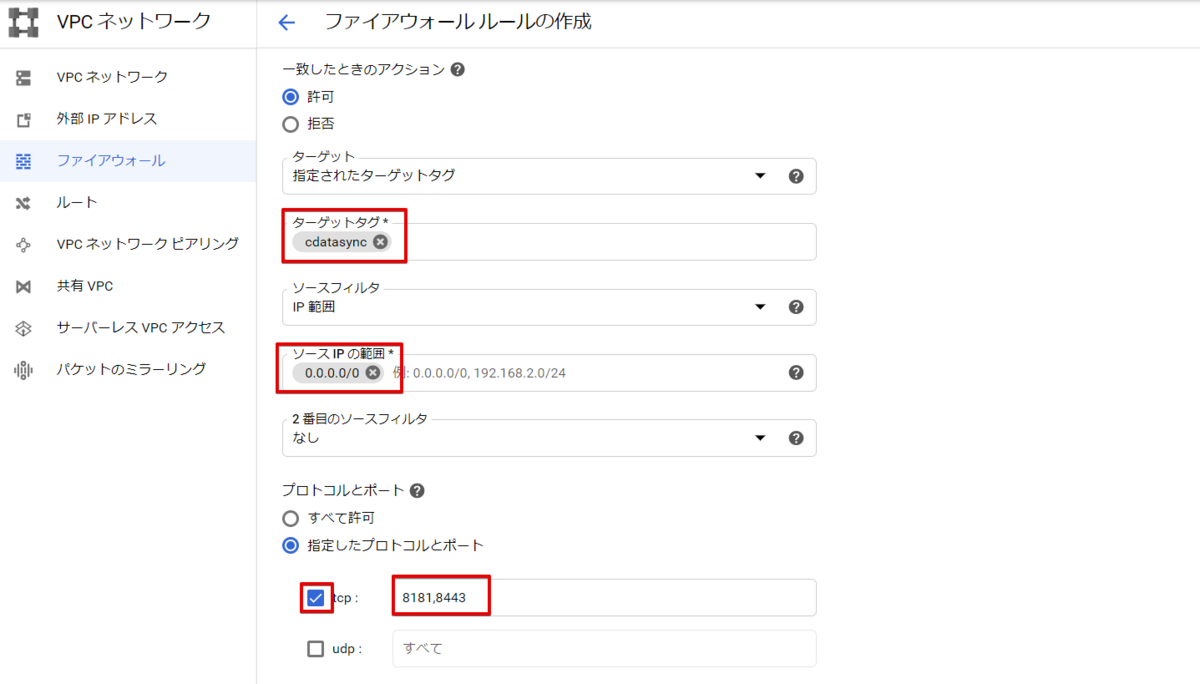
ファイアウォールの名前とターゲットタグを任意の名前で設定し、送信元のIP アドレスは今回は全て対象にするために「0.0.0.0/0」を設定しています。次に、「指定したプロトコルとポート」以下の「TCP」を選択し、 「8181,8443」を指定して、「作成」ボタンをクリックします。
今度は先ほど作成したGCE のインスタンスを編集します。ネットワークタグにファイアウォールで作成したタグ(今回は「cdatasync」というタグを作成)を設定します。
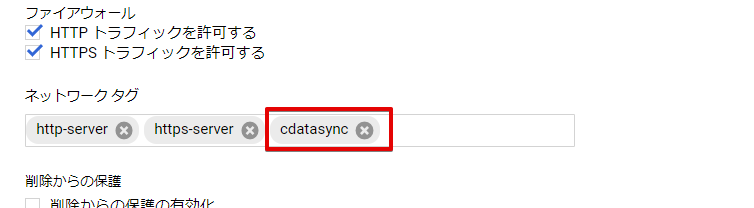
これで、CData Sync が使用するポートの開放設定が完了しました。
それでは、CData Sync をインストールしてIBM Cloud Data Engine から BigQuery にデータをレプリケートしましょう。
最初にCData Sync をダウンロードします。こちらからダウンロードページにアクセスできます。
自動データレプリケーション | CData Software Japan
右上に「無償トライアルへ」ボタンがありますのでクリックします。
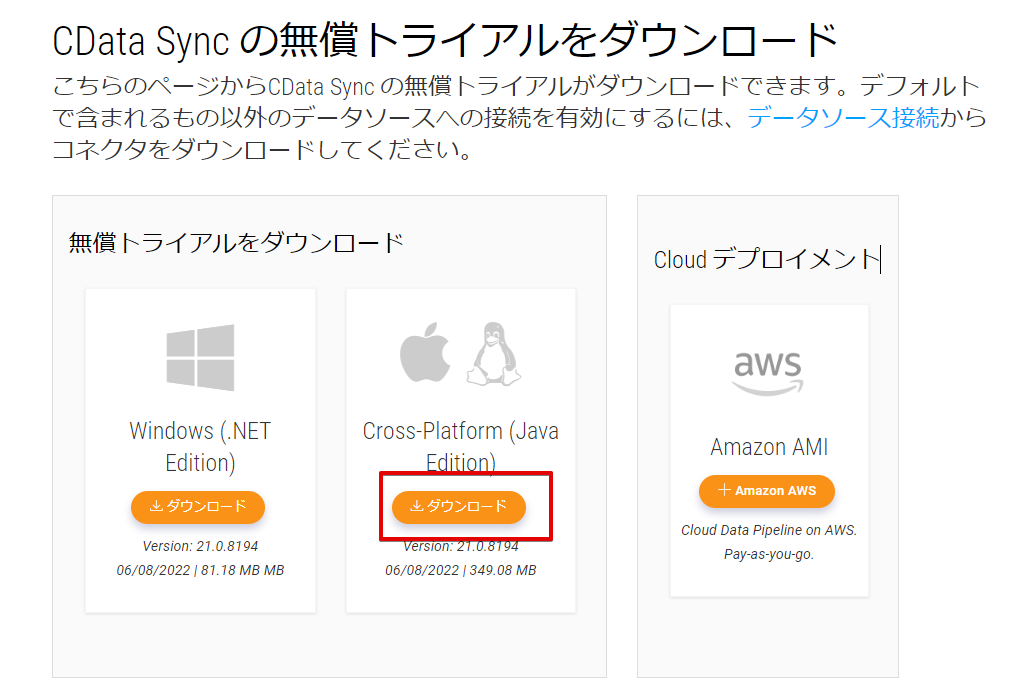
ちなみにCData Sync は「.NET版」、「Java版」があるので、Windows OS 以外の環境でも利用可能です。
