
こんにちは。CData Software Japanリードエンジニアの杉本です。
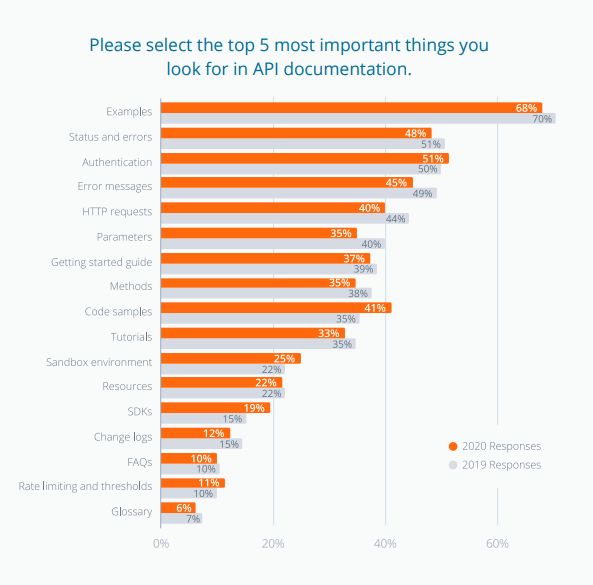
早速ですが、みなさん以下のグラフをご存知でしょうか?
smartbear.com
このグラフはAPI管理ツールを提供するSmartBearのAPI調査において、APIドキュメントで最も重要な要素として選ばれた要素のランキングです
APIドキュメントといえば、APIの認証方法やメソッドの使い方、エラーメッセージやパラメータの有無、そういった内容が詰め込まれたドキュメントですが、その中でも最も重要であるとAPI開発者やユーザーが投票したのが「Examples」つまり、APIのサンプルリクエストでした。
私はこのデータから一つ重要なメッセージが読み取れると感じています。
それは「API Reference だけで簡単にAPIを扱えるユーザーなどほとんど存在しない」という、身も蓋も無い話です。
昨今APIはますます増加の一途をたどり、またそれらを扱うサービス・iPaaSやローコード・ノーコードツール、SaaSのへの連携組み込みなども、同様に増加しています。その組み合わせパターンはすでに私達が認知できる数字を超えているとも考えられるでしょう。
それにもかかわらず、未だに私達はそれらAPI連携の実態を、方法を、根幹を簡単に掴みきれずにいます。どんなに良いAPIが世の中に溢れていようと、そのアクセス方法は多種多様に存在し、一律に扱えるわけではありません。
以下の調査結果からも、そういった傾向が見えるかなと思います。
www.cdatablog.jp
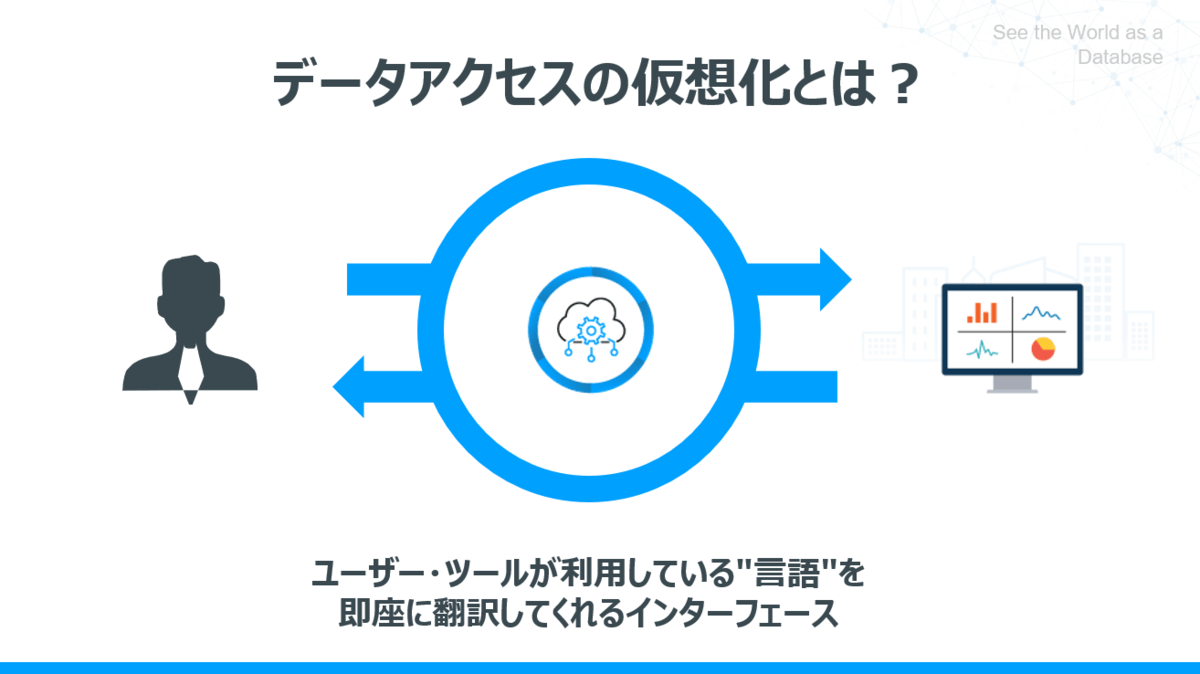
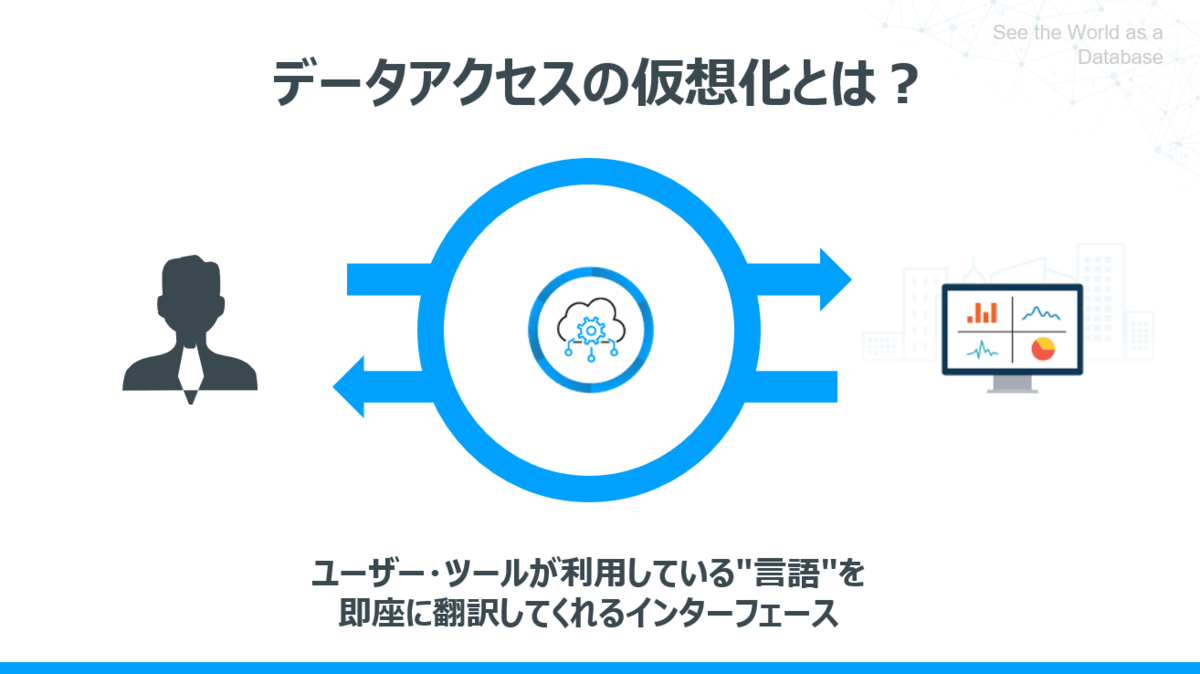
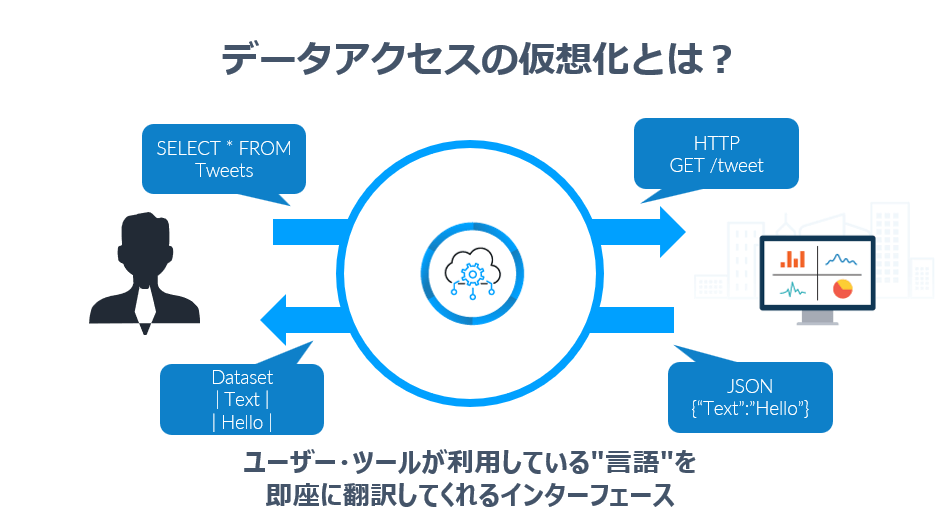
そこで、今回一つ紹介したいキーワードが「データアクセス仮想化」です。
ざっくり言ってしまえば、アプリケーションやクライアントとAPIを仲介し、そのやりとりの言語(API)を翻訳してくれるインターフェースのことを指します。
おそらくあまり聞き馴染みが無いこのワードですが、実はすでに身の回りでよく使われているアプローチだったりします。そしてこのクラウド・APIの時代において、その重要性がますます高まっているように感じます。
そこで今回はこの「データアクセス仮想化」について、どういったものなのか? どんな風に役に立つのか? そして、なぜ今の時代に必要なのか? を追っていきたいと思います。
ちなみに今回の記事はBurikaigi 2021 で登壇したときのセッションをベースに構成しています。以下の記事でスライドなども紹介しているので、よかったご覧ください。
www.cdatablog.jp
まずデータアクセス仮想化を試してみる
詳しくこのキーワードを追っていく前に、ちょっと以下のデモを見てください。
MySQL Workbenchから「SELECT * FROM Tweets」のSQLを実行して、ツイッターのデータを取得している様子です。
すると、私のタイムラインのデータがMySQLWorkbench上で表示されます。

では、もう一つデモを見てみましょう。
