Consolidating Enterprise Data to a Data Lake on Amazon S3 with CData Sync

We recently discussed the benefits and challenges involved in building a data warehouse and gave an example with Google BigQuery. BigQuery is only one of many popular solutions for data warehousing. Lately, flat-file ingestion-based destinations have become popular due to their ubiquity for data export and their use as the storage basis for data lakes.
Amazon Simple Storage Service (S3) is one possible flat-file replication destination from CData Sync. Replicating your SaaS, big data, and NoSQL data sources as to S3 makes it ready to be queried and analyzed through the full suite of Amazon Web Services, like Amazon Athena and Amazon QuickSight. And since the data is replicated as flat files, it is easily consumable by other popular tools capable of consuming delimited file data.
Replicating Your Data for Use in the AWS Ecosystem
Storing, accessing, querying, and analyzing your enterprise data in the AWS ecosystem is accomplished in four straightforward steps.
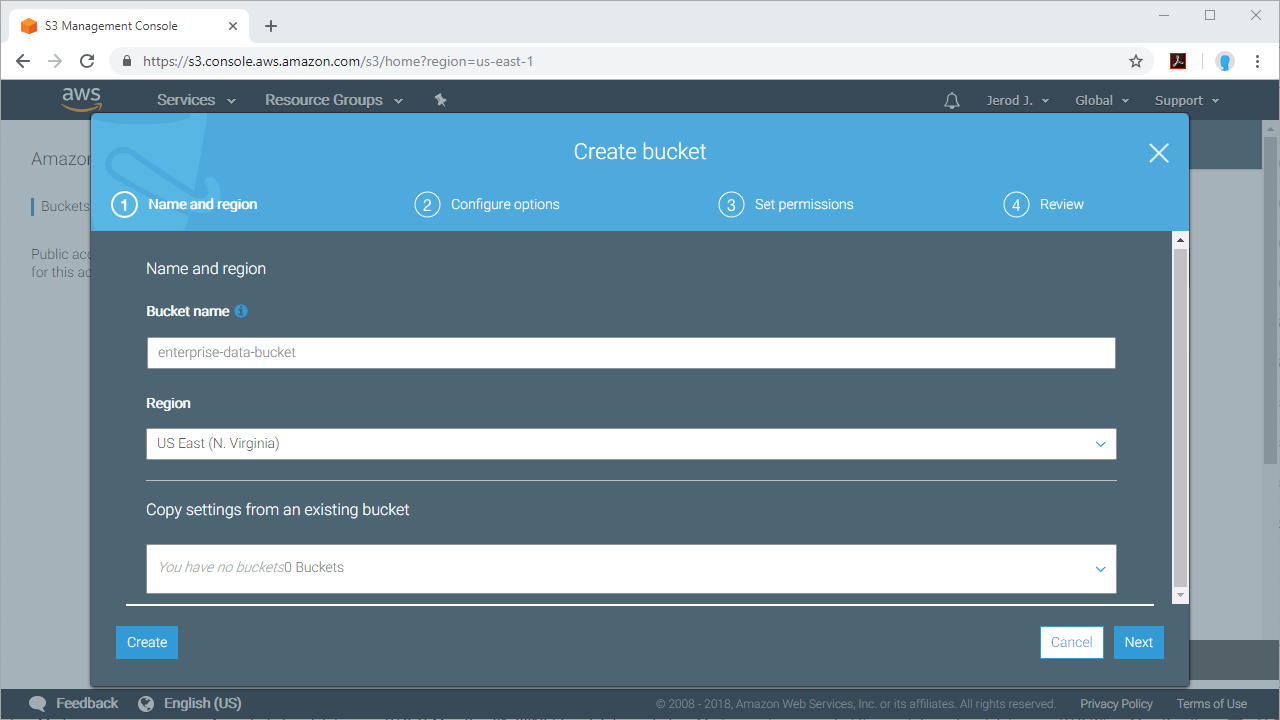
1. Configure Amazon S3 as a destination for CData Sync
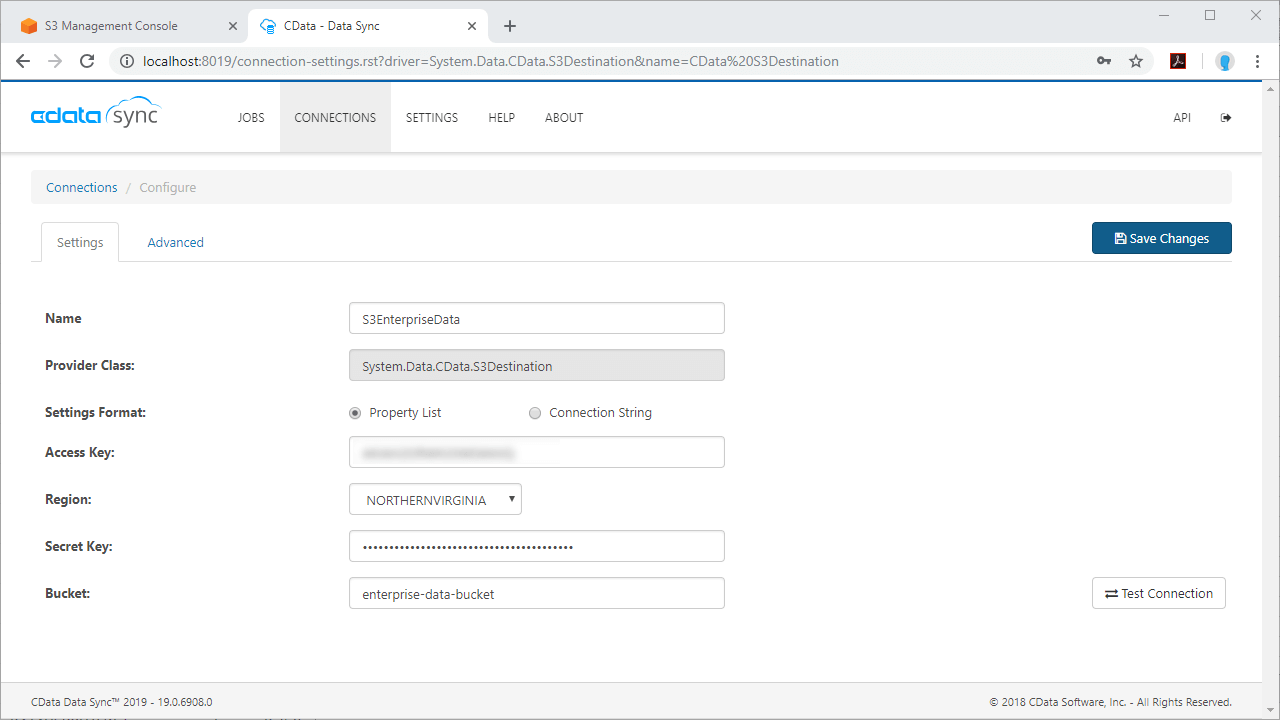
2. Set up CData Sync to replicate data to Amazon S3
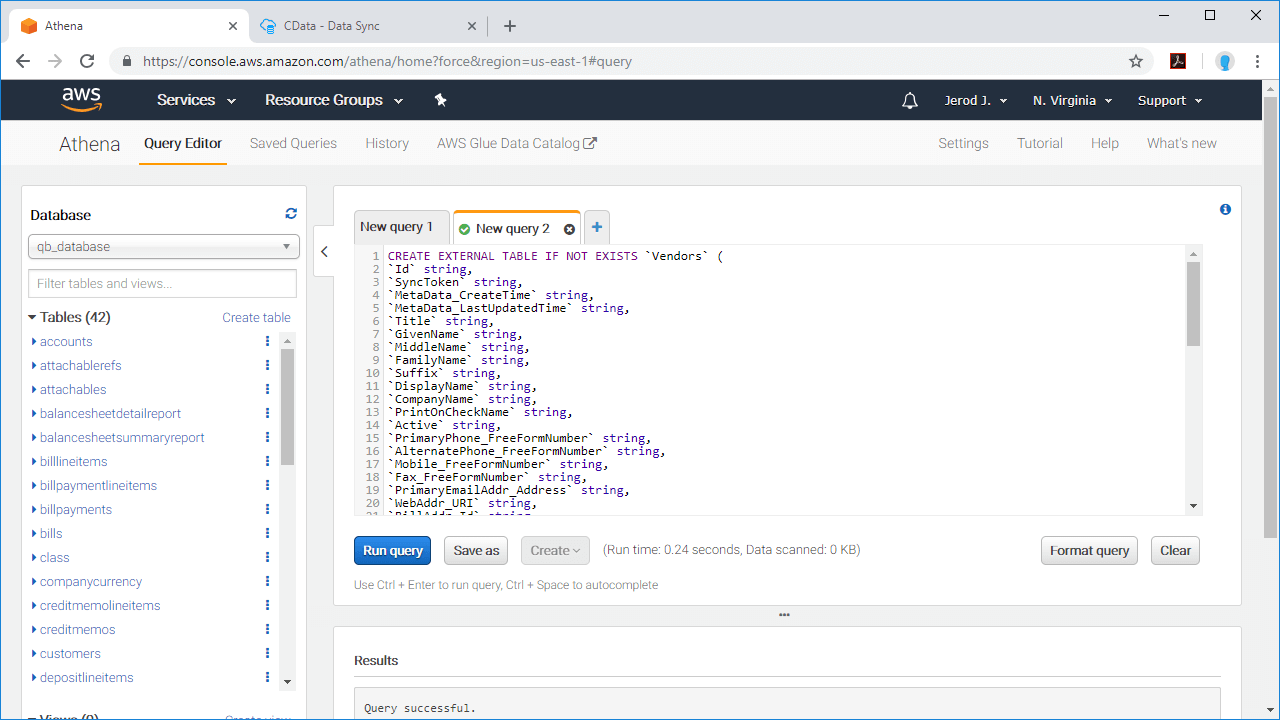
3. Configure Amazon Athena to query the data replicated to Amazon S3
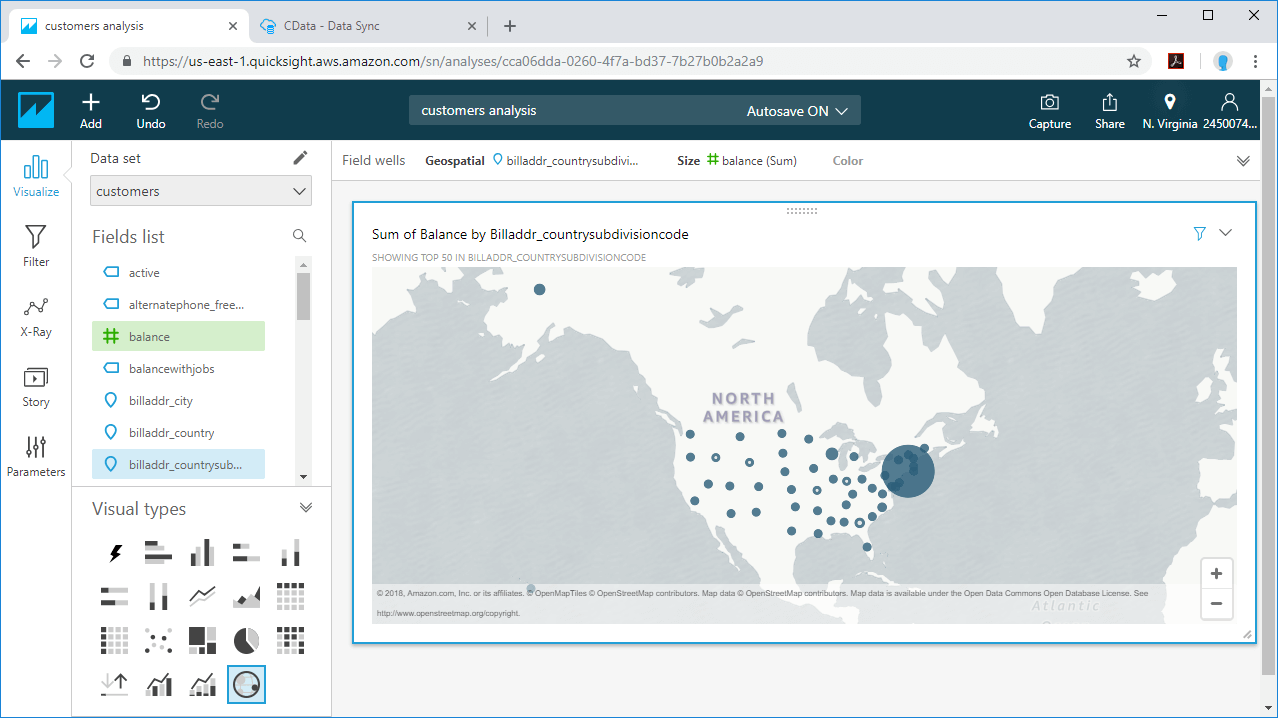
4. Utilize Amazon QuickSight to visualize the replicated data via Amazon Athena
Read the Full Article
For a detailed walk-through of the steps above to use CData Sync to replicate data to Amazon S3 and then query and visualize the replicated data in Amazon Athena and Amazon QuickSight, read our Knowledge Base article.
Continue to the Full Article »
CData Sync allows you to use Amazon S3 as a common data store for all of your enterprise data, which opens your data up to the full suite of tools, applications, and platforms capable of performing analytics, ML, and AI on data stored in S3.
Key CData Sync Features
CData Sync dramatically simplifies the process of aggregating enterprise data - from any data source to any destination. Features include:
- Support for more than 100 data sources, including every major database and data storage destination.
- Easy configuration: tables are created in the replication destination, as needed, for each table (entity) in the original data source.
- Incremental data replication: only entries added or updated since the last replication are included in the replication job.
- Fully customizable replication and data transformation: select specific columns (fields), filter data, create aggregations, and more!
Ready to get started? Download a free, 30-day trial of CData Sync today.



