こんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
Oracle Data Integrator(ODI)はOracle エコシステムのハイパフォーマンスなデータ統合プラットフォームです。CData JDBC Driver for ApacheHive を使えば、OCI をはじめとするETL ツールからHive データにJDBC 経由で簡単に読み取りと書き込みを実現できます。リアルタイムHive データをデータウェアハウス、BI・帳票ツール、CRM、基幹システムなどに統合すれば、データ活用もぐっと楽に。
CData のコネクタを使えば、Hive API にリアルタイムで直接接続して、ODI 上で通常のデータベースと同じようにHive データを操作できます。Hive エンティティのデータモデルを構築、マッピングを作成し、データの読み込み方法を選択するだけの簡単なステップでHive データのETL が実現できます。
ドライバーのインストール
ドライバーをインストールするには、インストールフォルダにあるドライバーのJAR ファイルと.lic ファイルをODI の適切なディレクトリにコピーします。
- UNIX/Linux(Agent なし):~/.odi/oracledi/userlib
- UNIX/Linux(Agent):$ODI_HOME/odi/agent/lib
- Windows(Agent なし):%APPDATA%\Roaming\odi\oracledi\userlib
- Windows(Agent):%APPDATA%\Roaming\odi\agent\lib
ODI を再起動してインストールを完了します。
モデルのリバースエンジニアリング
ODI の機能を使ってモデルをリバースエンジニアリングすることで、ドライバー側で取得したHive データのリレーショナルビューに関するメタデータが取得できます。リバースエンジニアリング後、リアルタイムHive データにクエリを実行してHive テーブルのマッピングを作成できます。
-
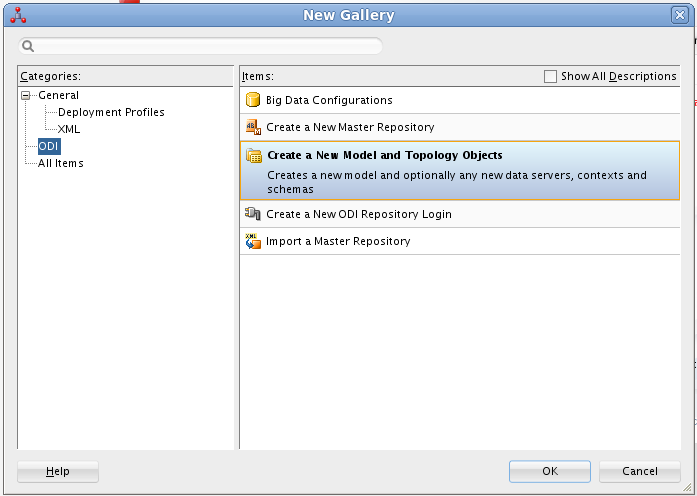
ODI でリポジトリに接続し、「New」->「Model and Topology Objects」をクリックします。
![新しいモデルを作成]()
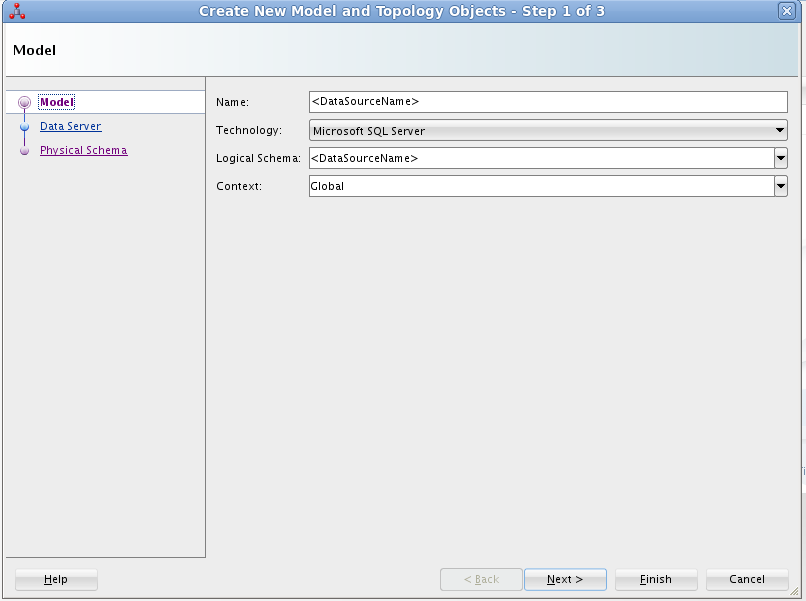
- 表示されるダイアログの「Model」画面で、以下の情報を入力します。
- Name:ApacheHive と入力します。
- Technology:Technology:Generic SQL(ODI がVersion 12.2+ の場合はMicrosoft SQL Server)を選択します。
- Logical Schema:ApacheHive と入力します。
- Context:Global を選択します。
![モデルを設定]()
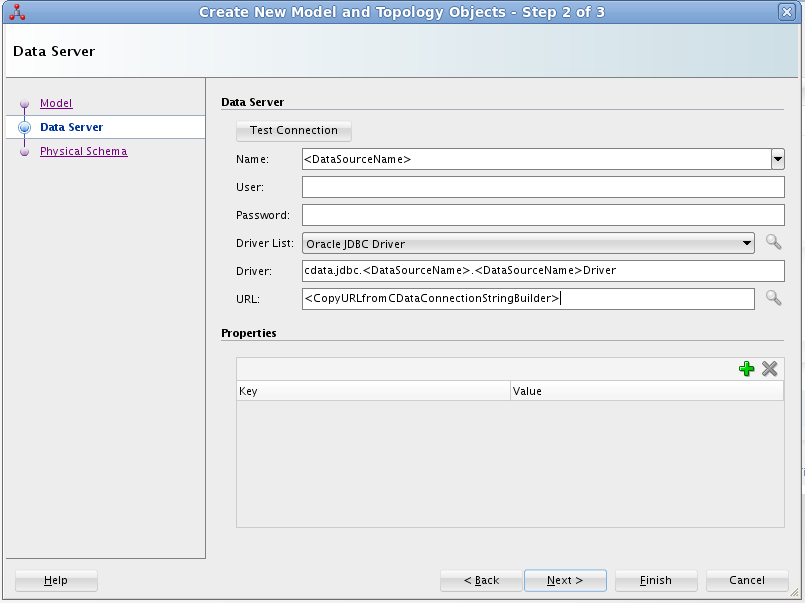
- 表示されるダイアログの「Data Server」画面で、以下の情報を入力します。
- Name:ApacheHive と入力します。