今度は「INSERT INTO Tweets(TEXT)VALUES('Hello World')」のSQLを発行しています。
INSERT文を発行すると、私のツイッターアカウントにツイートが投稿されました。
なんとも不思議な感じがしませんか?
このSQLは、MySQLのインターフェース、MySQL Wireprotocol を通じて、ツイッターのAPIにアクセスしています。そう、みなさんもご存知のあの、ツイッターのAPIです。
つまり何かしらの汎用的なインターフェース・プロトコルを通じて、APIにアクセスすることができるようにするアプローチ、それが「データアクセス仮想化」です。
そもそも仮想化とはなんだろう?

早速データアクセス仮想化について、実例をお見せしましたが、もうちょっとこのキーワードを咀嚼していきましょう。
まず、皆さんとイメージをすり合わせておきたいのですが、「仮想化」と言われるとどんなイメージでしょうか?
今の時代、仮想化と言われて一番最初に思い浮かぶのが、「VM(Vertial Machine)」あたりかとは思いますが、少し物理的な部分を想定すると、ブレードサーバーを思い浮かべる人や

ja.wikipedia.org
プログラミング的な部分でいけば、CLR:共通言語ランタイムやJVMを思い浮かべる人も居るかもしれませんね。
ja.wikipedia.org
Wikipediaにも掲載されている通りですが、この「仮想化」テクノロジーは実に幅広い要素・アプローチを数多く含んでいます。
ja.wikipedia.org

そんな「仮想化」は大きく分けて、2種類のアプローチが存在し、コンピューター全体やAPI・アプリケーションのエミュレーション、シュミレーションを行う「プラットフォーム仮想化」、そして物理的な補助記憶装置やボリューム、ネットワークなどを抽象化する「リソース仮想化」が存在します。
ただ、ベースに存在するのは、「根底にある(ネイティブのAPI)実装を隠蔽した外部インターフェースを生成する」ことです。

「データアクセス仮想化」は、どちらかと言えばプラットフォーム仮想化に属するアプローチの一つであり、API・アプリケーションを抽象化して、特定のインターフェースをエミュレーションしているものと捉えることができます。
とはいえまだイメージがふんわりしているかと思うので、この「データアクセス仮想化」を関係する興味深いリリースを紹介してみましょう。
去年の年末に、AWSからとても興味深い新機能「Babelfish for Aurora PostgreSQL」がリリースされていました。
www.publickey1.jp
Amazon Aurora PostgreSQLにSQL Server の互換レイヤーを提供、つまるところ PostgreSQL に対して TDSプロトコルのサポートおよびT-SQLでのクエリが可能になる、大変ユニークな機能です。
aws.amazon.com
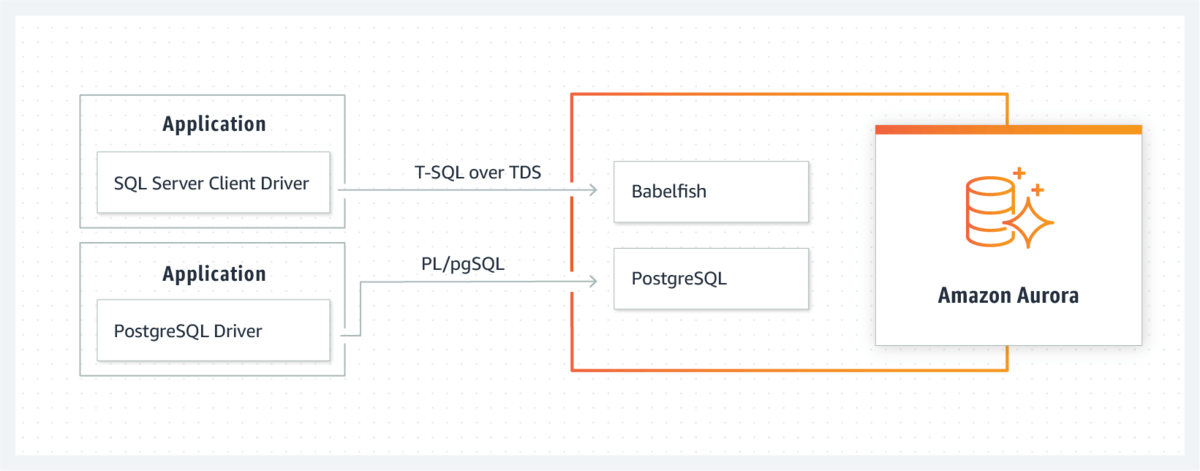
このリリースはまさに、「データアクセス仮想化」のアプローチの一つです。
こういった事例を踏まえて、「データアクセス仮想化」とはなにか? を噛み砕いていきます。
データアクセス仮想化とは?
