
With the right data warehousing solution, you can efficiently scale operations, refine analytics, safeguard data, and gain the flexibility needed for continued growth. Snowflake is an advanced data warehousing platform that stands out as a top choice for businesses seeking to streamline their data operations.
Migrating data from PostgreSQL (commonly known as Postgres) to Snowflake lets businesses tap into Snowflake’s powerful data warehousing features. With its capability to manage large datasets, scale efficiently, and integrate with various tools, Snowflake is ideal for improving data management.
The migration from Postgres to Snowflake, however, can be challenging due to compatibility issues, performance differences, and the complexity of transferring large datasets. For example:
- SQL syntax differences: Queries may need manual adjustments due to differing SQL syntax.
- Data type variations: Numeric and other data types might behave differently, leading to unexpected results.
- Complex data transformations: Some data transformations and aggregations might need reengineering to fit Snowflake’s architecture.
- JSON and NULL value handling: Snowflake uses different functions for processing JSON and null values, requiring modifications to existing Postgres queries.
This guide will walk you through a step-by-step approach to efficiently loading data from Postgres into Snowflake, outlining key strategies, tools, and best practices to streamline the migration process. By the end of this blog, you’ll have the clear foundation needed to ensure a smooth and effective migration that maximizes the capabilities of both platforms.
Understanding Postgres and Snowflake
What is Postgres?
PostgreSQL is a reliable, open-source relational database management system known for its extensibility and SQL compliance. It’s ideal for transactional databases and supports a variety of data types, indexing methods, and complex queries.
Key features
- High-performance transactions: PostgreSQL is designed for high-performance transaction processing using advanced isolation levels and locking mechanisms to ensure data integrity even under heavy loads.
- Complex data modeling: It supports sophisticated data modeling techniques, including table inheritance, triggers, and stored procedures, enabling more complex database structures.
- Extensible architecture: You can create custom data types, operators, and functions in PostgreSQL, adapting the database to specific use cases.
- Advanced SQL support: PostgreSQL efficiently handles complex queries, including joins, subqueries, and window functions, ensuring robust querying capabilities.
- JSON support: With strong support for JSON, PostgreSQL enables both SQL and JSON-based querying of semi-structured data for flexible data management.
- Concurrency control: It employs Multi-Version Concurrency Control (MVCC) to handle concurrent transactions efficiently, maintaining smooth operation even with multiple users.
- Indexing: PostgreSQL supports various indexing methods, such as B-tree, Hash, and GIN, optimizing query performance across diverse data types.
What is Snowflake?
Snowflake is a cloud-native data warehousing solution with a decoupled compute and storage architecture, allowing for independent scaling and dynamic resource adjustment.
Key features
- Decoupled compute and storage: Snowflake enables the independent scaling of compute and storage resources, allowing for optimal cost management and performance efficiency.
- Elastic scalability: It can automatically adjust resources in real time to handle varying workloads, ensuring that performance remains consistent under different conditions.
- Native support for semi-structured data: Snowflake efficiently manages and queries semi-structured data formats such as JSON, Avro, and Parquet, making it versatile for diverse data needs.
- Concurrency management: Its multi-cluster architecture effectively handles high user concurrency, ensuring smooth and efficient query execution even with numerous simultaneous users.
- Automatic scaling and optimization: Snowflake automates the scaling and optimization of resources, significantly reducing the need for manual tuning and administrative effort.
- Integrated security: It provides robust security features, including advanced encryption and adherence to industry compliance standards, ensuring data protection and regulatory compliance.
- Zero management: Routine administrative tasks, such as backups and system maintenance, are automated, greatly reducing the administrative overheads.
6 Reasons to migrate PostgreSQL data to Snowflake
- Adding flexibility, scalability, and security: Snowflake offers independent scaling of compute and storage, optimizing performance and cost. Its robust security features ensure data protection throughout and after migration.
- Building a data warehouse: Designed for data warehousing, Snowflake provides features like automatic clustering, instant scaling, and time travel, enhancing your warehousing capabilities beyond PostgreSQL.
- Unlocking advanced analytics capabilities: Snowflake’s powerful analytics engine handles complex queries quickly, enabling advanced analytics such as predictive modeling and real-time data processing for deeper insights.
- Leveraging AI/ML capabilities: Snowflake supports scaling for data-intensive machine learning (ML) models and artificial intelligence (AI) algorithms. It integrates with platforms like TensorFlow and PyTorch, enhancing your machine learning and AI capabilities.
- Breaking down data silos: Snowflake consolidates data from various sources into a unified platform, eliminating data silos and ensuring all stakeholders have timely access to necessary data.