また「Amazon AMI版」もあるので最初から CData Sync
がセットアップされた状態の環境を利用することもできます。
今回はJava 版を利用して、CentOS マシンにインストールしていきます。
インストールは以下のコマンドで「setup.jar」を実行すると開始されます。基本的にはそのまま次へで進めてしまってOKです。
sudo java -jar setup.jar
これでインストールが完了です。
では、CData Sync を起動してみましょう。
インストールディレクトリ(デフォルトでは/opt/sync/)に移動し、「sync.jar」を実行します。
sudo java -jar sync.jar
「INFO: Server started successfully」というメッセージが表示されたらOKです。
それではCData Sync にアクセスします。GCE のIP アドレスと8181 ポートでアクセスします。
正常にアクセスできれば、以下のようにログイン画面が表示されますのでユーザーを作成してログインします。
IBM Cloud Data Engine への接続設定
最初にIBM Cloud Data Engine の接続設定を行います。以下の赤枠順に進みIBM Cloud Data Engine アイコンをクリックします。
※もしアイコンがない場合は青枠の「Add More」からダウンロードしてください

IBM Cloud Data Engine へ接続するための情報を入力します。
詳しくはこちらをご参照ください。
IBM Cloud Data Engine Connector for CData Sync -
接続の確立
入力が完了しましたら接続テストを行います。
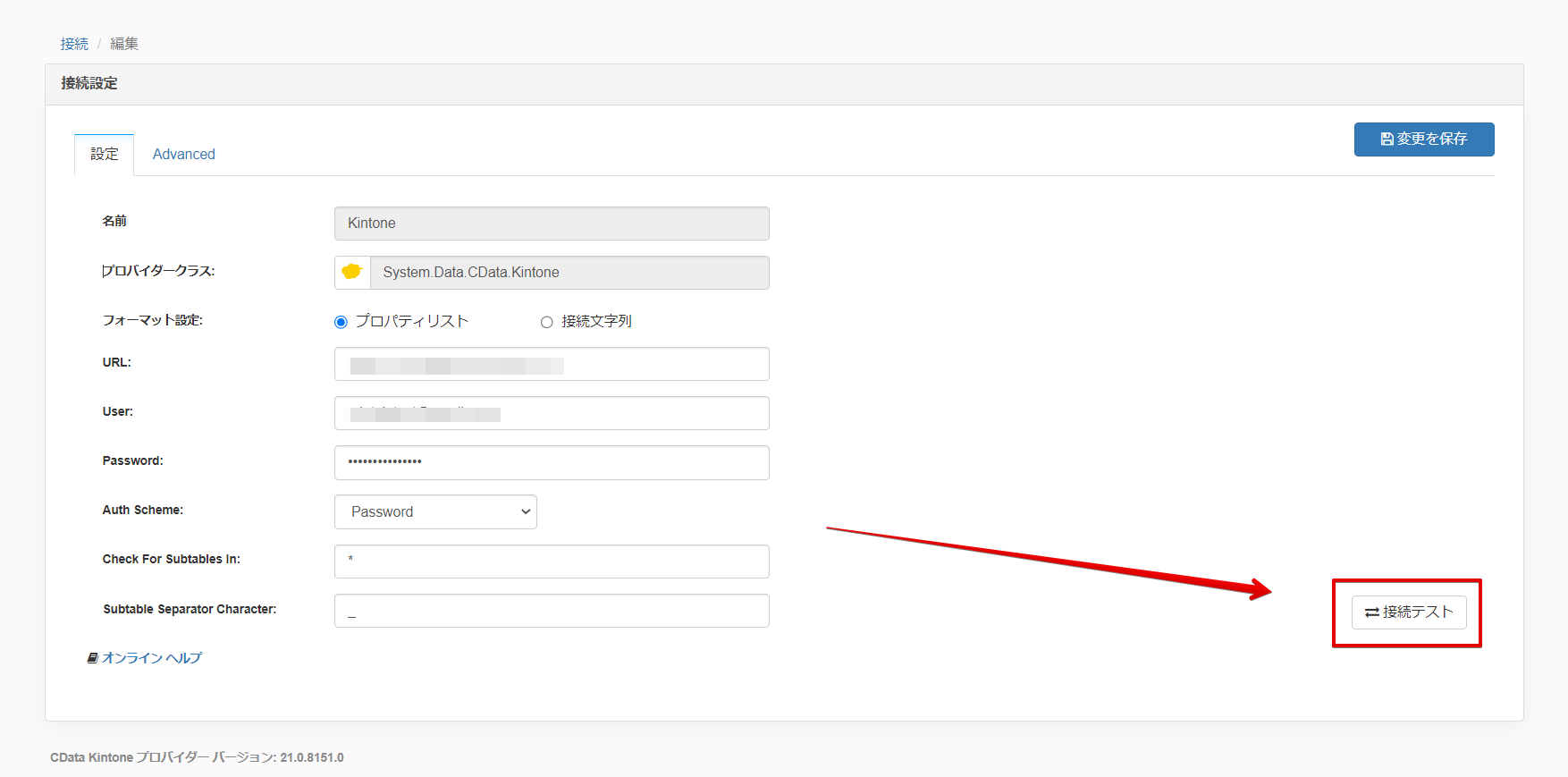
接続に成功したら「変更を保存」で保存します。
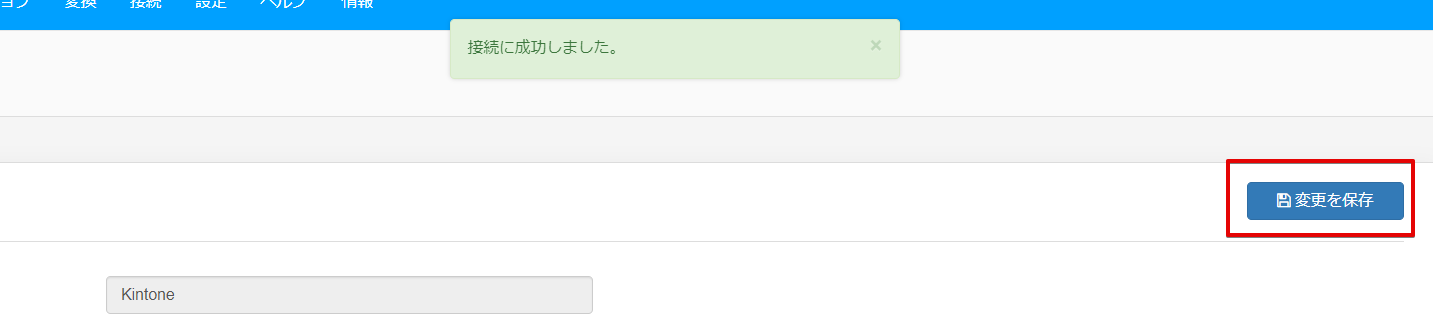
これで IBM Cloud Data Engine への接続設定が完了したので、次はBigQuery への接続設定を行います。
BigQuery への接続設定
先ほどと同手順ですが同期先タブを選択してBigQuery アイコンをクリックします。

BigQuery への接続はユーザーアカウントかサービスアカウントのどちらかを利用します。
Google BigQuery Connector for
CData Sync - 接続の確立
ユーザーアカウントの場合、プロジェクトIDとデータセットIDだけを入力して接続テストをクリックするだけでブラウザ認証画面がたちがあり、そのまま認証プロセスに入ります。
サービスアカウントの場合は、下記項目をそれぞれ埋めていきます。
