Don't Let Slow Performance Freeze Your Snowflake Integrations

Snowflake is a leading cloud data warehouse and a popular backbone for enterprise BI, analytics, data management, and governance initiatives. Its fast query access, dynamic auto-scaling, cloud-first architecture, and fully managed SaaS delivery model make it a common choice for cloud data consolidation.
To make the most of your investment in Snowflake you need the best connectivity solutions to your Snowflake warehouse. CData gives you easy data access for real-time insights on top of your Snowflake data, and high-speed insertion of your enterprise data into Snowflake for comprehensive data storage.
Driver in Focus: Snowflake Performance Benchmarks
This article provides an overview of the technical capabilities of the CData JDBC Driver for Snowflake and compares the read and write performance of the CData JDBC Driver with the native Snowflake JDBC Driver and a competitor JDBC Driver for Snowflake when working with large datasets.
- Read Performance: The CData JDBC Driver is 10% to 31% faster than other available drivers when reading datasets (with better performance for larger data sets).
- Write Performance: The CData JDBC Driver is 45% faster than the competitor driver and immeasurably faster than the native driver.
Explore the datasets we used, the queries we ran, and the details of the results, including CPU and Java heap usage.
JDBC Driver Read Performance
The goal of this investigation was to compare the related performance of three JDBC Snowflake drivers available on the market. We did this by running the same set of queries with each JDBC driver. We used LIMIT clauses to change the size of the dataset returned in each query, but we requested the same columns for each query.
The Data
To provide a reproducible comparison for reading data, we queried the ORDERS table in the TPC-H schema of the SNOWFLAKE_SAMPLE_DATA shared database.
| Table Size |
Number of Rows |
Number of Columns |
| 4.3 GB |
150,000,000 |
9 |
Base Query
SELECT
O_ORDERKEY,
O_CUSTKEY,
O_ORDERSTATUS,
O_TOTALPRICE,
O_ORDERDATE,
O_ORDERPRIORITY,
O_CLERK,
O_SHIPPRIORITY,
O_COMMENT
FROM
"SNOWFLAKE_SAMPLE_DATA"."TPCH_SF100"."ORDERS"
Limit by Query
- LIMIT 1000000
- LIMIT 10000000
- none
To test the drivers, we connected to Snowflake using a basic Java application and executed the above queries repeatedly. The results were read and stored in a new variable (based on the datatype) for each column in each row. The times you see in the chart below are the average times for each query, in seconds.
Query Results
| Query Times by Driver (in seconds) |
| Query |
CData JDBC |
Competitor JDBC |
Snowflake JDBC |
| 1 (1M rows) |
6.65 (+10.7%-22.1%) |
7.45 |
8.54 |
| 2 (10M rows) |
58.66 (+10.1%-18.9%) |
65.23 |
72.38 |
| 3 (150M rows) |
592.83 (+26.8%-31.4%) |
863.63 |
809.82 |
As seen in the results, the CData JDBC driver regularly outperformed the other drivers, retrieving and processing results up to 31% faster.
JDBC Driver Resource Usage
While testing the read performance of the JDBC drivers, we also measured client-side resource usage, looking specifically at memory and CPU usage. The charts below were found by running a sample Java program and using Java VisualVM to capture the CPU and memory usage. We used Java version 8 update 333 with no maximum heap size.
The images below show the resource usage for reading 150 million rows.
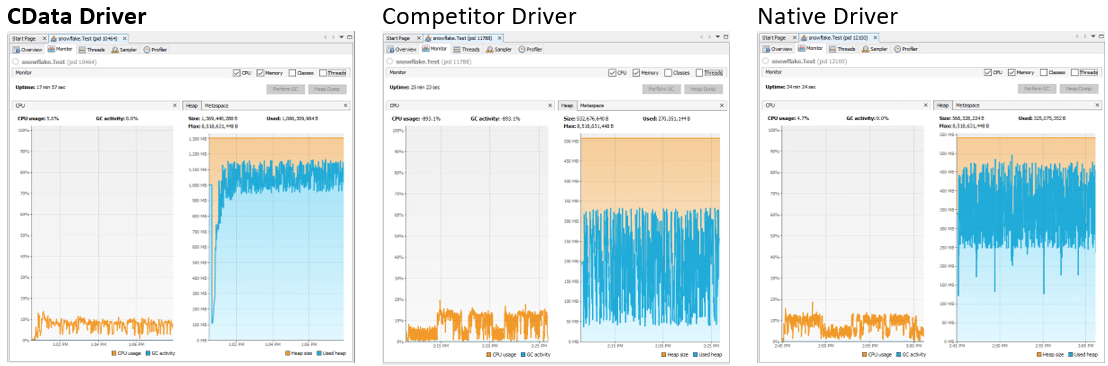
* Note the change in scale for the Heap graph.