「データアクセス仮想化」とは、「ユーザー・ツールが利用している"言語"を即座に翻訳してくれるインターフェース」であると書きました。
先程の例は Amazon Aurora PostgreSQL に SQL Server の互換レイヤーを提供することで、内部に持つPostgreSQLのネイティブAPIを隠蔽し、PostgreSQLに対してTDSプロトコルのサポートおよびT-SQLでのクエリが可能になるものです。
もう少し噛み砕いて言えば、「ネイティブなフォーマット・APIに直接アクセスするのではなく、異なるプロトコル・仕様のレイヤーを通じてそれらのデータにアクセスする方法」となります。

通常、私達は「なにかのデータを扱いたい」「このサービスのデータにアクセスしたい」といった場合、以下のような要素を意識します。
・CSVやXML・JSONといったファイルフォーマットの仕様
・HTTP・REST・SOAP・OData・GraphQLといったプロトコルの仕様
・それぞれのプロトコル・APIの処理プロセス
もし、そのAPIやプロトコルに専用のライブラリがあれば、それを使ってプログラミングをすると思いますし、なければ自分でライブラリを作るか、ネイティブに実装する、といった取り組み方になるでしょう。
実はそこにもう一つの選択肢として「仮想化されたインターフェース」を通じて、データアクセスを行う手段が存在します。
前述のAmazon Aurora の TDS・T-SQL機能はまさにその典型的な一例です。
例えば、SQL Server向けに実装されたアプリケーションをPostgreSQLに置き換えたい、といったシチュエーションを考えた場合、PostgreSQLとSQL ServerのSQL方言の調整、ライブラリの変更、ネイティブ実装の変更といったコストが発生します。
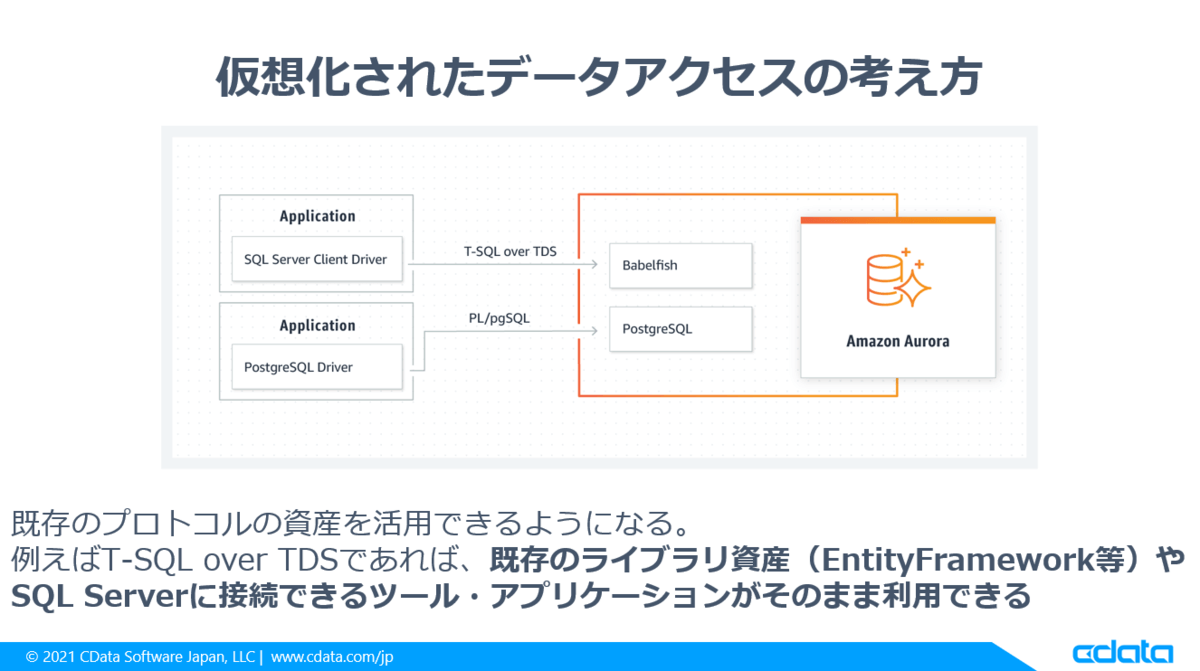
ですが Aurora が PostgreSQL の仕様を T-SQL over TDS で包み込み、擬態することによって、既存のTDS・T-SQLの資産、例えば EntityFramework や ADO.NET 等のライブラリを利用して、アプリケーションのシームレスな置き換えが可能になります。
(※もちろん100%すべてのPostgreSQLの機能が利用できるわけではないと思いますが)
これが「データアクセス仮想化」の大きなポイントになります。
データアクセス仮想化は何が嬉しいの? プロトコルのエコシステム
とはいえ「SQL Serverに接続するためのインターフェースであるTDS」それを使って「PostgreSQLに接続できるようになった」と言われて、どれだけ皆さんの中では「あ、それは嬉しいな」と思える人が居るでしょうか?
もう少しデータアクセス仮想化の文脈を寄せて
「BigQueryがTDSでアクセスできるようになった」
「SalesforceがTDSでアクセスできるようになった」
であれば、どうでしょうか?
