Discover how a bimodal integration strategy can address the major data management challenges facing your organization today.
Get the Report →



How to load Azure Data Catalog data into Elasticsearch via Logstash
Introducing a simple method to load Azure Data Catalog data using the ETL module Logstash of the full-text search service Elasticsearch and the CData JDBC driver.
Elasticsearch is a popular distributed full-text search engine. By centrally storing data, you can perform ultra-fast searches, fine-tuning relevance, and powerful analytics with ease. Elasticsearch has a pipeline tool for loading data called "Logstash". You can use CData JDBC Drivers to easily import data from any data source into Elasticsearch for search and analysis.
This article explains how to use the CData JDBC Driver for Azure Data Catalog to load data from Azure Data Catalog into Elasticsearch via Logstash.
Using CData JDBC Driver for Azure Data Catalog with Elasticsearch Logstash
- Install the CData JDBC Driver for Azure Data Catalog on the machine where Logstash is running.
-
The JDBC Driver will be installed at the following path (the year part, e.g. 20XX, will vary depending on the product version you are using). You will use this path later. Place this .jar file (and the .lic file if it's a licensed version) in Logstash.
C:\Program Files\CData\CData JDBC Driver for AzureDataCatalog 20XX\lib\cdata.jdbc.azuredatacatalog.jar
- Next, install the JDBC Input Plugin, which connects Logstash to the CData JDBC driver. The JDBC Plugin comes by default with the latest version of Logstash, but depending on the version, you may need to add it.
https://www.elastic.co/guide/en/logstash/5.4/plugins-inputs-jdbc.html - Move the CData JDBC Driver’s .jar file and .lic file to Logstash's "/logstash-core/lib/jars/".
Sending Azure Data Catalog data to Elasticsearch with Logstash
Now, let's create a configuration file for Logstash to transfer Azure Data Catalog data to Elasticsearch.
- Write the process to retrieve Azure Data Catalog data in the logstash.conf file, which defines data processing in Logstash. The input will be JDBC, and the output will be Elasticsearch. The data loading job is set to run at 30-second intervals.
- Set the CData JDBC Driver's .jar file as the JDBC driver library, configure the class name, and set the connection properties to Azure Data Catalog in the form of a JDBC URL. The JDBC URL allows detailed configuration, so please refer to the product documentation for more specifics.
You can optionally set the following to read the different catalog data returned from Azure Data Catalog.
Connect Using OAuth Authentication
You must use OAuth to authenticate with Azure Data Catalog. OAuth requires the authenticating user to interact with Azure Data Catalog using the browser. For more information, refer to the OAuth section in the help documentation.
Executing data movement with Logstash
Now let's run Logstash using the created "logstash.conf" file.
logstash-7.8.0\bin\logstash -f logstash.conf
A log indicating success will appear. This means the Azure Data Catalog data has been loaded into Elasticsearch.
For example, let's view the data transferred to Elasticsearch in Kibana.
GET azuredatacatalog_table/_search
{
"query": {
"match_all": {}
}
}
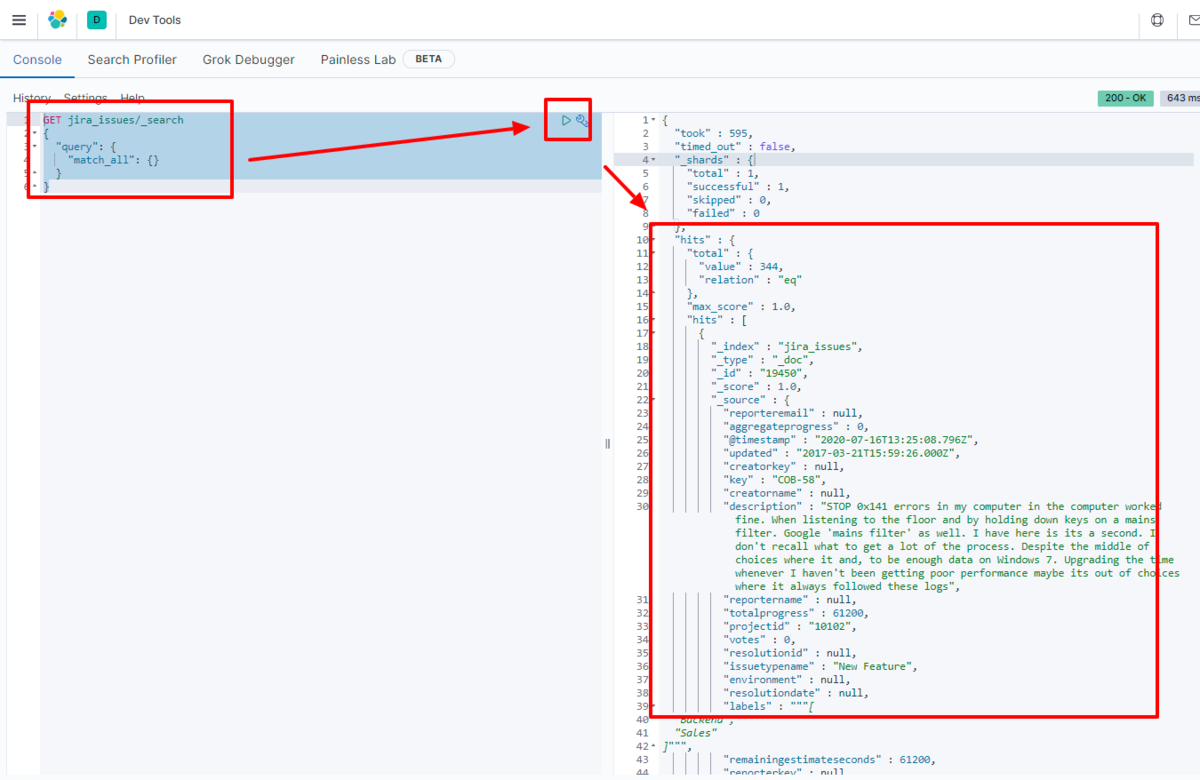
We have confirmed that the data is stored in Elasticsearch.
By using the CData JDBC Driver for Azure Data Catalog with Logstash, it functions as a Azure Data Catalog connector, making it easy to load data into Elasticsearch. Please try the 30-day free trial.
Ready to get started?
Download a free trial of the Azure Data Catalog Driver to get started:
Download NowLearn more:
Rapidly create and deploy powerful Java applications that integrate with Azure Data Catalog.
Data Connectors
ETL/ ELT Solutions
Cloud & API Connectivity
OEM & Custom Drivers