
データは21世紀の石油と言われますが、貯めておくだけではガラクタの山になってしまいます。ガラクタの山であるデータを、ビジネスに資するインサイトを取得可能なものにするために必要なプロセスが、データパイプラインです。いわば、データパイプラインは、データという石油の精製所です。
本記事では、データパイプラインの解説からその変遷、そしてモダンなデータパイプラインに求められる機能をご紹介します。
データパイプラインとは?
データパイプラインは、エンタープライズの業務システムからデータを分析できる環境に転送、変換する一連のプロセス、と定義できます。通常、分析対象のデータが発生する業務システムをデータソースと呼び、複数のデータソースが整えられて分析用に保管される場所をデータ分析基盤と呼びます。
こうして構築した分析基盤に、データを消費するアプリケーション(BI ツールや機械学習プラットフォーム)からアクセスします。このプロセスには、パイプラインの種類によって異なりますが、Extract(データの抽出)、Transform(変換)、Load(ロード)が含まれます。それらの処理の順番によって、ETL パイプライン、ELT パイプラインと言われます。
データパイプラインは、データをシステムA からシステムB にコピーするだけという簡単なものではありません。データソース側では、データは企業のオンプレミスの基幹システムだけではなく、複数のSaaS・Web サービス・IoT に分散しAPI 仕様が異なるものからデータを抽出する必要があります。
また企業のデータのボリュームは年々増加しており、差分更新などで効率的にデータ取得を行う必要があります。さらに、異なるシステムからの構造化データ・非構造化データに変換処理を適用して分析できる形にしなければなりません。変換処理の具体例としては、重複削除、正規化、データ型の変換、マスキング、集計などがあります。
データパイプラインを正しく構築することで、以下のようなメリットを得ることができます。