私達が普段開発で利用しているフレームワークの可能性が一気に広がるイメージが湧きませんか?
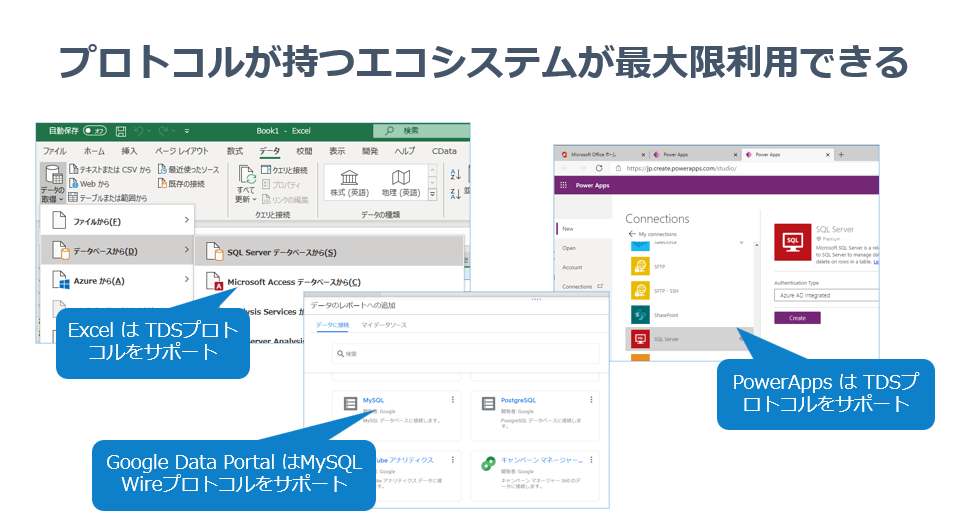
そして実はそれだけではありません。みなさんが思っている以上に、このTDSプロトコルが持つコネクティビティは世の中のサービスに数多く溢れています。
例えば Microsoft の BI ツールである Power BI はどうでしょうか?
例えば、Excel はどうでしょうか?
例えば、帳票ツールはどうでしょうか?
Dynamics 365 や Salesforce などのクラウドサービスのAPI には繋がらないけど、SQL Serverにはつながる、MySQL にはつながる、みたいなサービスやツールはありませんか?
例えば、Excelのデータベース接続はSQL Serverが対応しています。これはTDSが内部のプロトコルとして利用されているので、先程のAmazon Aurora の PostgreSQLにTDSで接続できる可能性があります。
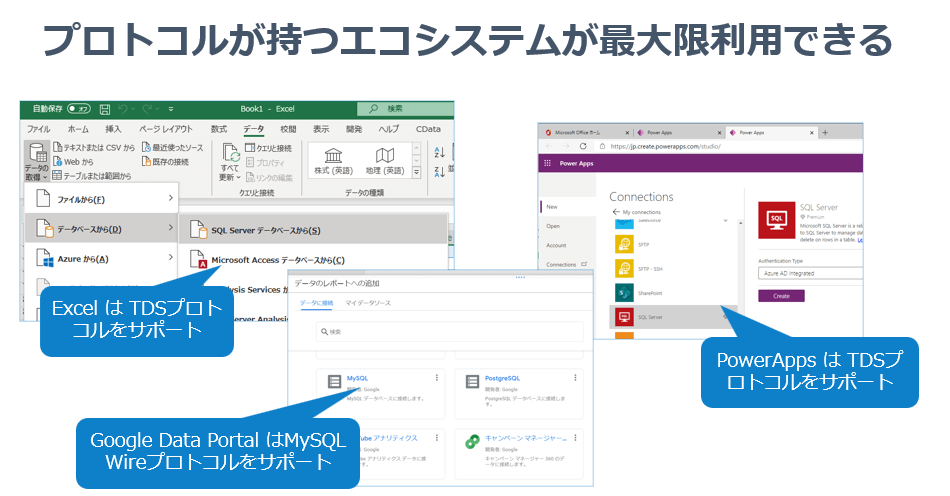
Microsoft のローコード開発ツール PowerAppsでもSQL Serverコネクターがありますが、これも内部的にはTDSで動作しています。
MySQL コネクターも内部的にはMySQL Wireプロトコルで動作していますので、MySQLに仮想化されたインターフェースがあれば、Google Data Portal などもつなぐことができるわけなんですね。
