こんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
Informatica Cloud を使うと、抽出、変換、読み込み(ETL)のタスクをクラウド上で実行できます。Cloud Secure Agent およびCData JDBC Driver for SparkSQL を組み合わせると、Informatica Cloud で直接Spark のデータにリアルタイムでアクセスできます。この記事では、Cloud Secure Agent のダウンロードと登録、JDBC ドライバーを経由したSpark への接続、そしてInformatica Cloud の処理で使用可能なマッピングの生成について紹介します。
Informatica Cloud Secure Agent
JDBC ドライバー経由でSpark のデータを操作するには、Cloud Secure Agent をインストールします。
- Informatica Cloud の「管理者」ページに移動します。
![]()
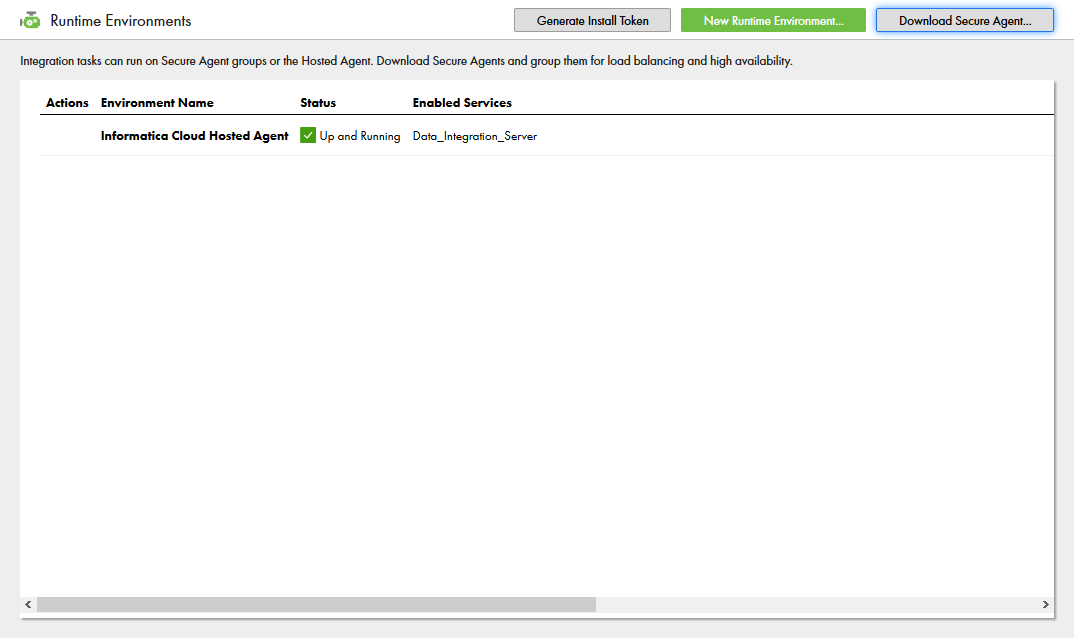
- 「ランタイム環境」タブを選択します。
- 「Secure Agent のダウンロード」をクリックします。
![]()
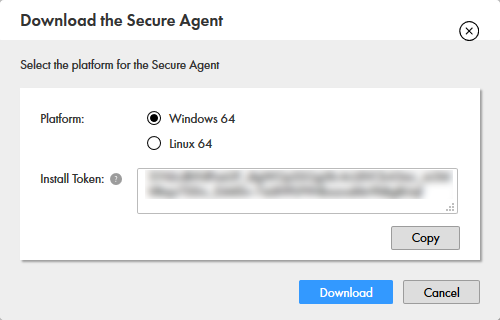
- 「インストールトークン」の文字列を控えておきます。
![]()
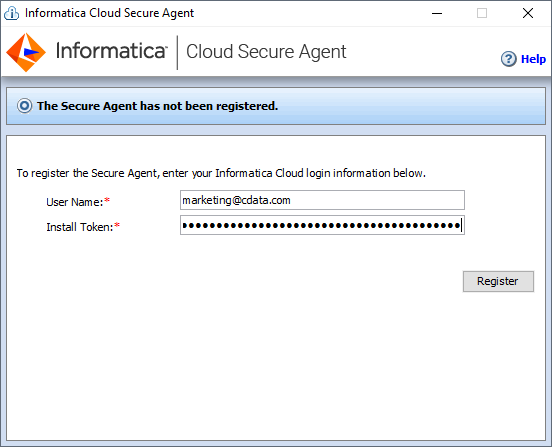
- クライアントマシンでインストーラーを実行し、ユーザー名とインストールトークンを入力してCloud Secure Agent を登録します。
![]()
NOTE:Cloud Secure Agent の全サービスが立ち上がるまで、時間がかかる場合があります。
Spark JDBC Driver への接続
Cloud Secure Agent をインストールして実行したら、JDBC ドライバーを使ってSpark に接続できるようになります。はじめに「接続」タブをクリックし、続けて「新しい接続」をクリックします。接続するには次のプロパティを入力します。
