各製品の資料を入手。
詳細はこちら →Apache Spark Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへCData


こんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
MicroStrategy は、データ主導のイノベーションを可能にする、モビリティプラットフォームです。MicroStrategy をCData JDBC Driver for SparkSQL とペアリングすると、MicroStrategy からリアルタイムSpark へのデータベースのようなアクセスが得られ、レポート機能と分析機能が拡張されます。この記事では、MicroStrategy Developer でSpark のデータベースインスタンスを作成し、Spark のWarehouse Catalog を作成します。
CData JDBC ドライバーは、ドライバーに組み込まれた最適化されたデータ処理により、MicroStrategy でリアルタイムSpark と対話するための圧倒的なパフォーマンスを提供します。MicroStrategy からSpark に複雑なSQL クエリを発行すると、ドライバーはフィルタや集計などのサポートされているSQL 操作をSpark に直接プッシュし、組み込みSQL エンジンを利用して、サポートされていない操作(一般的にはSQL 関数とJOIN 操作) をクライアント側で処理します。組み込みの動的メタデータクエリを使用すると、ネイティブのMicroStrategy データタイプを使用してSpark を視覚化および分析できます。
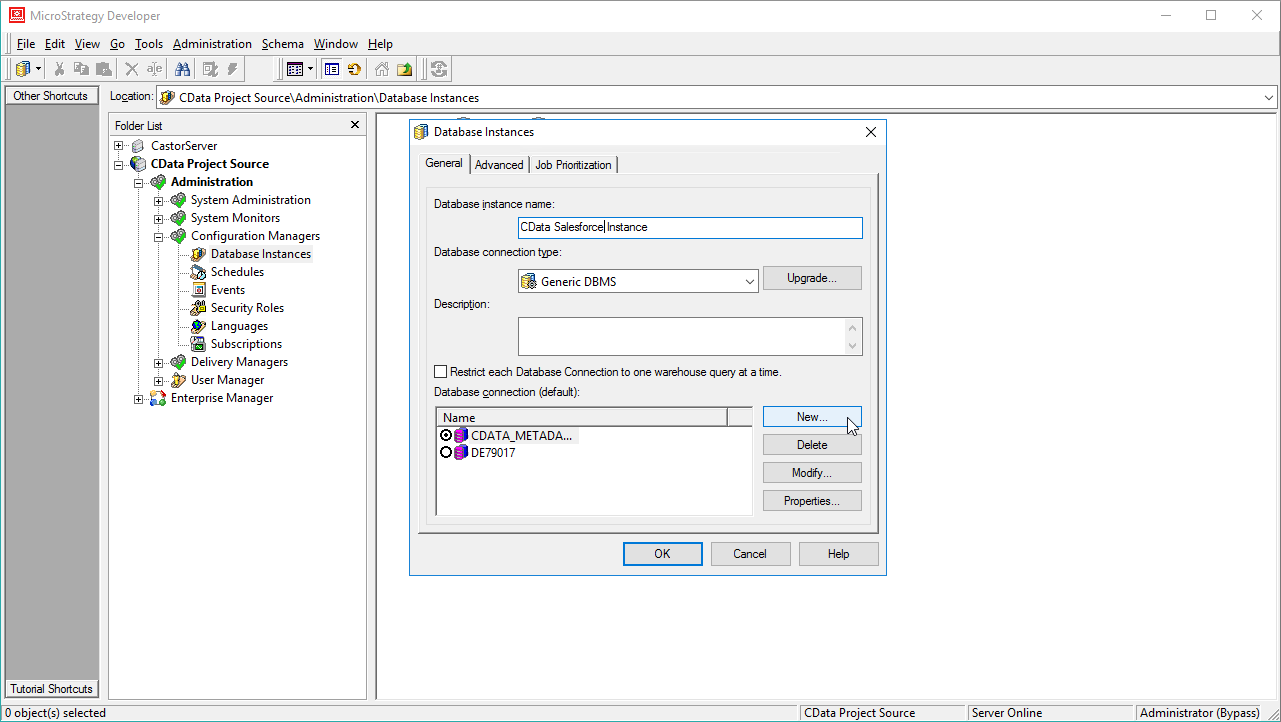
CData JDBC Driver for SparkSQL に基づくデータベースインスタンスを追加することにより、MicroStrategy Developer のSpark に接続できます。* 開始する前に、MicroStrategy Developer のインスタンスが接続されているMicroStrategy Intelligence Server をホストとするマシンにJDBC Driver for SparkSQL をインストールする必要があります。
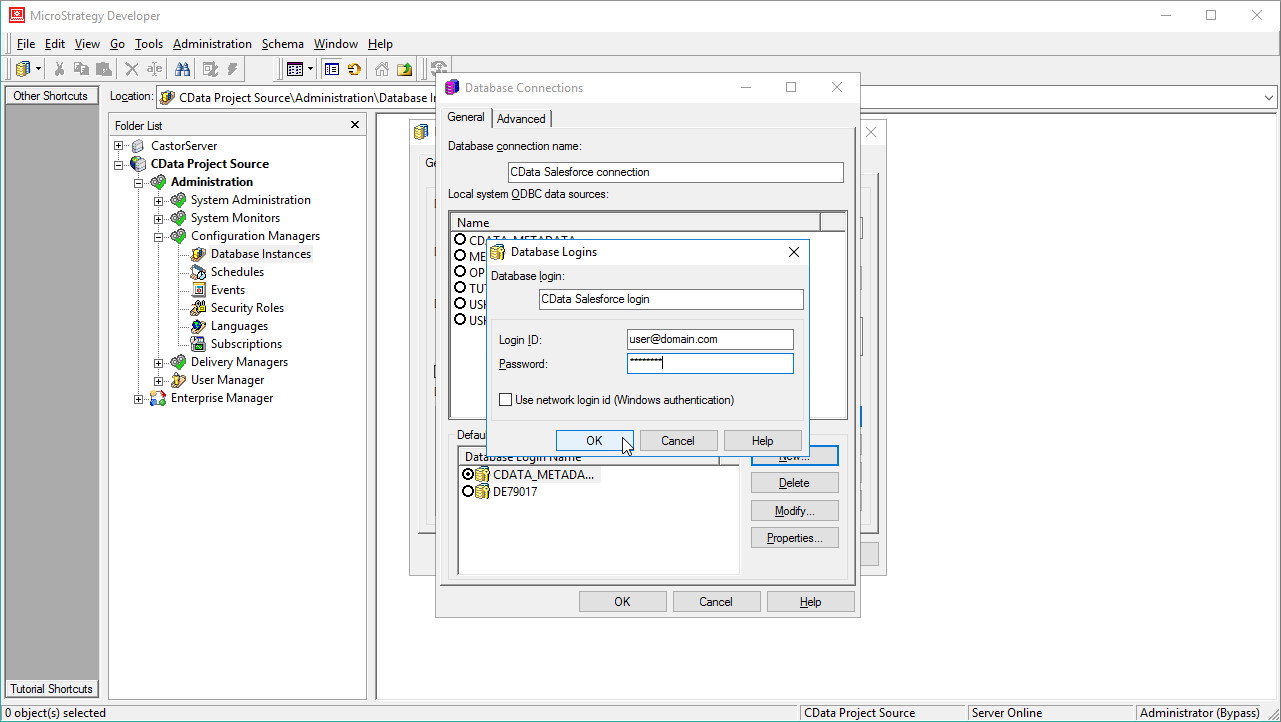
SparkSQL への接続を確立するには以下を指定します。
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
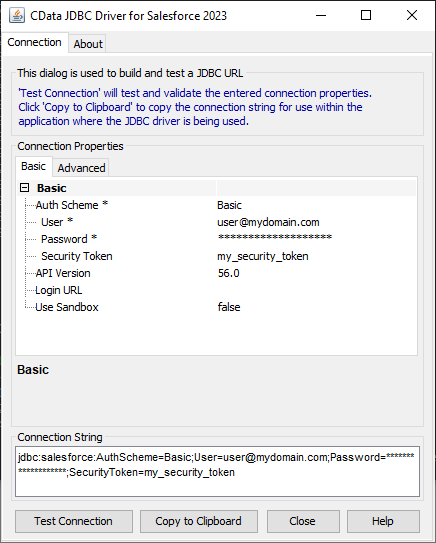
