MicroStrategy Desktop でCData JDBC Driver を使ってSpark に接続する
CData JDBC Driver を使用してMicroStrategy Desktop のSpark に接続します。
加藤龍彦
デジタルマーケティング
最終更新日:2023-10-04
こんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
MicroStrategy は、データ主導のイノベーションを可能にする、モビリティプラットフォームです。MicroStrategy をCData JDBC Driver for SparkSQL とペアリングすると、MicroStrategy からリアルタイムSpark へのデータベースのようなアクセスが得られ、レポート機能と分析機能が拡張されます。この記事では、MicroStrategy Desktop にデータソースとしてSpark を追加し、Spark の簡単なヴィジュアライゼーションを作成する方法について説明します。
CData JDBC ドライバーは、ドライバーに組み込まれた最適化されたデータ処理により、MicroStrategy でリアルタイムSpark と対話するための比類のないパフォーマンスを提供します。MicroStrategy からSpark に複雑なSQL クエリを発行すると、ドライバーはフィルタや集計などのサポートされているSQL 操作をSpark に直接プッシュし、組み込みSQL エンジンを利用して、サポートされていない操作(一般的にはSQL 関数とJOIN 操作) をクライアント側で処理します。組み込みの動的メタデータクエリを使用すると、ネイティブのMicroStrategy データタイプを使用してSpark を視覚化および分析できます。
MicroStrategy Desktop を使用してSpark データに接続および視覚化する
