
Gone are the days when businesses ran on paper records: One analog medium, “reusable” by re-entering the same data on a different piece of paper or photocopying the data for backup or reuse. Modern businesses create value by leveraging data from scores of diverse sources. During its lifetime, that data will be collected, processed, and then stored in many places and formats.
Understanding where data comes from and how it flows through the organization is crucial for the health of your data pipeline. It’s also crucial if you need to comply with relevant data regulations.
What is data lineage?
Data lineage refers to the process of recording and tracking data’s entire journey through the business pipeline. The result is a visualization of how the data moves within an environment. That visualization enables businesses to track where the data comes from, how it has been transformed, and all the locations where it has been stored.
The best data lineage practices take into account all eight phases of the data lifecycle:
Generation of the original data at the source
Collection of data from internal and external sources
Processing of the raw data so that it can be used in combination with other data
Storage of the data in a suitable location, such as a data warehouse or a data lake
Management of the data, ongoing
Analysis of some or all the data
Visualization of some or all the data
Interpretation of the data
Of these, only generation and collection happen only once.
If data is duplicated, a single iteration of that data might be processed, stored, analyzed, and interpreted only once. However, data reuse can create multiple branches from the original, resulting in each branch having a different processing, storage, management, analysis, visualization, and interpretation “fingerprint”.
This makes tracking data lineage an extremely complex task.
How data lineage is tracked
Data lineage collects metadata as the data flows through different systems. This metadata is used to generate a map that shows all the places where the data interacted with other processes or applications, and its ultimate destination or product.
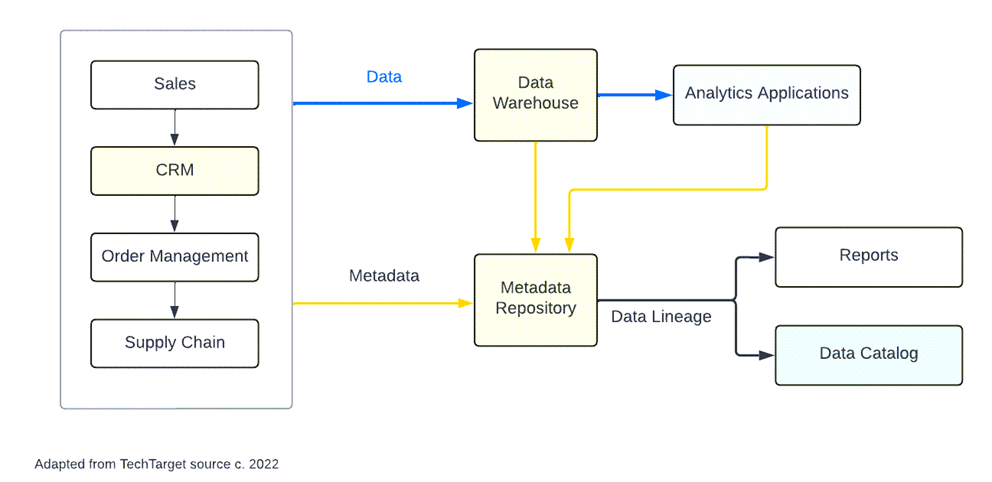
The result of a data lineage analysis is a data lineage diagram: A visual representation of all the places the data has been in the system. The diagram is updated dynamically as the data continues to pass through the system.
Why is data lineage important?
After it is collected, every process that data undergoes is another opportunity for error. By identifying the precise journey each piece of data makes through the system, data lineage creates several benefits.
Improves data quality
Data lineage facilitates the creation of a data mapping framework, which helps identify, track, and correct data processing errors.
Data lineage can also communicate the impact radius of a given data quality incident, so you understand what data assets have been affected, who’s using them, and what to keep an eye on as you begin the incident management process.
Ensures data integrity & compliance
Data lineage helps companies meet data governance goals and lower the cost of regulatory compliance. The details tracked in data lineage feed directly into compliance auditing requirements. They also improve risk management and ensure that data is stored and processed according to regulatory standards.
Improves scalability
As a business grows, its ability to get by using manual IT tasks begins to erode. Manually tracing the lineage of several tables with three or four main data sources does not scale once there are 100 or more tables across 20 data sources, with assets consumed by five different teams.
Because data lineage practices create a clean blueprint of where data enters the system, where it stops to be processed, and where it winds up, it’s a great aid to implementing process changes. It also provides insight that empowers data teams to resolve data quality incidents quickly and well, reducing the impact of data downtime.
Improves data analysis & business performance
Data lineage focuses on validating data accuracy and consistency by enabling users to search upstream and downstream, from source to destination, to discover anomalies and correct them. Validated, trusted data on hand yields explainable BI (Business Intelligence), which is crucial for making business technology decisions.
