Spark データをDataSpider Servista の連携先として使う方法
CData JDBC ドライバを使って、データ連携ツールのDataSpider Servista からSpark データを連携利用する方法を解説。
杉本和也
リードエンジニア
最終更新日:2023-09-07
CData

こんにちは!リードエンジニアの杉本です。
DataSpider Servista は、異なるシステムのデータやアプリケーションをノンプログラミングで「つなぐ」データインテグレーションプラットフォームです。
CData JDBC ドライバはDataSpider Servista において、JDBC データソースとして利用することが可能です。通常のJDBC の検索・更新などのアイコンを使って、標準SQL でSaaS/Web DB のデータを扱うことを可能にします。
この記事では、DataSpider で CData JDBC Driverを利用してSpark データに外部データとしてSQL でアクセスする方法を紹介します。
CData JDBC Driver for SparkSQL をDataSpider にコネクタとして登録
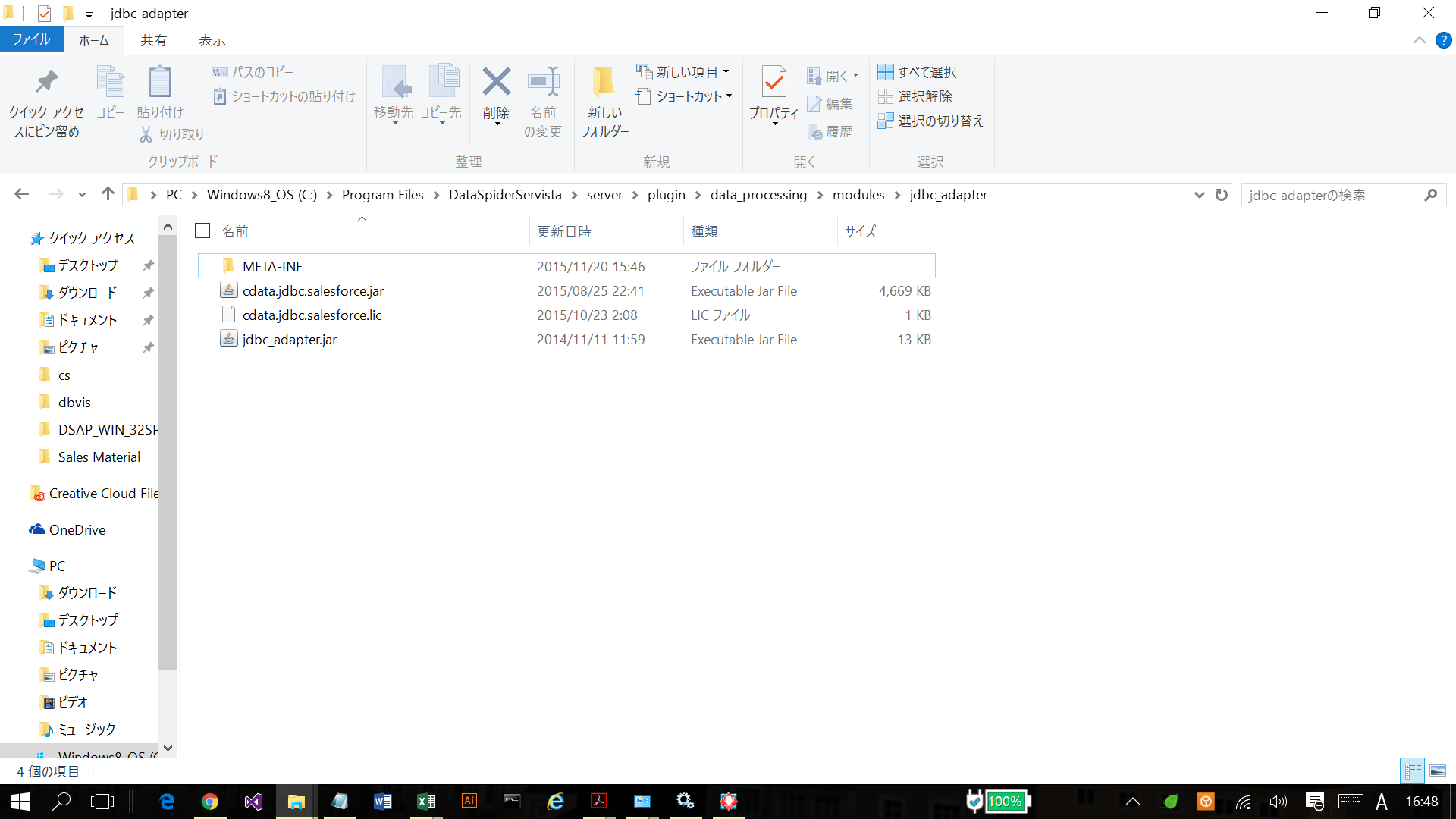
- JDBC Driver をDataSpider と同じサーバーにインストール
- DataSpider の外部JDBCドライバのパスにCData JDBC ドライバのcdata.jdbc.sparksql.jar とcdata.jdbc.sparksql.lic を配置
DataSpider 側:DataSpiderServista\server\plugin\data_processing\modules\jdbc_adapter
