各製品の資料を入手。
詳細はこちら →Apache Spark Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへCData


こんにちは!ドライバー周りのヘルプドキュメントを担当している古川です。
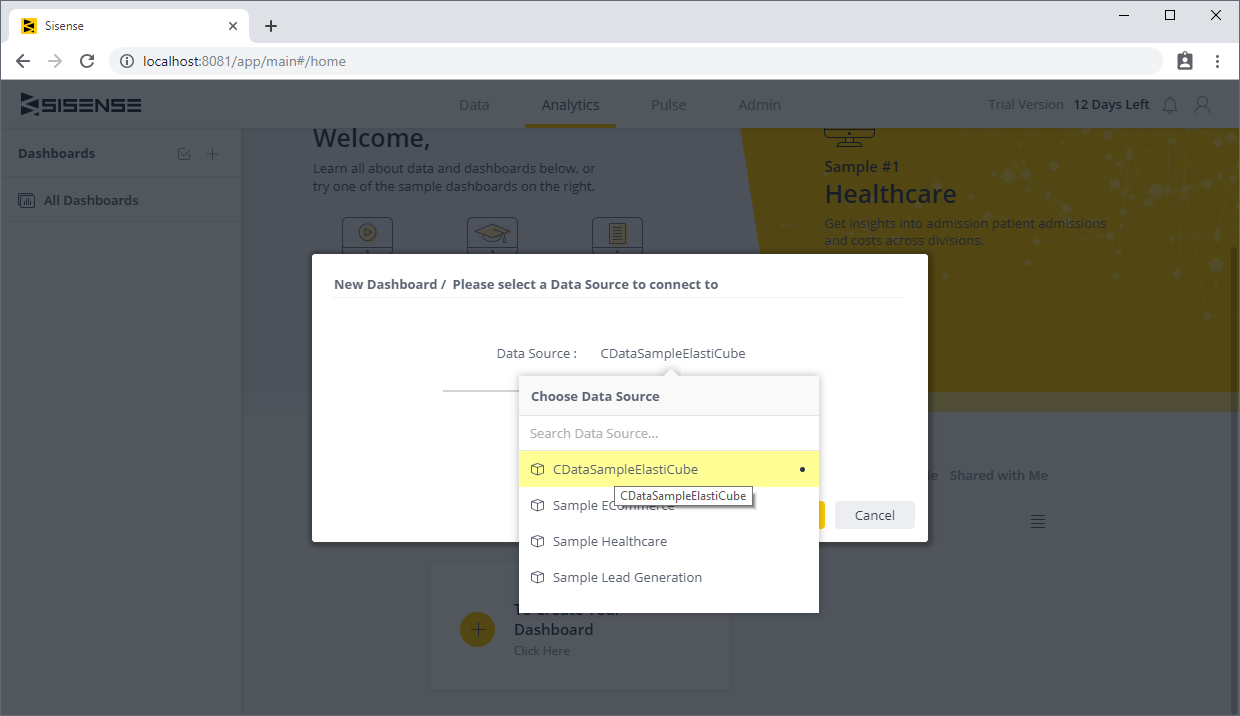
Sisense を使用すると、データを結合、分析、画像化lし、よりインテリジェントなビジネス決定を行い、効果的な戦略を作成できます。CData JDBC Driver for SparkSQL は、Sisense に簡単に統合して利用することができます。この記事では、Spark に接続するElastiCube の作成方法と、それを使用してSisense のSpark をビジュアライズする方法を説明します。
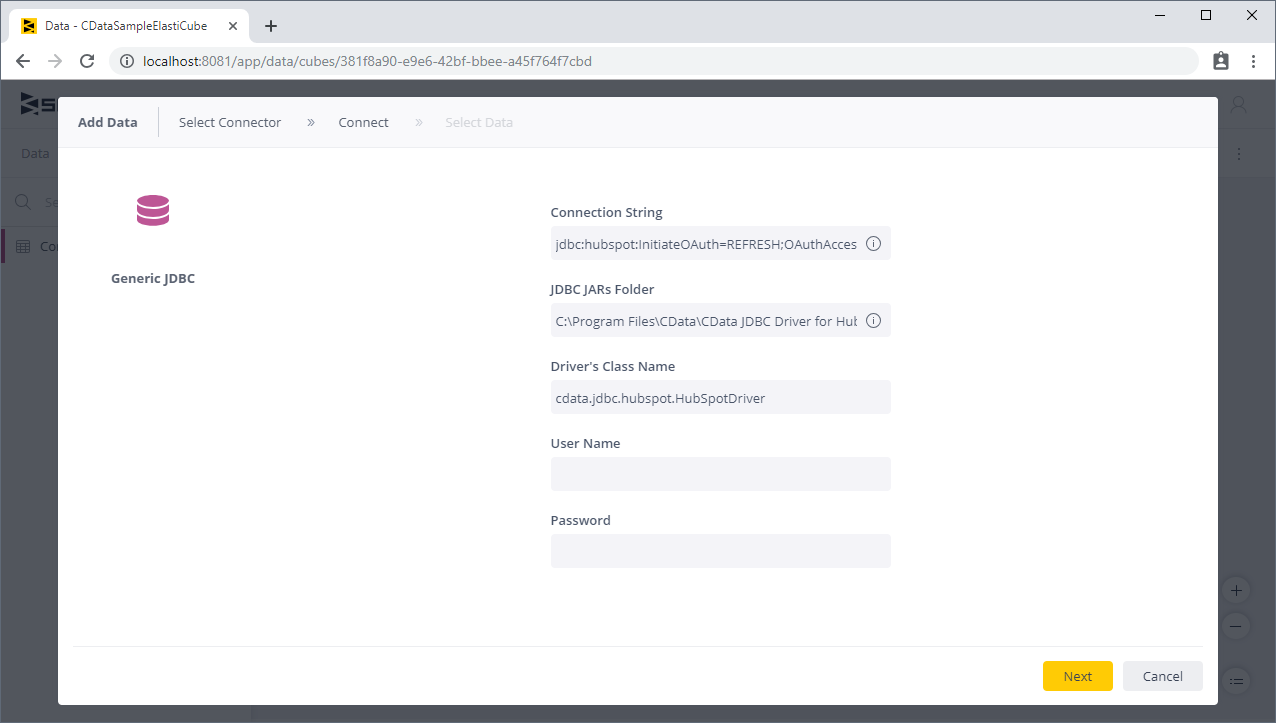
