こんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
Nintex Workflow Cloud は、コーディングなしでドラッグアンドドロップを使用して単純 / 複雑なプロセスを自動化するワークフローを設計できる、クラウドベースのプラットフォームです。CData Connect Cloud と組み合わせると、ビジネスアプリケーション用にSpark のデータにクラウドベースでアクセスできます。この記事では、Connect Cloud にSpark の仮想データベースを作成し、Nintex でSpark のデータから単純なワークフローを構築する方法を説明します。
CData Connect Cloud は、Spark にクラウドベースのインターフェースを提供し、ネイティブにサポートされているデータベースにデータを複製することなくNintex Workflow Cloud でリアルタイムSpark のデータからワークフローを作成できるようにします。Nintex では、SQL クエリを使用してデータに直接アクセスできます。CData Connect Cloud は、最適化されたデータ処理を使用してサポートされているすべてのSQL 操作(フィルタ、JOIN など)をSpark に直接プッシュし、サーバー側の処理を利用して、要求されたSpark のデータを高速で返します。
Connect Cloud アカウントの取得
以下のステップを実行するには、CData Connect Cloud のアカウントが必要になります。こちらから製品の詳しい情報とアカウント作成、30日間無償トライアルのご利用を開始できますので、ぜひご利用ください。
Connect Cloud からSpark に接続する
CData Connect Cloud は直感的なクリック操作ベースのインターフェースを使ってデータソースに接続します。
- Connect Cloud にログインし、 Add Connection をクリックします。
![コネクションを追加]()
- Add Connection パネルから「Spark」を選択します。