なお、KARTE Datahub から自身のBigQuery にアクセスするにはサービスアカウントが必要になりますので、CData Sync 上の接続設定でも上記項目を埋めてサービスアカウントで行っていきます。
接続テストが完了したら保存します。
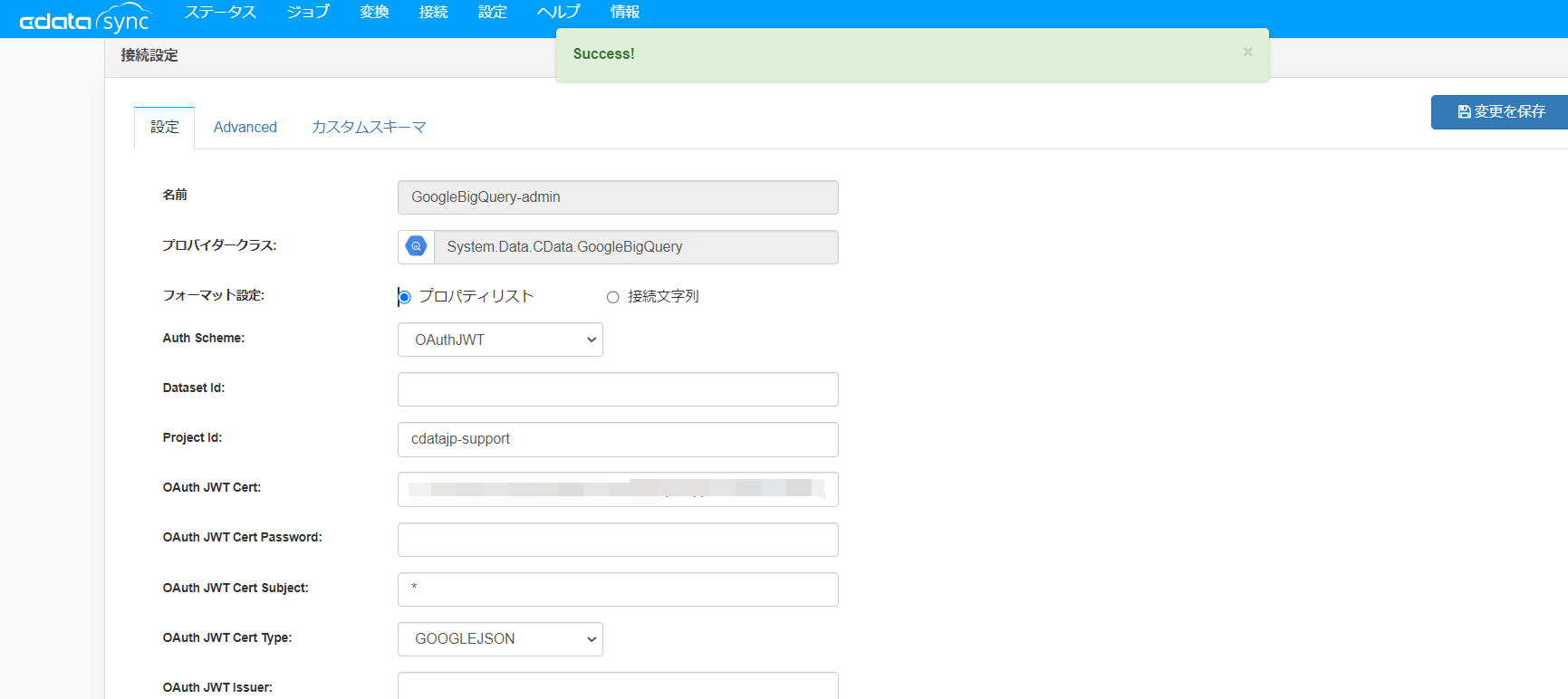
これでBigQuery のコネクション設定が完了です。
ヘッダーにあるジョブボタンからジョブ一覧画面を表示させ、「ジョブを作成」でジョブ名、ソース、同期先を入力・選択しましたら「作成」ボタンをクリックします。
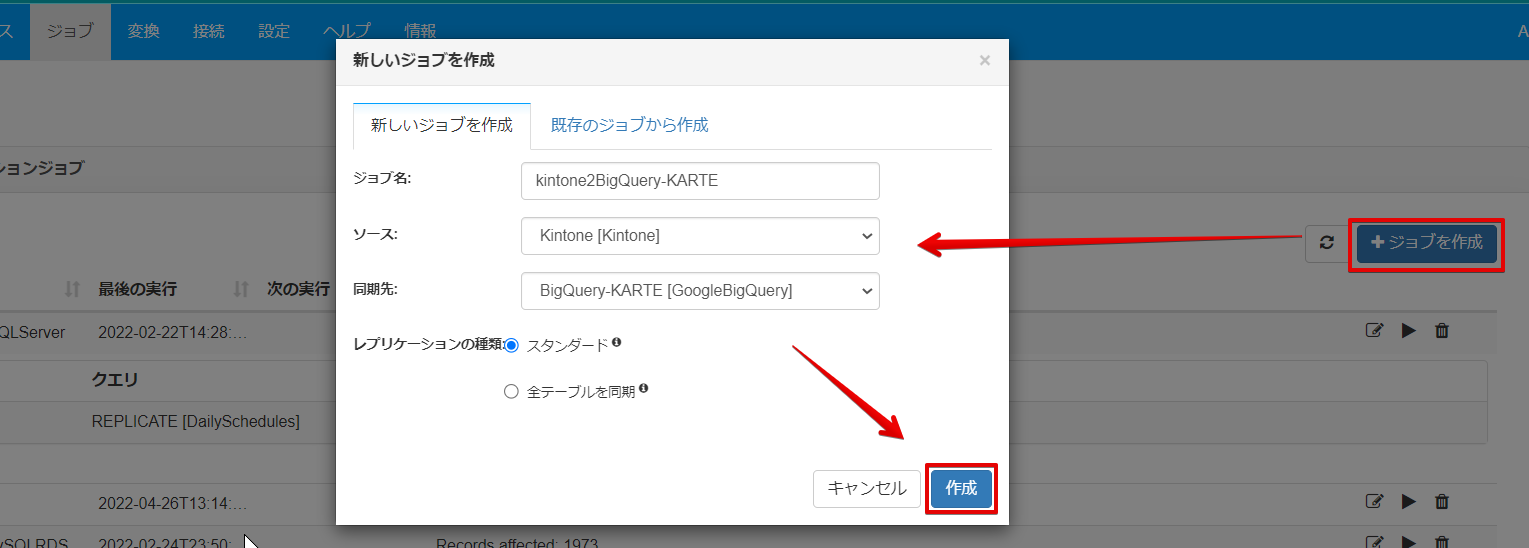
「テーブルを追加」をクリックして「顧客管理(営業支援パック)」にチェックを入れて追加ボタンをクリックします。
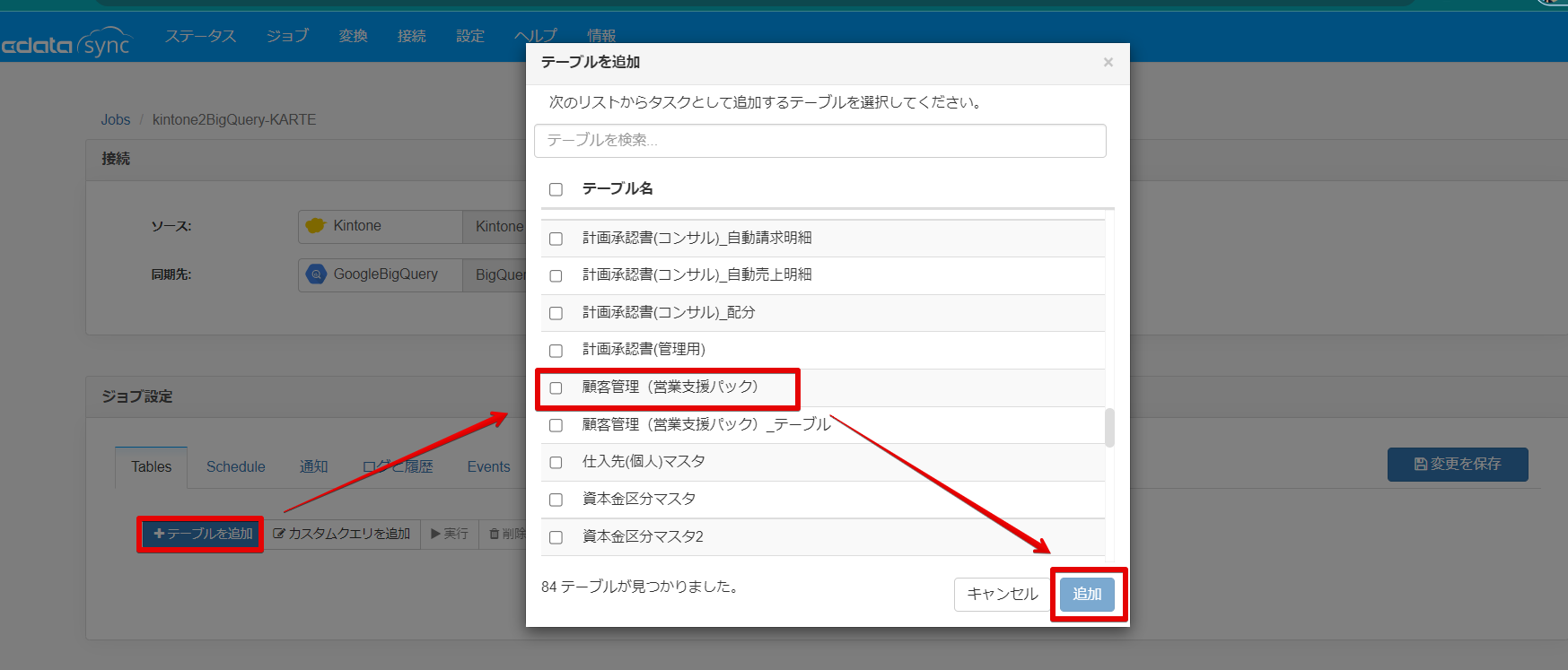
追加ボタンをクリックしますと以下のような連携用クエリが作成されます。
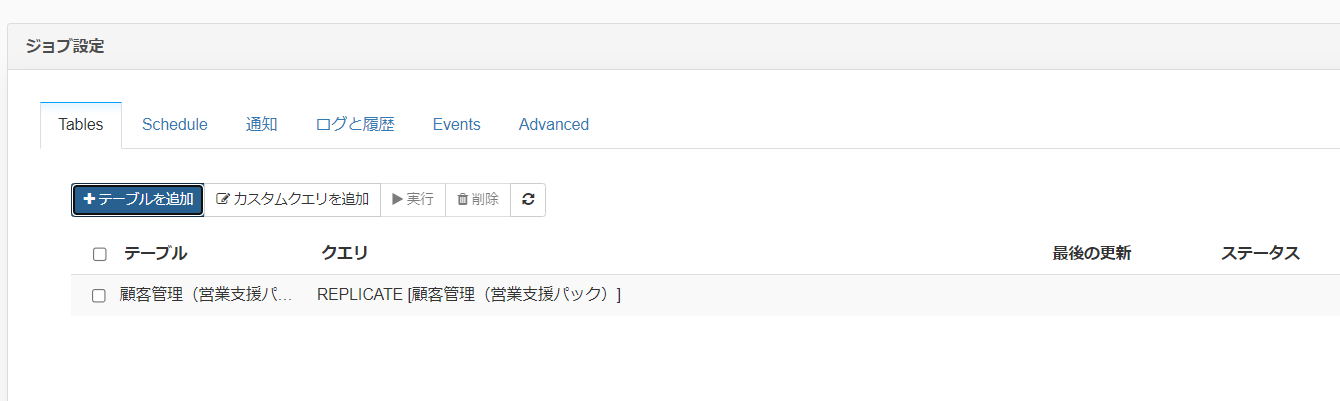
こちらの見方は、顧客管理(営業支援パック)というテーブル名でBigQuery にテーブルを作成してレプリケーションするという意味になってます。
とは言え、BigQuery
では日本語で項目名を作成することが現状では出来ないので、カラムマッピング機能でカラム名を変更していきます。