ElastiCube を作成する前に、JDBC Driver のJAR ファイル(通常はC:\Program Files\CDatat\CData JDBC Driver for SparkSQL\lib) のインストール場所をメモするか、jar ファイル(cdata.jdbc.sparksql.SparkSQL.jar) をSisense JDBC driver ディレクトリの新しいフォルダ(通常はC:\ProgramData\Sisense\DataConnectors\jdbcdrivers)にコピーします。
SparkSQL への接続を確立するには以下を指定します。
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
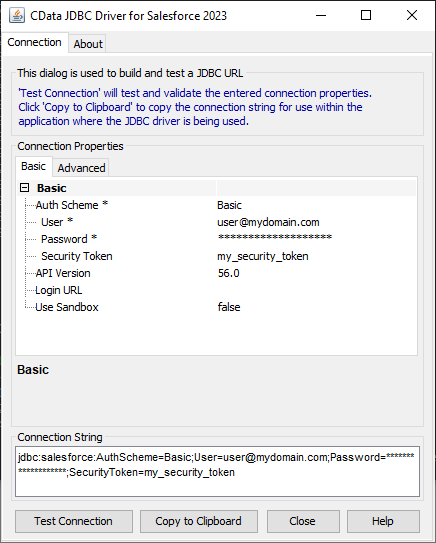
JDBC URL の構成については、Spark JDBC Driver に組み込まれている接続文字列デザイナを使用してください。JAR ファイルのダブルクリック、またはコマンドラインからJAR ファイルを実行します。
java -jar cdata.jdbc.sparksql.jar
