こんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
Power BI を使えば、企業のデータを豊富なビジュアルに変換して収集および整理することができるため、重要なことだけに集中できます。CData Connect Cloud と組み合わせると、ビジュアライゼーションやダッシュボード用にSpark のデータにアクセスできます。この記事では、CData Connect Cloud を使用してSpark のOData フィードを生成し、Spark のデータをPower BI にインポートして、Power BI サービスのSpark のデータに関するレポートを作成する方法について説明します。
Connect Cloud アカウントの取得
以下のステップを実行するには、CData Connect Cloud のアカウントが必要になります。こちらから製品の詳しい情報とアカウント作成、30日間無償トライアルのご利用を開始できますので、ぜひご利用ください。
Connect Cloud を構成する
Power BI online でSpark のデータを操作するには、Connect Cloud からSpark に接続し、コネクションにユーザーアクセスを提供してSpark のデータのOData エンドポイントを作成する必要があります。
Spark に接続したら、目的のテーブルのOData エンドポイントを作成します。
(オプション)新しいConnect Cloud ユーザーの追加
必要であれば、Connect Cloud 経由でSpark に接続するユーザーを作成します。
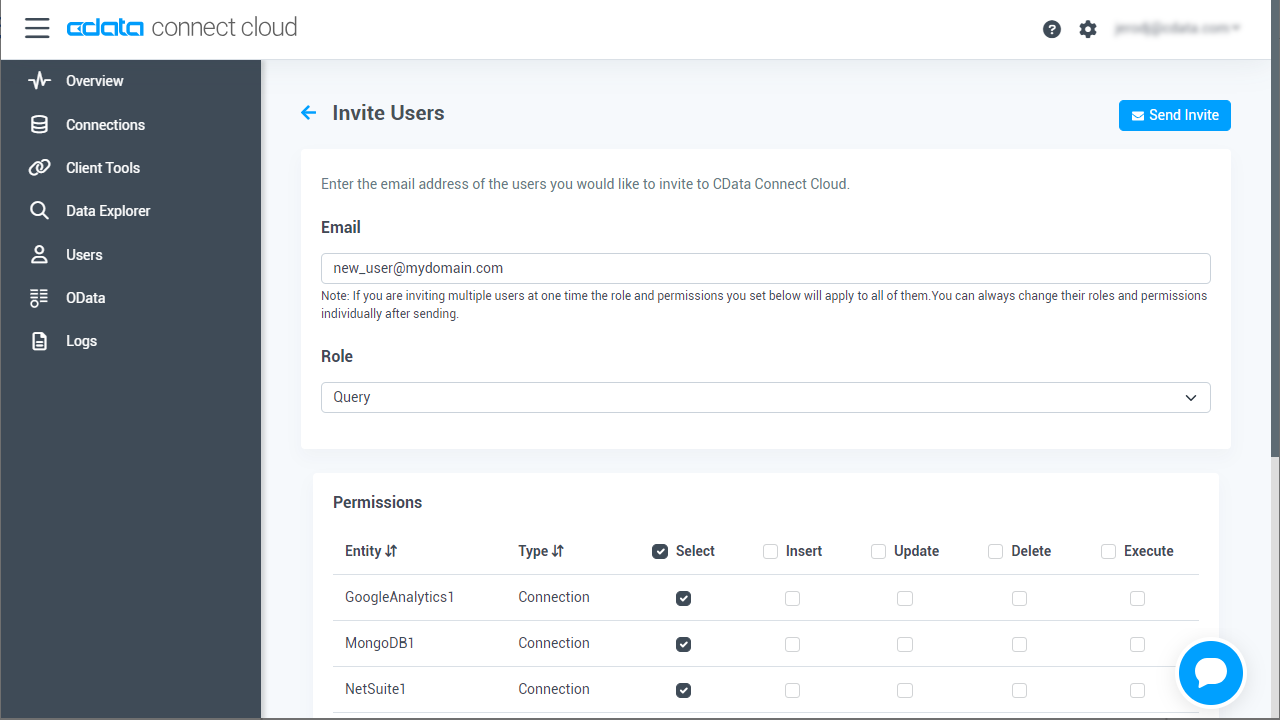
- ユーザーページに移動し、 Invite Users をクリックします。
- 新しいユーザーのE メールアドレスを入力して、 Send to invite the user をクリックします。
![新しいユーザーを招待]()
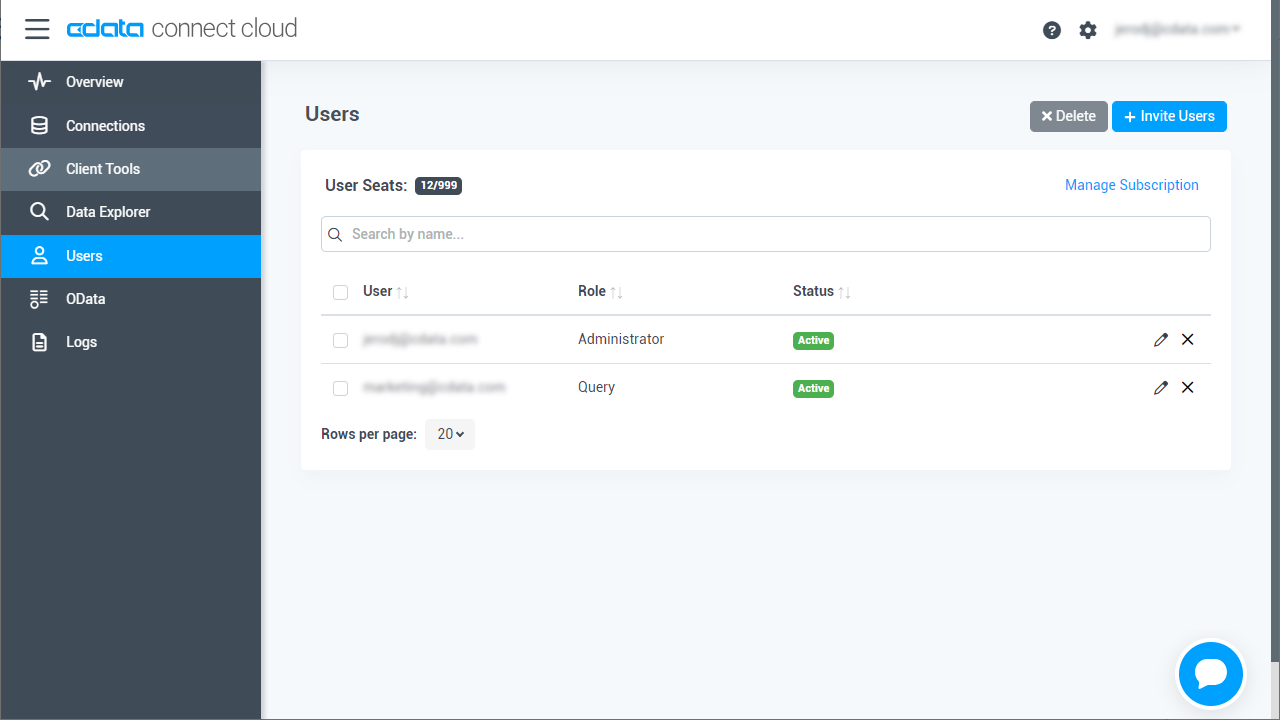
- ユーザーページからユーザーを確認および編集できます。
![Connect Cloud users]()
パーソナルアクセストークンの追加