カラムマッピングタブをクリックしてカラム名を直接クリックし変更します。
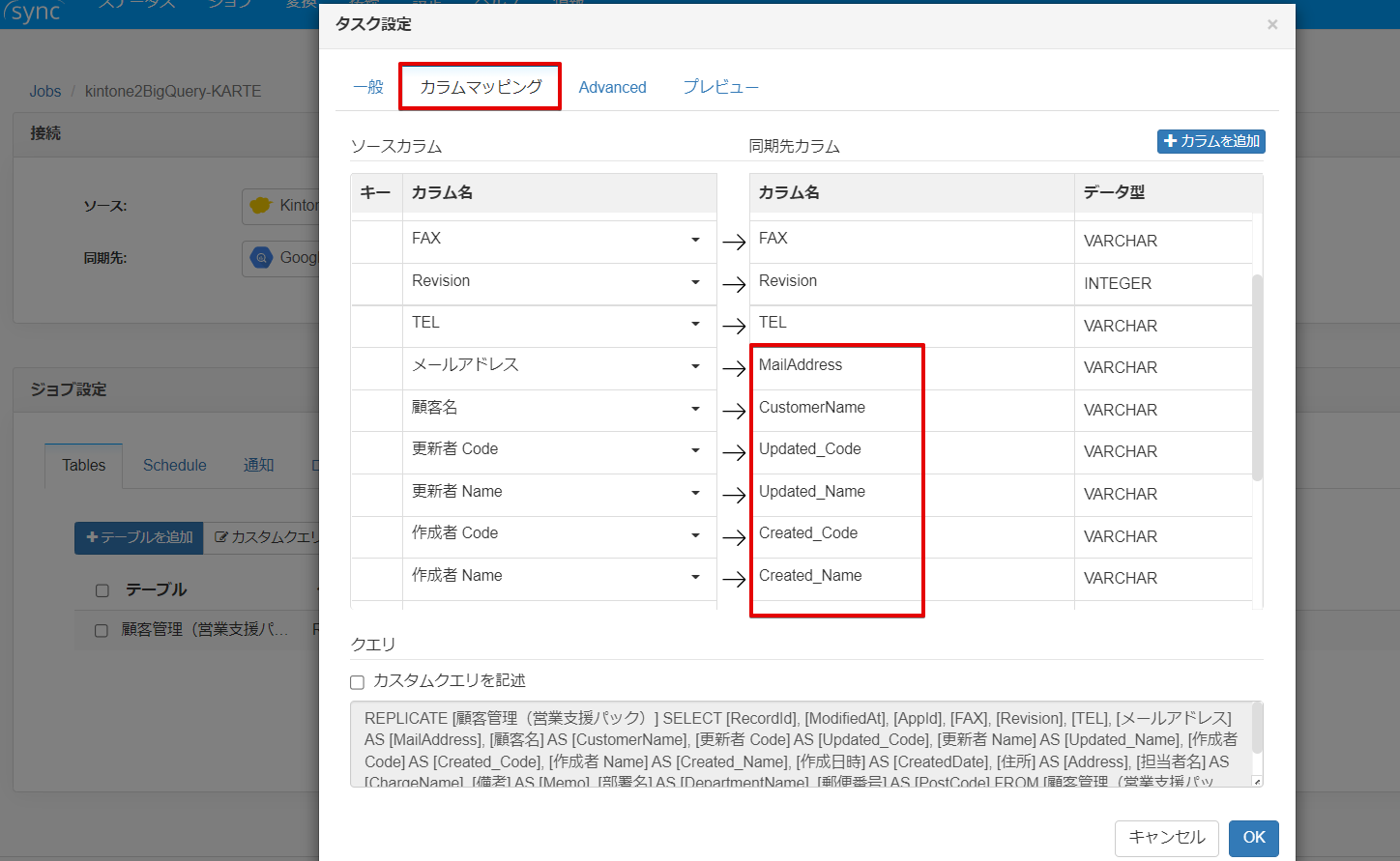
最後にテーブル名を変更します。既存の状態ですと"()" が含まれているため、この状態でレプリケーションするとBigQuery
側でエラーが発生します。
そのため「カスタムクエリを記述」にチェックを入れ、()の部分を別な文字に置き換えましょう。
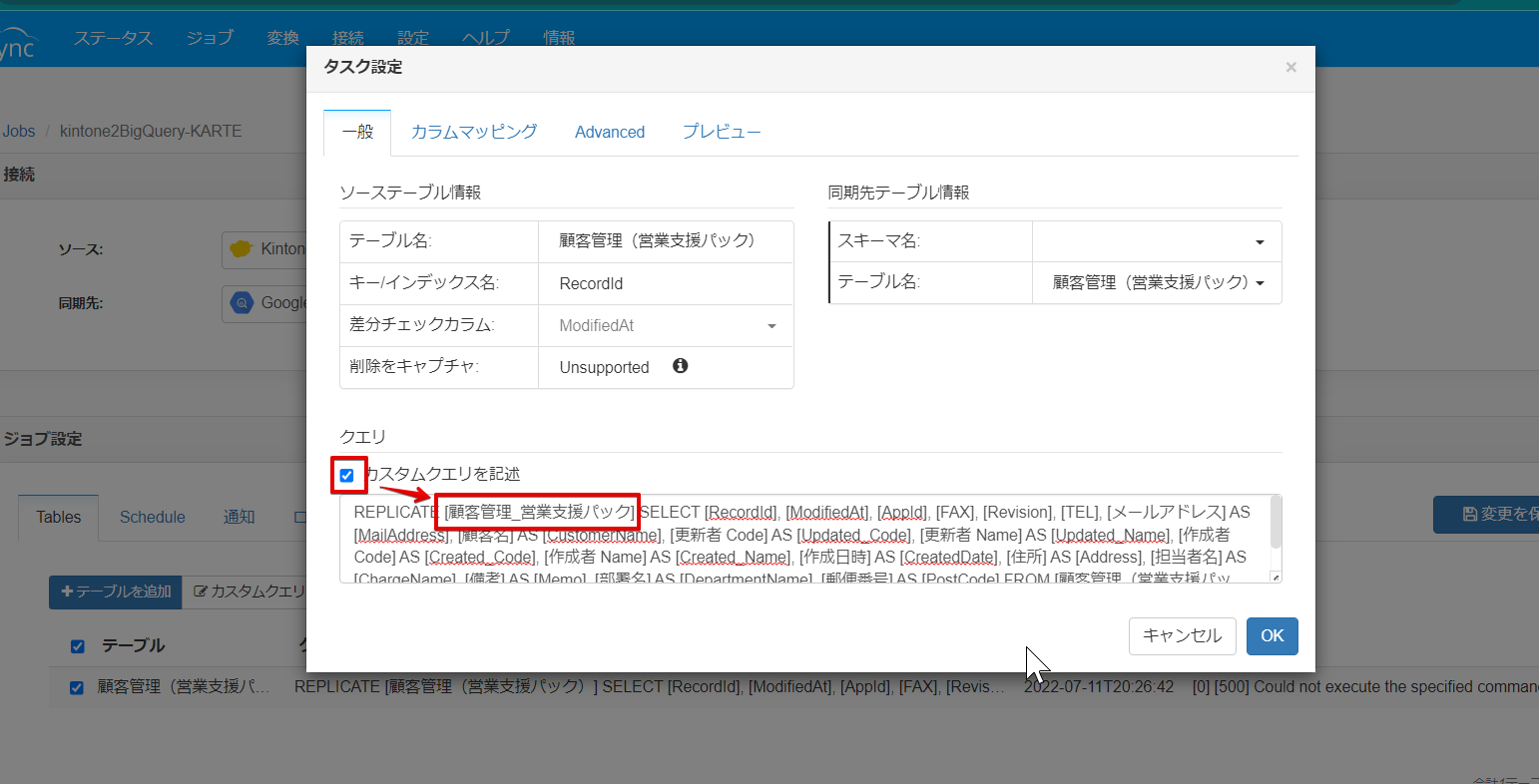
これでレプリケートクエリができました。
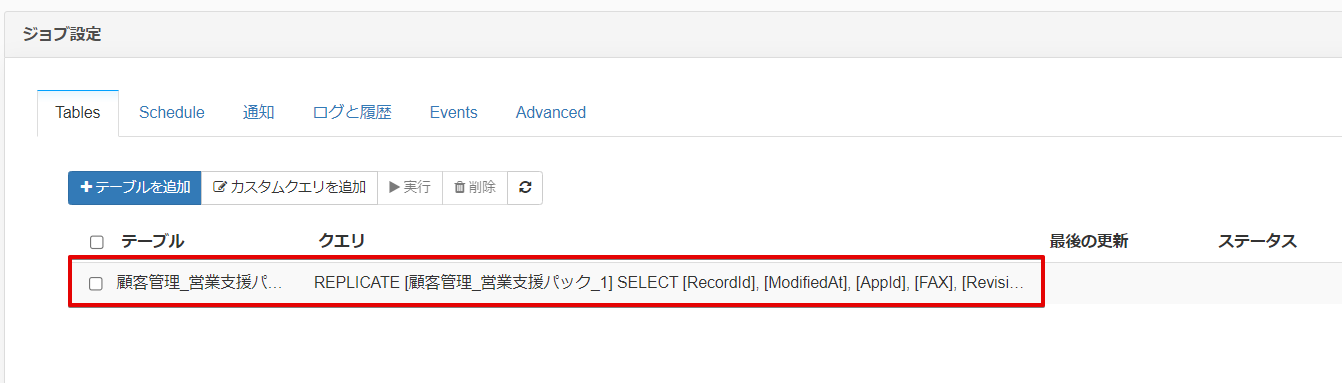
では作成したレプリケートクエリを実行していきましょう。
実行方法は作成したクエリにチェックを入れて実行ボタンをクリックするだけです。
実行が完了すると右側に更新日時とステータスが表示されます。
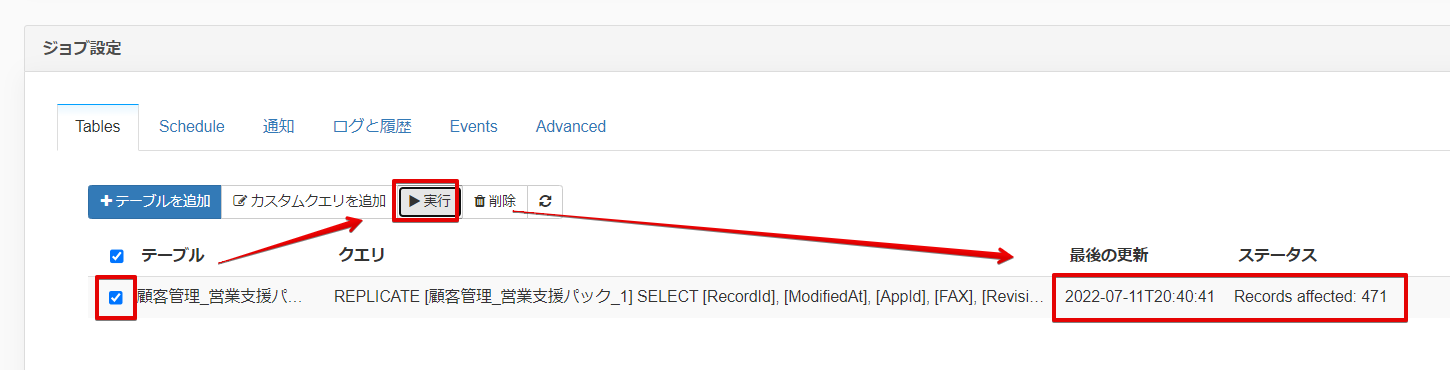
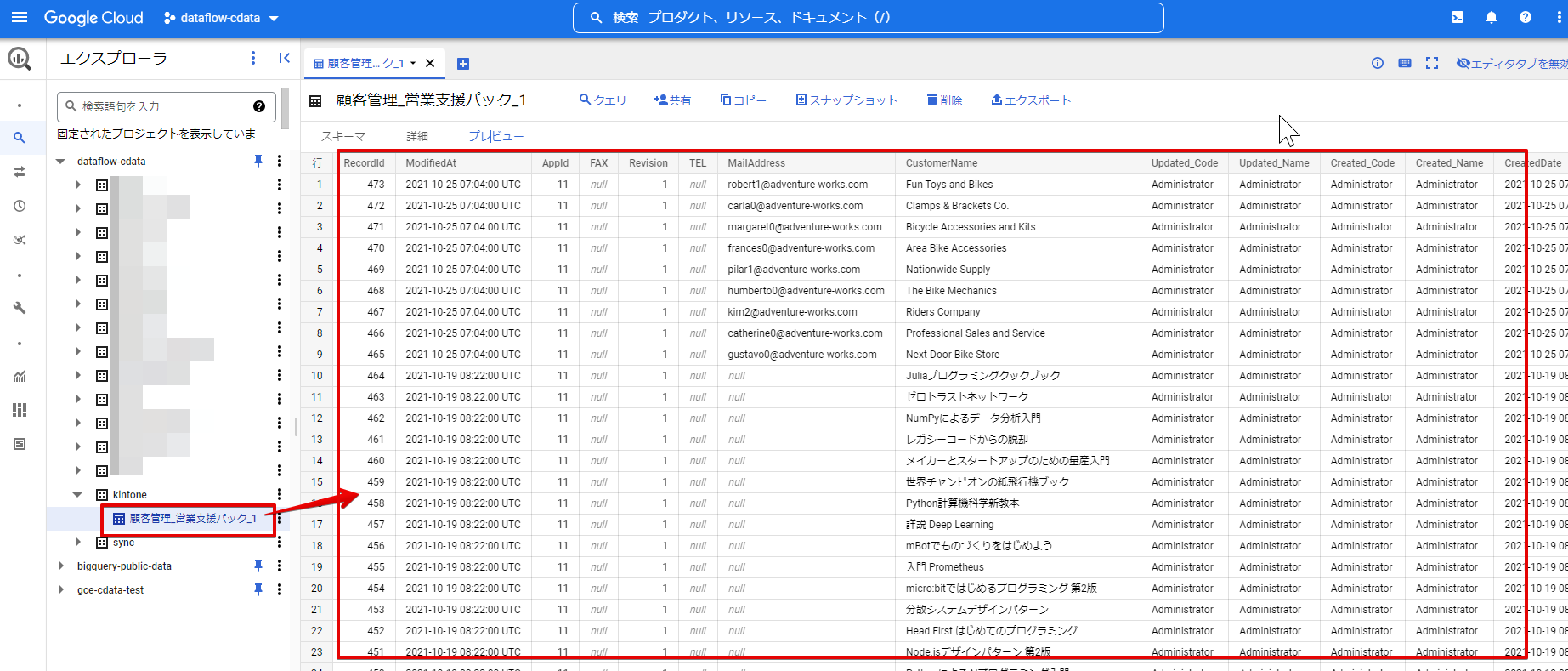
ジョブが正常に終了したので BigQuery 側を参照してみると、IBM Cloud Data Engine というデータセット配下に指定した名前でテーブルが作成され、中身についてもIBM Cloud Data Engine
にあるレコードが格納されていることが確認できました。