![データソースを選択]()
-
必要な認証情報を入力し、Spark に接続します。
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、
「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
![コネクションの設定(Salesforce の例)]()
- Create & Test をクリックします。
- Edit Spark Connection ページのPermissions タブに移動し、ユーザーベースのアクセス許可を更新します。
![権限の更新]()
パーソナルアクセストークンを追加する
OAuth 認証をサポートしないサービス、アプリケーション、プラットフォーム、フレームワークから接続する場合、パーソナルアクセストークン(Personal Access Token, PAT)を認証に使用できます。きめ細かくアクセスを管理するために、サービスごとに個別のPAT を作成するのがベストプラクティスです。
- User Profile ページでPersonal Access Token セクションにスクロールし、 Create PAT をクリックします。
- PAT の名前を入力して Create をクリックします。
![新しいPAT を作成]()
- パーソナルアクセストークンは作成時にしか表示されないため、必ずコピーして安全に保存してください。
接続が構成されたら、Nintex Workflow Cloud からSpark のデータに接続できるようになります。
Nintex からSpark に接続する
以下のステップは、(Connect Cloud を介して)Nintex からSpark のデータへの新しい接続を作成する方法の概要です。
- Nintex Workflow Cloud にログインします。
- Connections タブで「Add new」をクリックします。
- コネクタとして「Microsoft SQL Server」を選択し、「Connect」をクリックします。
![Adding a new SQL Server Connection]()