OAuth 認証をサポートしていないサービス、アプリケーション、プラットフォーム、またはフレームワークから接続する場合は、認証に使用するパーソナルアクセストークン(PAT)を作成できます。きめ細かなアクセス管理を行うために、サービスごとに個別のPAT を作成するのがベストプラクティスです。
- Connect Cloud アプリの右上にあるユーザー名をクリックし、User Profile をクリックします。
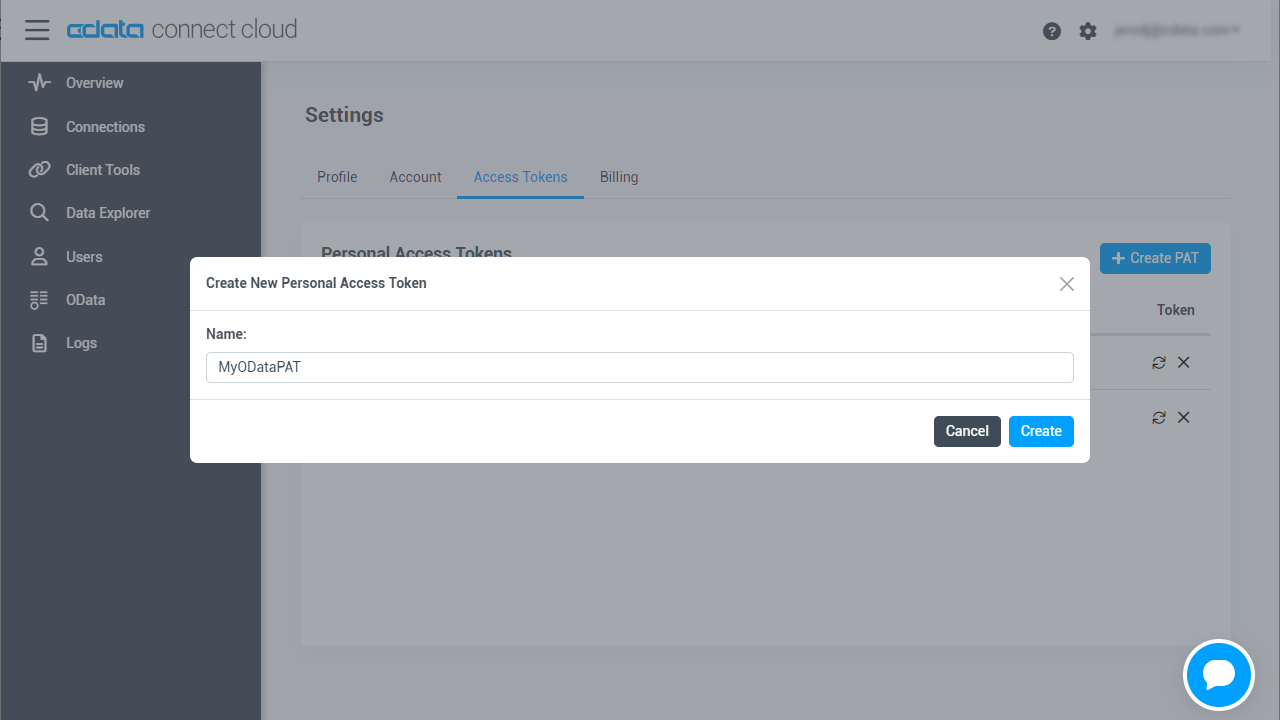
- User Profile ページでPersonal Access Token セクションにスクロールし、 Create PAT をクリックします。
- PAT の名前を入力して Create をクリックします。
![Creating a new PAT]()
- パーソナルアクセストークンは作成時にしか表示されないため、必ずコピーして安全に保存してください。
Connect Cloud からSpark に接続
CData Connect Cloud では、簡単なクリック操作ベースのインターフェースでデータソースに接続できます。
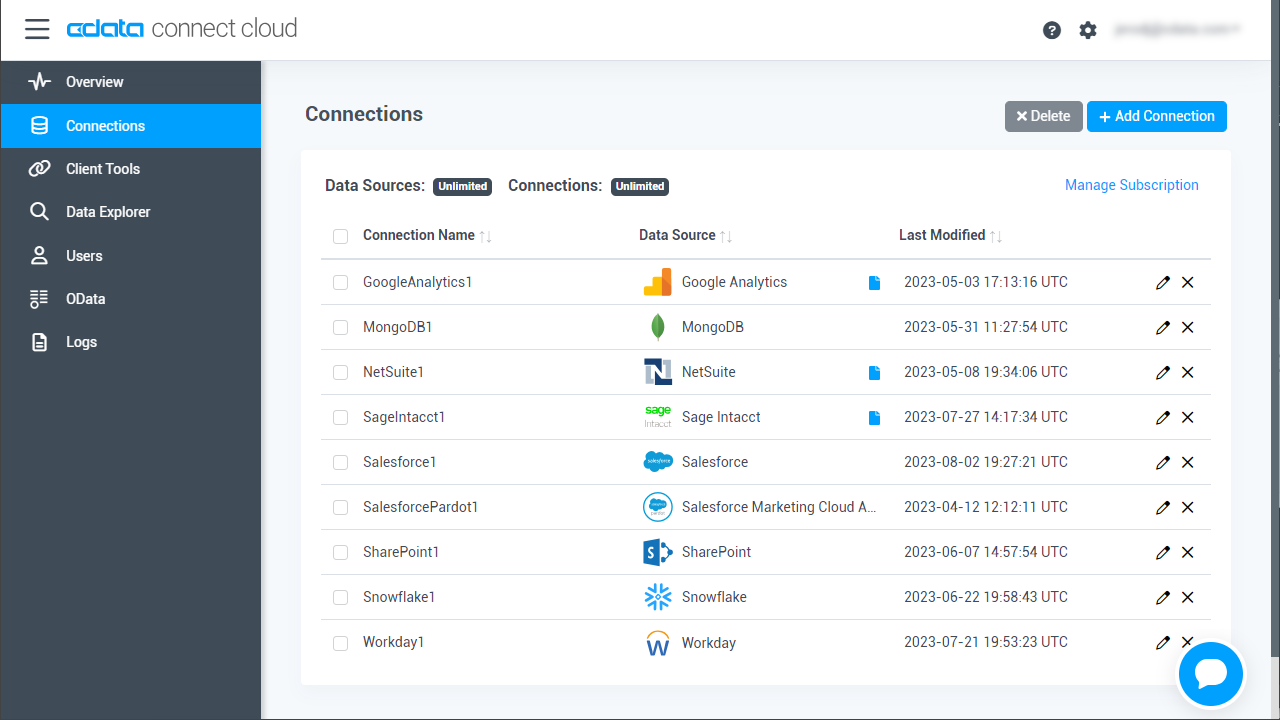
- Connect Cloud にログインし、 Add Connection をクリックします。