私達が想像している以上に、このTDSプロトコルやMySQL Wireプロトコルのエコシステムはとてつもなく大きいものであることがわかってくると思います。
プロトコルという世界共通で定めた規約であるからこそ、サービスプロバイダーはその仕様の可能性を理解し、エコシステムの価値を知って、そのTDSに連携できるサービスを実装することができる。これがプロトコル・データ仮想化が持つ大きな可能性になっています。
データアクセス仮想化サービス:CData Connect
それでは「データアクセス仮想化」の具体的なユースケース・活用方法として、CData で提供している製品「CData Connect」を使った例を紹介しましょう。
www.cdata.com
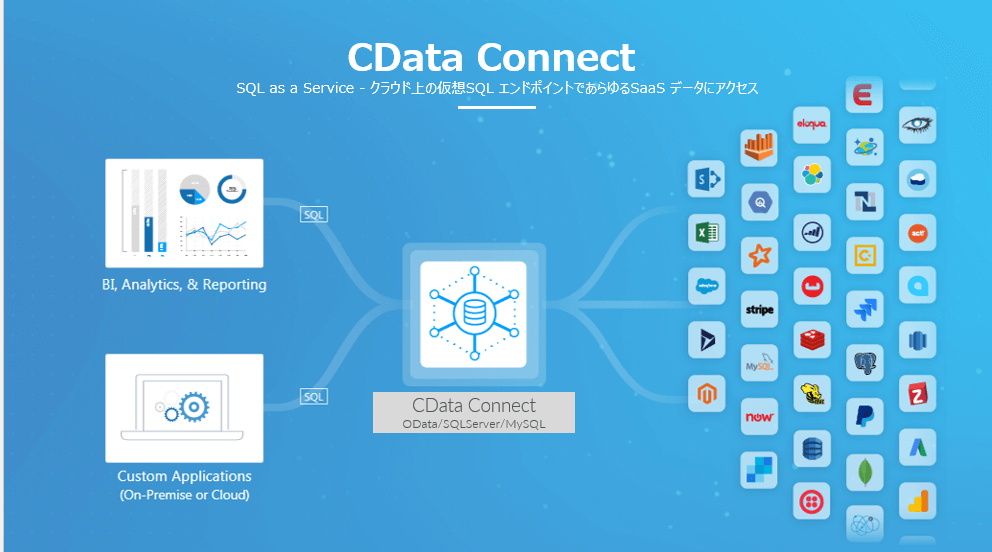
CData Connect は、SaaS ベースで提供されるデータハブサービスです。
Salesforce、NetSuite、Dynamics、Marketo など多様なSaaS にBI、アナリティクス、iPaaS、NoCode/LowCode 開発プラットフォームからアクセスするための仮想エンドポイントを生成します。
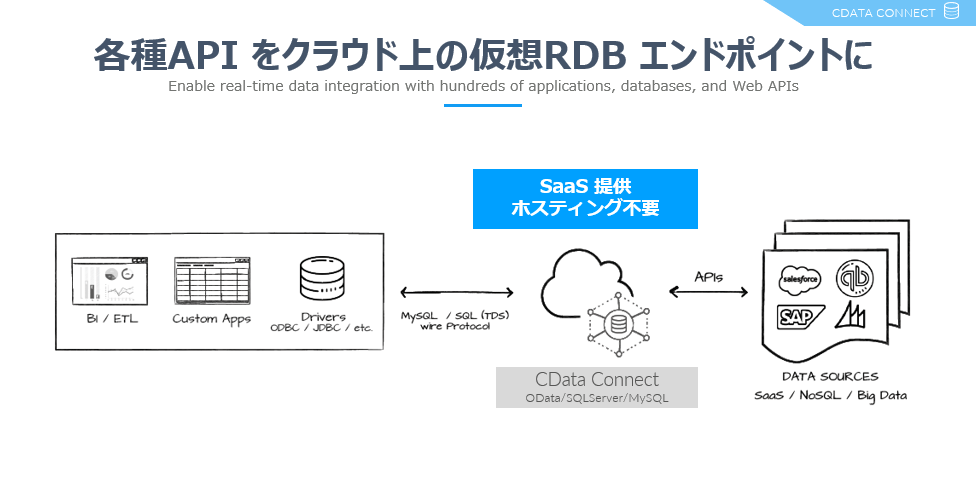
連携方法が異なるSaaS をMySQL、SQL Server、OData の3種類のプロトコルに仮想化することで、データ連携をシンプルに実現します。
"SQL as a Service" といっていいかもしれません。
設定は単純で、まず接続したいクラウドサービスを選択して、各種認証情報を入力します。