- Harnessing an expanded ecosystem of integrations and tools: Snowflake connects with cloud services, ETL (extract, transform, load) tools, and business intelligence platforms like Tableau and Power BI, streamlining data workflows and enhancing management and analytics capabilities.
How to replicate data from Postgres to Snowflake: 3 approaches
Manual connection from PostgreSQL to Snowflake
Manual replication involves exporting data from PostgreSQL using SQL commands like COPY TO, transferring CSV files to Snowflake’s stages, and importing them using COPY INTO. This process provides full control over the data but can be time-consuming and requires careful monitoring of file transfers and schema compatibility.
Here’s how to do it:
1. Export data from PostgreSQL
Use the COPY command to export your PostgreSQL data to a CSV file. Run the following SQL command from your PostgreSQL terminal:
COPY table_name TO '/path/to/exported_file.csv' DELIMITER ',' CSV HEADER;
This command will export the data from table_name to a CSV file at the specified path.
2. Prepare Snowflake for data loading
Create a Snowflake table: If you don’t already have a corresponding table in Snowflake, create one that matches the structure of your PostgreSQL table.
CREATE OR REPLACE TABLE snowflake_table_name (
column1 datatype,
column2 datatype,
...
);
3. Transfer the CSV file to your local machine
Once the data is exported from PostgreSQL, move the file to your local system for uploading.
4. Upload the CSV file to Snowflake using the PUT command
Create an internal Snowflake stage: Before uploading data to Snowflake, create a staging area where you will temporarily store the CSV file.
CREATE OR REPLACE STAGE my_internal_stage;
Upload the CSV file: Use the SnowSQL command-line tool to upload the CSV file to the internal Snowflake stage.
snowsql -q "PUT file:///path/to/exported_file.csv @my_internal_stage"
5. Load data into Snowflake
Load the data: After uploading, load the CSV file into your Snowflake table using the COPY INTO command.
COPY INTO snowflake_table_name
FROM @my_internal_stage/exported_file.csv
FILE_FORMAT = (TYPE = CSV FIELD_OPTIONALLY_ENCLOSED_BY='"' SKIP_HEADER=1);
6. Verify data in Snowflake
Check the data: Run a simple query to verify that the data was correctly imported into Snowflake.
SELECT * FROM snowflake_table_name LIMIT 10;
Loading data from PostgreSQL to Snowflake via Amazon S3
This approach utilizes Amazon S3 as an intermediary for data replication, a scalable option for large datasets.
Here’s how to do it:
1. Export the data
Export PostgreSQL data to CSV:
COPY table_name TO '/path/to/file.csv' DELIMITER ',' CSV HEADER;
2. Upload to S3
Upload CSV to S3 using AWS CLI:
aws s3 cp /path/to/file.csv s3://bucket-name/
3. Create a Snowflake stage
Define an external Snowflake stage:
CREATE OR REPLACE STAGE my_s3_stage
URL='s3://bucket-name/'
CREDENTIALS=(AWS_KEY_ID='key' AWS_SECRET_KEY='secret');
4. Load the data
Load CSV from S3 into Snowflake:
COPY INTO snowflake_table
FROM @my_s3_stage/file.csv
FILE_FORMAT = (TYPE = CSV FIELD_OPTIONALLY_ENCLOSED_BY='"'
SKIP_HEADER=1);
5. Verify the data
Ensure data is loaded:
SELECT * FROM snowflake_table;
Using CData Sync for automated PostgreSQL replication to Snowflake
CData Sync offers real-time, customizable replication from PostgreSQL to Snowflake. It requires little to no coding and is ideal for always-on applications requiring automatic failover and continuous data access.