![コネクションを追加]()
- Add Connection パネルから「Spark」を選択します。
![Selecting a data source]()
-
必要な認証プロパティを入力し、Spark に接続します。
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、
「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
![Configuring a connection (Salesforce is shown)]()
- Create & Test をクリックします。
- Edit Spark Connection ページのPermissions タブに移動し、ユーザーベースのアクセス許可を更新します。
![権限を更新]()
Connect Cloud にSpark OData エンドポイントを追加する
Spark に接続したら、目的のテーブルのOData エンドポイントを作成します。
- OData ページに移動し、 Add to create new OData endpoints をクリックします。
- Spark コネクション(例:SparkSQL1)を選択し、Next をクリックします。
- 使用するテーブルを選択し、Confirm をクリックします。
![テーブルを選択(Salesforce の例)]()
接続とOData エンドポイントが構成されたら、Power BI online からSpark のデータに接続できるようになります。
Power BI Desktop からデータセットを公開する
Connect Cloud にOData エンドポイントを追加すると、OData 接続を使用してPower BI Desktop にデータセットを作成し、そのデータセットをPower BI サービスに公開できます。
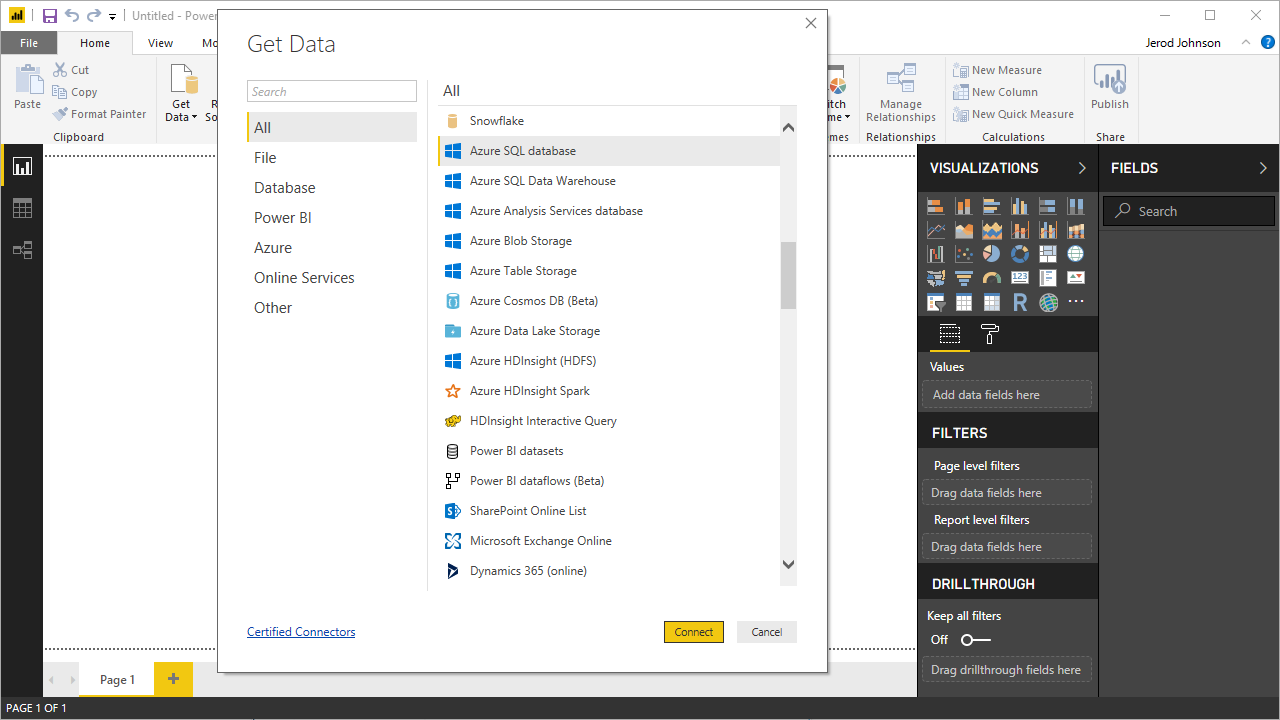
- Power BI を開いて「データを取得」-->「詳細」とクリックし、OData フィードを選択して「接続」をクリックします。
![Create a new connection in Power BI]()
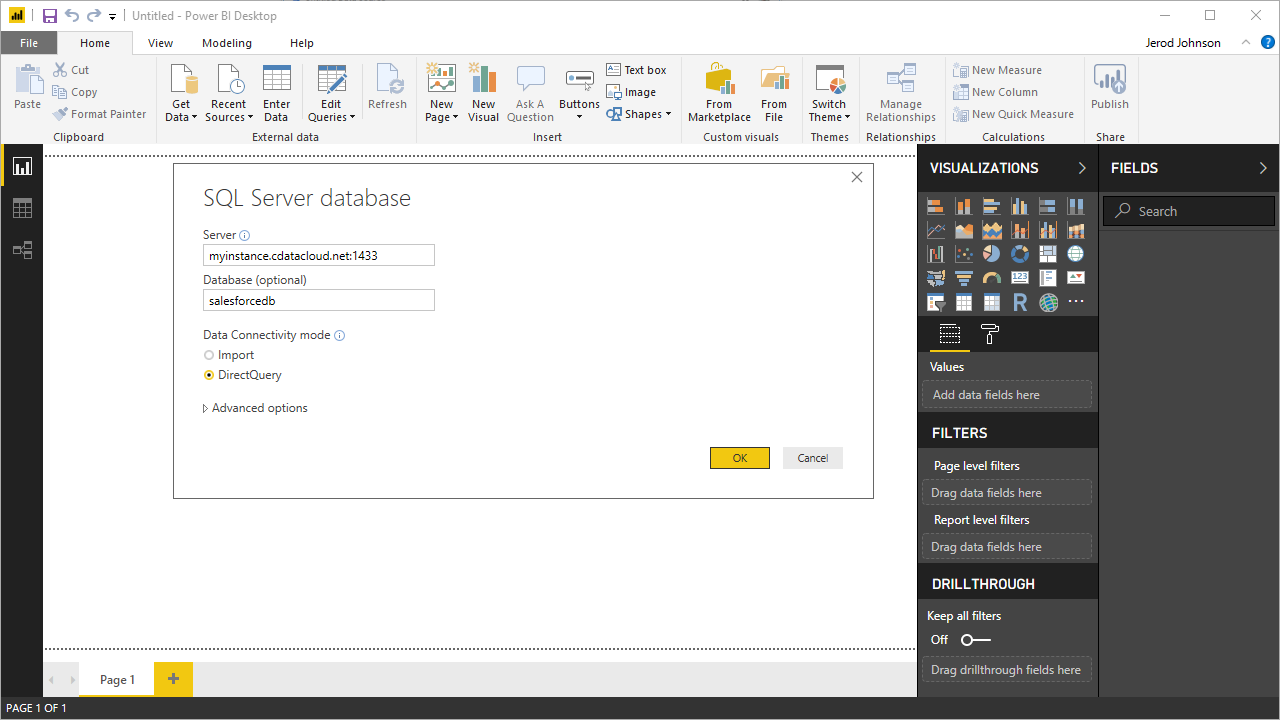