With explainable BI you can:
Migrate systems with confidence
Lower the cost of new IT development and application maintenance
Combine new datasets and existing datasets with an agile data infrastructure
Democratize data throughout the organization, increasing trust and reliance on that data
Improve data analysis
Data lineage techniques
This section describes several techniques you can use to track data lineage on strategic datasets.
Pattern-based lineage
Pattern-based lineage evaluates data sets based on metadata for tables, columns, and business reports. (That is, it analyzes the data without dealing with the code used to generate or transform the data.) Once the metadata is obtained, it looks for patterns. For example, if two datasets include a column with a similar name and similar data values, it is likely that they share data in two stages of its life cycle. To note this possible relationship, the two columns are linked together in a data lineage chart.
The advantage of pattern-based lineage is that it is technology-agnostic; it can be used the same way across any database technology. The disadvantage is that this method is not always accurate. If the data processing logic is hidden in the programming code and not apparent in the human-readable metadata, pattern-based lineage can sometimes miss connections between datasets.
Self-contained lineage
Self-contained lineage can be performed in a data environment that provides storage, processing logic, and master data management (MDM) for central control over metadata. One example of such an environment is a data lake, which stores all data in all stages of its lifecycle. This kind of self-contained system inherently provides lineage without the need for external tools.
However, self-contained lineage is unaware of anything that happens outside of the self-contained environment. The insights that can be gained are limited by the closed nature of the containing environment.
Lineage by data tagging
Lineage by data tagging tracks data that has been marked or tagged by a transformation engine. In this case, the process tracks the data’s tag from the start to the end of the data’s journey through the system.
This method can be very effective if your environment has a single transformation tool that controls all data movement, and you are aware of the tagging structure used by the tool. However, as with self-contained lineage, this method is limited by the closed nature of the containing environment. It cannot be applied to any data generated or transformed without the tool.
Lineage by parsing
Lineage by parsing is the most advanced form of data lineage tracking. It reverse-engineers data transformation logic to perform comprehensive, end-to-end tracing of data through the system.
This solution is complex to deploy because it requires access to all the logic that is used to process all the data in your environment. That means it needs to understand all the programming language and tools your company uses to transform and move data. This could include ETL logic, SQL-based solutions, JAVA solutions, XML-based solutions, and legacy data formats.
Data lineage examples & use cases
This section explores some common use cases of data lineage in businesses.
Impact analysis
Data lineage tools can provide visibility into the impact of specific business changes, such as any downstream reporting. For example, if the name of a data element changes, data lineage can help leaders understand how many dashboards that might affect, and by implication how many users.
Data lineage tools can also help assess the impact of data errors and the exposure across the organization. Data errors, which can occur for a myriad of reasons, may erode trust in certain business intelligence reports or data sources. However, data lineage tools can help teams trace them to the source, enabling data processing optimizations and improving communication to the affected teams.
Data governance
Data governance processes govern compliance with patient data regulations like HIPAA and GDPR. These regulations protect patient privacy and facilitate secure information-sharing that is critical for the highest level of patient care, and they impact every area of healthcare, including biotechnology companies, health insurance providers, medical device manufacturers, and pharmaceutical companies.
Detailed data lineage maps help ensure that you are processing and securing data within HIPAA and GDPR requirements. They also supply a clear chain of custody to auditors, who will need to see who has had access to your regulated data assets and apply stricter controls around who has access.
Data modeling
Data lineage tools help companies create visual representations of the different data elements and their corresponding linkages within an enterprise, defining their underlying data structures and exposing the different dependencies across the data ecosystem. Since data evolves over time, new data sources are constantly emerging, prompting the need for new data integrations. Data lineage helps to identify and manage these changes over time through data model diagrams, which highlight new or outdated connections or tables.
Data migration
Data lineage tools assist with changes or extensions to their data storage systems by showing how this data has progressed through the organization to date. It also provides teams with the opportunity to clean up the data system, archiving or deleting old, irrelevant data. And as we all know, cleaning out old, irrelevant cruft can reduce the amount of data a system needs to manage, improving the overall performance of the data system.
Simplify your data landscape with CData Connect AI
Data lineage gets harder every time data is copied, moved, or transformed across systems. CData Connect AI reduces that complexity by providing governed, live connectivity to over 350 enterprise data sources — without moving or replicating data from where it resides. With centralized access controls, full audit trails across every AI and user query, and role-based permissions inherited from the source, Connect AI helps you maintain a cleaner, more traceable data environment from the start.
Try CData Connect AI today
Get a free trial of CData Connect AI to see how governed, live data connectivity can help you maintain a cleaner, more traceable data environment across your enterprise.




