各製品の資料を入手。
詳細はこちら →Apache Spark Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへこんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
MicroStrategy は、データドリブンイノベーションを可能にする分析およびモバイルプラットフォームです。MicroStrategy とCData JDBC Driver for SparkSQL を組み合わせると、MicroStrategy からデータベースと同じようにリアルタイムSpark データにアクセスできるようになり、レポート機能と分析機能が拡張されます。この記事では、MicroStrategy Web の外部データソースとしてSpark を追加し、Spark データの簡単なビジュアライゼーションを作成する方法について説明します。
CData JDBC ドライバーは、ドライバーに組み込まれている最適化されたデータ処理により、MicroStrategy でリアルタイムSpark データとやり取りするための比類のないパフォーマンスを提供します。MicroStrategy からSpark に複雑なSQL クエリを発行すると、ドライバーはフィルタや集計などのサポートされているSQL 操作をSpark に直接プッシュし、組み込まれたSQL エンジンを利用してサポートされていない操作(主にSQL 関数とJOIN 操作)をクライアント側で処理します。ビルトインの動的メタデータクエリを使用すると、ネイティブのMicroStrategy データタイプを使用してSpark データをビジュアライズおよび分析できます。
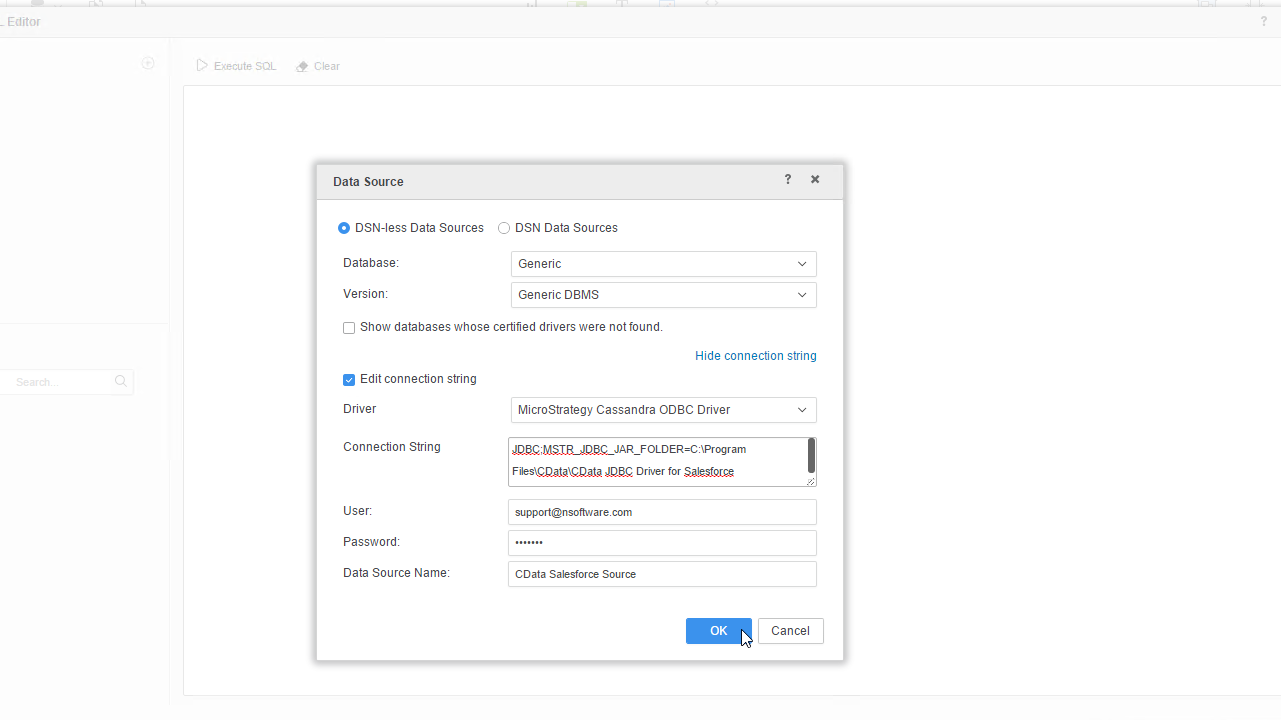
CData JDBC Driver for SparkSQL を使用したデータソースを追加することにより、MicroStrategy Web のSpark に接続できます。*始める前に、MicroStrategy Web のインスタンスが接続されているMicroStrategy Intelligence Server をホストするマシンにJDBC Driver for SparkSQL をインストールする必要があります。データソースを作成したら、MicroStrategy Web でSpark データの動的なビジュアライゼーションを構築できます。
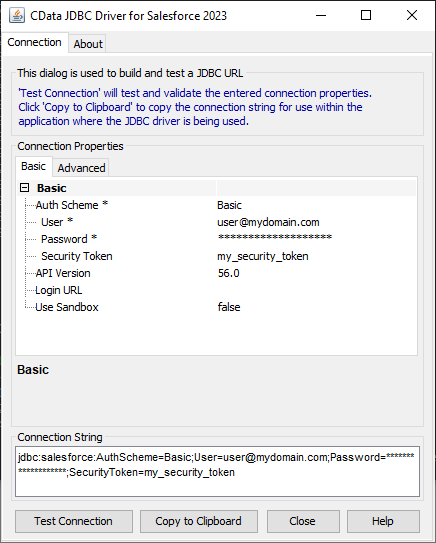