Here’s how to do it:
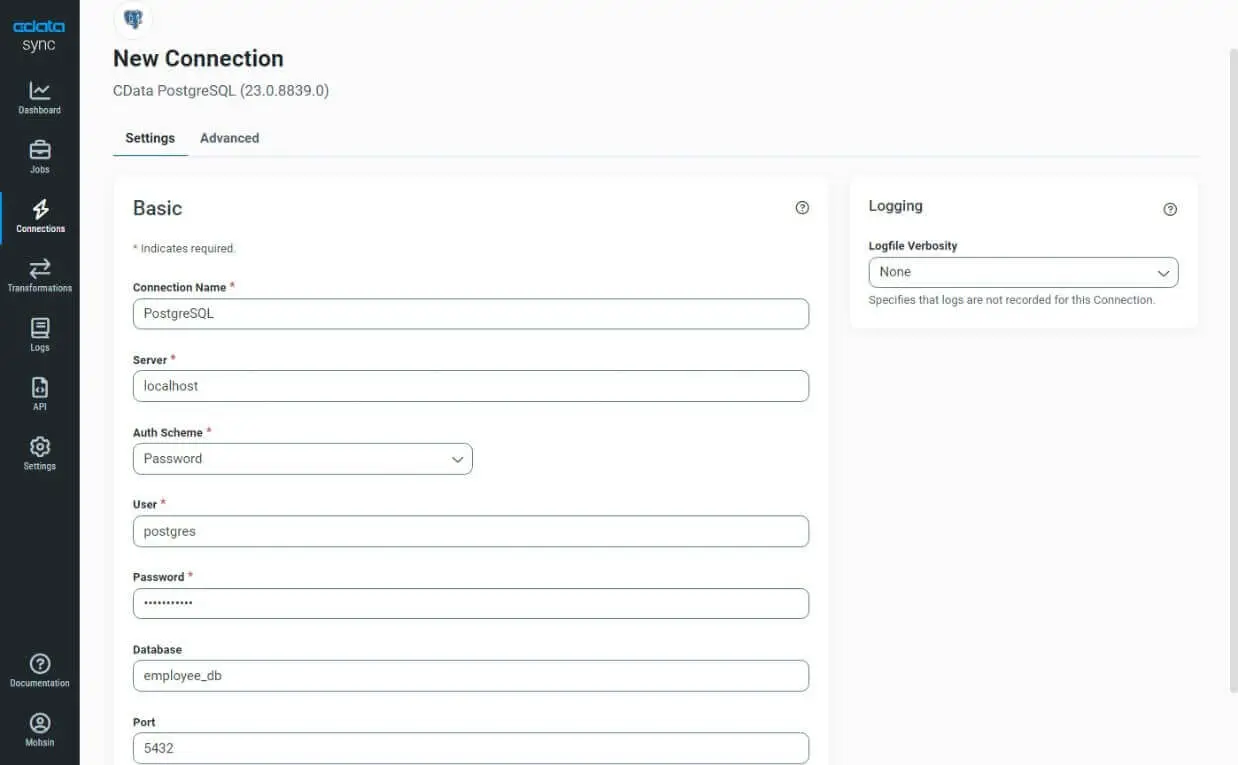
- Configure PostgreSQL as the source:
- In the CData Sync interface, go to the Connections tab on the left, click the Add Connection button, and search for PostgreSQL under Sources.
- Add the connection by entering the following basic details: Connection Name, Server, Auth Scheme, User, Password, Database, and Port.
- OPTIONAL: Configure additional settings in the Advanced section, such as security and authentication type. For more details, read the complete documentation.
- Test and save the connection by clicking Create & Test on the top right.