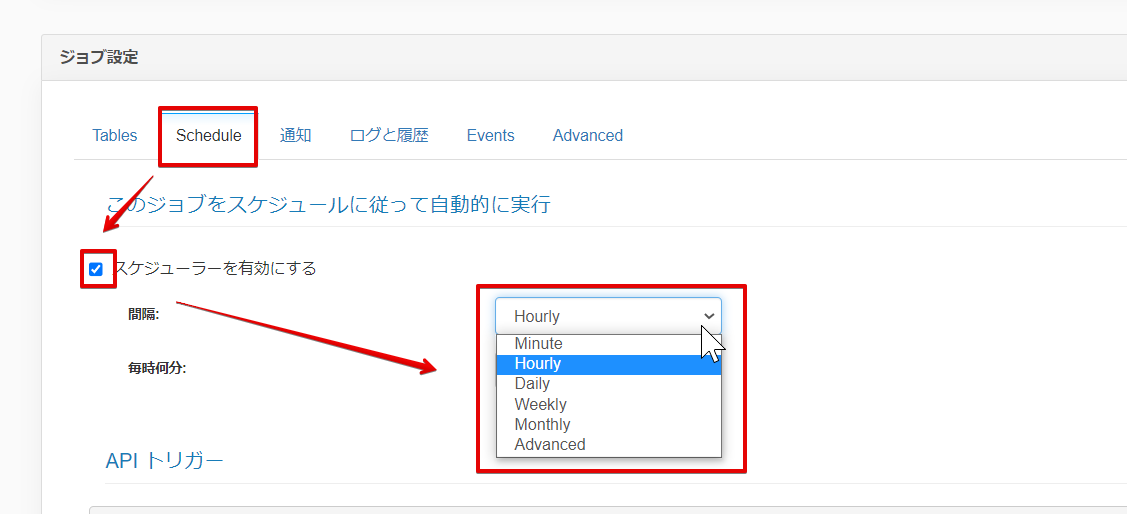
もし定期実行したい場合は「Schedule」タブにて指定することができます。
一つポイントとしては、BigQuery は主キー設定がなくレコードを蓄積していくタイプになるので、
の手段で行うことをお勧めします。
全件洗い替え方式は、ジョブオプションでテーブル削除にチェックを入れると有効になります。
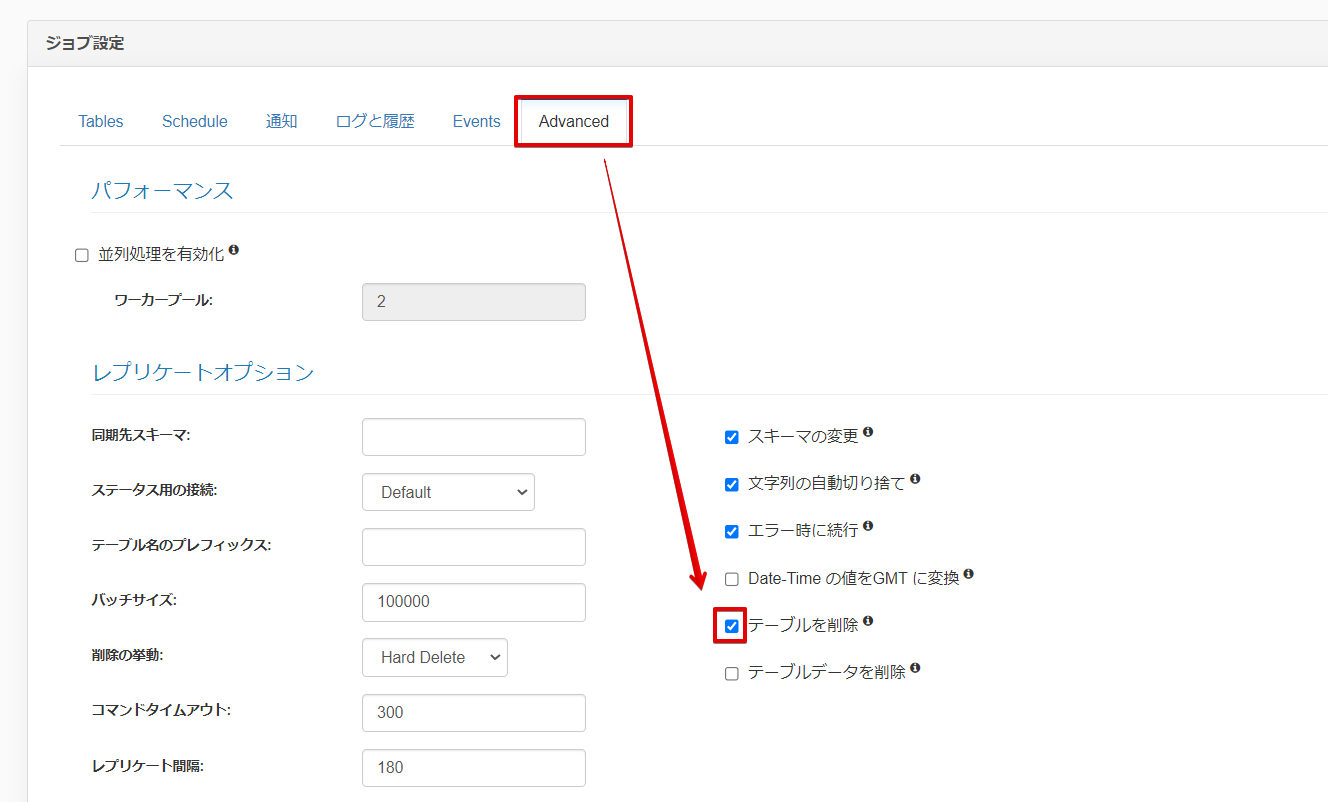
KARTE Datahub からはKARTE で作成したデータセットへのアクセスに加え、ユーザー側で保持しているデータセットにもサービスアカウントを利用してアクセスすることができるようになっています。本記事では後者の外部にあるデータセットを利用する手順を行っていきます。
もしKARTE のデータセットへ直接レプリケーションしたい場合は、対象サービスアカウントへの共有設定を KARTE Datahubで行うことで実現可能です。
詳細はKARTE
公式ドキュメントをご参照ください。
CData Sync(β版) (karte.io)
外部データセットを利用する設定を行うため、まずはKARTE の管理画面にログインします。
ログイン後、左のデータハブメニューからデータハブ→データハブ設定で進みます。
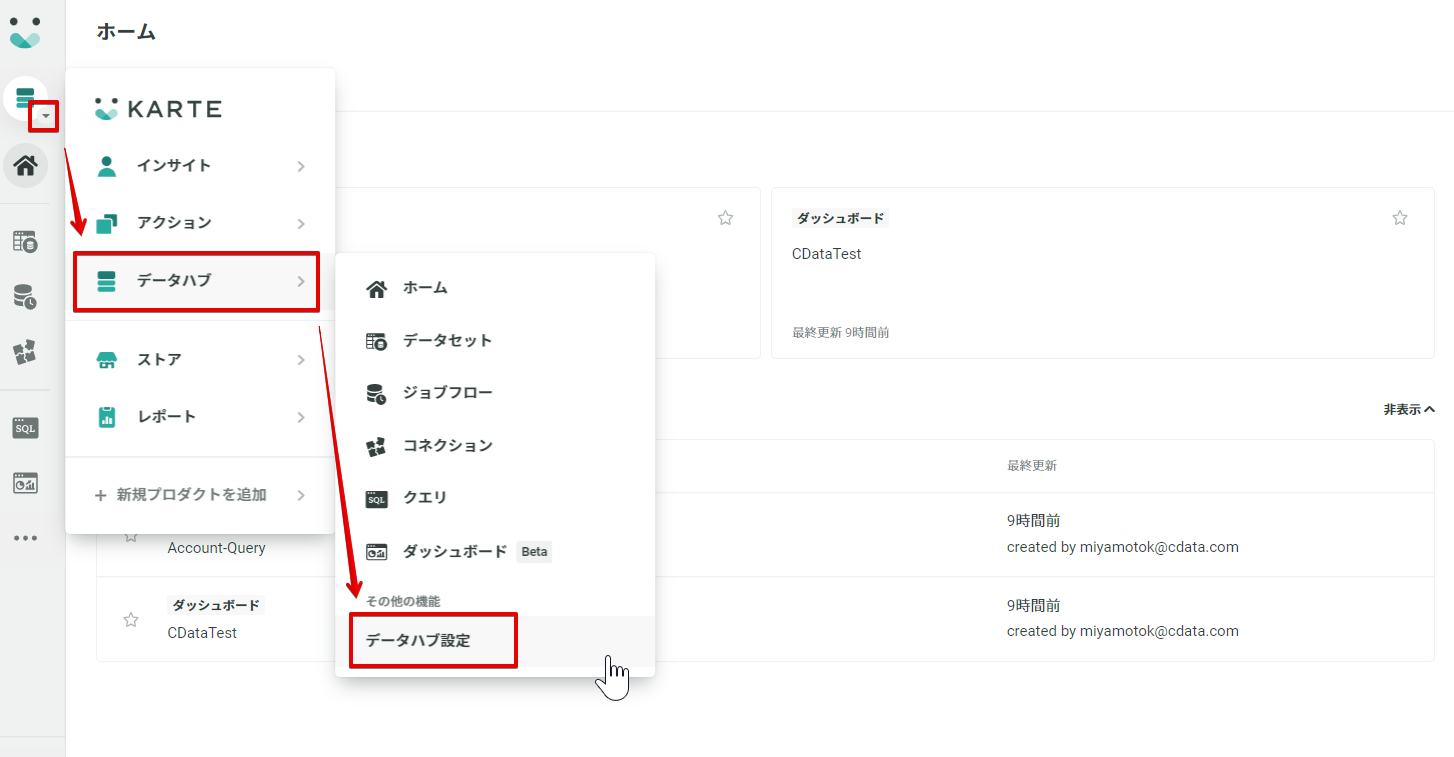