接続プロパティを入力し、接続文字列をクリップボードにコピーします。
JDBC URL を構成する際に、Max Rows プロパティを定めることも可能です。これによって戻される行数を制限するため、可視化・レポートのデザイン設計時のパフォーマンスを向上させるのに役立ちます。
以下は一般的な例です。
jdbc:sparksql:Server=127.0.0.1;
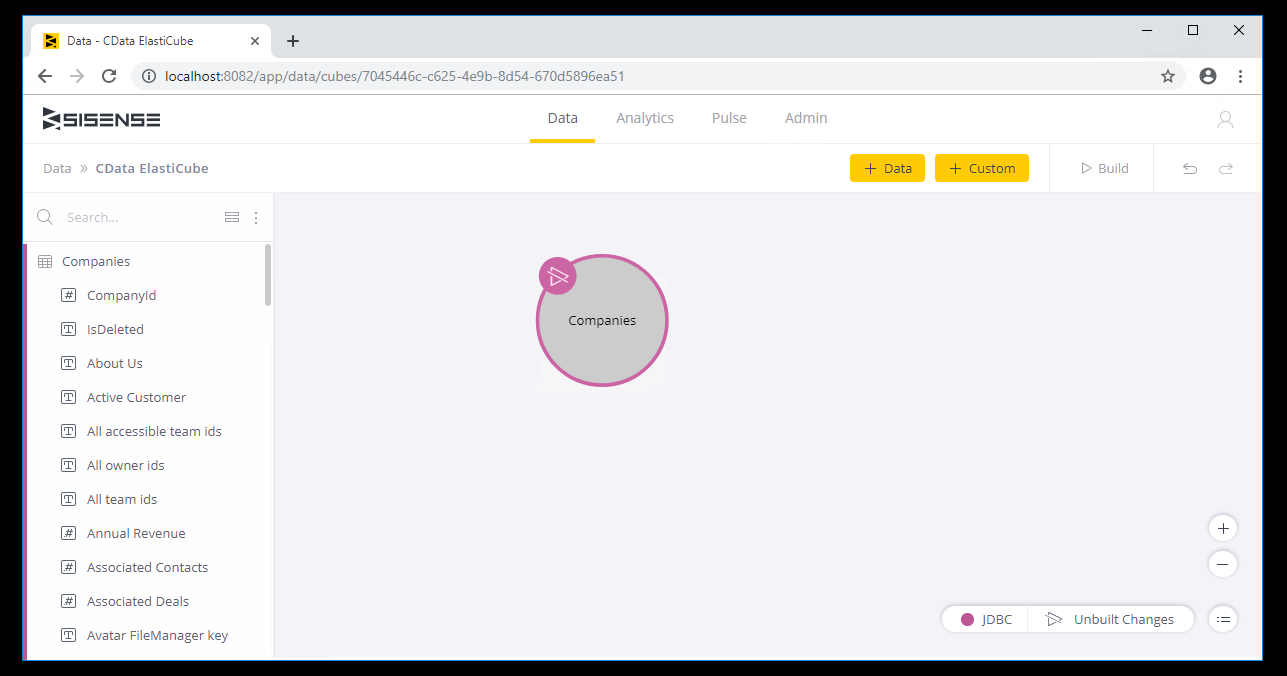
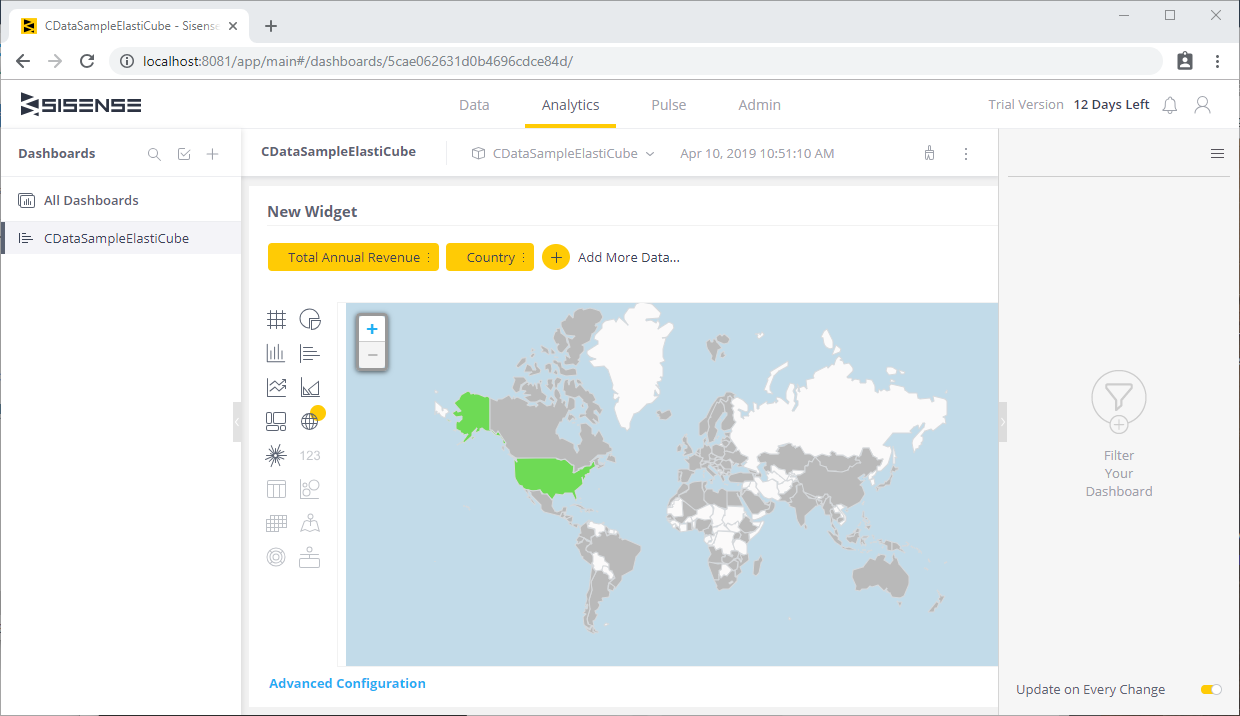
Spark に接続すると、ElastiCubeにテーブルとビューを追加できます。
ElastiCube をSpark テーブルに追加することで、Spark で分析を実行できます。
CData JDBC Driver for SparkSQL を使用することで、Sisense でSpark に直接アクセスしてビジュアライズと分析を行うことができます。30日の無償評価版をダウンロードし、今すぐSisense でSpark を使用しましょう!