こんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
CData JDBC Driver for ApacheHive は、JDBC 標準に準拠し、BI ツールからIDE まで幅広いアプリケーションでHive データへの接続を提供します。この記事では、DbVisualizer からHive データに接続する方法、およびtable エディタを使ってHive を編集、および保存する方法を説明します。
CData JDBC ドライバとは?
CData JDBC ドライバは、以下の特徴を持ったリアルタイムデータ接続ツールです。
- Hive をはじめとする、CRM、MA、グループウェア、広告、会計ツールなど多様な270種類以上のSaaS / DB に対応
- DBeaver を含む多様なアプリケーション、ツールにHive データを連携
- ノーコードでの手軽な接続設定
- 標準 SQL での柔軟なデータ読み込み・書き込み
CData JDBC ドライバでは、1.データソースとしてHive の接続を設定、2.DBeaver 側でJDBC Driver との接続を設定、という2つのステップだけでデータソースに接続できます。以下に具体的な設定手順を説明します。
Hive データの新しいドライバー定義を作成
下記の手順に従い、Driver Manager を使ってDbVisualizer ツールからHive データに接続します。
- DbVisualizer で「Tools」->「Driver Manager」をクリックします。
- 「」ボタンをクリックして新しくドライバーを作成します。
- テンプレートは「Custom」を選択します。
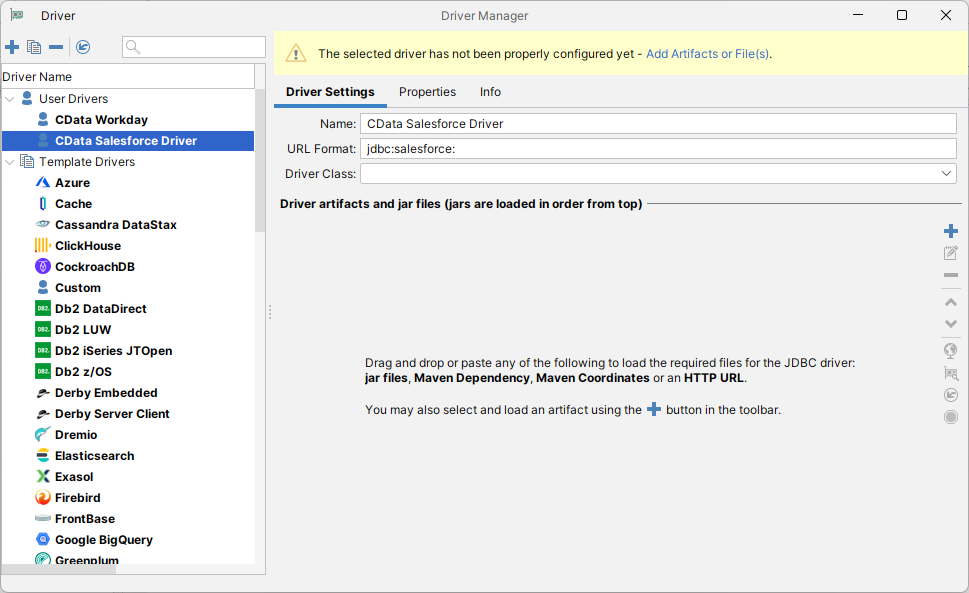
- Driver Settings タブで:
- Name をわかりやすい名前に設定します(例:CData Hive Driver)。
- URL Format をjdbc:apachehive: に設定します。
![ドライバー設定(Salesforce の場合)]()
- Driver artifacts and jar files (jars are loaded in order from top) セクションで:
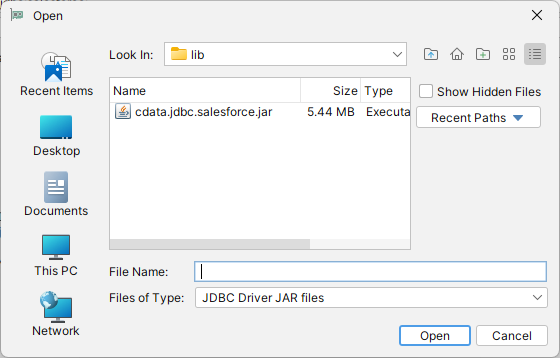
- 「」ボタンをクリックして、「Add Files」に進みます。
- インストールディレクトリ(C:\Program Files\CData\CData JDBC Driver for Hive XXXX\)の「lib」フォルダに移動します。
- JAR ファイル(cdata.jdbc.ApacheHive.jar)を選択して「Open」をクリックします。
![ドライバーのJAR ファイルをロード。]()
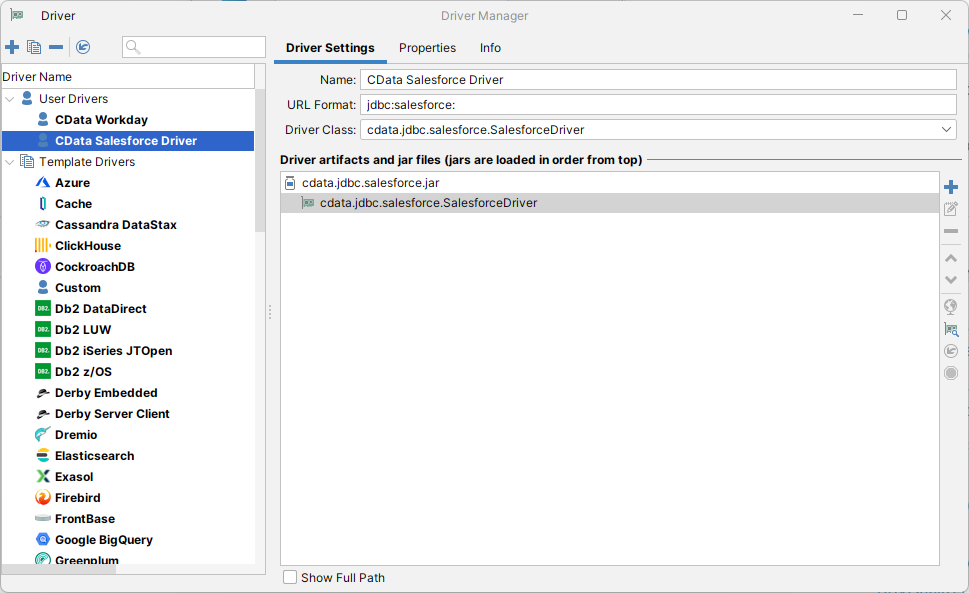
- Driver Class は自動的に入力されます。もし入力されない場合は、クラス(cdata.jdbc.apachehive.ApacheHiveDriver)を選択してください。
![設定されたJDBCドライバー(Salesforce の場合)]()
JDBC データソースへの接続を定義
「Driver Manager」を終了し、下記の手順に従ってJDBC URL に接続プロパティを入力します。
- 「Databases」タブで「」ボタンをクリックし、先ほど作成したドライバーを選択します。
「Connection」セクションで以下のオプションを設定します。
- Database Type:ウィザードオプションを選択した場合は、データベースの種類は自動検出されます。「No Wizard」オプションを選択した場合は、「Database Type」メニューから「Generic」または「Auto Detect」オプションを選択します。