サービスアカウント管理タブからサービスアカウントを登録で外部のGoogle サービスアカウントを登録します。
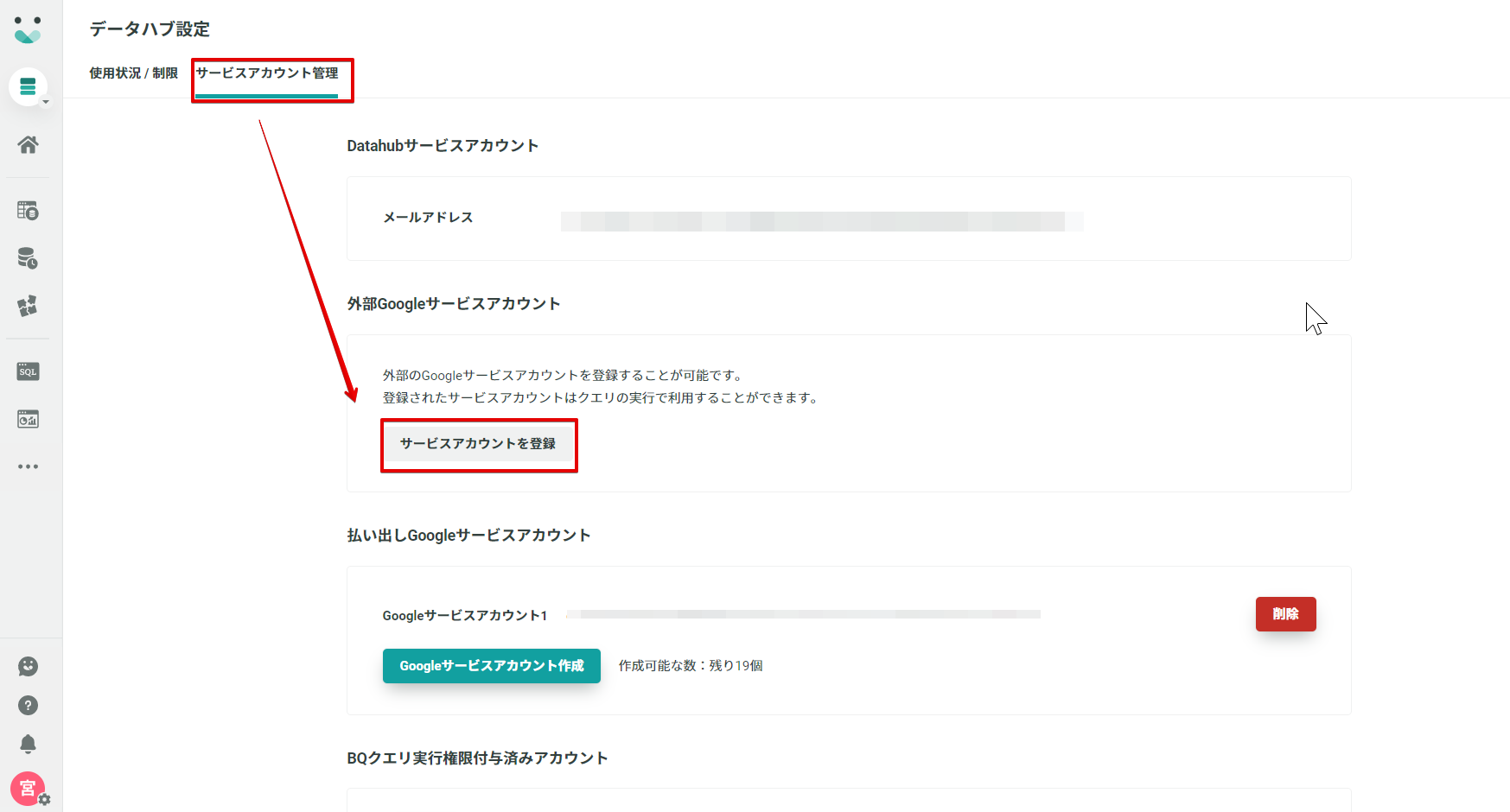
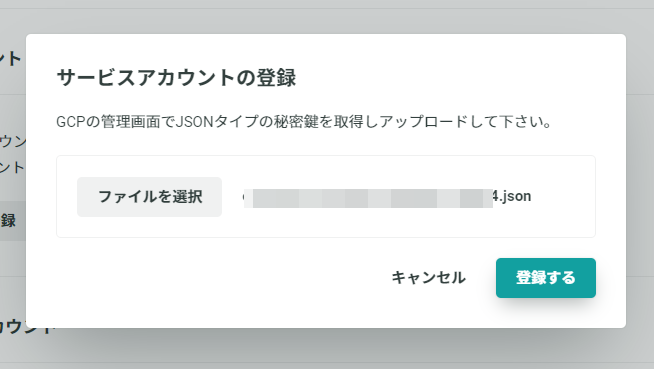
サービスアカウントを登録したら、あとは外部データセットの指定を行うとKARTE Datahub からでもアクセスすることができるようになります。
ではさっそく参照設定を行っていきます。
サイドメニューのKARTE Datahub メニューからデータハブ→データセットと進みます。
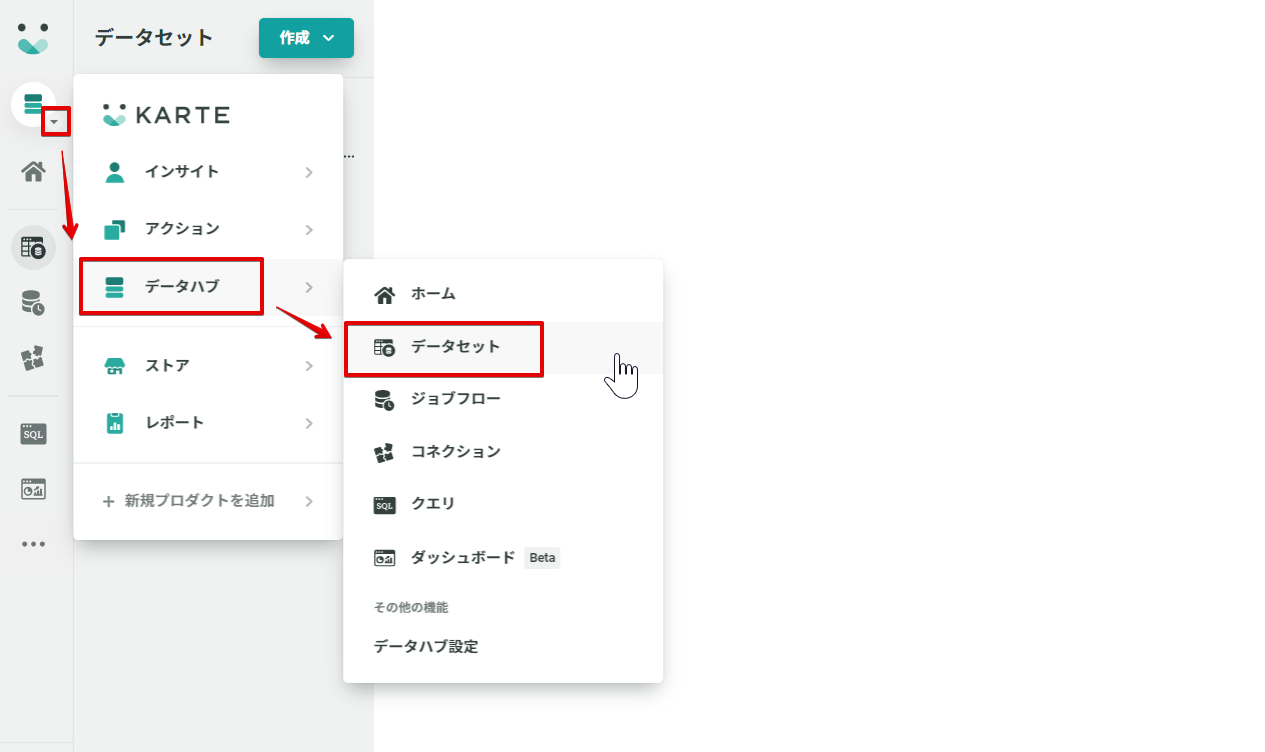
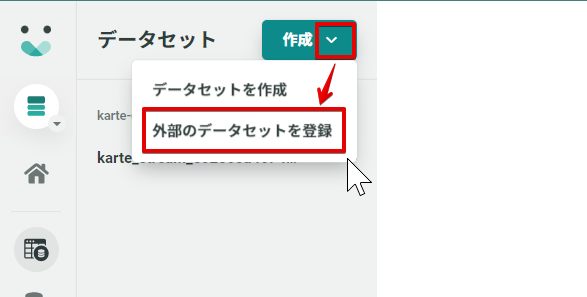
作成ボタンのメニューから外部のデータセットを登録をクリックします。
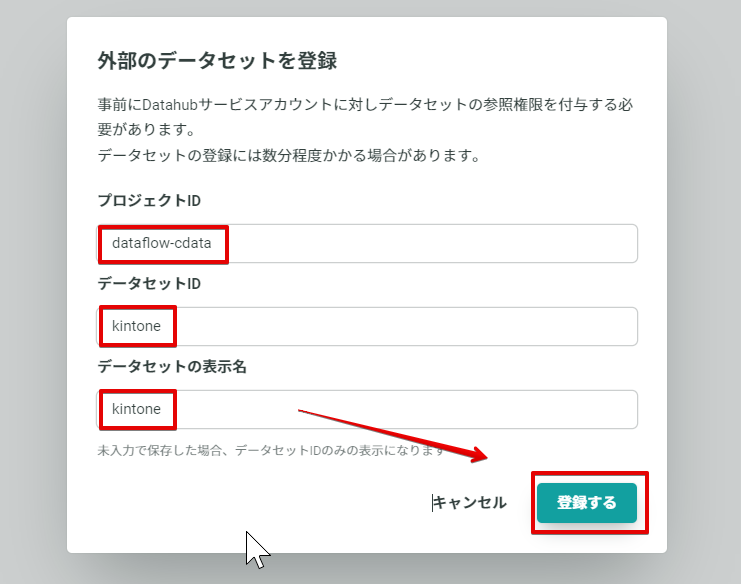
接続したいデータセット情報を設定します。
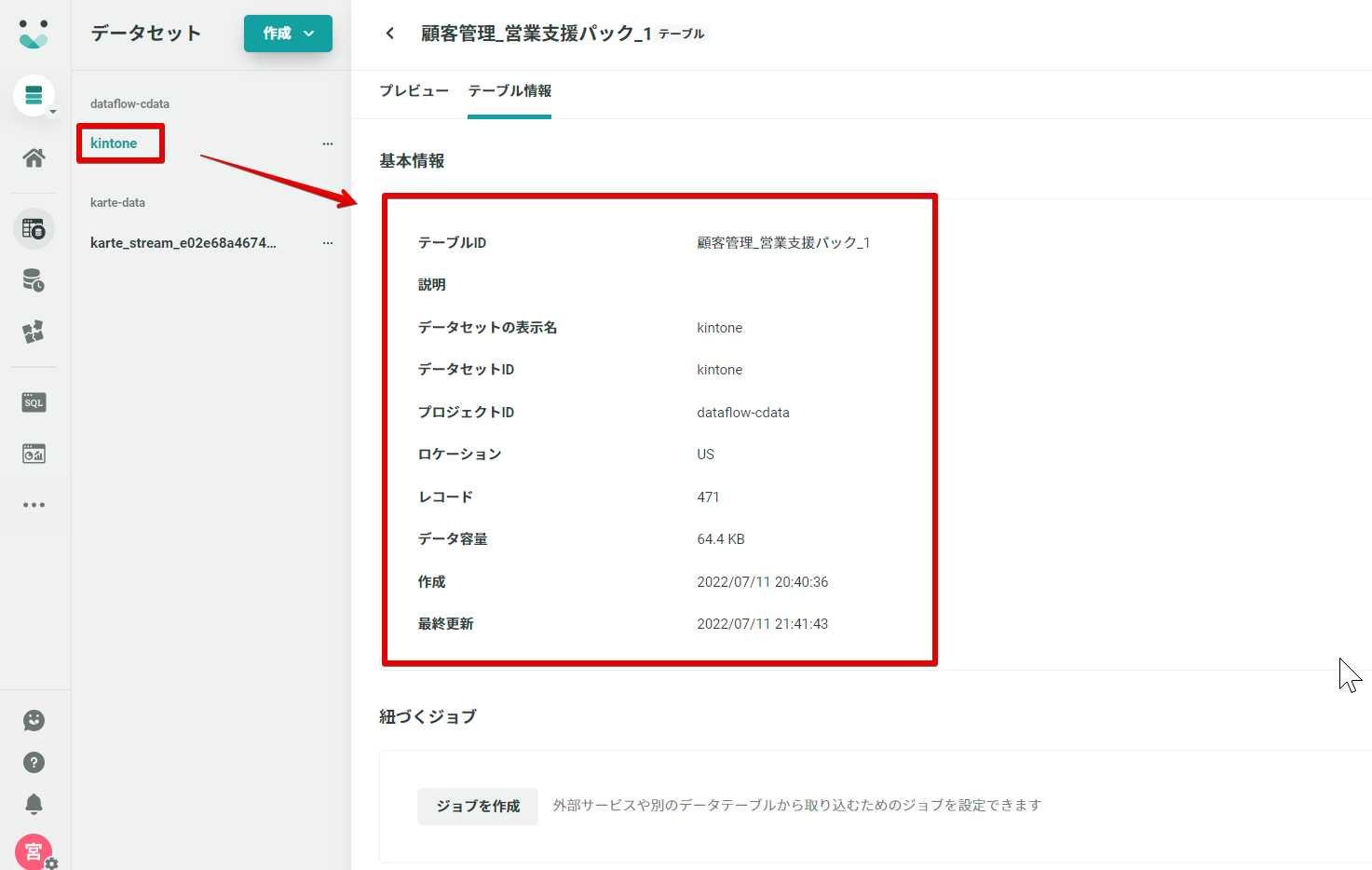
設定後、数分置くと KARTE Datahub から自分たちで保有するデータセットにアクセスすることができました。
KARTE Datahub 上でもクエリを実行してIBM Cloud Data Engine のデータを取得することができました。
