こんにちは!ドライバー周りのヘルプドキュメントを担当している古川です。
IBM Watson® を搭載したCognos Analytics では、データのクリーニングと連携、さらに可視化を行うことができます。CData Connect Cloud と組み合わせると、クラウドデータとCognos Analytics を即座にリアルタイムで接続し、データ管理、視覚化、分析などを行うことができます。
この記事では、CData Connect Cloud でSpark に接続し、さらにCognos Analytics でSpark のデータを分析する方法を紹介します。
NOTE:この手順を実行するにはCognos Analytics 11.2.4 以降が必要です。
CData Connect Cloud は、Spark にクラウドベースのインターフェースを提供し、ネイティブにサポートされているデータベースにデータを複製することなくCognos でのSpark のデータの分析を実現します。
CData Connect Cloud は最適化されたデータ処理により、サポートされているすべてのSQL 操作(フィルタ、JOIN など)をSpark に直接発行し、サーバー側の処理を利用して要求されたSpark のデータを高速で返します。
Connect Cloud アカウントの取得
以下のステップを実行するには、CData Connect Cloud のアカウントが必要になります。こちらから製品の詳しい情報とアカウント作成、30日間無償トライアルのご利用を開始できますので、ぜひご利用ください。
Connect Cloud からSpark への接続
CData Connect Cloud を使うと、直感的なクリック操作ベースのインターフェースを使ってデータソースに接続できます。
- Connect Cloud にログインし、 Add Connection をクリックします。
![コネクションを追加]()
- Add Connection パネルで「Spark」を選択します。
![データソースを選択]()
-
必要な認証プロパティを入力し、Spark に接続します。
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、