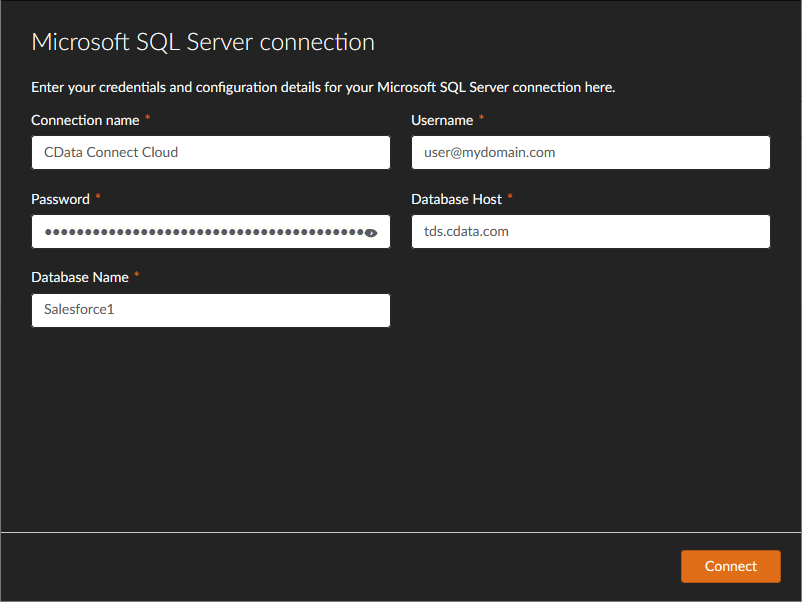
- SQL Server の接続ウィザードで以下のプロパティを設定します。
- Connection Name:a Connect Cloud
- Username:Connect Cloud のユーザー名(例:[email protected])
- Password:Connect Cloud のユーザーのPAT
- Database Host:tds.cdata.com
- Database Name:Spark 接続(例:SparkSQL1)
![Configuring the Connection to Connect Cloud]()
- 「Connect」をクリックします。
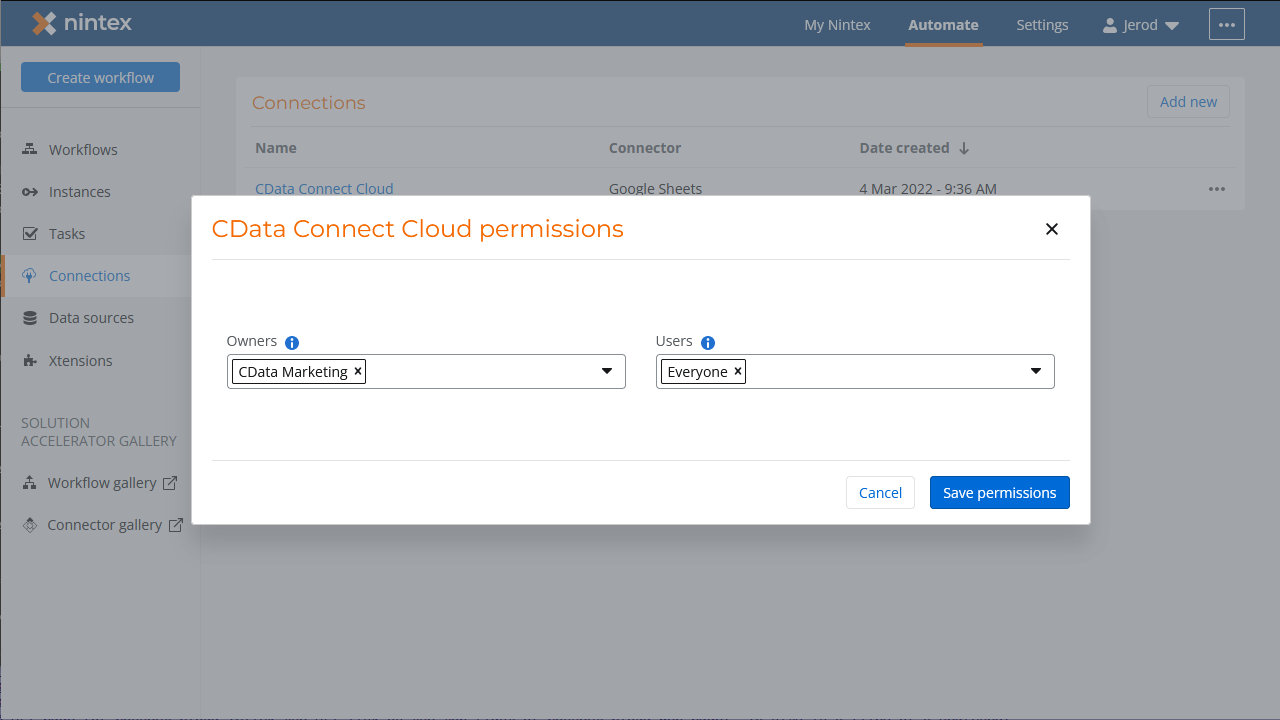
- 接続権限を構成し、「Save permissions」をクリックします。
![Configuring permissions and saving the Connection]()
単純なSpark ワークフローを作成する
CData Connect Cloud への接続が構成され、Spark にアクセスする単純なワークフローを作成する準備ができました。まずは、「Create workflow」ボタンをクリックします。
開始イベントアクションを構成する
- 開始イベントタスクをクリックし、「Form」イベントを選択します。
- 「Design form」をクリックします。
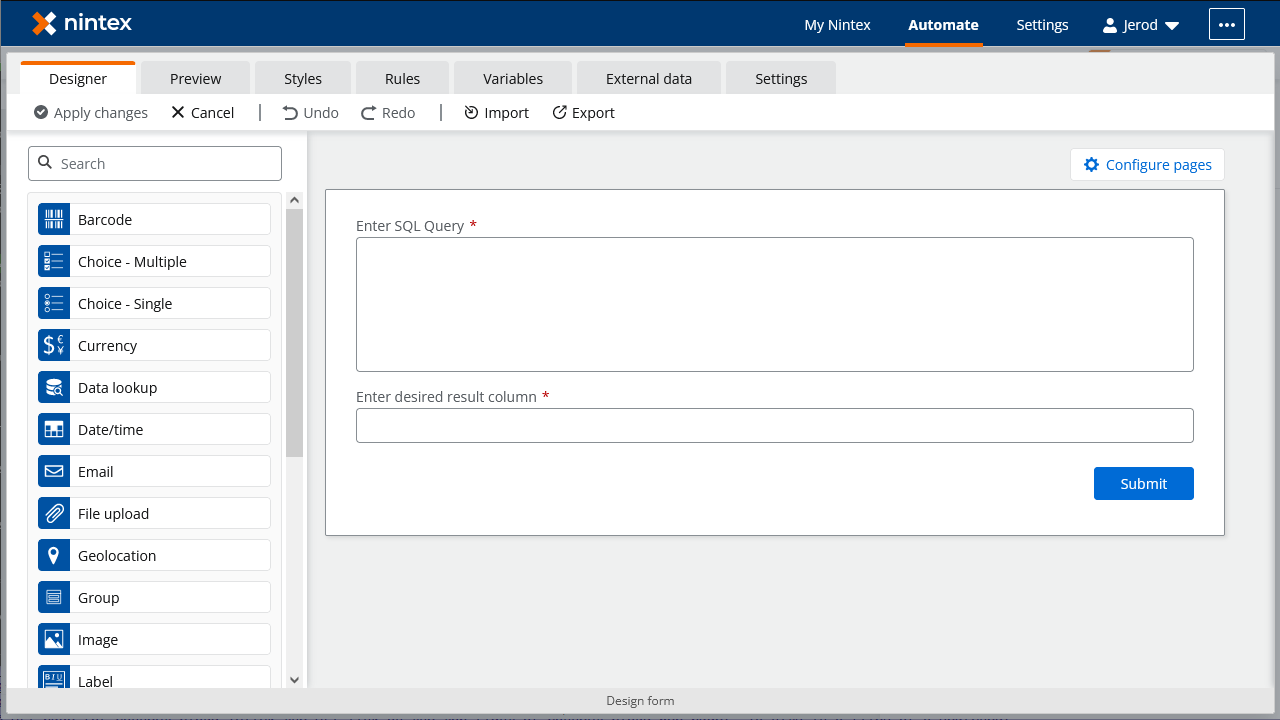
- 「Text - Long」エレメントをForm にドラッグし、エレメントをクリックして設定します。
- 「Title」を「Enter SQL query」に設定します。
- 「Required」をtrue に設定します。
- 「Text - Short」エレメントを「Form」にドラッグし、エレメントをクリックして構成します。
- 「Title」を「Enter desired result column」に設定します。
- 「Required」をtrue に設定します。