JDBC;MSTR_JDBC_JAR_FOLDER=PATH\TO\JAR\;DRIVER=cdata.jdbc.sparksql.SparkSQLDriver;URL={jdbc:sparksql:Server=127.0.0.1;};
SparkSQL への接続を確立するには以下を指定します。
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
JDBC URL の構築については、Spark JDBC Driver に組み込まれている接続文字列デザイナーを使用してください。JAR ファイルをダブルクリックするか、コマンドラインからjar ファイルを実行します。
java -jar cdata.jdbc.sparksql.jar
接続プロパティを入力し、接続文字列をクリップボードにコピーします。
JDBC URL を構成する際に、Max Rows 接続プロパティも設定できます。これにより返される行数が制限されるため、レポートやビジュアライゼーションをデザインするときのパフォーマンスを向上させることができます。
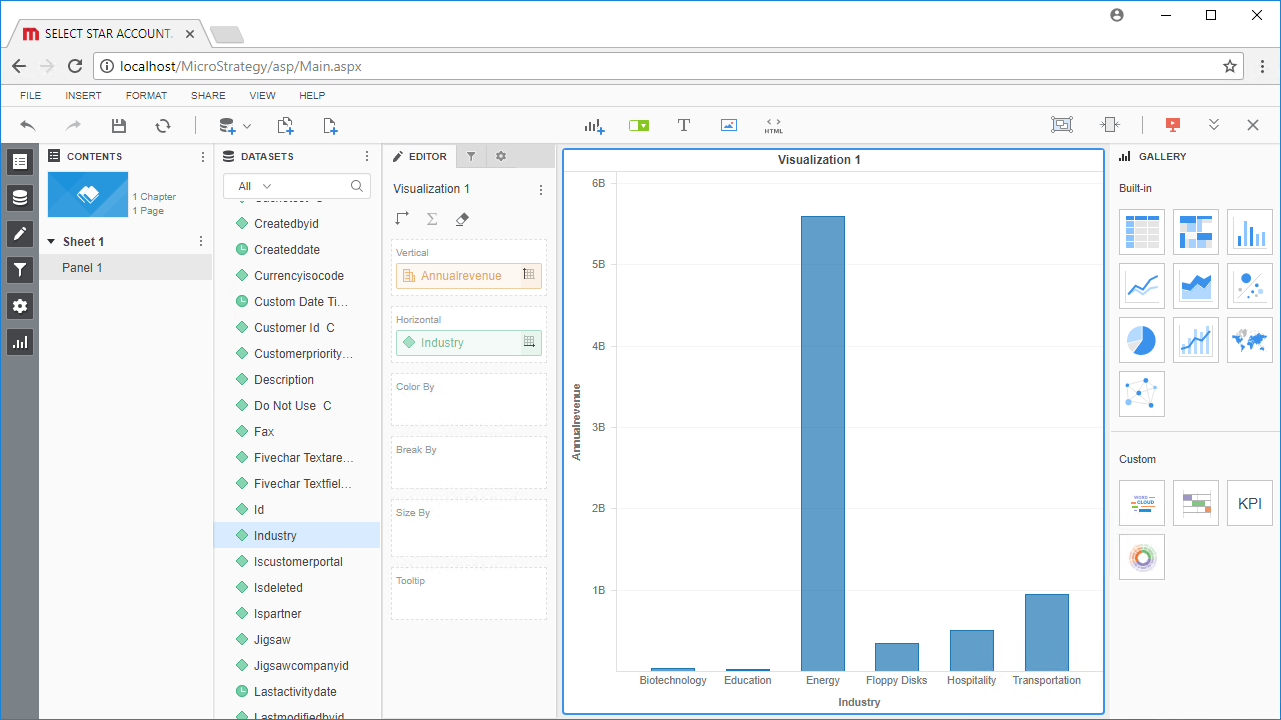