- 接続名:接続の名前を入力(例:CData Spark Connection)。
- タイプ:「JDBC_IC (Informatica Cloud)」を選択。
- ランタイム環境:Cloud Secure Agent をインストールしたランタイム環境を選択。
- JDBC 接続URL:Spark のJDBC URL に設定。URL は次のようになります。
jdbc:sparksql:Server=127.0.0.1;
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、
「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
組み込みの接続文字列デザイナー
JDBC URL の作成の補助として、Spark JDBC Driver に組み込まれている接続文字列デザイナーが使用できます。.jar ファイルをダブルクリックするか、コマンドラインから.jar ファイルを実行します。
java -jar cdata.jdbc.sparksql.jar
接続プロパティを入力し、接続文字列をクリップボードにコピーします。
![Using the built-in connection string designer to generate a JDBC URL (Google Sheets is shown.)]()
- JDBC Jar ディレクトリ:JDBC ドライバーがインストールされたディレクトリ(Windows の場合、デフォルトではC:\Program Files\CData\CData JDBC Driver for SparkSQL\)直下のlib フォルダに設定。
- JDBC Driver Class Name:cdata.jdbc.sparksql.SparkSQLDriver に設定。
- ユーザー名:プレースホルダーの値に設定(Spark がユーザー名を必要としないため)。
- パスワード:プレースホルダーの値に設定(Spark がパスワードを必要としないため)。