- URL をConnect Cloud インスタンスのBase URL(例: https://cloud.cdata.com/api/odata/service)に設定し、「OK」をクリックします。
- ユーザー名 とパスワード を上記のユーザー名とPAT に設定します。
- 設定を適用するレベルとして、フルのBase URL(https://cloud.cdata.com/api/odata/service)を選択します。
![Connect to Cdata Connect Cloud instance]()
- 「ナビゲーター」ダイアログでテーブルを選択し、ビジュアライズします。
- 「読み込み」をクリックしてPower BI にデータをプルします。
- 「リレーションシップ」タブで選択したエンティティ間の関連を定義します。
- 「ホーム」メニューから「発行」をクリックして「ワークスペース」を選択します。
Power BI Service のSpark のデータでレポートとダッシュボードを作成します。
Power BI サービスにデータセットを公開したので、公開されたデータに基づいて新しいレポートとダッシュボードを作成できます。
- PowerBI.com にログインします。
- 「ワークスペース」をクリックし、ワークスペースを選択します。
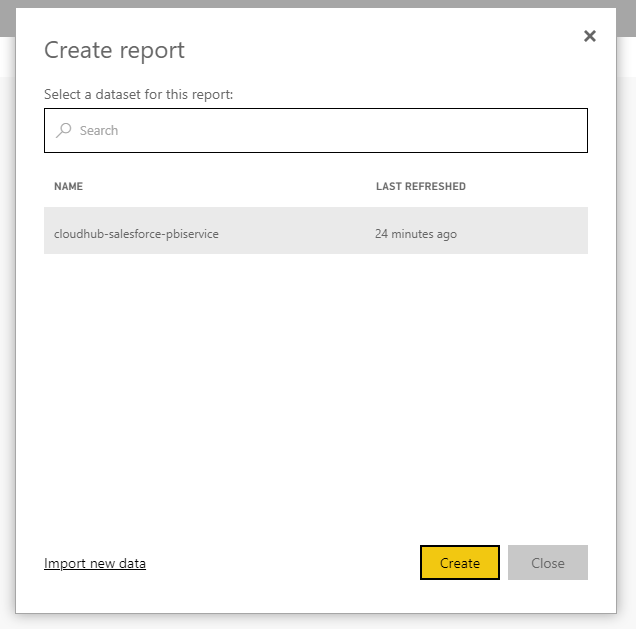
- 「作成」をクリックし、「レポート」を選択します。
- レポート用に公開されたデータセットを選択します。
![Select a dataset]()
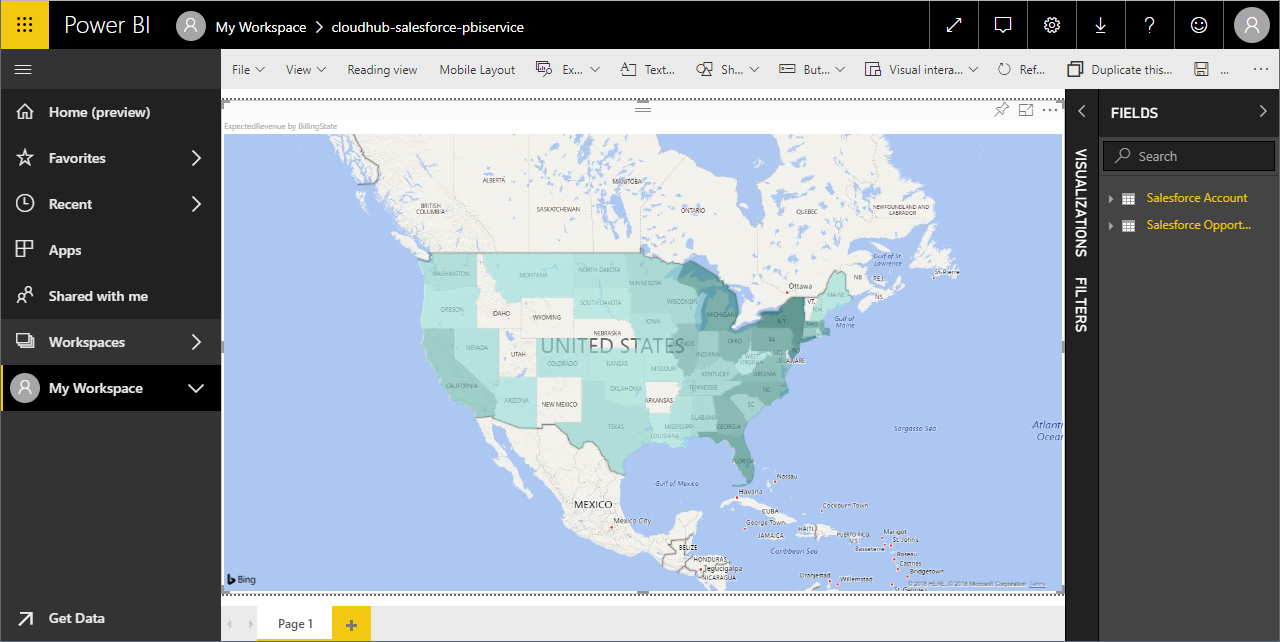
- フィールドとビジュアライゼーションを選択してレポートを追加します。
![Power BI サービスでSpark のデータをビジュアライズ]()
クラウドアプリケーションからSpark のデータへのSQL アクセス
Power BI サービスからリアルタイムSpark のデータへの直接接続ができるようになりました。これで、Spark を複製せずにより多くのデータソースや新しいビジュアライゼーション、レポートを作成することができます。
クラウドアプリケーションから直接100を超えるSaaS 、ビッグデータ、NoSQL ソースへのリアルタイムデータアクセスを取得するには、CData Connect Cloud をお試しください。