- データ品質の向上
- データ分析の効率化
- 意思決定の迅速化
- データガバナンスの向上
逆に、データパイプラインを活用せず、こうした作業に手作業、または場当たり的なスクリプトで対処しようとすれば、データ活用をスケールさせることはできないでしょう。
データパイプラインの基本がわかったところで、次にデータパイプラインの変遷とクラウド時代に求められるデータパイプラインのあり方を見ていきましょう。
データパイプラインの変遷
データパイプラインといっても、その用途・規模などにより多くの種類があります。これらの分け方ははっきりしたものではないのですが、単純化して説明をしていきます。
ETL パイプライン
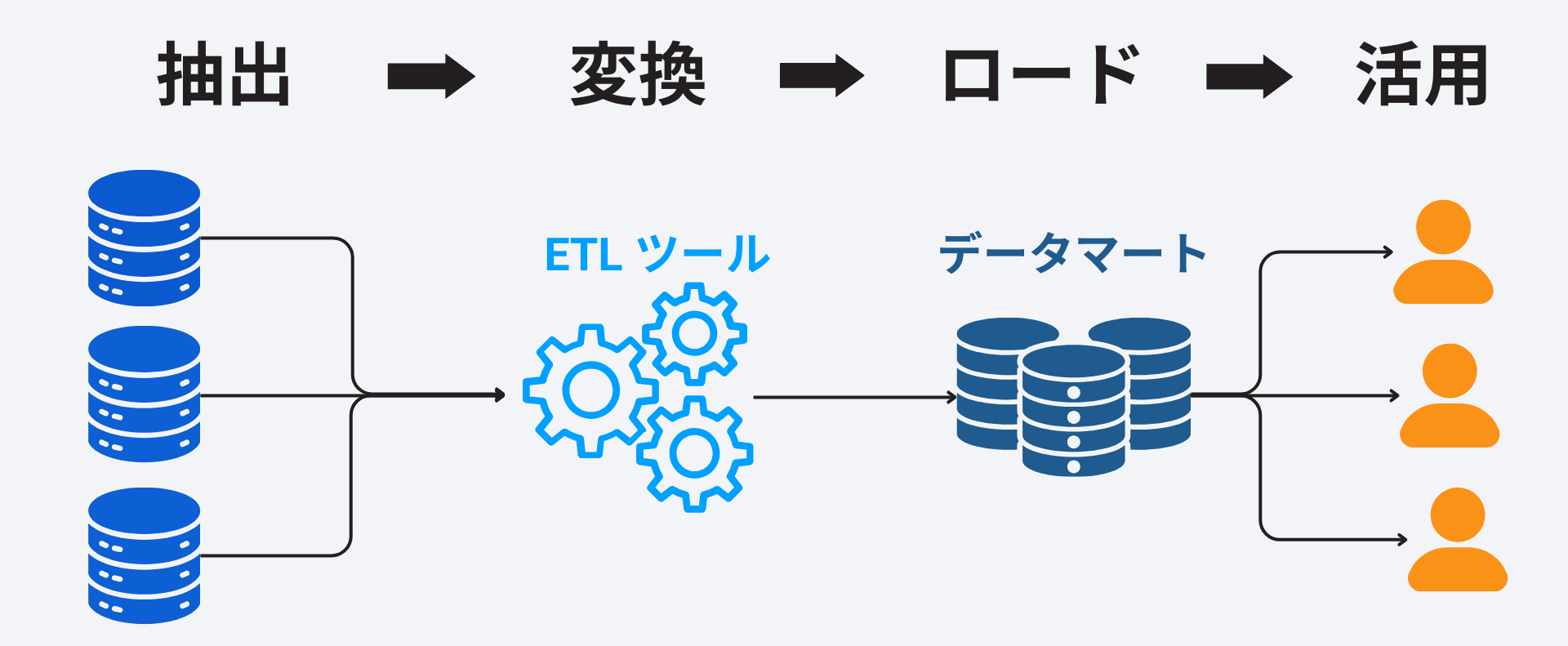
データをExtract、Transfer、Load の順番で処理をする方式がETL パイプラインです。基幹システムおよびサブシステムからのデータをOracle やSQL Server などのデータベースにETL ツールを使ってローディングして、分析に活用します。ソースから取得されたデータはETL ツールによりプロセス内で分析用に変換・集計されて、分析できるデータとしてデータベースに保管されます。
より規模の大きいデータを扱う場合にはHadoop を利用して、変換されたデータをOLAP に格納して分析するという方法も、このETL パイプラインの代表と言えます。
コーディングによるELT パイプライン
ETL パイプラインの時代には、ストレージと計算資源がすべてオンプレミスのサーバー上で管理されており、処理するデータ規模をスケールさせるには高いコストが必要でした。
この状況を変えたのが、2010年代からのAWS・GCP・Azure などのクラウドサービスの登場です。クラウドサービスは、ストレージと計算資源を切り離して管理することを可能にし、ストレージ面ではS3・GCS などのクラウド型の安価なストレージ(データレイク)の提供を開始しました。さらに、強力なコンピューティングリソースを持つ分析基盤として、Redshift、BigQuery のような次世代のクラウドデータウェアハウスが登場しました。