MicroStrategy エンタープライズ製品のSpark に接続するだけでなく、MicroStrategy Desktop のSpark に接続することもできます。以下のステップに従って、JDBC を使用してSpark をデータセットとして追加し、Spark の視覚化とレポートを作成します。
- MicroStrategy Desktop を開き、新しいドシエを作成します。
- データセットパネルで[New Data]をクリックし、[Databases]を選択して[Import Option]として[Select a Table]を選択します。
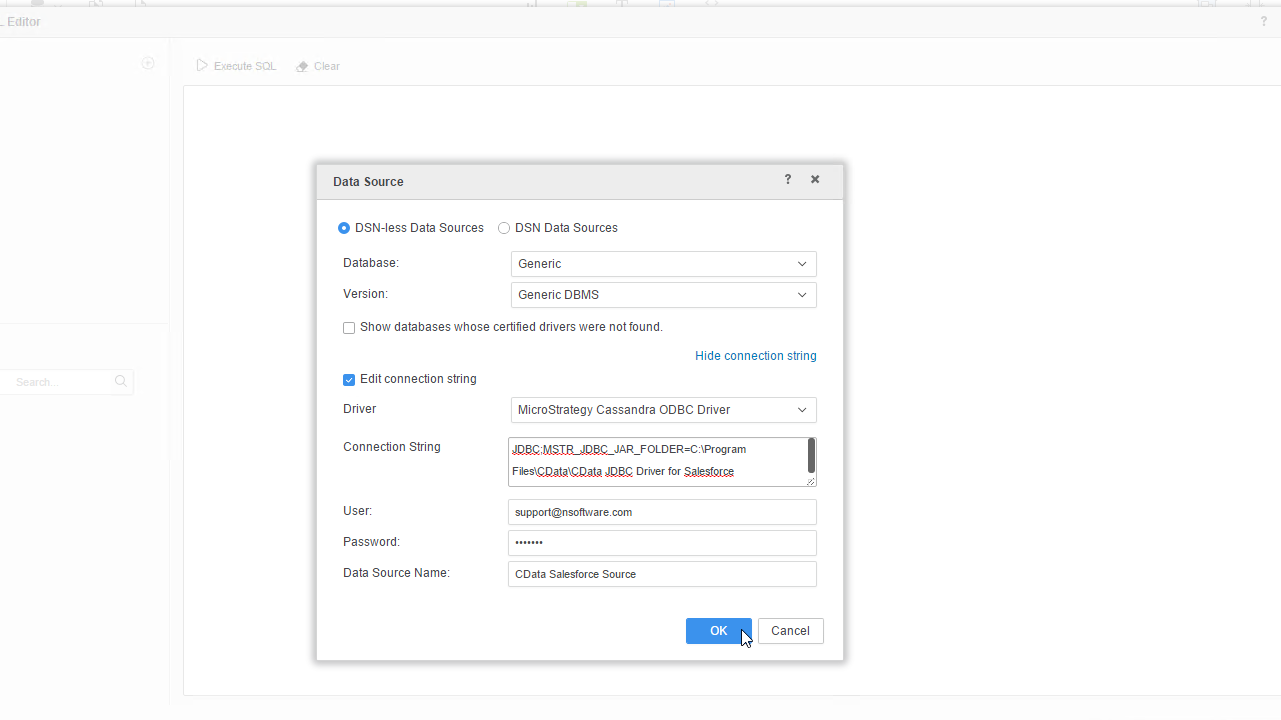
- 新しいデータソースを追加し、DSN レスデータソースオプションを選択します。
- [Database]メニューで[Generic]を、[Version]メニューで[Generic DBMS]を選択します。
- リンクをクリックして接続文字列を表示し、接続文字列を選択して編集します。[Driver]メニューで[MicroStrategy Cassandra ODBC Driver]を選択します。(MicroStrategy では、JDBC を介してインターフェースするために認定ドライバーが必要です。実際のドライバーは使用されません。)
- 接続文字列を以下のように設定し、[OK]をクリックします。
- JDBC キーワードを接続文字列に追加します。
- MSTR_JDBC_JAR_FOLDER をJDBC ドライバーJAR ファイルのパスに設定します。(C:\Program Files\CData JDBC Driver for SparkSQL\lib\ on Windows.)
- DRIVER をドライバークラスであるcdata.jdbc.sparksql.SparkSQLDriver に設定します。
- URL をSpark のJDBC URL に設定し、必要な接続プロパティを設定します。
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、
「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