「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
![コネクションを設定(Salesforce の場合)]()
- Create & Test をクリックします。
- Add Spark Connection ページのPermissions タブに移動し、ユーザーベースのアクセス許可を更新します。
![権限の更新]()
パーソナルアクセストークンの取得
OAuth 認証をサポートしていないサービス、アプリケーション、プラットフォーム、またはフレームワークから接続する場合は、認証に使用する個人用アクセストークン(PAT)を作成できます。
きめ細かなアクセス管理を行うために、サービスごとに個別のPAT を作成するのがベストプラクティスです。
- Connect Cloud アプリの右上にあるユーザー名をクリックし、User Profile をクリックします。
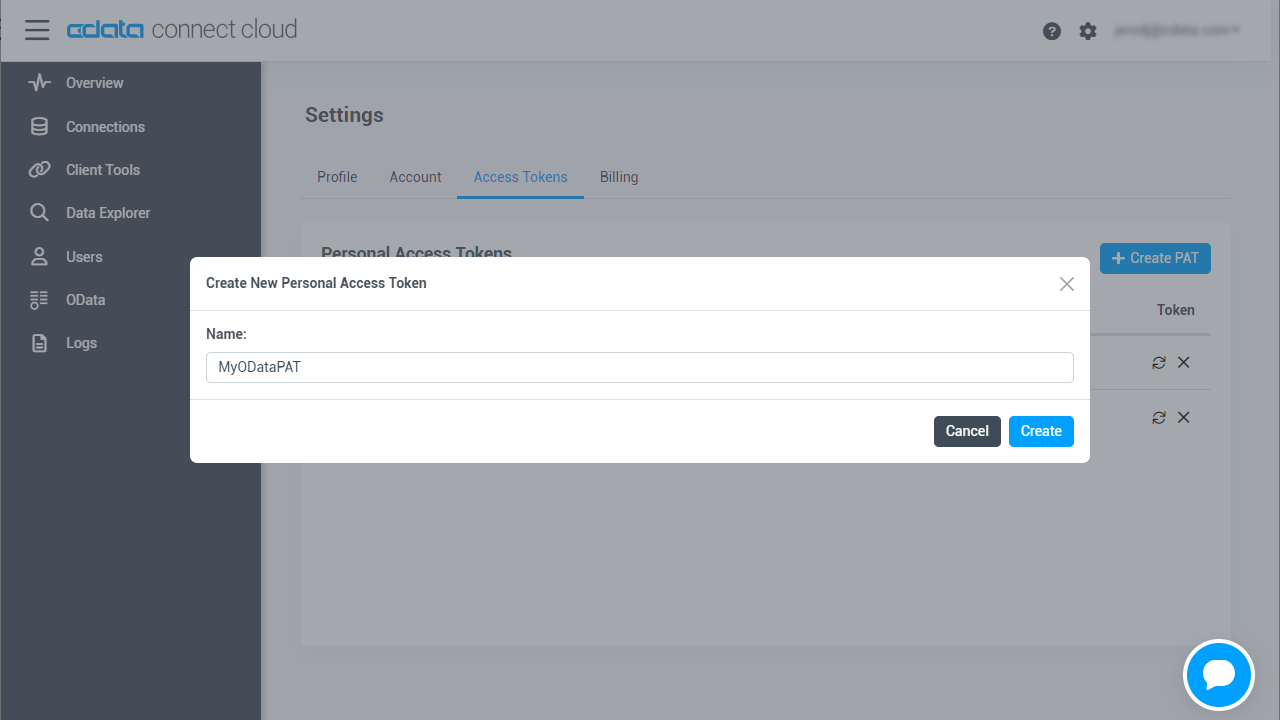
- User Profile ページでPersonal Access Token セクションにスクロールし、 Create PAT をクリックします。
- PAT の名前を入力して Create をクリックします。
![新しいPAT を作成]()
- 個人用アクセストークンは作成時にしか表示されないため、必ずコピーして安全に保存してください。
接続の設定が完了したら、Cognos Analytics からSpark のデータに接続できるようになります。
Cognos Analytics からSpark への接続
以下のステップでは、Cognos Analytics からCData Connect Cloud に接続してリアルタイムSpark のデータを分析する方法を説明します。
CData Connect Cloud JDBC Driver をダウンロードする
- CData Connect Cloud JDBC Driver をダウンロードしてインストールします:https://www.cdata.com/jp/cloud/clients/download.aspx#jdbc。