JDBC URL の構成については、Spark JDBC Driver に組み込まれている接続文字列デザイナを使用してください。JAR ファイルのダブルクリック、またはコマンドラインからJAR ファイルを実行します。
java -jar cdata.jdbc.sparksql.jar
接続プロパティを入力し、接続文字列をクリップボードにコピーします。
JDBC URL を構成する際に、Max Rows プロパティを定めることも可能です。これによって戻される行数を制限するため、可視化・レポートのデザイン設計時のパフォーマンスを向上させるのに役立ちます。
以下は、一般的な追加の接続文字列プロパティです。
JDBC;MSTR_JDBC_JAR_FOLDER=PATH\TO\JAR\;DRIVER=cdata.jdbc.sparksql.SparkSQLDriver;URL={jdbc:sparksql:Server=127.0.0.1;};
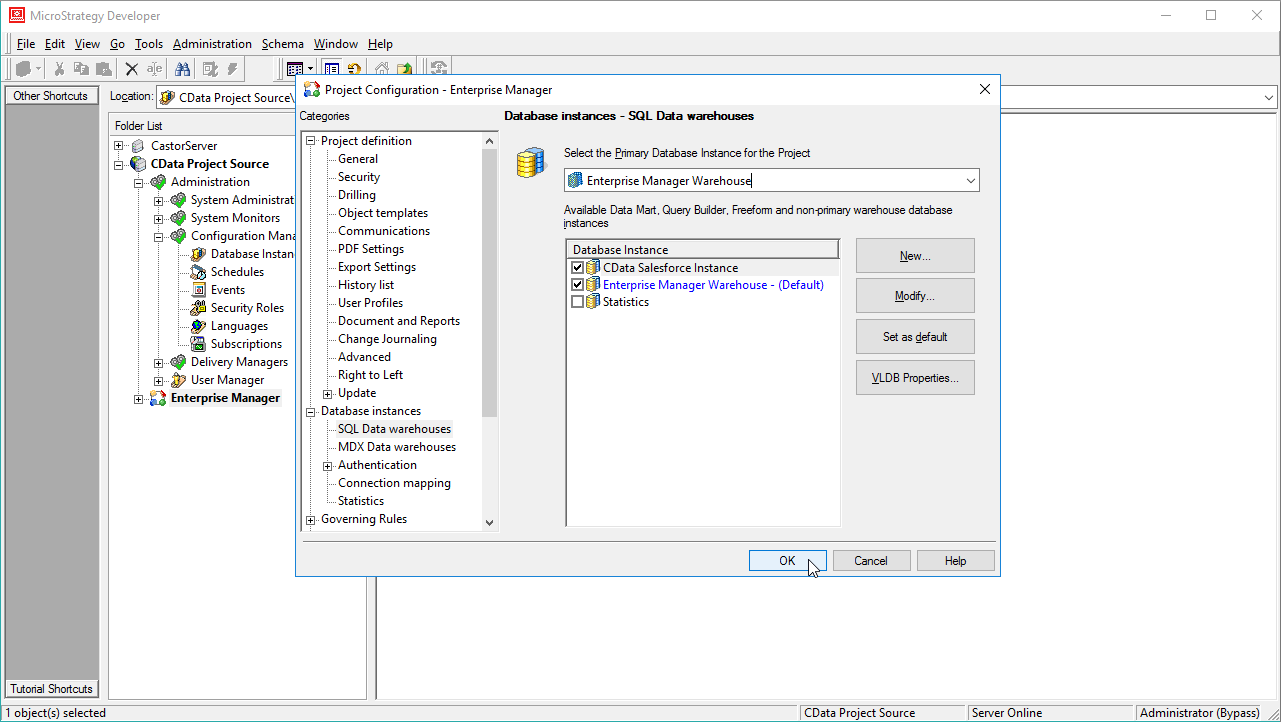
データベースインスタンスを構成すると、Warehouse Catalog およびData Import からSpark に接続できるようになります。