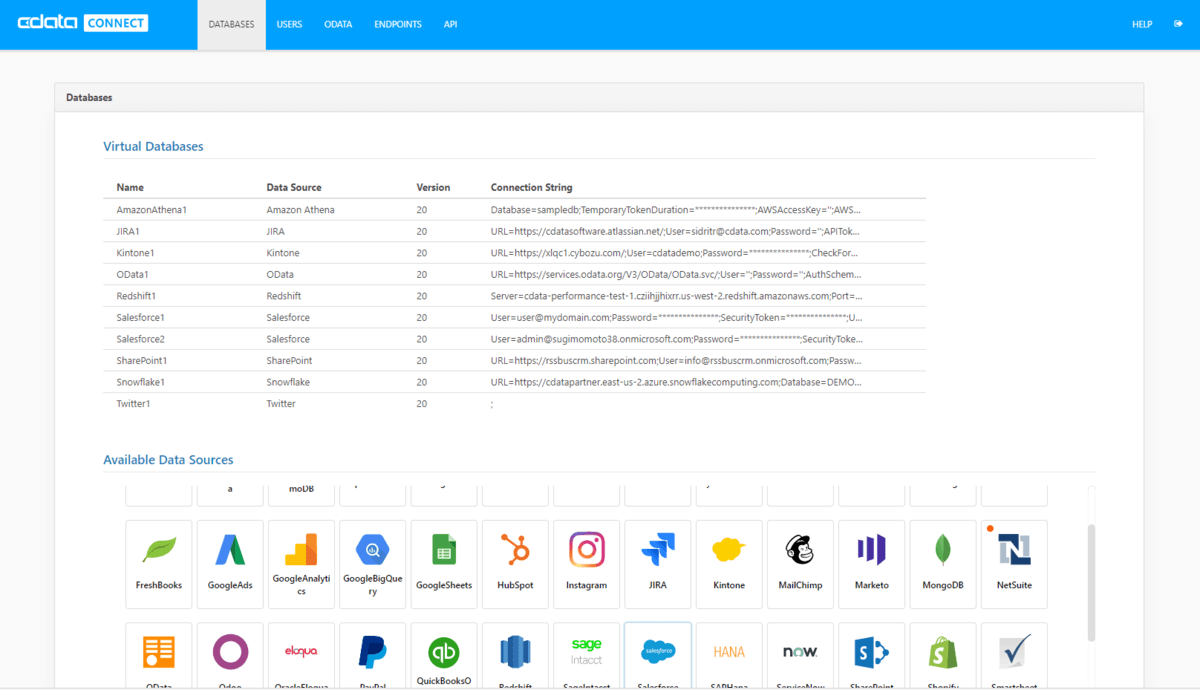
今回は国産クラウドサービスとして有名な kintone に接続してみました。
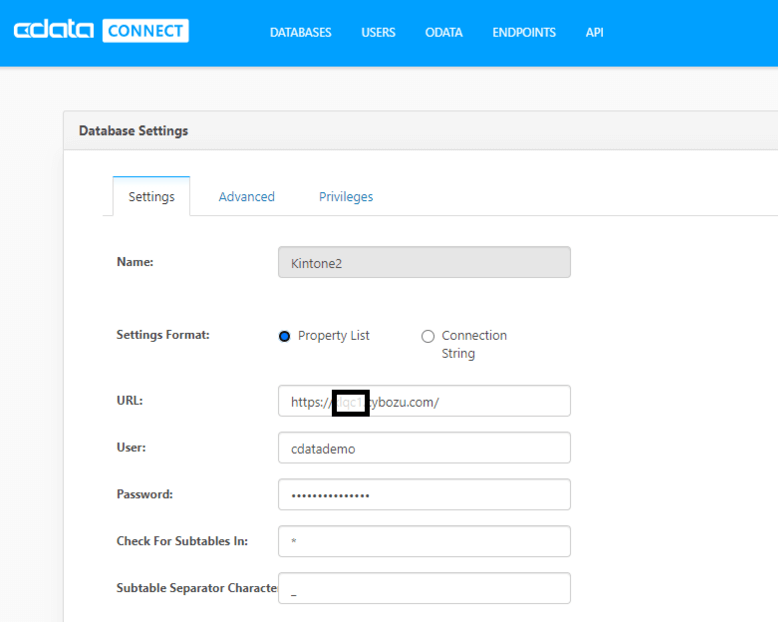
これだけで、kintone に接続できるMySQLやTDSのエンドポイントが生成されます。
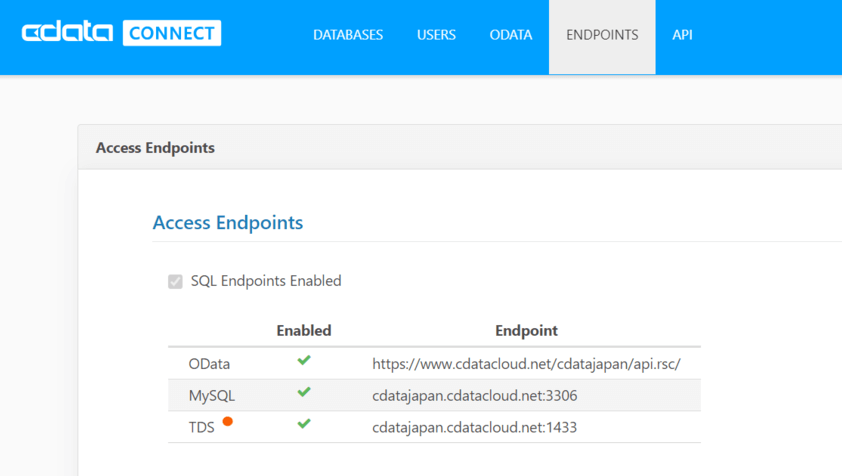
あとは利用したいツールのSQL Server 接続や MySQL接続を利用するだけです。
例えば、PowerAppsであれば以下のようにSQL Serverインターフェースがあるので、これにCData Connectの接続情報を入力します。
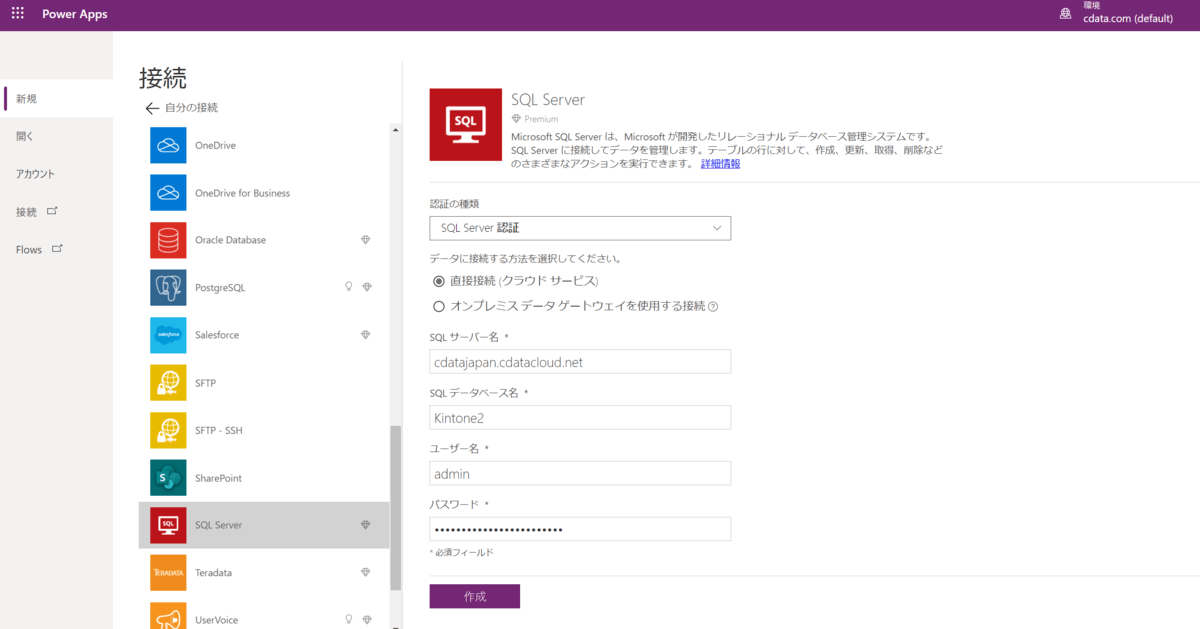
すると、以下のようにKintone のアプリ一覧が表示されて
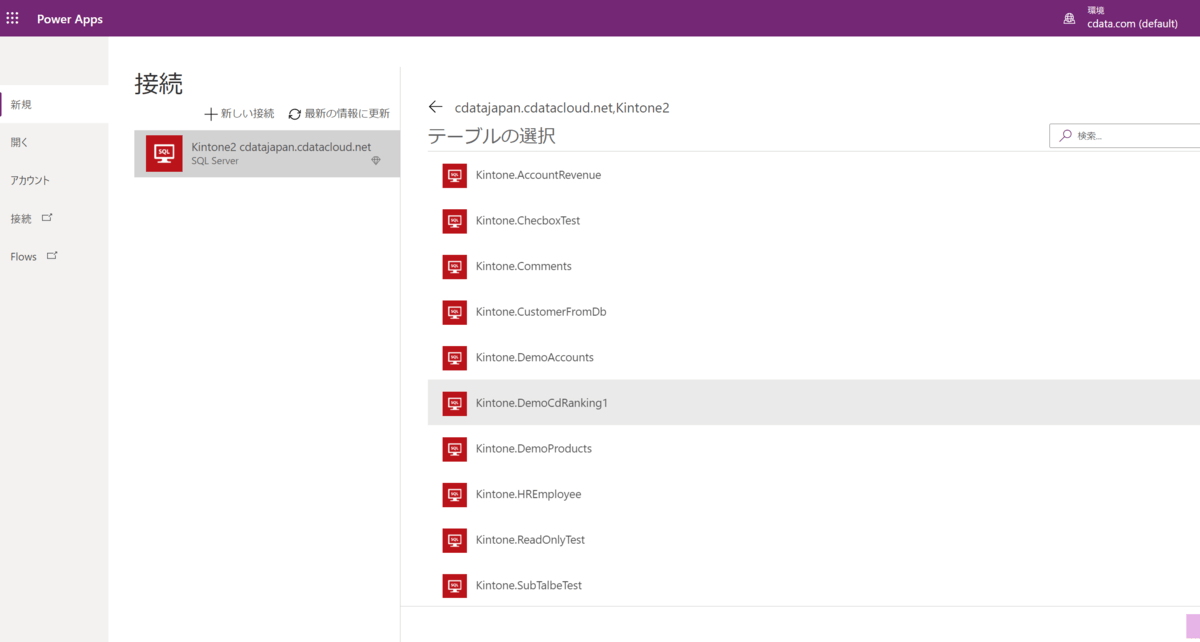
PowerApps上でSQL Serverのデータと同じように扱うことができるようになります。もちろん、データはKintoneからリアルタイムで取得し処理しています。
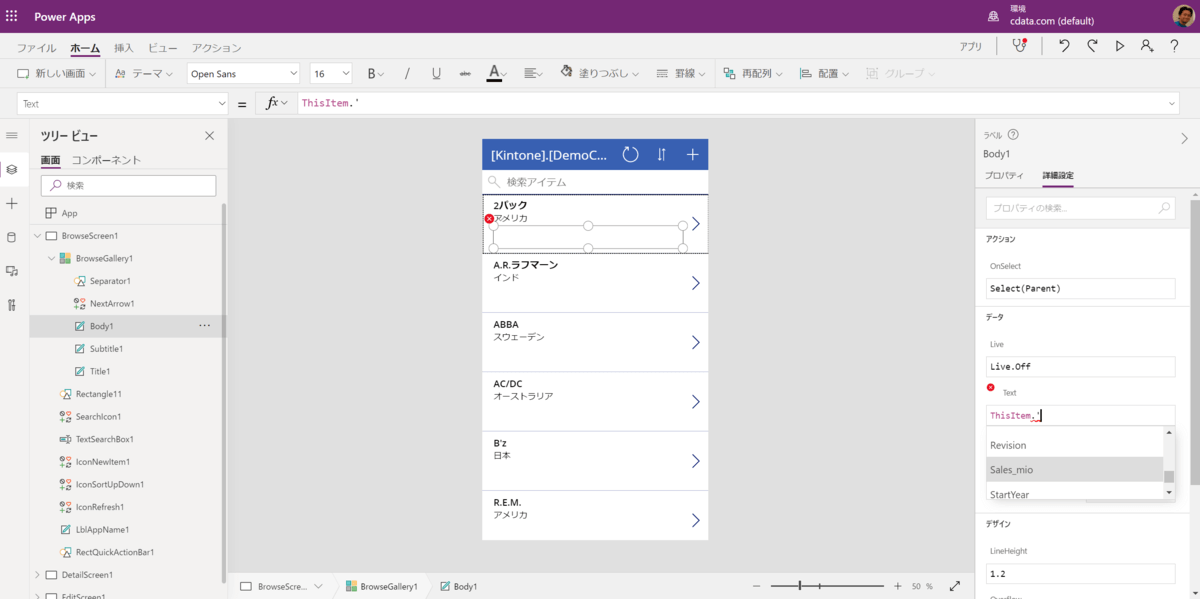
このような形でPowerAppsだけでなく、様々なSQL ServerやMySQLをサポートしているツールがCData Connectを介して、各種クラウドサービスにアクセスできるようになります。