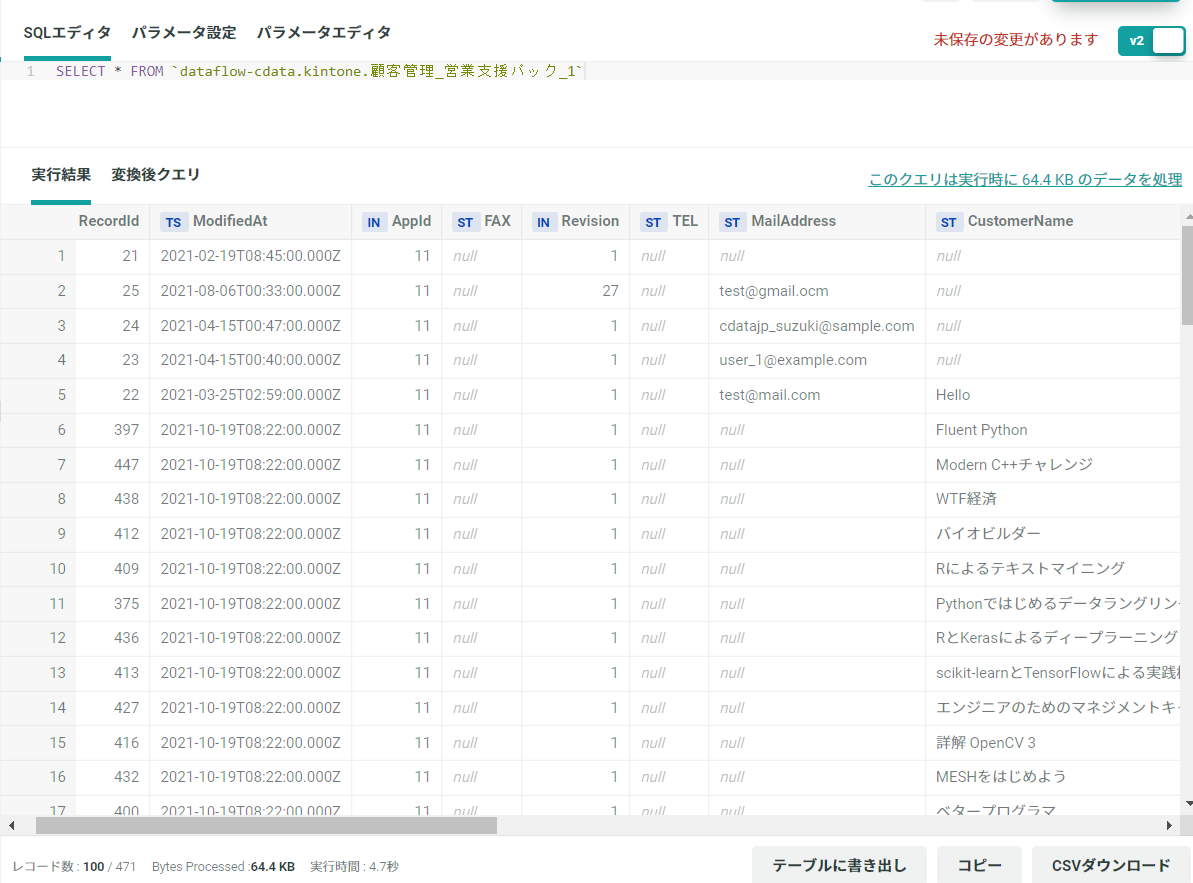
これによりKARTE で計測しているアプリや Webサイトの情報などとIBM Cloud Data Engine のようなSaaS データで持っているデータを掛け合わせて利用することができるようになりました。
KARTE Datahub ではBI 機能も備えているのですが、対象データはKARTE で計測しているデータのみということなので、今回のように外部データを利用する場合はデータポータルで可視化する流れになります。
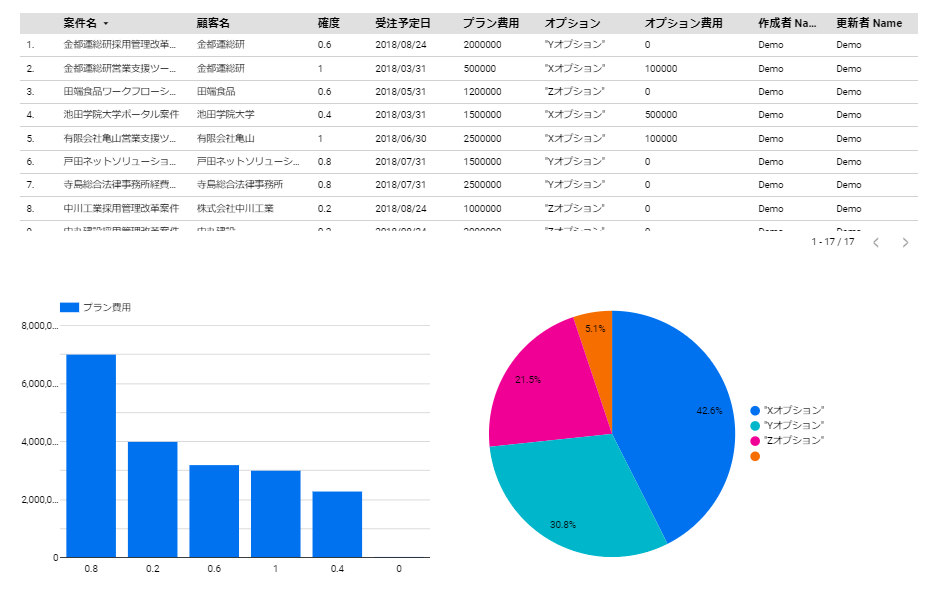
いかがでしたでしょうか。今回はCData Sync を使ってIBM Cloud Data Engine からKARTE Datahub が参照できるBigQuery のデータセットにデータをレプリケーションしてみました。これによりKARTE が計測しているリアルタイムな顧客情報とIBM Cloud Data Engine が保持している情報を掛け合わせて、より最適な情報を顧客にレコメンドするといったことができるになりました。今回はデータソースにIBM Cloud Data Engine を採用しましたが、他の SaaS や DB を指定しても同手順でKARTE Datahub で利用することができますので、ぜひユースケースに合ったデータソースでお試しください。