ビルトイン接続文字列デザイナ
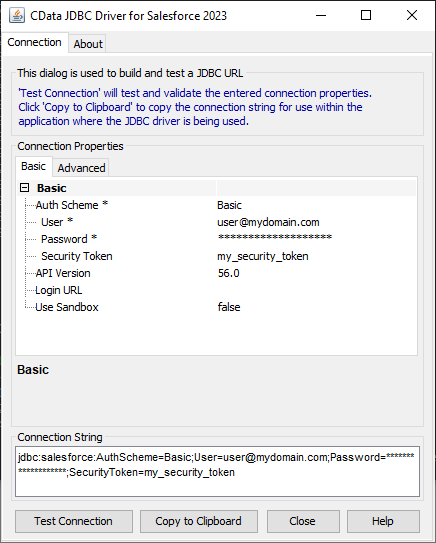
JDBC URL の構成については、Spark JDBC Driver に組み込まれている接続文字列デザイナを使用してください。JAR ファイルのダブルクリック、またはコマンドラインからJAR ファイルを実行します。
java -jar cdata.jdbc.sparksql.jar
接続プロパティを入力し、接続文字列をクリップボードにコピーします。
![Using the built-in connection string designer to generate a JDBC URL (Salesforce is shown.)]()
JDBC URL を構成する際に、Max Rows プロパティを定めることも可能です。これによって戻される行数を制限するため、可視化・レポートのデザイン設計時のパフォーマンスを向上させるのに役立ちます。
以下は一般的な接続文字列です。
JDBC;MSTR_JDBC_JAR_FOLDER=PATH\TO\JAR\;DRIVER=cdata.jdbc.sparksql.SparkSQLDriver;URL={jdbc:sparksql:Server=127.0.0.1;};
![Creating a new data source for Spark.]()
- 新しいデータソースを右クリックし、[Edit catalog]オプションを選択します。
- SQL ステートメントをSELECT * FROM SYS_SCHEMAS に編集し、JDBC ドライバーからメタデータを読み取ります。
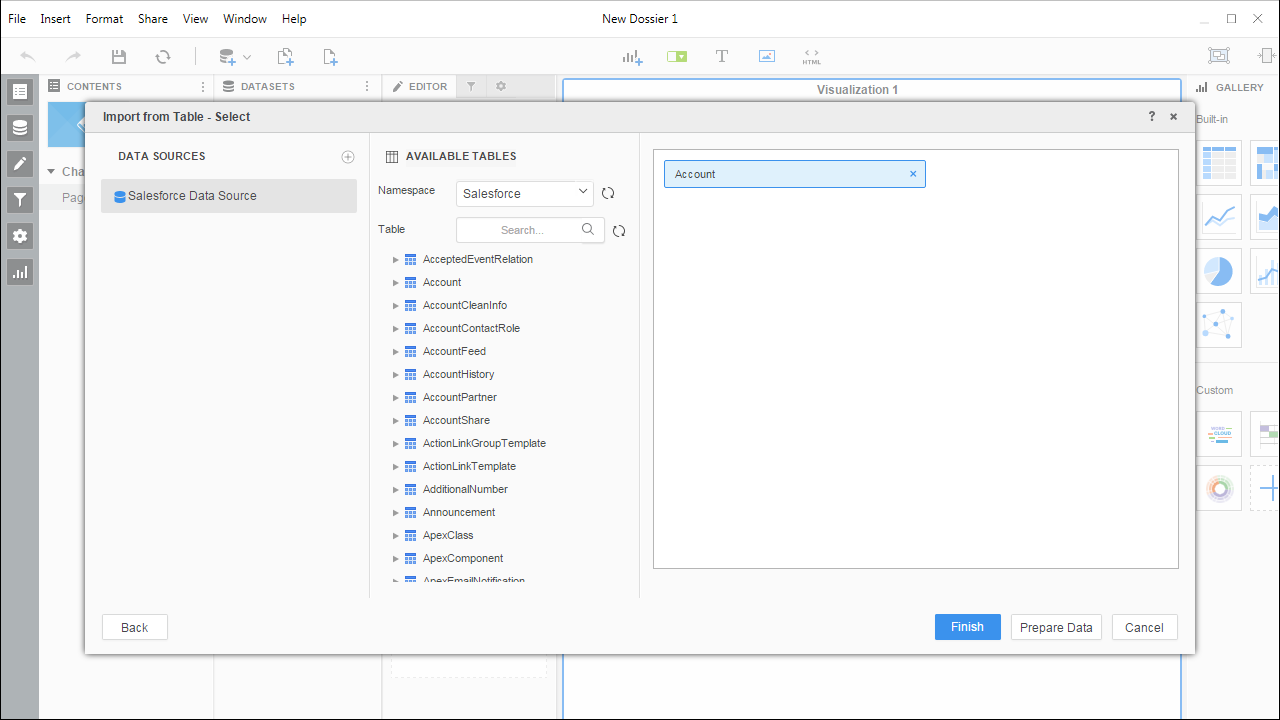
- 新しいデータソースを選択し、使用可能なテーブルを表示します。テーブルを表示するには、[Available Tables]セクションの検索アイコンを手動でクリックする必要がある場合があります。
- テーブルをペインにドラッグしてインポートします。