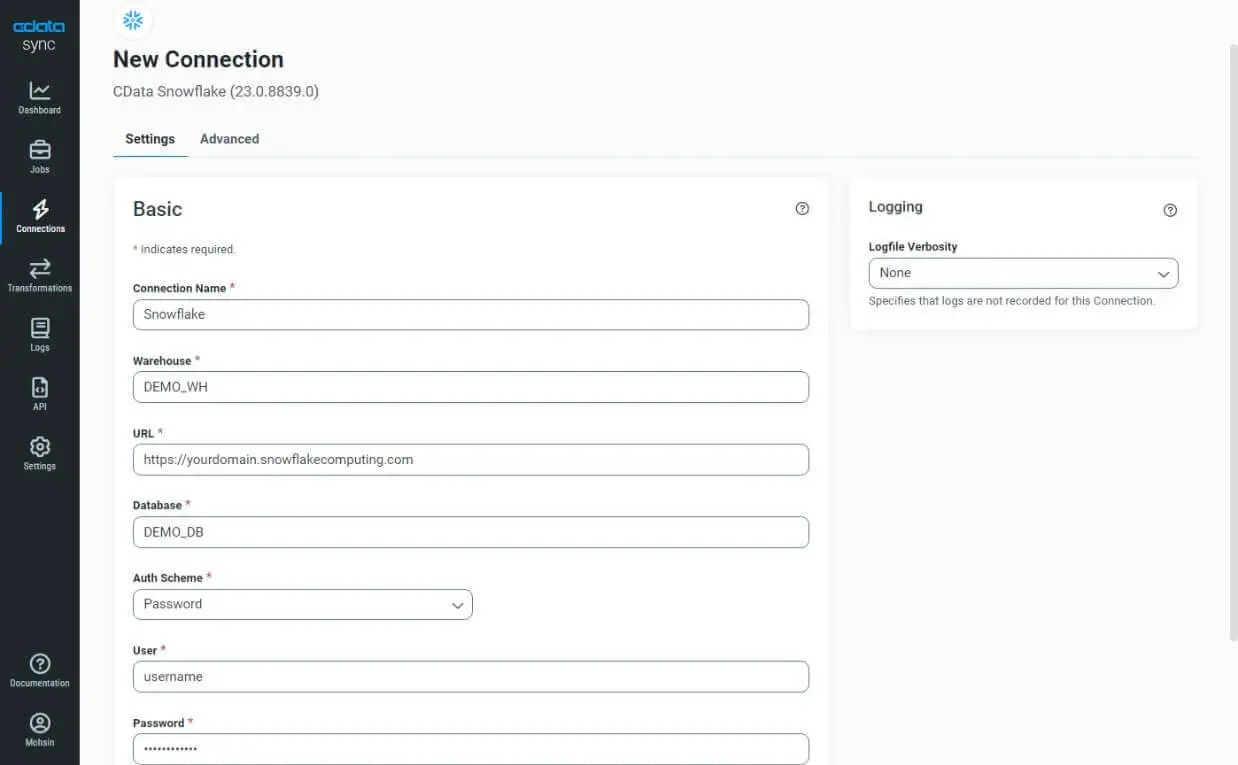
- Configure Snowflake as a destination:
- In the CData Sync interface, go to the Connections tab on the left, click the Add Connection button, and search for Snowflake under the Destinations
- Add the connection by entering the following basic details: Connection Name, Warehouse, URL, Database, Auth Scheme, User, Password, and Schema.
- Test and save the connection by clicking Create & Test on the top right.
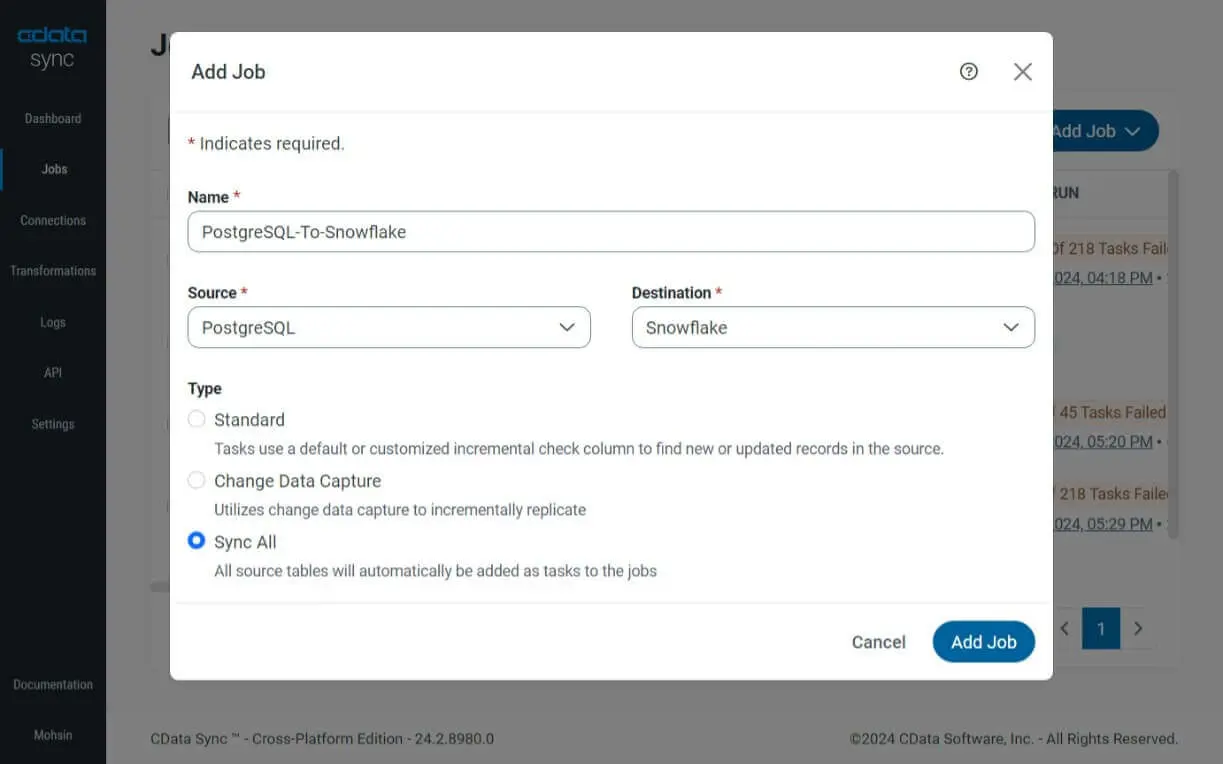
- Set up a replication job:
- Navigate to the Jobs tab on the left, click the Add Job button, and select Add New Job.