データレイクの登場により、DB に格納されたテーブル形式とは異なる、音声・動画・テキストデータに代表される大規模な非構造化データの活用が実現しました。こうしたデータは、特に機械学習やAI モデルの学習用途で求められます。
このような背景のもと、抽出(Extract)とデータレイクへのロード(Load)までを先に実行して、変換処理(Transer)はDWH などクラウドサービスの計算資源を活用して行う、ELT 方式のデータパイプラインが台頭してきました。
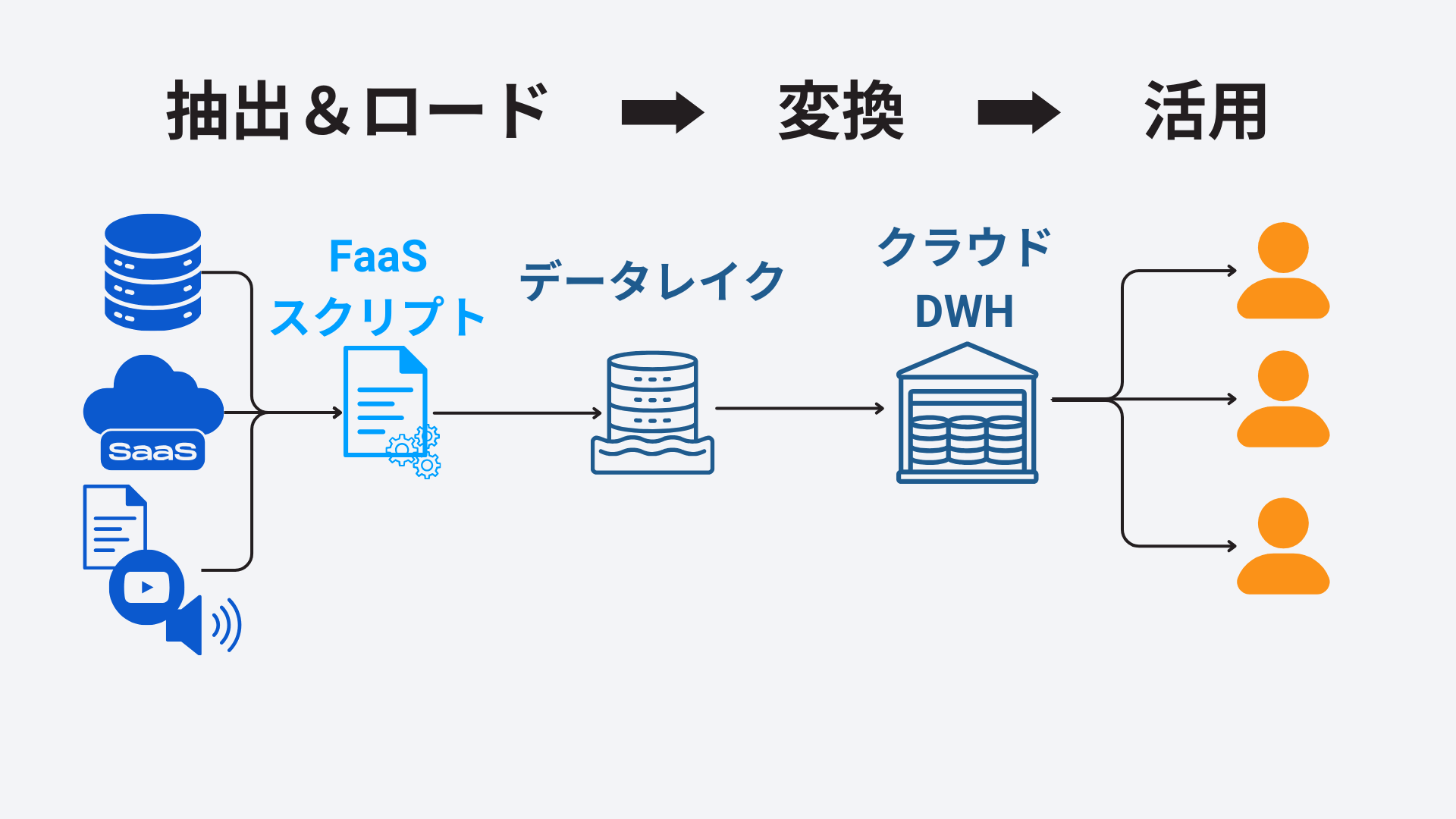
ELT パイプラインの中でも、抽出・ロードの部分をAWS Lambda、Google Cloud Functions のようなFaaS を使う、Python などのプログラミングでスクラッチでCSV を業務システムから吐き出させるやり方をコーディングELT パイプラインと呼びます(Coded ELT Pipeline)。このアプローチには、以下のような課題が意識されるようになってきました。
- 増加するSaaS やその他のデータソースに対応するプログラミングの負荷
- 差分更新などの要求されるロジックの高度化
モダンなELT パイプライン
こうしたコーディングによるELT パイプラインの持つ課題を解決するものがモダンなデータパイプラインです。モダンデータスタックでのデータパイプラインは以下のような構成です。
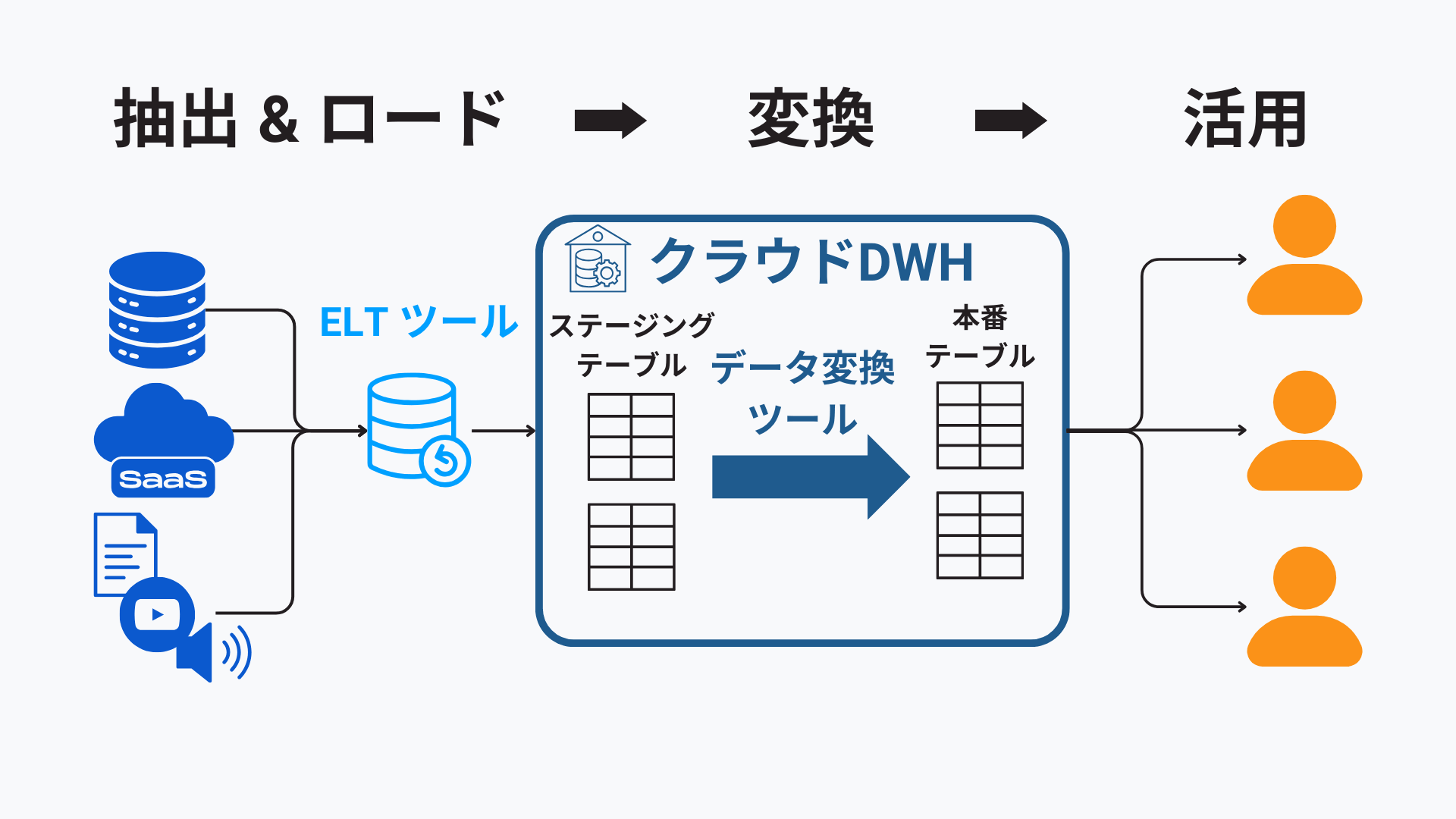
モダンなデータパイプラインでは、データの抽出(Extract)およびロード(Load)には、高度な機能(後述)を備えた専用のデータパイプライン(ELT)ツールが使われます。