- Driver Type:先ほど作成したドライバーを選択します。
Database URL:完全なJDBC URL を入力します。JDBC URL 構文は、jdbc:apachehive: に続けてセミコロン区切りでname-value ペアの接続プロパティを入力します。
Apache Hive への接続を確立するには以下を指定します。
- Server:HiveServer2 をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:HiveServer2 インスタンスへの接続用のポートに設定。
- TransportMode:Hive サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
- CData 製品においてTLS/SSL を有効化するには、UseSSL をTrue に設定します
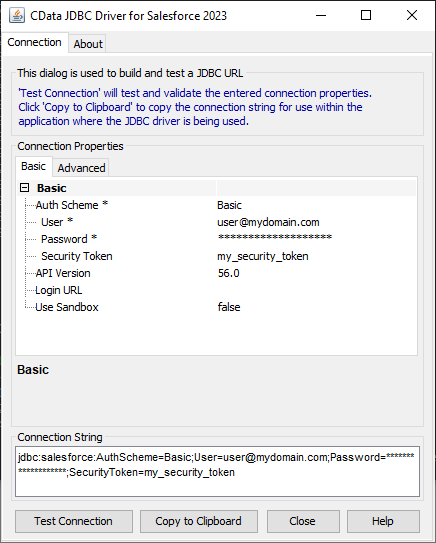
組み込みの接続文字列デザイナー
JDBC URL の作成の補助として、Hive JDBC Driver に組み込まれている接続文字列デザイナーが使用できます。JAR ファイルをダブルクリックするか、コマンドラインからjar ファイルを実行します。
java -jar cdata.jdbc.apachehive.jar
接続プロパティを入力し、接続文字列をクリップボードにコピーします。
![組み込みの接続文字列デザイナーを使ってJDBC URL を生成(Salesforce の場合)]()
JDBC URL を構成する際に、Max Rows 接続プロパティを設定することもできます。この設定は返される行数を制限するため、レポートやビジュアライゼーションを作成する際のパフォーマンスが向上します。