- Driver List:Oracle JDBC Driver を選択します。
- Driver:cdata.jdbc.apachehive.ApacheHiveDriver と入力します。
- URL:接続文字列を含むJDBC URL を入力します。
Apache Hive への接続を確立するには以下を指定します。
- Server:HiveServer2 をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:HiveServer2 インスタンスへの接続用のポートに設定。
- TransportMode:Hive サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
- CData 製品においてTLS/SSL を有効化するには、UseSSL をTrue に設定します
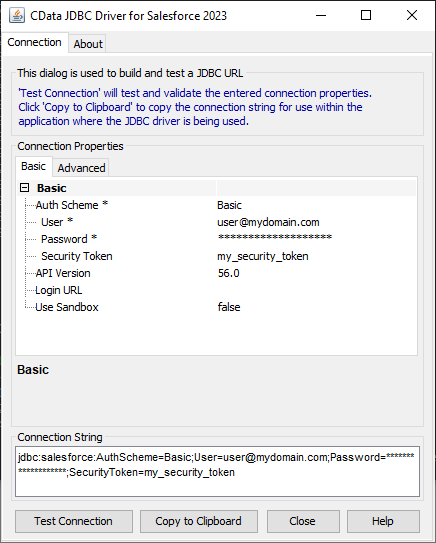
組み込みの接続文字列デザイナー
JDBC URL の作成の補助として、Hive JDBC Driver に組み込まれている接続文字列デザイナーが使用できます。JAR ファイルをダブルクリックするか、コマンドラインからjar ファイルを実行します。
java -jar cdata.jdbc.apachehive.jar
接続プロパティを入力し、接続文字列をクリップボードにコピーします。
![組み込みの接続文字列デザイナーを使ってJDBC URL を生成(Salesforce の場合)]()
