各製品の資料を入手。
詳細はこちら →Apache Spark Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへCData


こんにちは!ドライバー周りのヘルプドキュメントを担当している古川です。
Servoy は、迅速なアプリケーション開発とデプロイのためのプラットフォームです。CData JDBC Driver for SparkSQL と組み合わせることで、ユーザーはSpark に接続してリアルタイムSpark のデータを使用できるアプリケーションを構築できます。この記事では、Servoy からSpark に接続し、Spark のデータを表示、検索するための簡単なWeb アプリケーションを構築する方法を説明します。
ビルトインの最適化されたデータ処理により、CData JDBC Driver は、リアルタイムSpark のデータとやり取りする際に圧倒的なパフォーマンスを提供します。Spark に複雑なSQL クエリを発行すると、ドライバーはフィルタや集計などのサポートされているSQL 操作をSpark に直接プッシュし、サポートされていない操作(主にSQL 関数とJOIN 操作)は組み込みのSQL エンジンを利用してクライアント側で処理します。組み込みの動的メタデータクエリを使用すると、ネイティブデータソース型を使用してSpark のデータを操作できます。
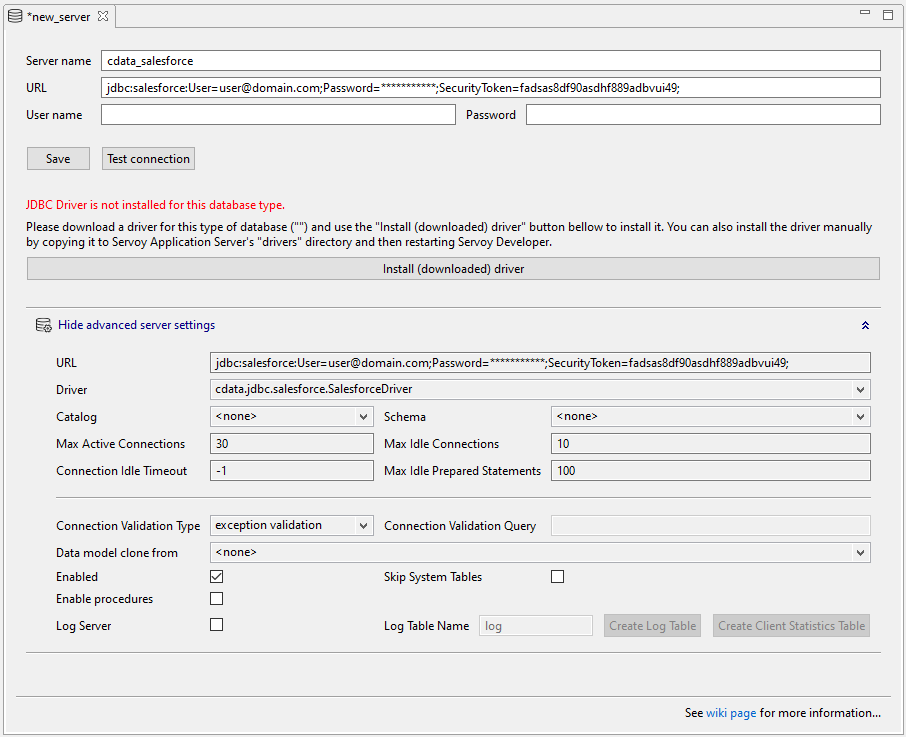
Spark に接続するアプリケーションを構築するには、まず、Servoy Developer からCData JDBC Driver for SparkSQL を使用してデータプロバイダを作成する必要があります。
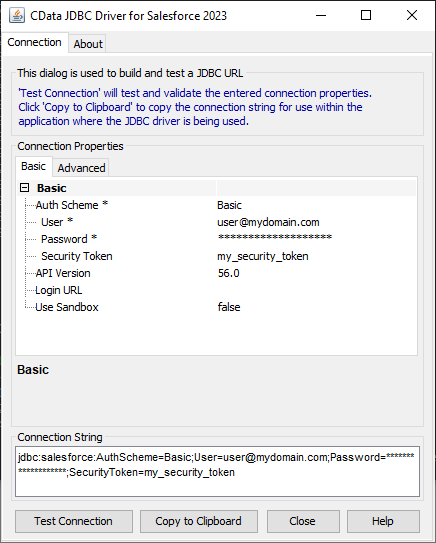
次のようにURL を設定します。例:jdbc:sparksql:Server=127.0.0.1;
JDBC URL の構築については、Spark JDBC Driver に組み込まれている接続文字列デザイナーを使用してください。JAR ファイルをダブルクリックするか、コマンドラインからjar ファイルを実行します。
java -jar cdata.jdbc.sparksql.jar
接続プロパティを入力し、接続文字列をクリップボードにコピーします。
