FineReport にSpark のデータを連携してビジュアライズ・レポートを作成
Spark を帳票ツールのFineReport からデータソースとして設定する方法。
桑島義行
テクニカルディレクター
最終更新日:2022-11-02
CData

こんにちは!テクニカルディレクターの桑島です。
CData JDBC Driver for SparkSQL は、JDBC 標準に準拠しており、BI ツールからIDE まで幅広いアプリケーションでSpark へのデータ連携を提供します。FineReport は中国BI ベンダー最大手の帆軟軟件(ファンランソフトウェア)が開発&販売する帳票とBIダッシュボード開発プラットフォームです。
この記事では、帳票ツールのFineReport からSpark] に連携する方法を説明します。
Spark のデータのJDBC データソースを作成
下記の手順に従って、FineReport からSpark にデータベース接続として繋ぎます。
- FineReport の「\FineReport_10.0\webapps\webroot\WEB-INF\lib」ディレクトリにCData JDBC ドライバインストールディレクトリの「lib」サブフォルダ内のcdata.jdbc.sparksql.jar ファイルをコピーして配置します。製品版の場合には.lic ファイルも同様に配置します。
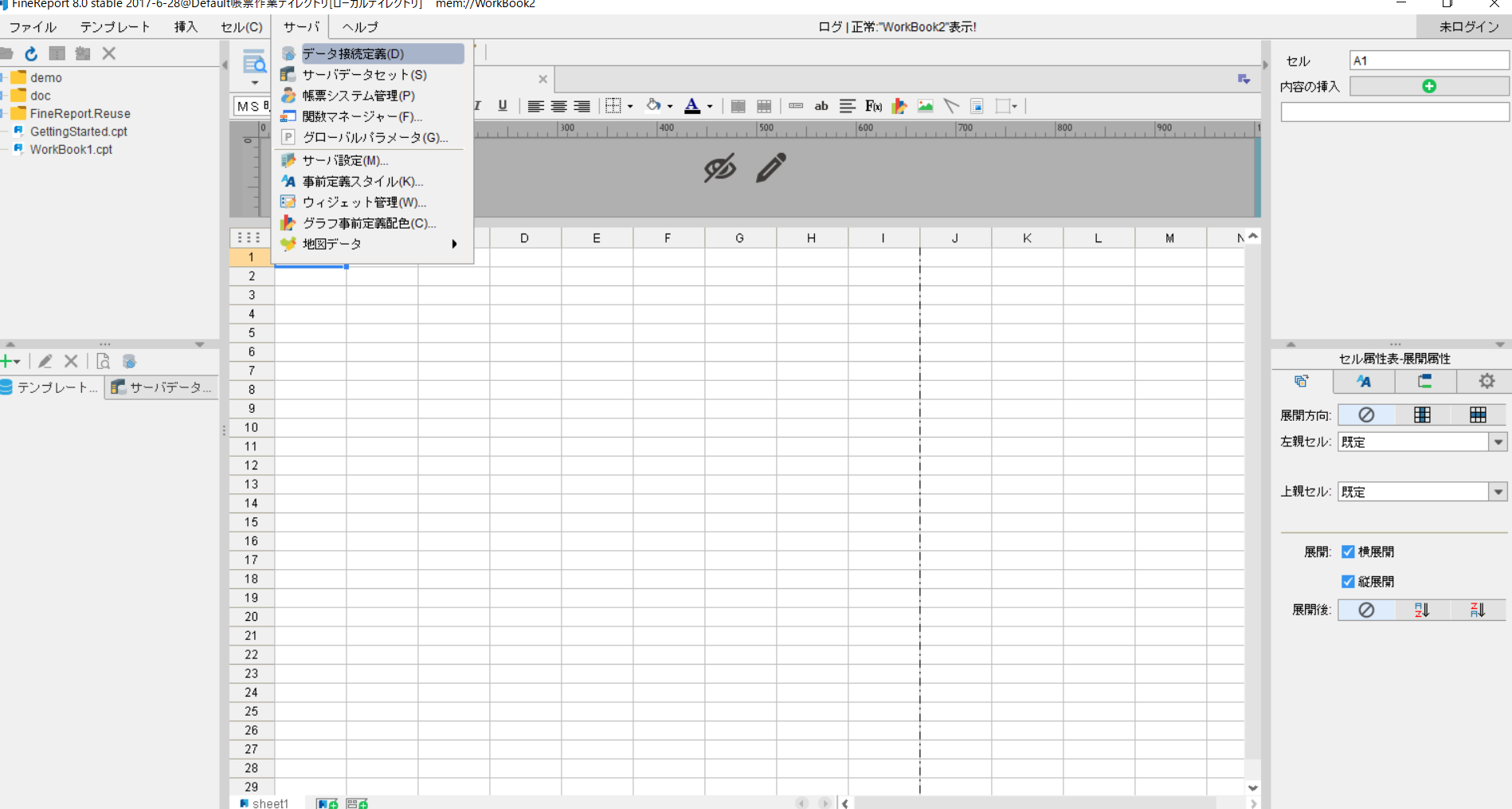
- FineReport の帳票デザイナーを起動します。[サーバ]タブから[データ接続定義]をクリックし、[JDBC]を選択します。
![FineReport サーバタブ]()
開いたデータ接続定義ウィンドウで接続を確立します。
- データベース:Other
- JDBC ドライバ:cdata.jdbc.sparksql.SparkSQLDriver
-
URL: jdbc:sparksql: に続けてセミコロン区切りで接続プロパティを入力します。
一般的なJDBC URL は次の通りです:
jdbc:sparksql:Server=127.0.0.1;
![FineReport データ接続定義ウィンドウ]()
- [接続プール属性]をクリックして、[接続の貸出前に接続有効性を検証]の属性項目を[なし]に変更します。
![FineReport 接続プール属性]()
データ接続定義ウィンドウ上部の[接続テスト]をクリックします。これでSpark のデータへの接続が確立され、FineReport 上で仮想RDB としてデータを連携利用することができるようになりました。
Spark のデータを実際にデザイナで抽出(Select)してレポートで使ってみる
- 左下ペインの+印をクリックし、[データベースクエリ]を選択します。データベースクエリウィンドウが開きます。
- 左上のドロップダウンリストで先ほど作成したJDBC 接続を選択します。
- 左ペインにSpark のエンドポイントがそれぞれテーブルとして表示されます。
![FineReport データベースクエリ]()
- Spark のデータの表示されているテーブルから抽出するテーブル・カラムを指定してSelect 文を書きます。
- プレビューをクリックするとデータがテーブル状で取得され、表示されます。
![FineReport データベースクエリプレビュー]()
- 作成したデータセットを利用してダッシュボードを作成していきます。
![FineReport のダッシュボード]()
このようにSpark 内のデータをAPI を書くことなくFineReport上で連携利用することができるようになります。
関連コンテンツ