一般的な接続文字列は次のとおりです。
jdbc:apachehive:Server=127.0.0.1;Port=10000;TransportMode=BINARY;
![Data Server を設定]()
- Physical Schema 画面で、以下の情報を入力します。
- Name:ドロップダウンメニューから選択します。
- Database (Catalog):CData と入力します。
- Owner (Schema):Hive にSchema を選択した場合は、選択したSchema を入力し、それ以外の場合はApacheHive と入力します。
- Database (Work Catalog):CData と入力します。
- Owner (Work Schema):Hive にSchema を選択した場合は、選択したSchema を入力し、それ以外の場合はApacheHive と入力します。
![Physical Schema を設定]()
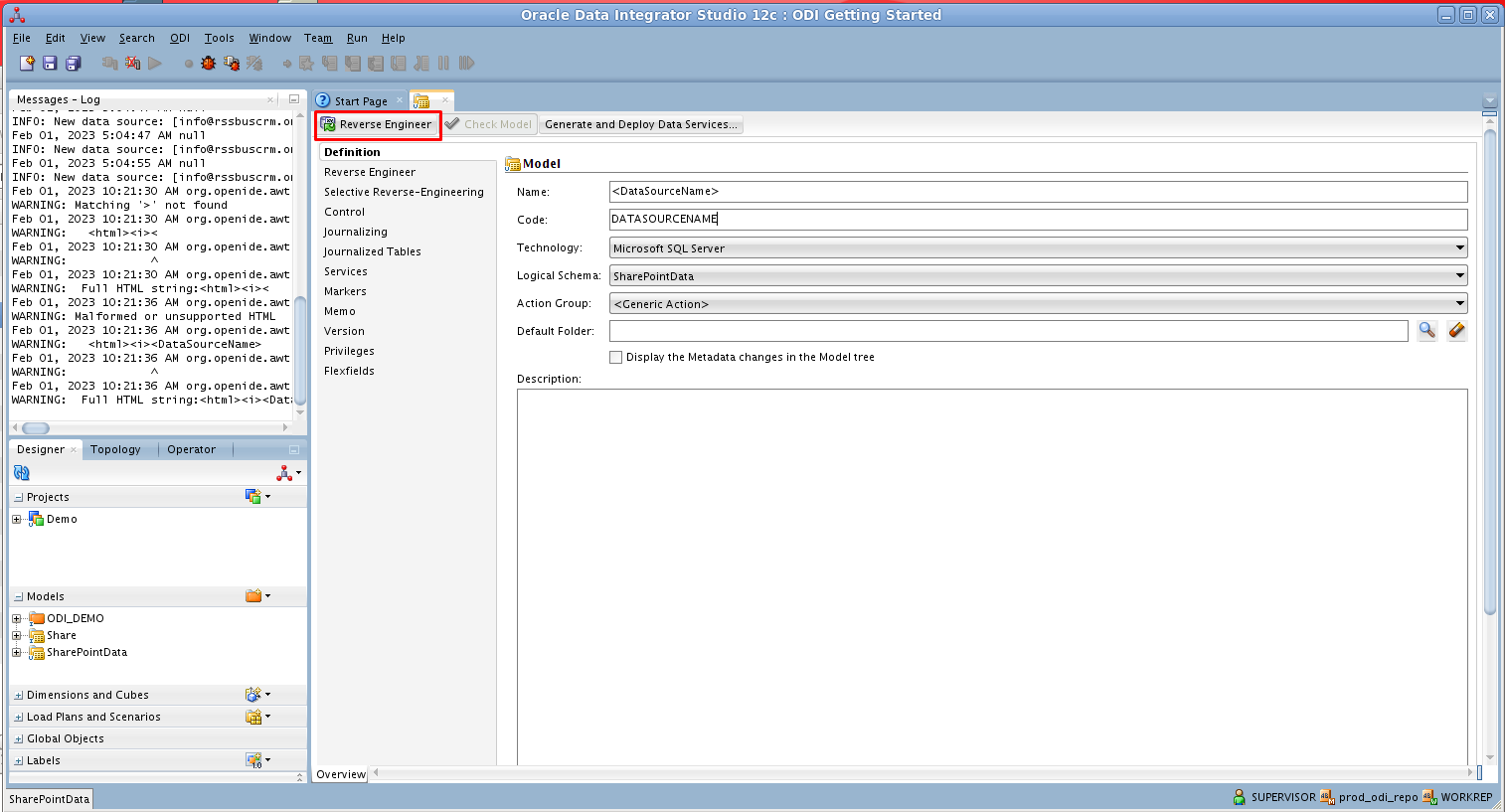
- 開いたモデルで「Reverse Engineer」をクリックしてHive テーブルのメタデータを取得します。
![モデルをリバースエンジニアリング]()
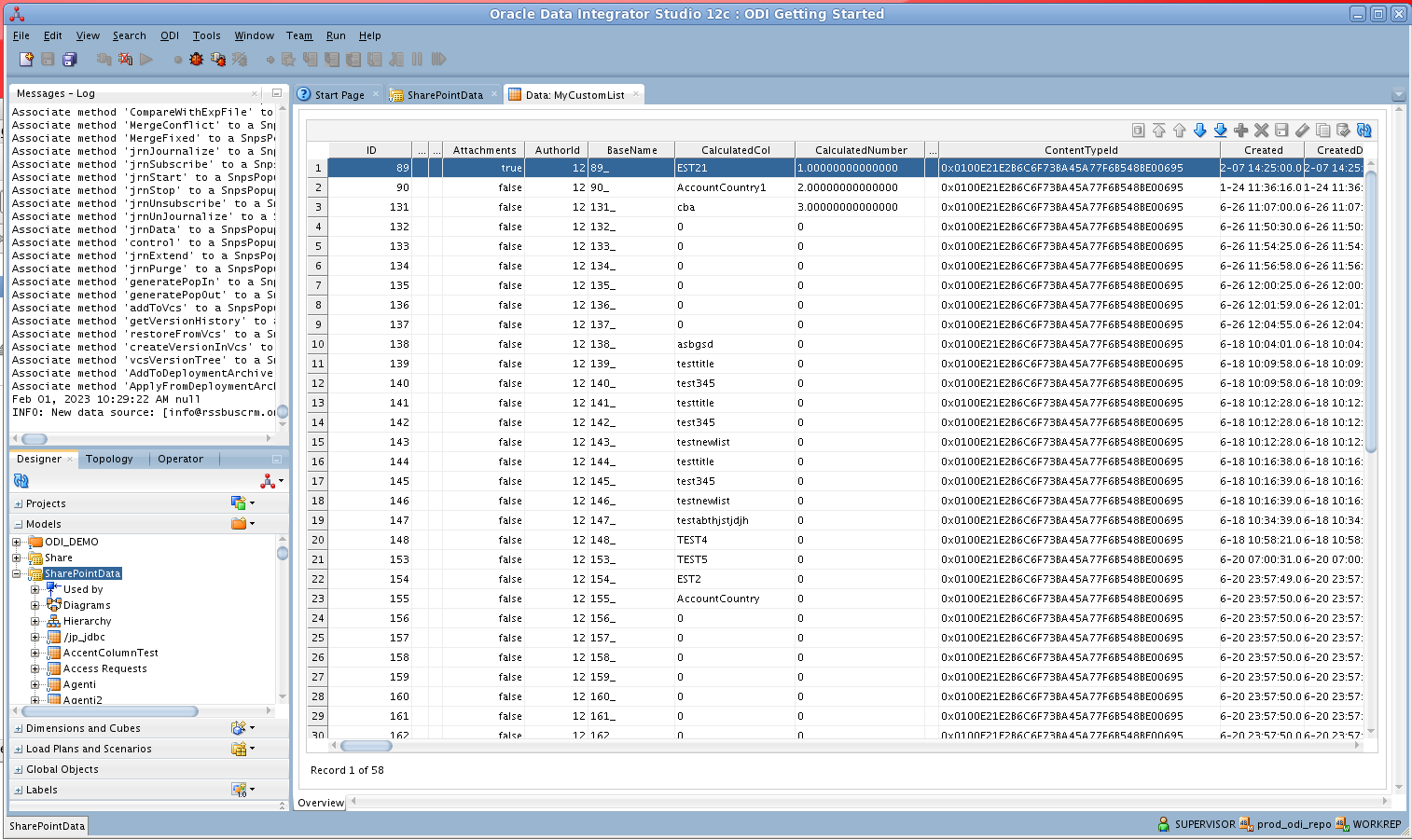
Hive データの編集と保存
リバースエンジニアリング後、ODI でHive データを操作できるようになります。