![Configuring the Connection (Google Sheets is shown.]()
Spark のデータマッピングの作成
Spark への接続設定が完了し、Informatica のどのプロセスでもSpark のデータにアクセスできるようになりました。以下の手順で、Spark から別のデータターゲットへのマッピングを作成します。
- 「データ統合」ページに移動します。
![]()
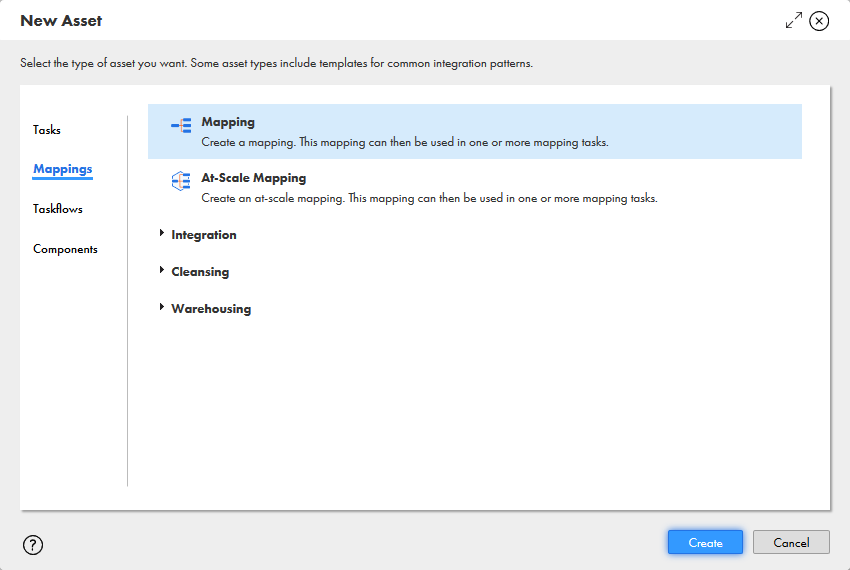
- 「新規」をクリックし、「マッピング」タブを開くと表示される「マッピング」を選択します。
![]()
- 「ソース」ノードをクリックし、表示されるプロパティの「ソース」タブで「接続」と「ソースタイプ」を設定します。
![Selecting the Source Connection and Source Type]()
- 「選択」をクリックして、表示されるテーブル一覧からマッピングするテーブルを選択します。
![Selecting the Source Object]()
- 「フィールド」タブで、Spark テーブルからマッピングするフィールドを選択します。
![Selecting Source Fields to map]()
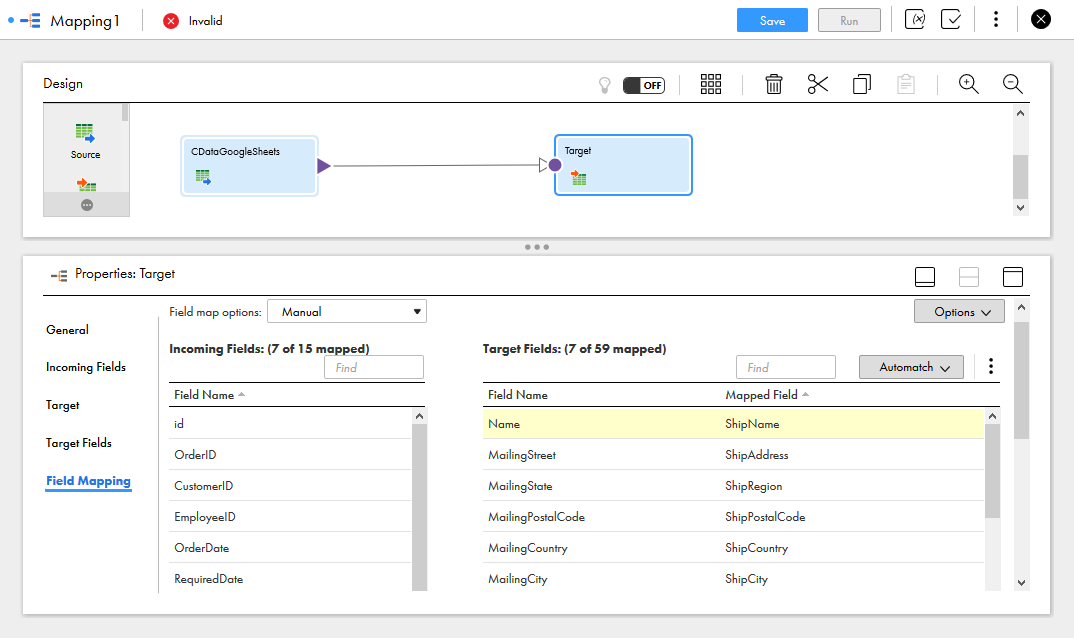
- 「ターゲット」ノードをクリックし、ターゲットソース、テーブル、およびフィールドを設定します。「フィールドマッピング」タブで、ソースフィールドをターゲットフィールドにマッピングします。
![Selecting the Target Field Mappings]()
マッピングの設定が完了し、Informatica Cloud でサポートされている接続とリアルタイムSpark のデータの統合を開始する準備ができました。CData JDBC Driver for SparkSQL の30日の無償評価版をダウンロードして、今日からInformatica Cloud でリアルタイムSpark のデータの操作をはじめましょう!