JDBC Driver for SparkSQL に基づいてデータベースインスタンスを作成すると、Warehouse Catalog のデータに接続できます。
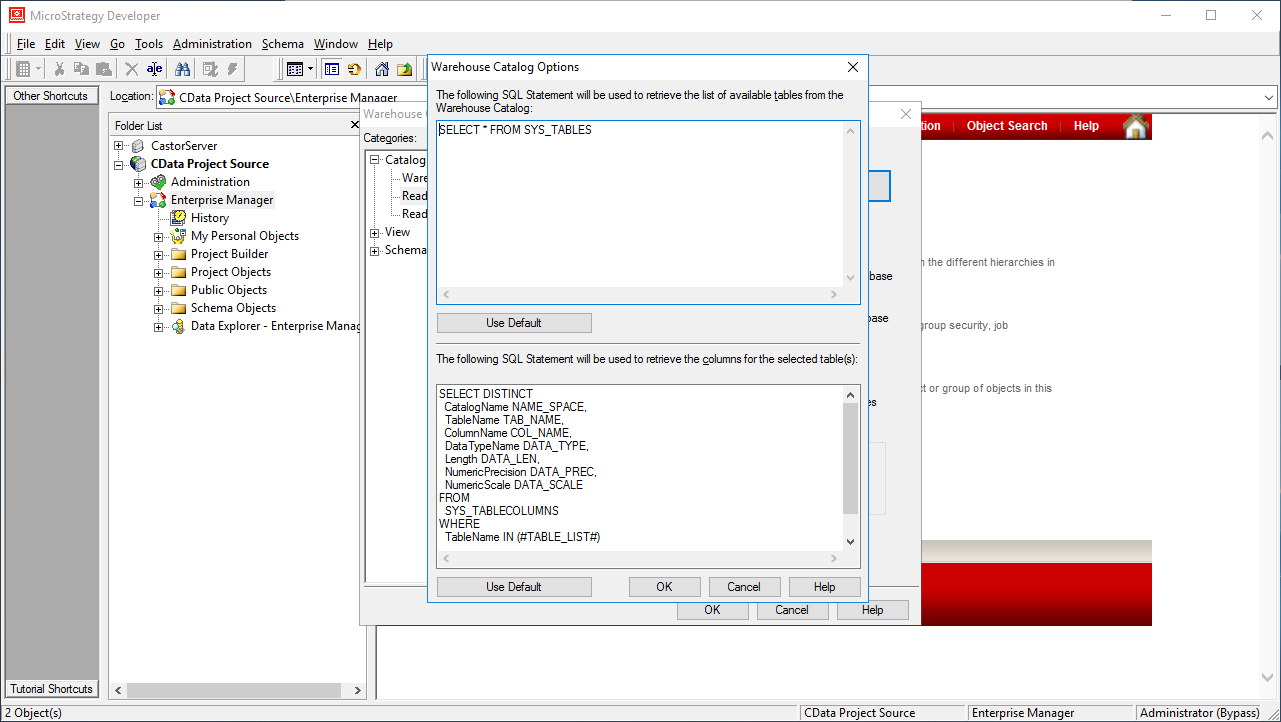
SELECT
*
FROM
SYS_TABLES
SELECT DISTINCT
CatalogName NAME_SPACE,
TableName TAB_NAME,
ColumnName COL_NAME,
DataTypeName DATA_TYPE,
Length DATA_LEN,
NumericPrecision DATA_PREC,
NumericScale DATA_SCALE
FROM
SYS_TABLECOLUMNS
WHERE
TableName IN (#TABLE_LIST#)
ORDER BY
1,2,3
MicroStrategy のCData JDBC Driver for SparkSQL を使用すると、Spark で安定したビジュアライズとレポートを簡単に作成できます。詳細については、MictroStrategy でのSpark への接続やMicroStrategy Desktop でのSpark への接続 に関するほかの記事をお読みください。
NoteJDBC Driver を使用して接続するには、3層から4層のアーキテクチャが必要です。