![DataSpider]()
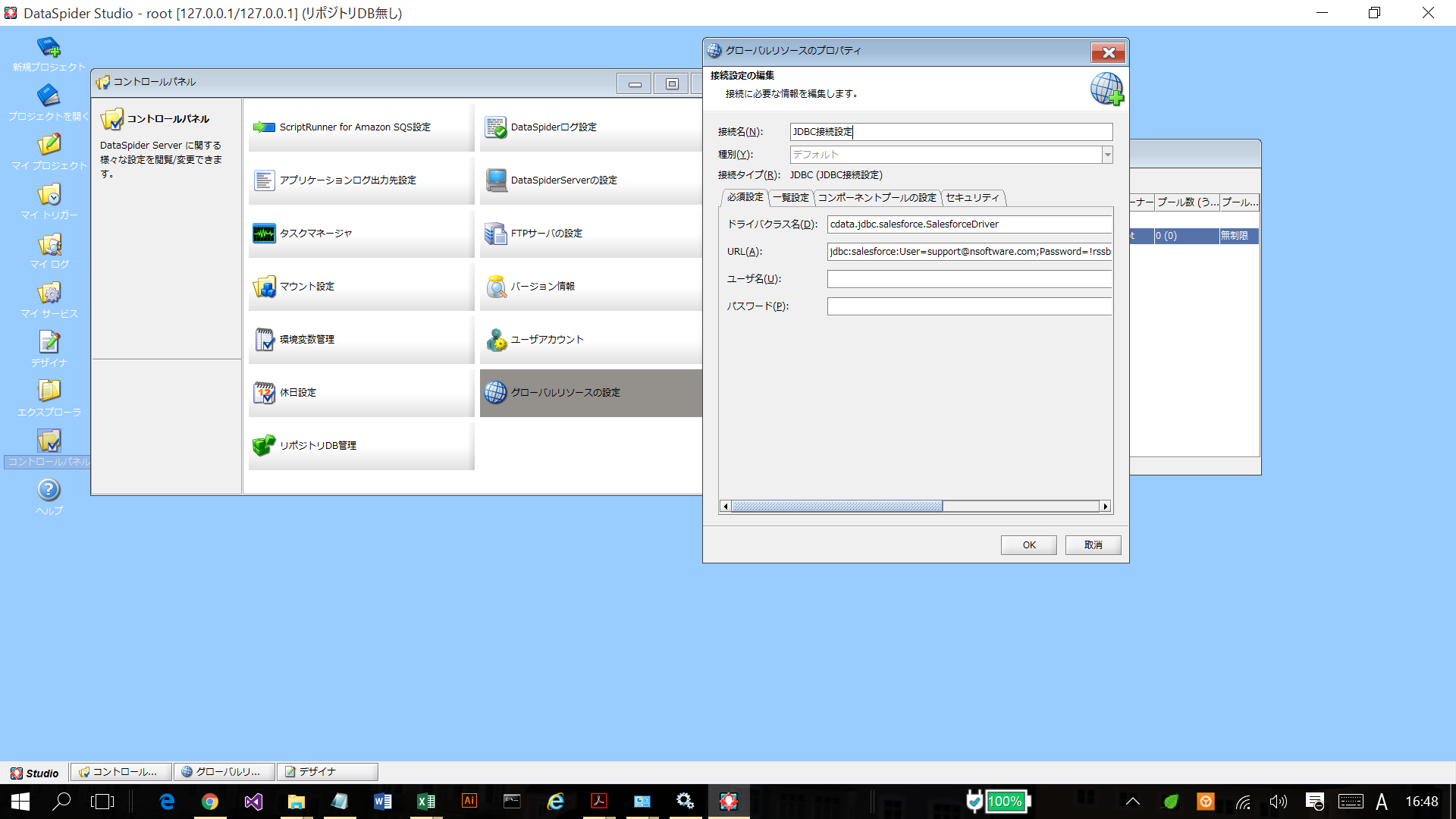
- グローバルリソースのプロパティで、ドライバクラス名およびURL を入力。
- 接続名:任意
- 種別:デフォルト
- 接続タイプ:接続タイプ:JDBC(JDBC接続設定)
- ドライバクラス名:cdata.jdbc.sparksql.SparkSQLDriver
- URL:jdbc:sparksql:Server=127.0.0.1;
-
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、
「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
![DataSpider]()
DataSpider でSpark データを連携利用する
あとは通常のRDB コンポーネントのように、Spark データを扱うことが可能です。ツールパレットのJDBC からSQL 実行やストアドプロシージャ実行コンポーネントが使用できます。
![DataSpider]()
例えばSpark データの取得であれば、検索系SQL実行処理を使って、SELECT 文でSpark データを抽出することができます。
このようにCData JDBC ドライバを使って、簡単にDataSpider でSpark データ データをノーコードで連携利用することができます。
CData JDBC Driver for SparkSQL 30日の無償評価版 をダウンロードして、お試しください。
関連コンテンツ