データはSnowflake、Google BigQuery、Azure Synapse、Databricks、AWS Redshift などのクラウドデータウェアハウス・データレイクハウスに直接ロードできます。DWH・レイクハウス内で格納用のステージングテーブルから分析用の本番テーブルにデータ変換がなされ、成型されます。データ変換にはdbt などのツールが使われることも一般的になっています。
モダンなデータパイプラインに求められる6つの機能
ここからはモダンなデータパイプラインに求められる機能を見ていきましょう。
多数のSaaS・データベースのデフォルトでのサポート
増加を続ける企業で利用されるSaaS の種類に対応するために、モダンなデータパイプラインツールでは、数十・数百のSaaS・データベースのサポートが期待されます。複数の認証のサポート、データソース内の幅広いデータオブジェクトのサポート、データのスキーマ付与、フィルタリングなどの高度な要件を満たすコネクタを用意することで圧倒的に効率を高めることが可能です。基底となるAPI は絶えず変更されるため、API 変更への追従を行うことも必須です。
CDC(変更データキャプチャ)
CDC は、データソースであるDB 側のデータから変更された部分だけを抽出して転送することを可能にする技術です。更新日付用カラムを用意することでCDC を実現するカラムベース、DB のトランザクションログをベースに実現するログベースといった方式が存在します。
ログベースなどの形では、データベースにクエリをする必要がないため、データベースにデータ取得時に負荷をかけない点が重要です。そのほかの方法でも全データを毎回クエリ・転送する必要がなくなり、データの転送から活用までに必要な時間を大きく短縮できるほか、通信帯域を抑えてコストを削減できます。
SaaS データの差分抽出・ロード