Hive データを編集し保存するには、Designer ナビゲーターでモデルアコーディオンを展開し、テーブルを右クリックして「Data」をクリックします。「Refresh」をクリックしてデータの変更を取得します。変更が完了したら「Save Changes」をクリックします。
![データを表示]()
ETL プロジェクトの作成
次の手順に従って、Hive からETL を作成します。Customers エンティティをODI Getting Started VM に含まれているサンプルデータウェアハウスにロードします。
SQL Developer を開き、Oracle データベースに接続します。Connections ぺインでデータベースのノードを右クリックし、「New SQL Worksheet」をクリックします。
もしくは、SQLPlus を使用することもできます。コマンドプロンプトから、以下のように入力します。
sqlplus / as sysdba
- 以下のクエリを入力し、ODI_DEMO スキーマにあるサンプルデータウェアハウスに新しいターゲットテーブルを作成します。以下のクエリは、Hive のCustomers テーブルに一致するいくつかのカラムを定義します。
CREATE TABLE ODI_DEMO.TRG_CUSTOMERS (COMPANYNAME NUMBER(20,0),City VARCHAR2(255));
- ODI でDesigner ナビゲーターのModels アコーディオンを展開し、ODI_DEMO フォルダの「Sales Administration」ノードをダブルクリックします。Model Editor でモデルが開きます。