The CData driver averages over 1000 MB of heap usage for the read, making the most out of the freely available memory resources to outperform the other drivers. We can also see that the CData driver consistently uses around 10% of the CPU available, continuously processing the data as fast as it is returned.
The competitor driver only uses on average 200 MB of the unlimited heap availability. The competitor driver is also inconsistent in its CPU usage, spiking to nearly 20%, signifying erratic processing of the incoming data.
The native driver uses on average 350 MB of the unlimited heap availability. The native driver, like the competitor driver, is inconsistent in its CPU, also spiking to nearly 20% and signifying erratic processing of the incoming data.
Million Row Challenge
In this comparison we put the drivers to the task of inserting one million rows into a Snowflake table (a task the native driver was not able to complete). The CData JDBC driver is 45% faster than the competitor driver and is more efficient when it comes to client-side resource usage. The native driver spent more than four hours inserting rows without completing the task.
We used a simple Java program to add rows to a copy of the ORDERS table from the TPC-H schema. For our testing, we inserted the data in 100 batches of 10,000 rows.
Sample Code
//one batch
Connection connection = DriverManager.getConnection("jdbc:googlebigquery:InitiateOAuth=GETANDREFRESH;QueryPassthrough=false;ProjectId=" + projectId + ";DatasetId=" + datasetId + ";Timeout=240;UseLegacySQL=false;");
String cmd = "INSERT INTO TestDataset.nyc_yellow_trips_copy (vendor_id, pickup_datetime, dropoff_datetime, pickup_longitude, pickup_latitude, dropoff_longitude, dropoff_latitude, rate_code, passenger_count, trip_distance, payment_type, fare_amount, extra, mta_tax, imp_surcharge, tip_amount, tolls_amount, total_amount, store_and_fwd_flag) VALUES (?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?)";
PreparedStatement pstmt = connection.prepareStatement(cmd);
for (int row = 0; row < rows.length; row++){
String[] line = rows[row].split(",");
for (int i = 0 ; i < line.length; i++) {
//add parameters based on datatype
if ( (i < 3) || (i ==7) || (i==10) || (i==18) ) {
pstmt.setString(i + 1, line[i]);
} else if (i == 8) {
pstmt.setInt(i+1, Integer.parseInt(line[i]));
} else {
pstmt.setDouble(i+1, Double.parseDouble(line[i]));
}
}
pstmt.addBatch();
}
int[] affected = pstmt.executeBatch();
Results
| 1 Million Row Write Times by Driver (in seconds) |
| CData JDBC Driver |
Competitor Driver |
Native Driver |
| 52.38 |
94.57 |
4+ hours |
Conclusion
The CData JDBC Driver for Snowflake offers better querying performance for large datasets over both the native driver and the competitor driver, processing the largest datasets 31% faster by making better use of the available client resources to read and process data as quickly as possible.
When it comes to writing data, the CData JDBC Driver outperforms the competitor driver, inserting 1 million rows nearly 50% faster than the competitor (and immeasurably faster than the native driver, which had not completed the task after 4 hours.
Our developers have labored to optimize the performance in processing the results returned by Snowflake to the point that the driver appears to only be hindered by web travel time and server processing times. The same effort has been put into making efficient use of the Snowflake write functionality, making the CData driver the clear winner for both reading from and writing to Snowflake data warehouses.
Ready to try it yourself? Download the CData JDBC Driver for Snowflake today.