データソースがSaaS の場合でも、データパイプラインツールでデータの差分抽出が可能です。SaaS の場合にはAPI リミットがあり、MA やCRM などのデータを毎回全量取得することは不可能に近いです。そのようなデータの場合には、差分だけを抽出する機能が非常に重要となります。
データ変更履歴の保持
SCD(Slowly Changing Dimension) はデータ分析基盤となる中核であるデータウェアハウスで分析軸となるデータの属性値の履歴管理をどのように保管するかをタイプ別に分類したデータモデリング手法です。変更されたデータをデータウェアハウス内で上書きすることなく、履歴データとして利用可能な形で保存することでプロジェクトや案件の推移などデータの変化を追うことが可能になります(SCD についてはこちらの記事を参考にしてください)。
dbt などのデータ変換ツールとの連携
モダンなデータパイプラインで活躍しているデータ変換ツールとの連携も大変重要です。データ変換ツールの代表例としては、dbt やGoogle Dataform が挙げられます。DB/DWH 上のデータ変換をSQL ベースで定義でき、変換処理の開発をCI / CD で管理できるようになっています。
ストリーミング
医療機器などのIoT デバイス、ゲームなどのWeb アプリから継続的に生成されるデータを扱うことに特化したストリーミングデータパイプラインの採用も進んでいます。ストリーミングデータパイプラインには、生成されるデータをリアルタイムかつ信頼性を担保しつつ処理することが求められます。こうしたパイプラインの処理基盤としては、分散ストリーミング処理基盤のApache Kafka やAmazon Kinesis が有名です。
また、ビジネススピードが加速化する中で1日に1度といった単位でのデータ転送しかできなければ、意思決定は競合に出遅れることになります。絶えずELT プロセスを回しているような継続的レプリケーションを求めるケースも増えています。
CData Sync で実現するモダンなデータパイプライン