![Designing the Start event Form]()
「Execute a Query」アクションを構成する
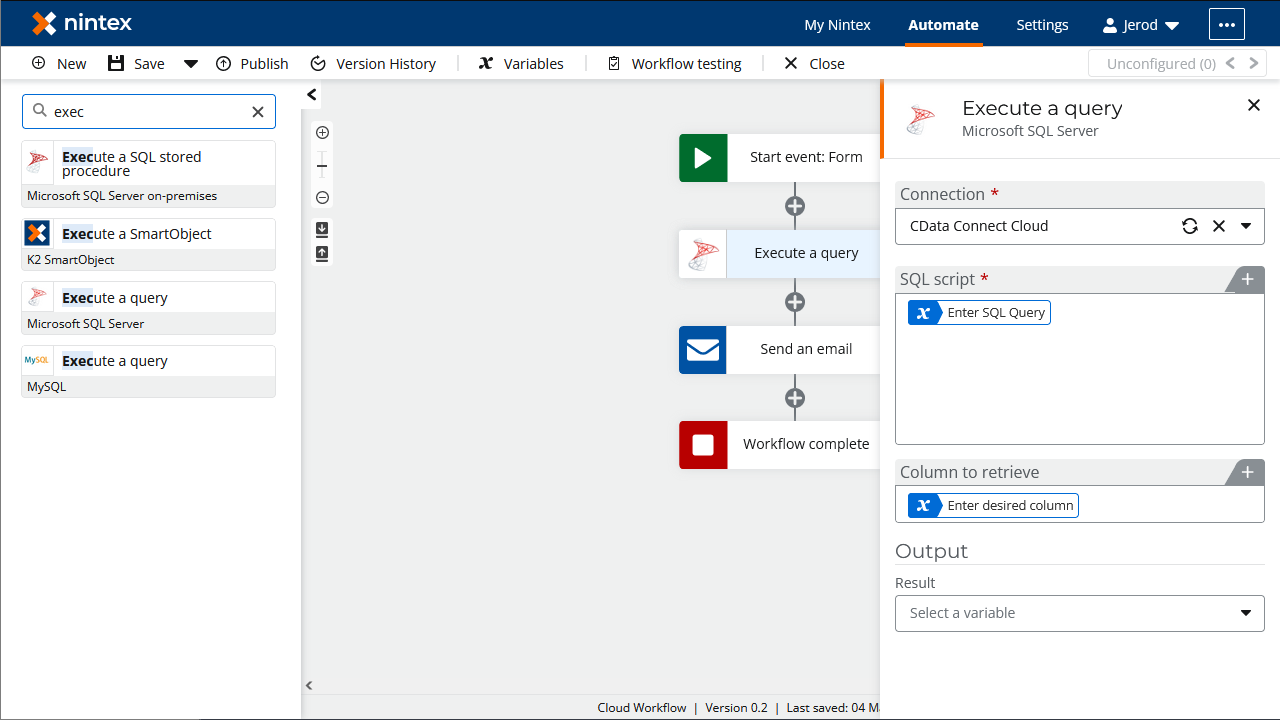
- 「Start event: Form」アクションのあとに「Execute a query」アクションを追加し、クリックしてアクションを構成します。
- 「Start event」アクションから「SQL Script」を「Enter SQL Query」変数に設定します。
- 「Start event」アクションから「Column to retrieve」を「Enter desired result column」変数に設定します。
- 「Retrieved column」を新しい変数に設定します。(例:「values」)
![Configuring the SQL Server query action]()
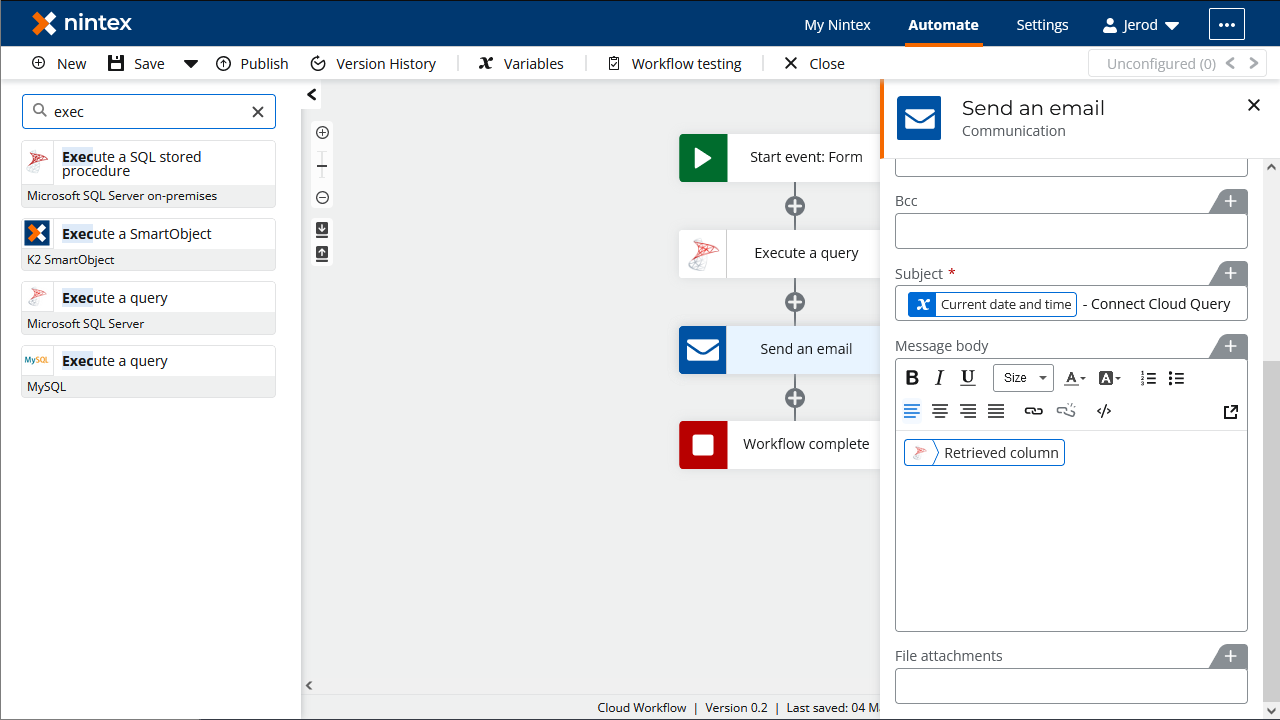
「Send an Email」アクションを構成する
- 「Execute a query」アクションののち、「Send an email」アクションを追加し、クリックしてアクションを構成します。
- 「Recipient email address」を設定します。
- 「Subject」を設定します。
- 「Message body」を取得したカラム用に作成された変数に設定します。
![Configuring the email action]()
アクションを構成したら、「Save」をクリックしてワークフローに名前を付け、もう一度「Save」をクリックします。これで、SQL を使用してSpark をクエリし、結果をメールで送信する単純なワークフローができました。
クラウドアプリケーションから直接100を超えるSaaS 、ビッグデータ、NoSQL データソースにリアルタイムアクセスする方法の詳細は、CData Connect Cloud を参照してください。無償トライアルにサインアップして、ご不明な点があればサポートチームにお問い合わせください。