![Select tables to import.]() Noteライブ接続を作成するため、テーブル全体をインポートしてMicroStrategy 製品に固有のフィルタリングおよび集計機能を利用できます。
Noteライブ接続を作成するため、テーブル全体をインポートしてMicroStrategy 製品に固有のフィルタリングおよび集計機能を利用できます。
- [Finish]をクリックし、ライブに接続するオプションを選択します。CData JDBC Drivers のネイティブな高性能データ処理のおかげで、効果的なライブ接続が可能です。
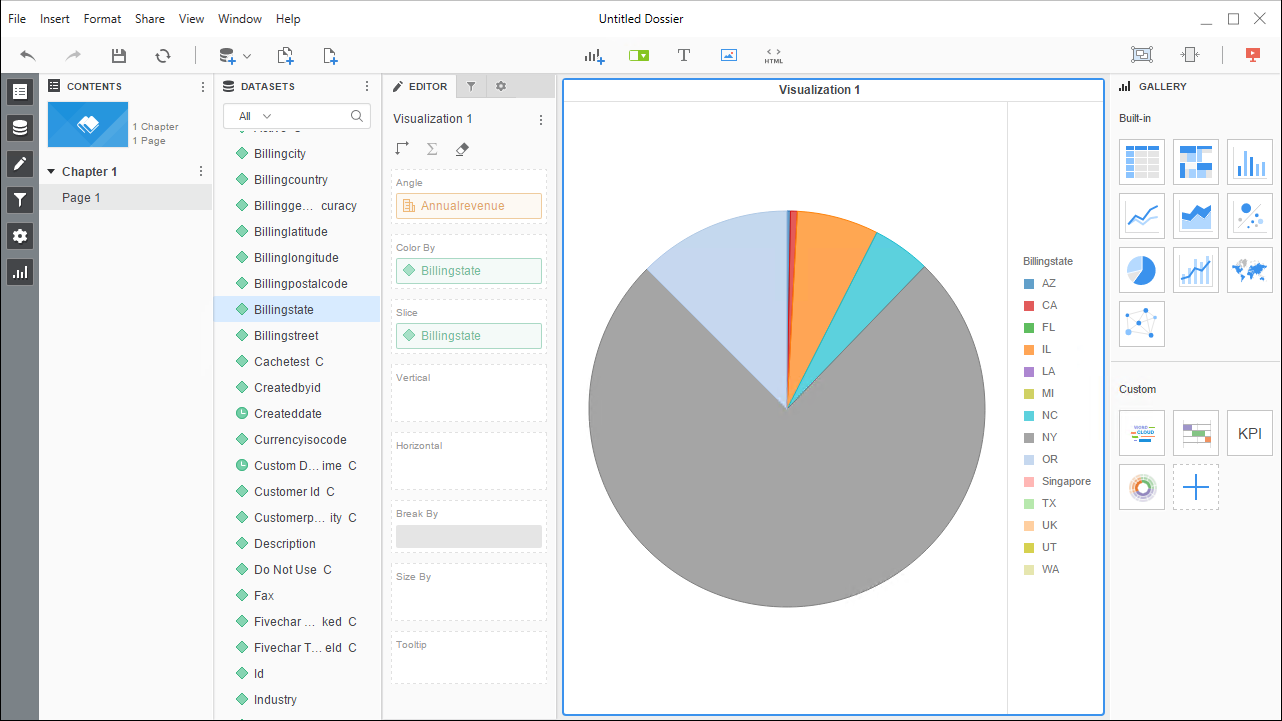
- ビジュアライゼーションと表示するフィールドを選択し、フィルタを適用してSpark の新しいビジュアライゼーションを作成します。データタイプは、動的メタデータ検出によって自動的に検出されます。可能な場合、フィルタと集計によって生成された複雑なクエリはSpark にプッシュダウンされ、サポートされていない(SQL 関数とJOIN 操作を含み得る) 操作は、ドライバーに埋め込まれているCData SQL エンジンによってクライアント側で管理されます。
![Visualize Spark データ.]()
- ドシエの構成が完了したら、[File]->[Save]をクリックします。
MicroStrategy Desktop のCData JDBC Driver for SparkSQL を使用すると、Spark で安定したビジュアライゼーションとレポートを簡単に作成できます。その他の例については、MicroStrategy Developer のSpark に接続 やMicroStrategy Web のSpark に接続 などの記事をお読みください。
関連コンテンツ



 Noteライブ接続を作成するため、テーブル全体をインポートしてMicroStrategy 製品に固有のフィルタリングおよび集計機能を利用できます。
Noteライブ接続を作成するため、テーブル全体をインポートしてMicroStrategy 製品に固有のフィルタリングおよび集計機能を利用できます。