- JAR ファイル(cdata.jdbc.connect.jar)をインストールディレクトリ(例:C:\Program Files\CData\JDBC Driver for CData Connect\lib)からCognos Analytics のインストールディレクトリにある"drivers" フォルダにコピーします。
CData Connect Cloud への接続を設定する
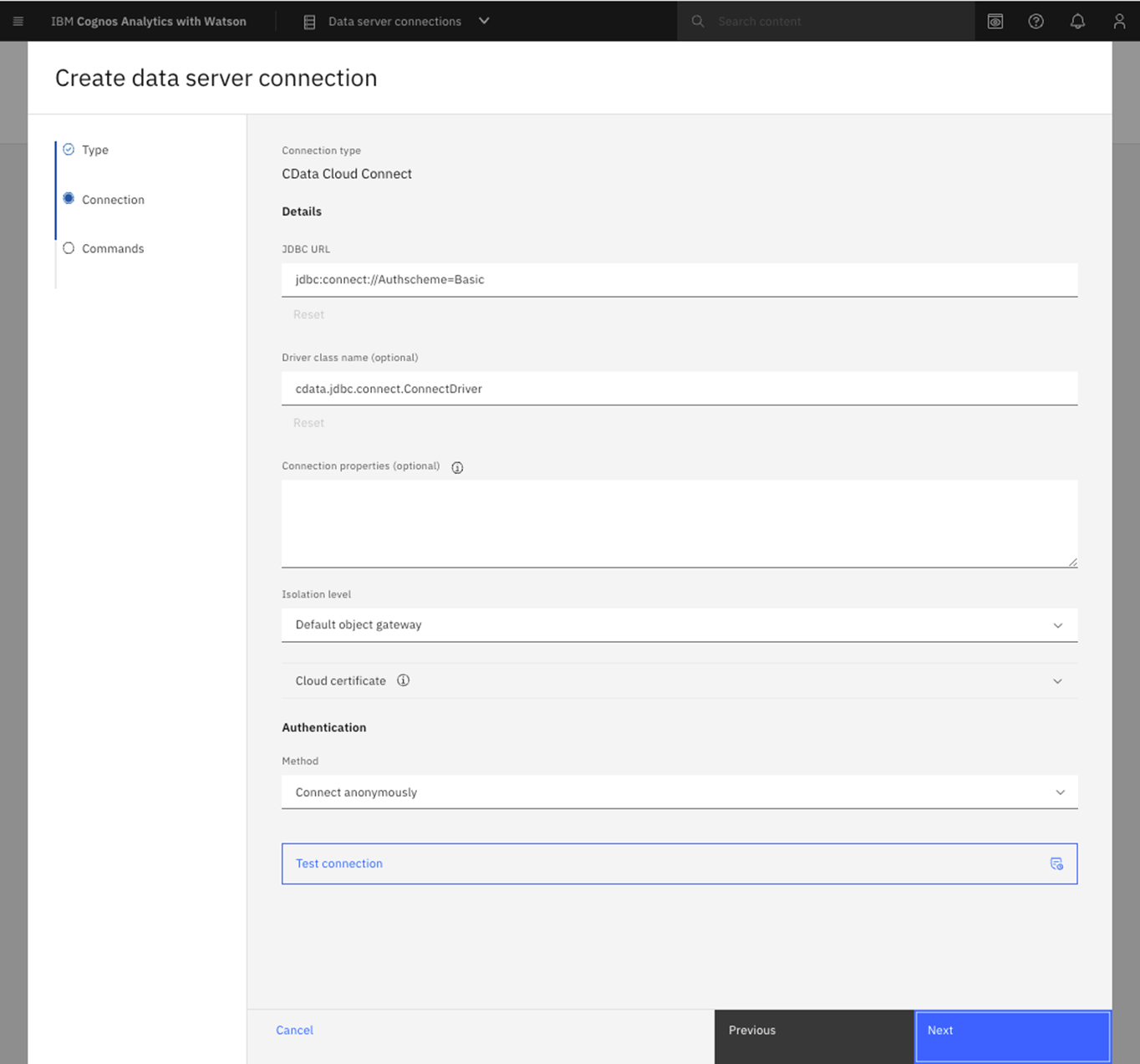
- IBM Cognos を立ち上げ、管理 -> データ・サーバー接続に移動します。
- アイコンをクリックしてデータサーバーを追加します。
- CData Connect Cloud を選択します。
- JDBC URL を適切な接続文字列に設定します。次に例を示します。
jdbc:connect://AuthScheme=Basic;
- Driver class name を"cdata.jdbc.connect.ConnectDriver" に設定します。
- 認証方式を選択し、認証情報を作成して保存します。
- Username をCData Connect Cloud のユーザー名(例:[email protected])に設定。
- Password を前述の生成したPAT に設定。
- Test connection をクリックし、接続が成功したことを確認します。
![Connecting to CData Connect Cloud from Cognos Analytics]()
これでCognos Analytics でSpark のデータを分析し可視化する準備が整いました。Cognos Analytics の使用について、詳しくはIBM Cognos Analytics のドキュメントを参照してください。
Cognos Analytics のSpark のデータへのリアルタイムアクセス
Cognos Analytics からリアルタイムSpark のデータに直接クラウド間接続ができるようになりました。これで、Spark を複製することなく新しい可視化やレポートなどを作成できます。
クラウドアプリケーションから直接100を超えるSaaS 、ビッグデータ、NoSQL データソースへのリアルタイムデータアクセスを実現するには、CData Connect Cloud の30日間無償トライアルをぜひお試しください。