- Enter a name for the job in the Name section and select Source as PostgreSQL and Destination as Snowflake from your newly added connections.
- Choose the replication method based on duration, date change, or other options under Type, and then click the Add Job
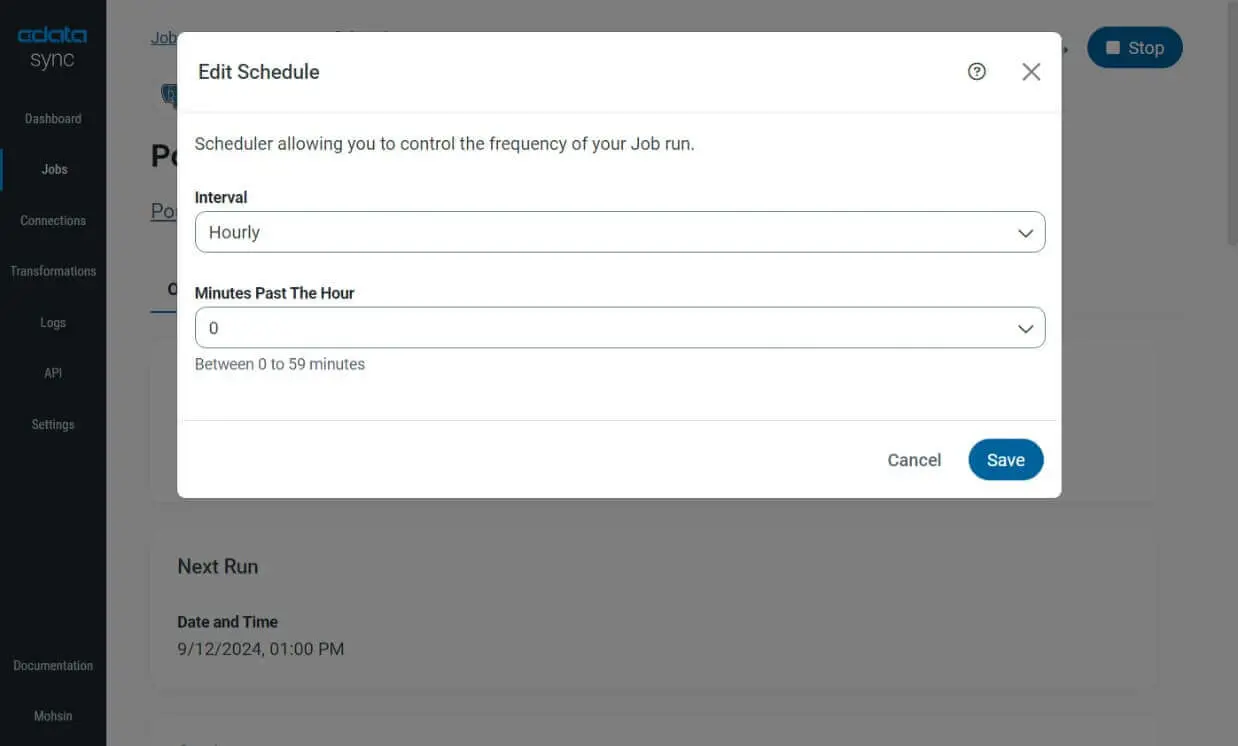
- Schedule and run the replication:
- On the Jobs page, click the Configure button under the Schedule section on the right and set up automatic replication intervals (e.g., every 10 minutes or monthly).
- Run the job by clicking the Run button on the top right and monitor the replication status in the dashboard.
This method is the easiest and fastest among all three approaches. CData Sync automates data replication with minimal configuration, offering real-time updates and reducing the need for manual intervention—perfect for streamlining workflows and ensuring that data is current and accessible.
Automate data migration with CData Sync
Now that you're familiar with the methods for migrating data from PostgreSQL to Snowflake, it's time to streamline the process. For automated, continuous, and customizable PostgreSQL replication to Snowflake, CData Sync provides a reliable and easy-to-use solution. Its low-code interface allows for easy setup and management, handling complex data workflows and keeping your data warehouse synchronized with operational databases efficiently.
Automate your data operations — start your free trial of CData Sync today and unlock the full potential of your data.
Explore CData Sync
Get a free product tour to learn how you can migrate data from any source to your favorite tools in just minutes.