SparkSQL への接続を確立するには以下を指定します。
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
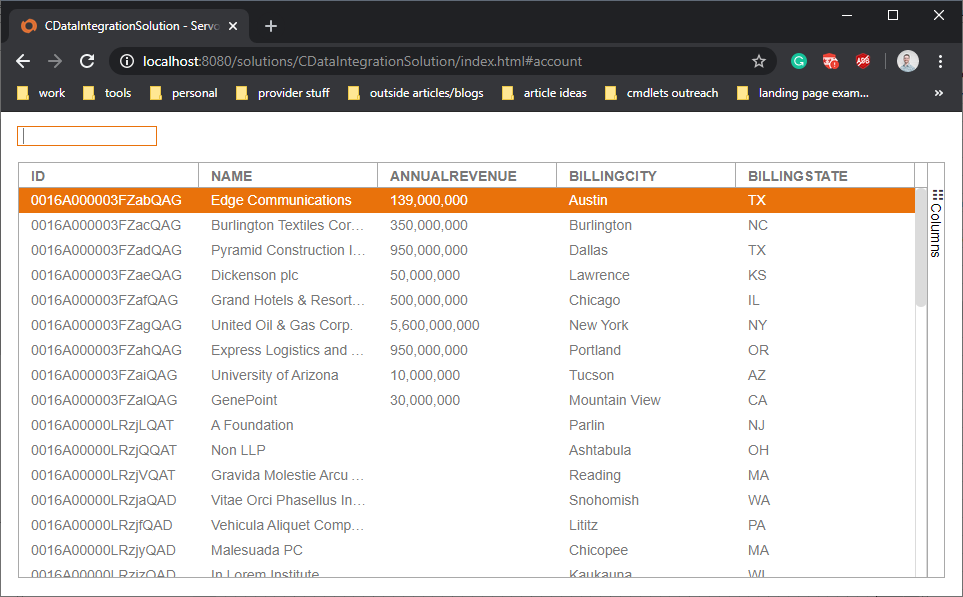
Servoy Developer リソースでSpark への接続を設定すると、リアルタイムSpark へのアクセス権を持つアプリケーションを構築することができます。
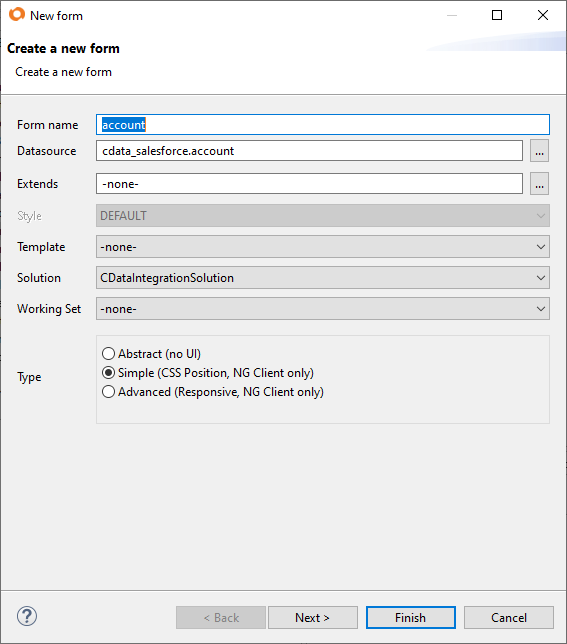
「Forms」を右クリックし、「Create new form」を選択します。
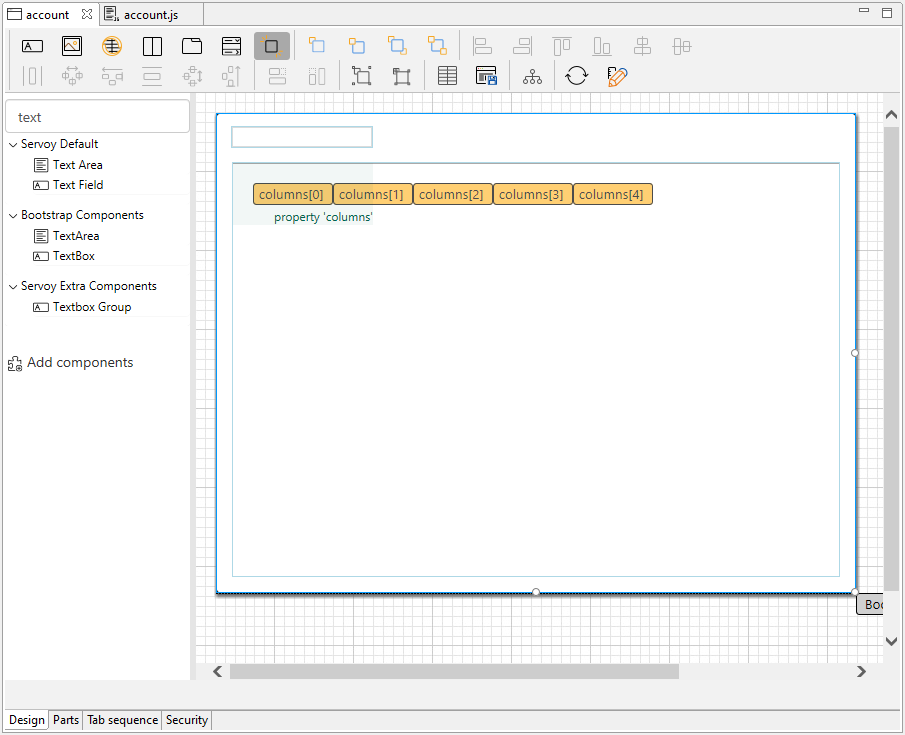
カラムコンポーネントをData Grid にドラッグし、各カラムコンポーネントの「dataprovider」プロパティをSpark 「table」のカラム(例:Customers テーブルのCity)に設定します。
必要に応じてカラムを追加します。
検索機能を追加するには、「svySearch」拡張機能が必要です。(新しいソリューションを作成する際にデフォルトで含まれます。)ソリューションの作成時に拡張機能を追加しなかった場合、または、既存のソリューションを変更する場合は、ソリューション内のModules を右クリックして「Add Module」を選択することで検索モジュールを追加できます。「svySearch」を選択し、「OK」をクリックします。
var searchText = '';
var search = scopes.svySearch.createSimpleSearch(foundset).setSearchText(searchText); search.setSearchAllColumns(); search.loadRecords(foundset);
フォームとJavaScript ファイルを保存し、「Run」->「Launch NGClient」とクリックしてWeb アプリケーションを起動します。
CData JDBC Driver for SparkSQL の30日の無償評価版をダウンロードし、Servoy でSpark に接続されたアプリケーションの構築を開始します。ご不明な点があれば、サポートチームにお問い合わせください。