CData JDBC Driver for SparkSQL をMicroStrategy Web で使用することで、Spark データで強固なビジュアライゼーションとレポートを簡単に作成することができます。その他の例については、MicroStrategy でSpark に接続やMicroStrategy Desktop でSpark に接続をお読みください。
Note:JDBC Driver を使用して接続するには、3- または 4-Tier Architecture が必要です。



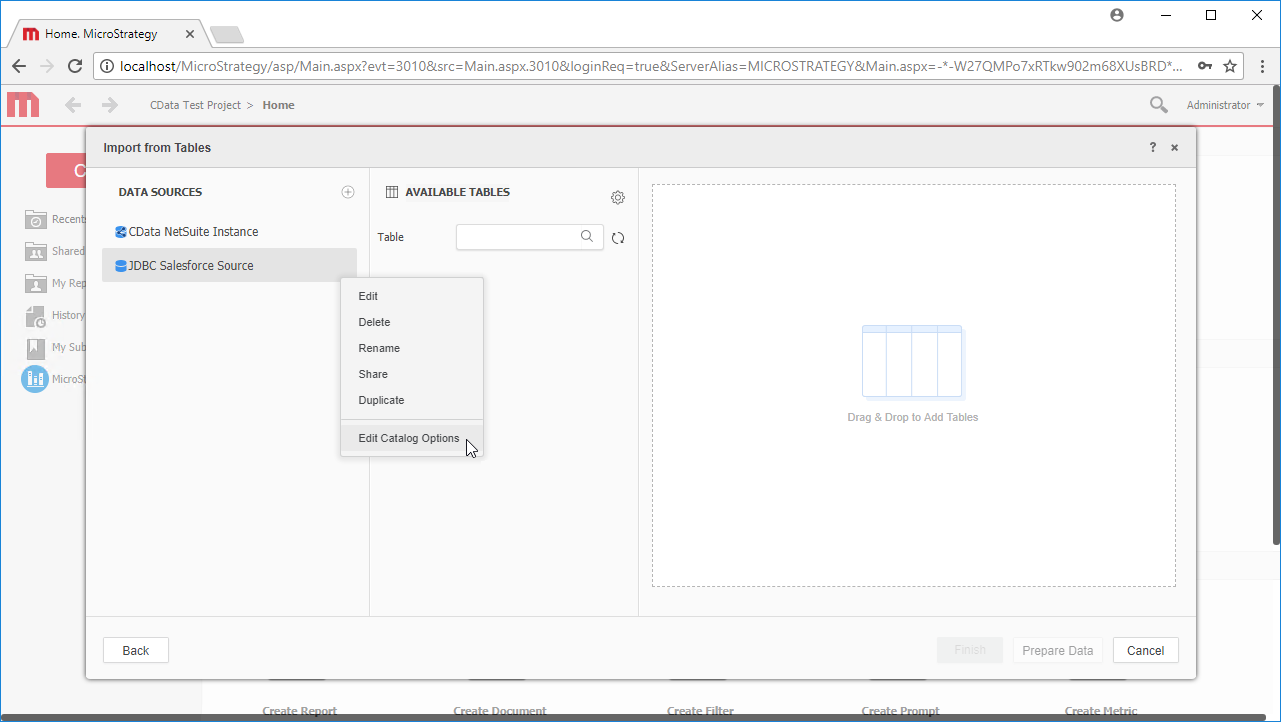
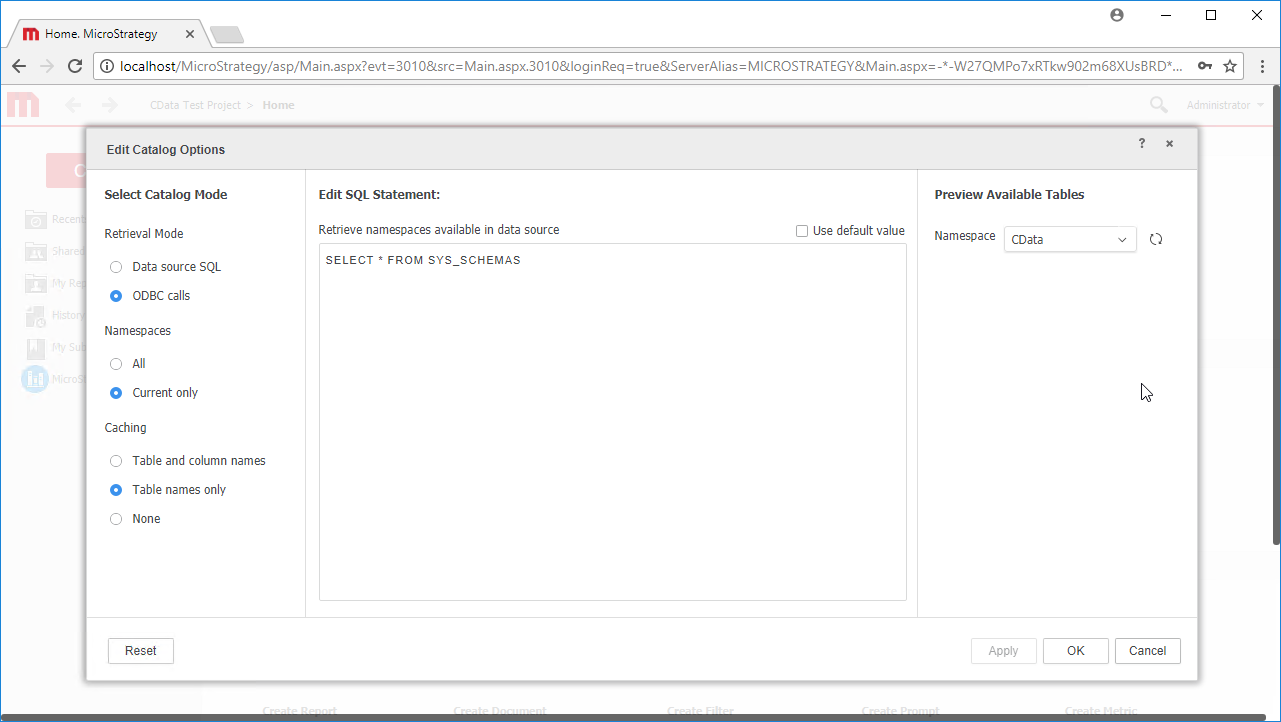
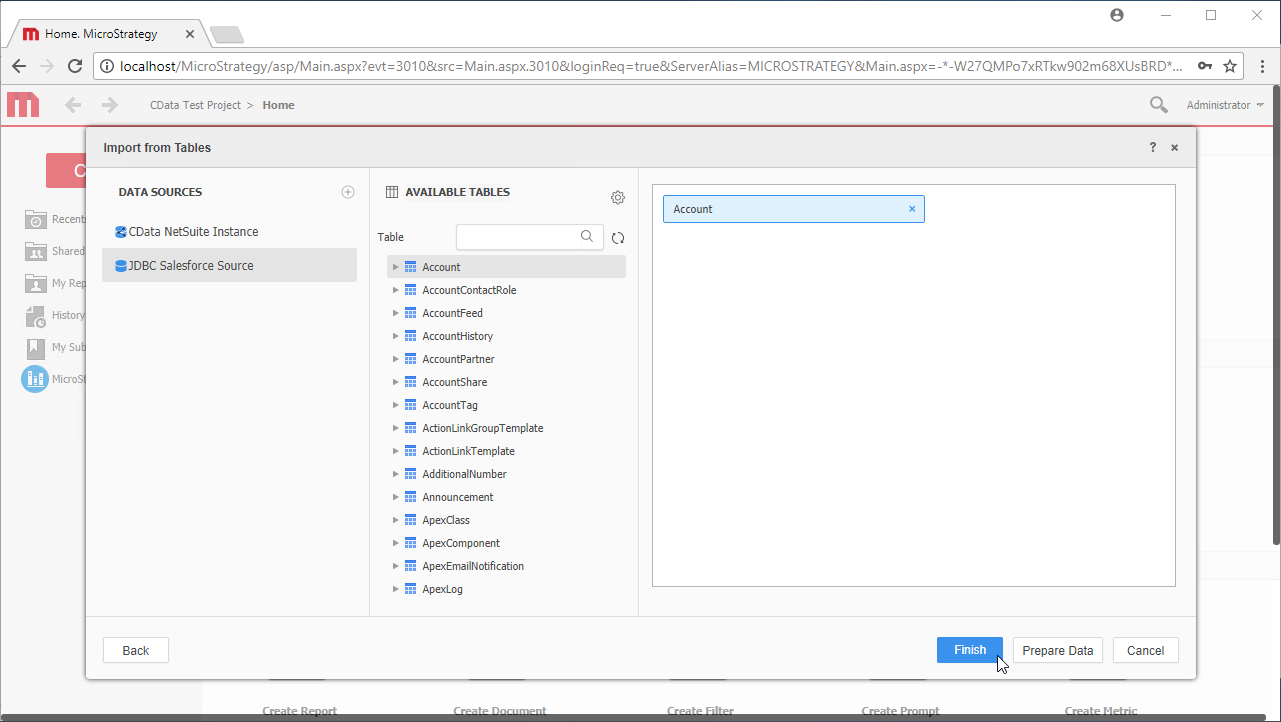 Note:ライブ接続を作成するので、テーブル全体をインポートしてMicroStrategy 製品に固有のフィルタリングおよび集計機能を利用してデータセットをカスタマイズできます。
Note:ライブ接続を作成するので、テーブル全体をインポートしてMicroStrategy 製品に固有のフィルタリングおよび集計機能を利用してデータセットをカスタマイズできます。