- 「Reverse Engineer」をクリックします。TRG_CUSTOMERS テーブルがモデルに追加されます。
- プロジェクトの「Mappings」ノードを右クリックし、「New Mapping」をクリックします。マッピングの名前を入力し、「Create Empty Dataset」オプションを無効にします。Mapping Editor が表示されます。
- TRG_CUSTOMERS テーブルをSales Administration モデルからマッピングにドラッグします。
- Customers テーブルをHive モデルからマッピングにドラッグします。
- ソースコネクタポイントをクリックしてターゲットコネクタポイントにドラッグします。Attribute Matching ダイアログが表示されます。ここでは、デフォルトオプションを使用します。その場合、目的の動作はターゲットカラムのプロパティに表示されます。
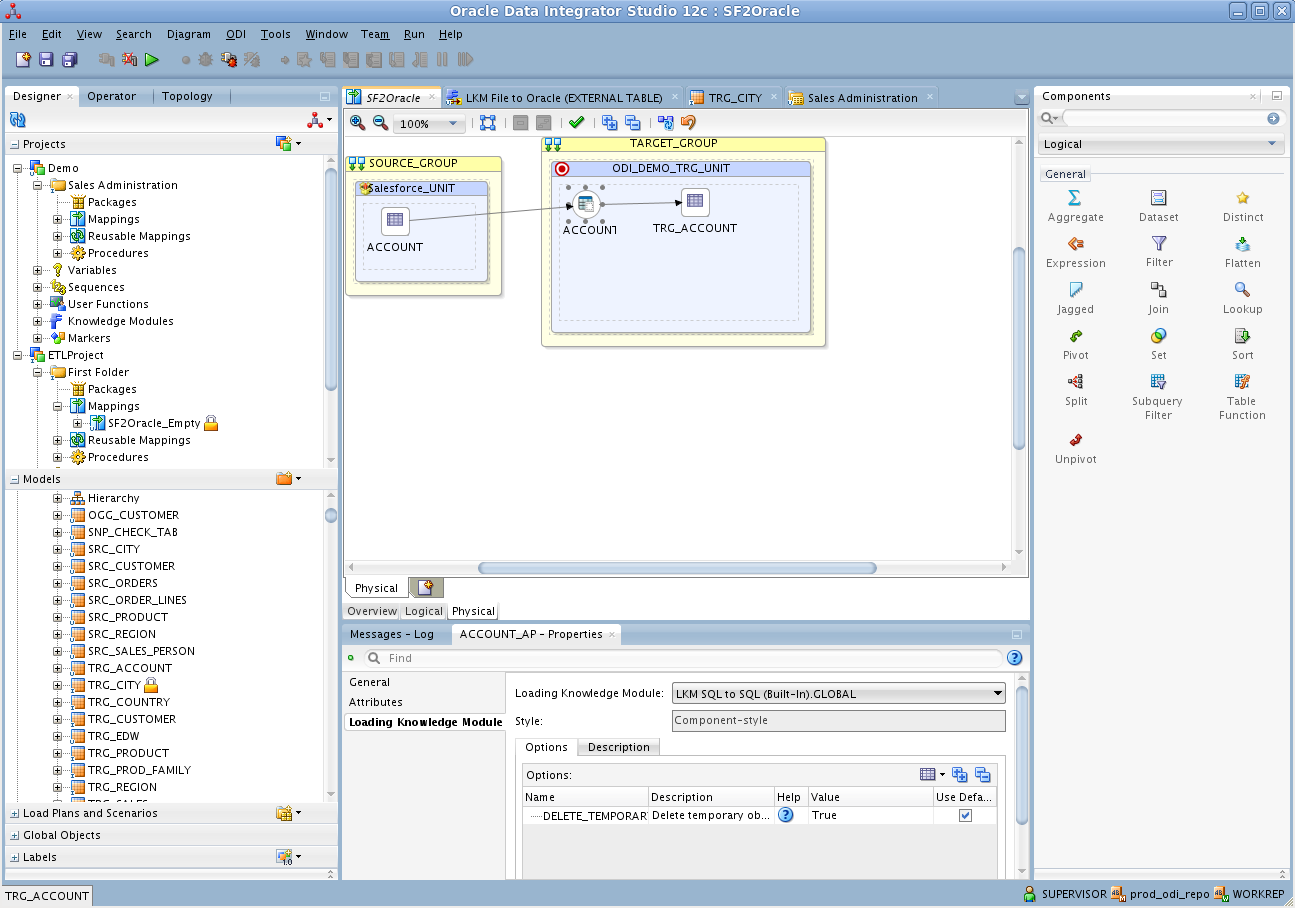
- Mapping Editor のPhysical タブを開き、TARGET_GROUP の「CUSTOMERS_AP」をクリックします。
- CUSTOMERS_AP プロパティで、Loading Knowledge Module タブの「LKM SQL to SQL (Built-In)」を選択します。
![Hive へのSQL ベースのアクセスには、標準データベース間のナレッジモジュールを使用できます]()
これで、マッピングを実行してHive データをOracle にロードできます。