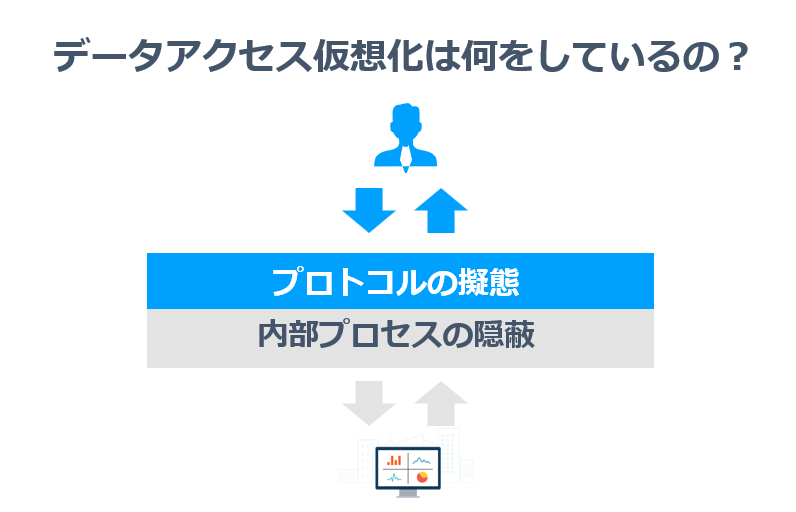
データアクセス仮想化は何をしている?
もう少し踏み込んで「データアクセス仮想化」とは、具体的にどんなことをしているのか? についても掘り下げてみましょう。
これは大きく2つの要素で、その内部処理を隠蔽し、仮想化を行っています。
- プロトコルの擬態
- 内部プロセスの隠蔽
1. インターフェースの隠蔽
まずはインターフェースの隠蔽です。
通常ネイティブのAPIが持つ仕様、プロトコルのプロセス
これがライブラリであれば、各プログラミング言語の関数・プロパティ・クラス/オブジェクト構造として定義し直す、ことが一般的なユースケースですが、データアクセスの仮想化では既存のプロトコル・汎用的なAPIにこのネイティブの仕様を隠蔽してしまいます。
例えば、SQL Server の TDSプロトコルであれば、通常 TCP/IPレイヤーを使って、Serverとの接続を確立し、1433ポートでリクエスト・レスポンスを行います。
docs.microsoft.com
このTDSプロトコルのリクエストの受付およびTDSプロトコルに準拠したレスポンスの返却を行うインターフェースに擬態することで、内部で利用しているAPIやデータベースがなんであろうと、
ざっくり言ってしまえばこの「TDS」はSQLを受け取り、テーブル構造とデータ本体をレスポンスするシンプルな仕組みです。
(もちろん、どこまでこのTDSを実装するのか? といった部分は抽象化を行う製品によって左右されます。)
2. 処理の抽象化
では、処理の抽象化はなんでしょうか?