一般的な接続文字列は次のとおりです。
jdbc:apachehive:Server=127.0.0.1;Port=10000;TransportMode=BINARY;
-
NOTE:Hive は認証にUser やPassword を必要としないため、Database Userid とDatabase Password には任意の値を使用できます。
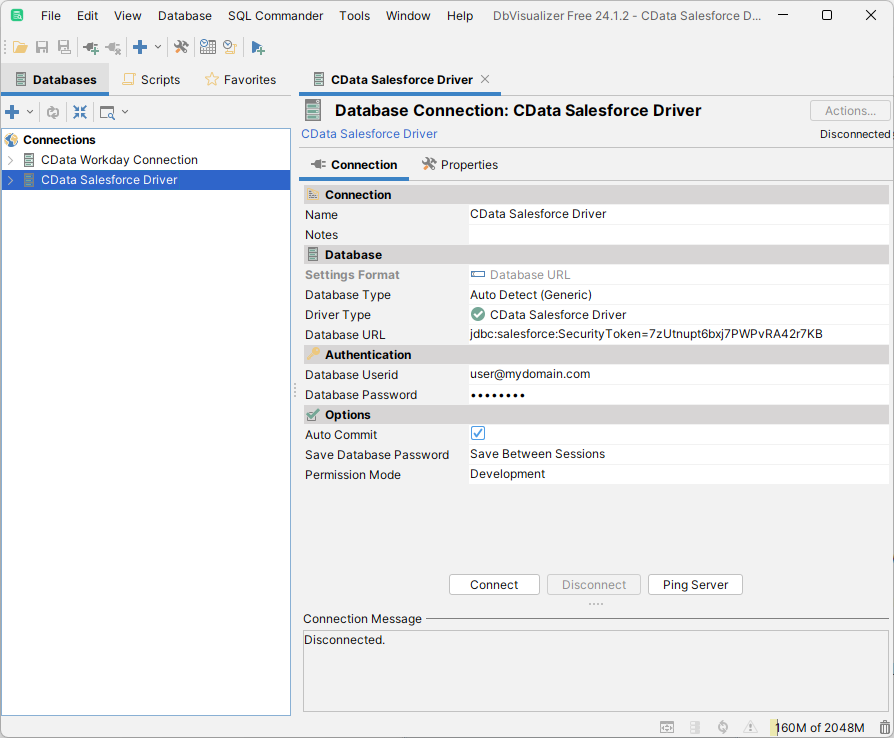
- 「Connection」タブで「Connect」をクリックします。
![新しく設定されたデータベース接続(Salesforce の場合)。]()
Hive JDBC Driver が表示するテーブルをブラウズするには、テーブルを右クリックして「Open In New Tab」をクリックします。
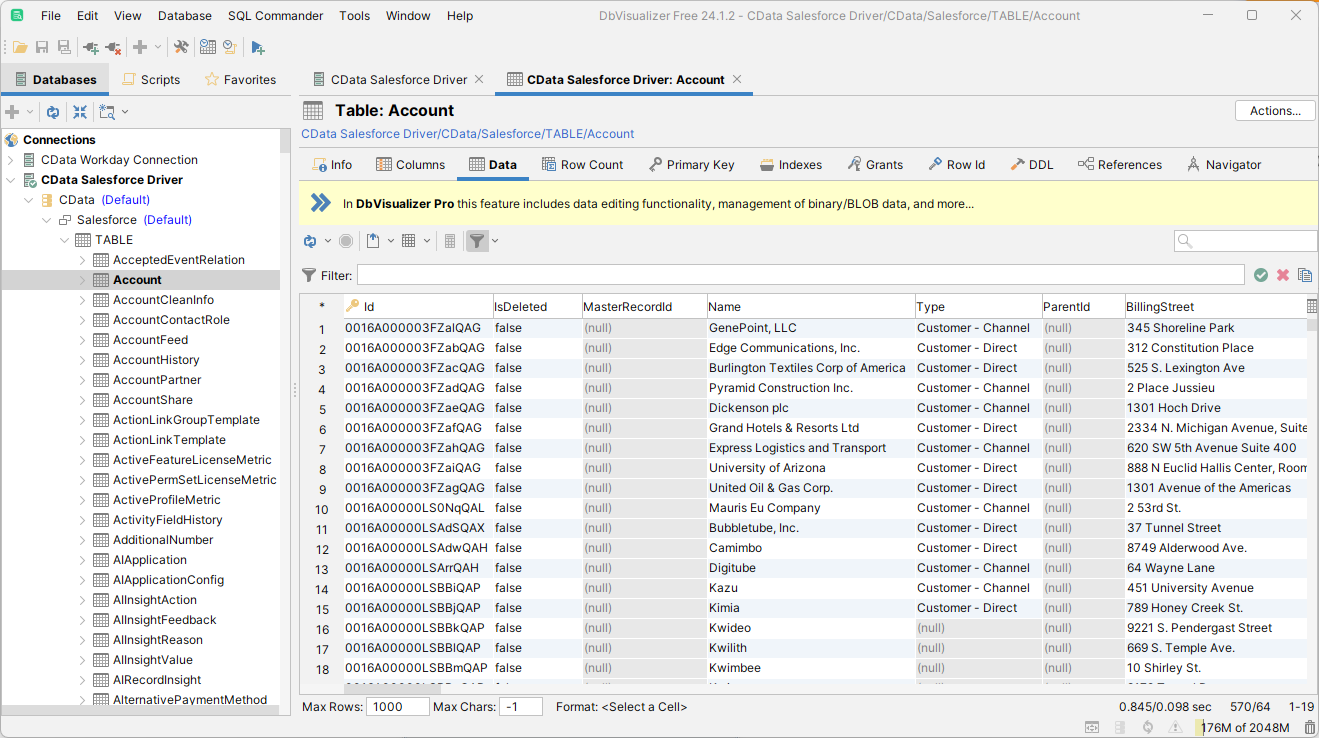
SQL クエリの実行には、SQL Commander ツールを使用します。「SQL Commander」->「New SQL Commander」をクリックします。利用可能なメニューから「Database Connection」、「Database」、「Schema」を選択します。
サポートされるSQL についての詳細は、ヘルプドキュメントの「サポートされるSQL」をご覧ください。テーブルに関する情報は「データモデル」をご覧ください。
![DBVisualizer でクエリを実行した結果(Salesforce の場合)。]()
おわりに
CData JDBC Driver for ApacheHive の
30日間無償トライアル
をダウンロードして、DbVisualizer でリアルタイムHive データの操作をはじめましょう!ご不明な点があれば、
サポートチームにお問い合わせください。