以上見てきたように、モダンなデータパイプラインにはCDC を活用した高速・低コストのデータ転送、データ変更履歴の保持、dbt 連携、リアルタイム性といった機能が求められます。こうした機能を実現するのが、ELT パイプライン構築ツールであるCData Sync です。
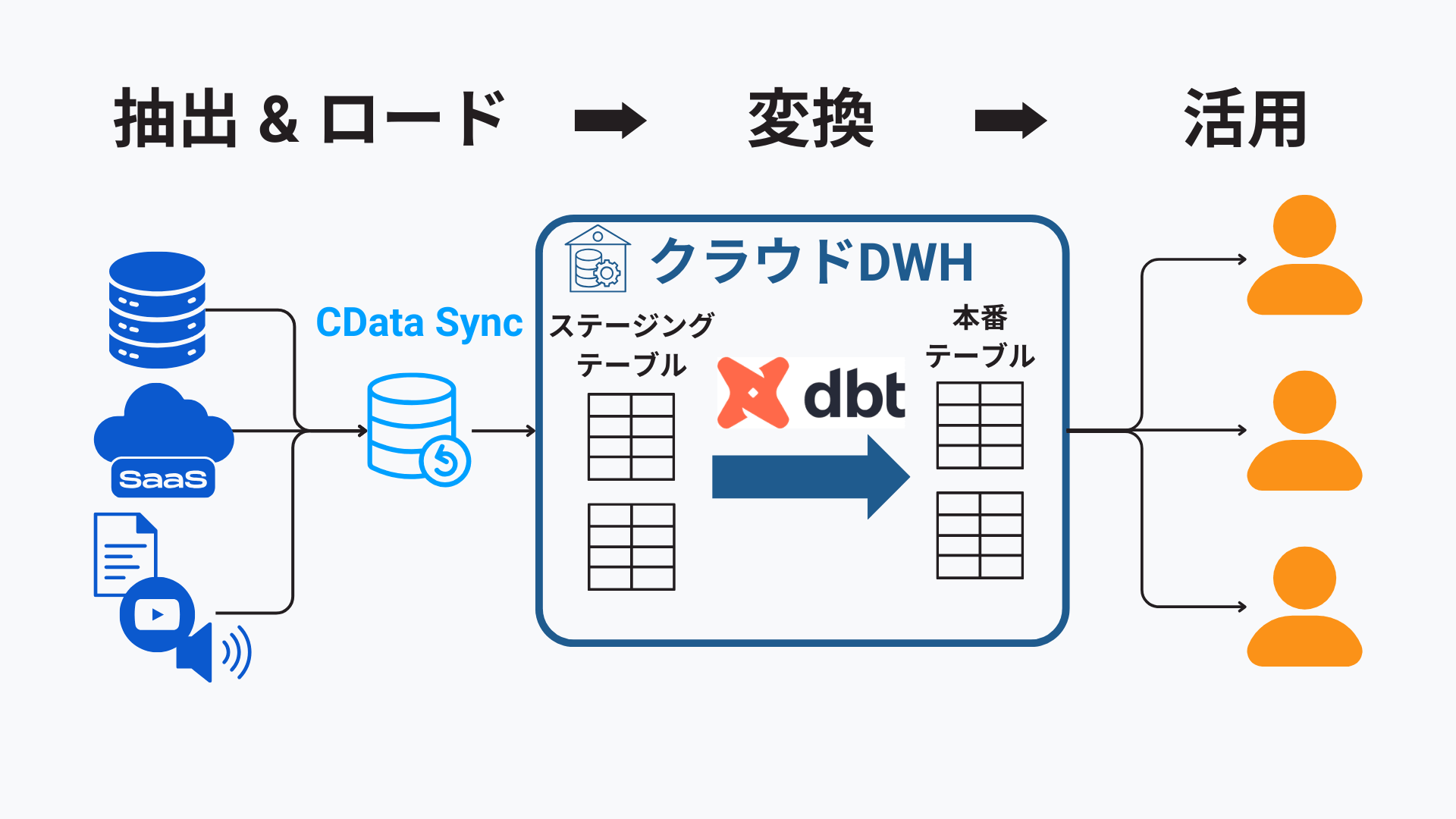
主要な機能を挙げてみましょう(より詳しくはこちらのページをご確認ください)。
- SaaS、DB、ファイルを含む400種類以上のデータソース
- 差分更新・CDC
- ヒストリーモード(SCD Type 2)
- dbt 連携
- ニアリアルタイムのデータ転送
- スキーマ変更の自動追従・データ型の検出
- リバースETL
こうした機能をすべて備えた上で、CData Sync の設定はノーコードで完結します。CData Sync が、増加するSaaS 連携ニーズに応えつつ、ハイパフォーマンス、リアルタイムなデータパイプラインの構築をお手伝いします。
おわりに
データパイプラインの変遷、そしてモダンなデータパイプラインに求められる機能について解説しました。必要とするデータソースや利用環境によってフィットするデータパイプラインを選ぶことで、データ分析をより効率的に行うことができます。
CData Sync は30日間の無償トライアルですべての機能を試用できます。また、毎月開催のハンズオンセミナーでは手軽にSync でELT 処理の構築を体験いただけます。
30日間無償トライアルで試してみる
CData Sync でモダンなデータパイプラインを実現
400種類以上のデータソース対応、差分更新・CDC、ヒストリーモード(SCD Type 2)、dbt 連携、ニアリアルタイムのデータ転送といったモダンなデータパイプラインに欠かせない機能を搭載したCData Sync で、データ基盤の構築をはじめてみませんか?
30日間の無償トライアルで試してみる
関連コンテンツ