これは、ネイティブのAPIを実装し、インターフェースの仕様に合わせてデータを返すための仕組み・処理の一連の流れを指します。
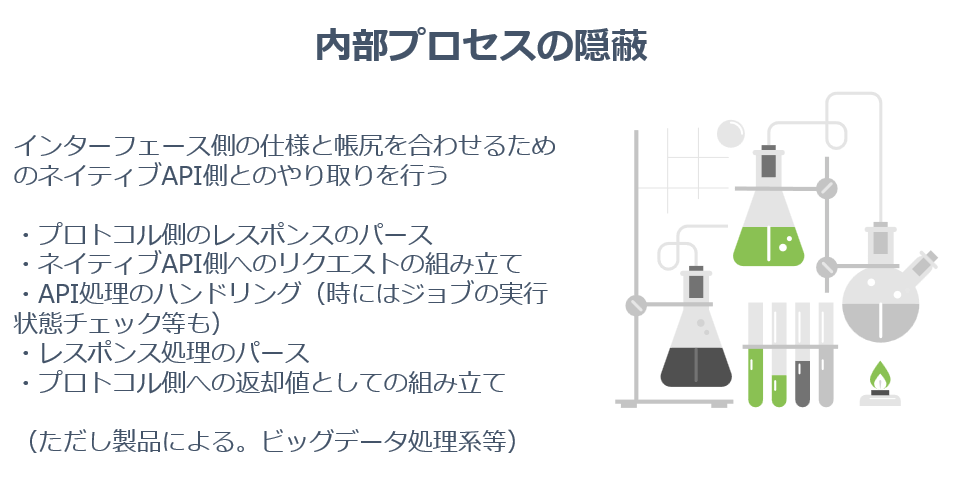
前述のTDSから受け取るデータは単純なSQL文になりますので、そのSQL文の構造を解析・パースして、どのようにネイティブAPIをコールするのか、どのようにAPIリクエストを組み立てるのかを決定し、処理します。
データアクセス仮想化のサービスの紹介
このデータアクセス仮想化は様々なシチュエーションでサービスが提供されていますので、最後にざっくり紹介していきましょう。
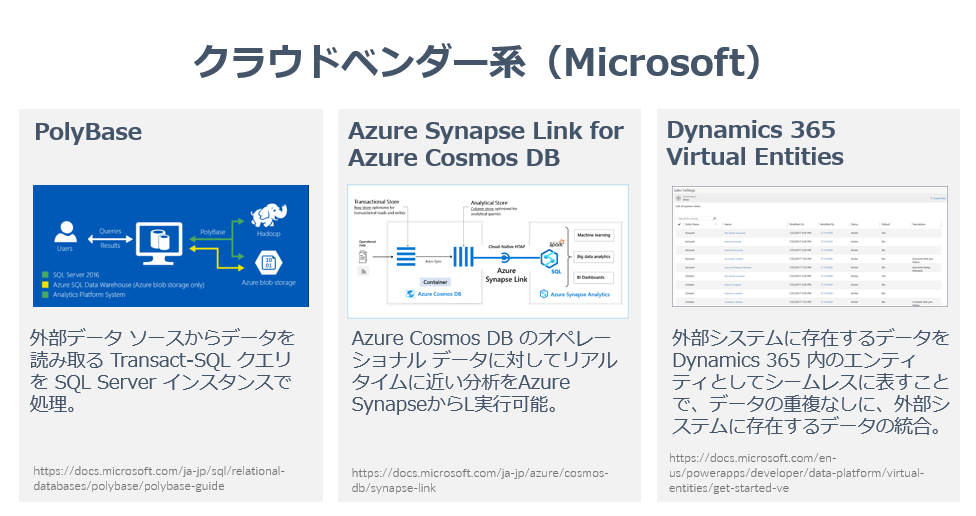
Microsoft Azure 周りのテクノロジーを見渡すとSQL Server の PolyBase 機能はわかりやすいデータ仮想化の一つでしょう。Azure Blob StorageやHadoopのデータをSQL Serverのインターフェースで隠蔽しています。
それに近い文脈でAzure Synpaseにもそのような機能がありますね。
また、Dynamics 365 にはODataプロトコルを通じて、Dynamics 365 上のデータかのように扱う機能「Virtual Entities」があったりします。
AWSを見渡してみると先程紹介した Babelfish for Aurora PostgreSQLはもちろん、Amazon AthenaもAmazon S3のデータを仮想的に扱うことができるサービスなので今回の例に含まれます。
GCPでは「BigQuery Omni」が昨年大きく話題になりましたね。Amazon S3やAzure Blob StorageのデータをBigQuery上で透過的に扱うことができるサービスです。

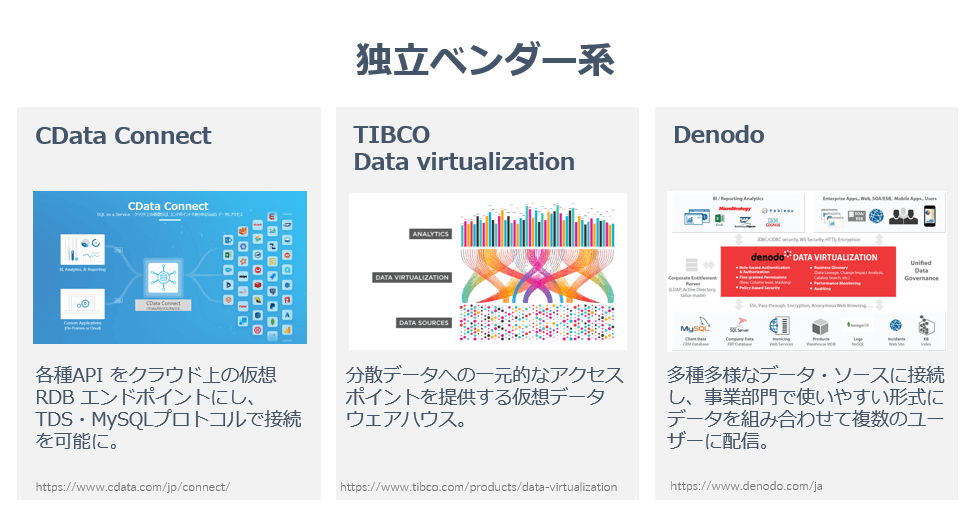
独立系やオープンソースを見渡せばさらに多くの製品が存在します。
CData で提供している CData Connectは Salesforceや Dynamics 365 等の各種サービスをTDS・MySQL Wire Protocol・ODataの3種類の仮想化しています。
TIBCOやDenodeはDWHとして様々な分散データを仮想化するサービスとしてよく知られていますね。
ここまで読んでいれば、勘の良い方ですとイメージが湧くと思うのですが、元をたどっていくと、Hadoopのエコシステムに到達しますね。
分散ファイルシステムの抽象化、分散コンピューティングの抽象化、そしてそれらを統括するAPIを抽象化を持って、Hadoopのエコシステムは様々な既存のアプリケーションとの互換性をもたせることを可能にしました。
それらの要素が今Hadoop内部のファイル群だけでなく、クラウド全体に広がっていると考えることができます。
まとめ
このように、データアクセス仮想化はみなさんの身の回りにすでに存在している一つの技術要素だったりします。
とはいえ、ここまでデータアクセス仮想化すごいよと述べてきましたが、もちろん注意は必要です。
やはりベースになっているネイティブのAPIを直接利用する方法と、データアクセス仮想化とでは、実装の自由度やパフォーマンス・チューニングの幅で差が出てしまいます。

ポイントとしてはどこまで利便性を追求するのか? です。利用するシナリオや使うツールが固まっていれば、利便性を享受しやすいでしょう。
内部で行っている技術スタックは複雑怪奇な感じで捉えられるかもしれませんが、普段身の回りで使っているツール・サービスがそれらのインターフェースを利用している、そして活用できる要素であると知ると、実に身近な気がしてきませんか?
そして、こういったアプローチを知っていて、自分たちの連携手段の一つにできることをおさえておくだけでも、連携に対する敷居がぐっと下がるのがこの「データアクセス仮想化」の大きなポイントです。
BIツールやETLツールの中でDBに接続できない製品はほとんど存在しません。
また、PowerAppsなどの昨今存在感を増しているローコードツールやiPaaSなどもDBのインターフェースをサポートしているものが数多くあります。
ガリゴリAPIのロジックを書くだけでなく、データ仮想化を活用する選択肢も是非このクラウド時代の連携手段の一つとして携えてもらえればと思います!
最後に
というわけで CData Software Advent Calendar 2021 1日目の記事でした!
qiita.com
関連コンテンツ



