各製品の資料を入手。
詳細はこちら →Azure Data Lake Storage Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへ製品の詳細
Azure Data Lake Storage データに連携するJava アプリケーションを素早く、簡単に開発できる便利なドライバー。
CData


こんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
Hibernate を使用することで、オブジェクト指向のドメインモデルを従来のリレーショナルデータベースにマッピングすることができます。以下のチュートリアルでは、CData JDBC Driver for ADLS を使用し、Hibernate でAzure Data Lake Storage リポジトリのORM を生成する方法を説明します。
この記事を通してEclipse がIDE として選択されていますが、CData JDBC Driver for ADLS はJava Runtime Environment をサポートするすべての 製品で機能します。Knowledge Base には、IntelliJ IDEA やNetBeans からAzure Data Lake Storage に接続するためのチュートリアルがあります。
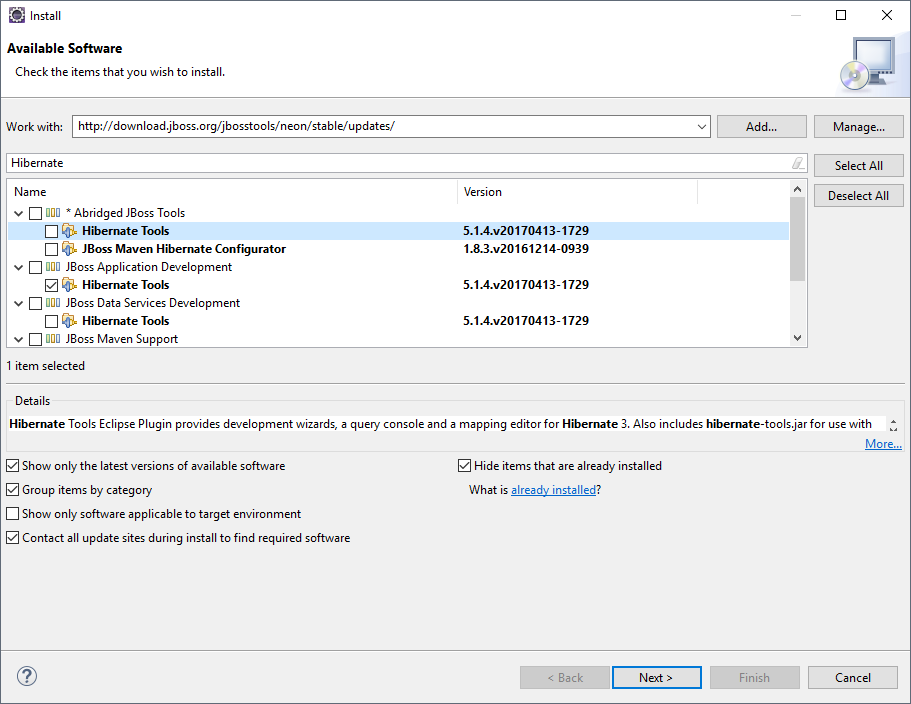
以下のステップに従って、Eclipse にHibernate プラグインをインストールします。
以下のステップに従って、新しいプロジェクトにドライバーJARs を追加します。
以下のステップに従って、Azure Data Lake Storage に接続プロパティを構成します。
以下の値をインプットします。
Connection URL:jdbc:adls: で始まり、セミコロンで区切られた接続プロパティのリストが続くJDBC URL
Gen 2 Data Lake Storage アカウントに接続するには、以下のプロパティを設定します。
本製品は、次の4つの認証方法をサポートします:アクセスキーの使用、共有アクセス署名の使用、Azure Active Directory OAuth(AzureAD)、Managed Service Identity(AzureMSI)。
Azure ポータルで:
接続の準備ができたら、次のプロパティを設定します。
共有アクセス署名を使用して接続するには、はじめにAzure Storage Explorer ツールを使用して署名を生成する必要があります。
接続の準備ができたら、次のプロパティを設定します。
AzureAD、AzureMSI での認証方法については、ヘルプドキュメントの「Azure Data Lake Storage Gen 2 への認証」セクションを参照してください。
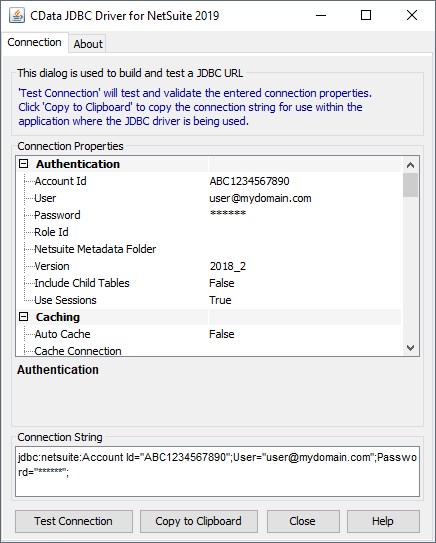
JDBC URL の構成については、Azure Data Lake Storage JDBC Driver に組み込まれている接続文字列デザイナを使用してください。JAR ファイルのダブルクリック、またはコマンドラインからJAR ファイルを実行します。
java -jar cdata.jdbc.adls.jar
接続プロパティを入力し、接続文字列をクリップボードにコピーします。
以下は一般的なJDBC URL です。
jdbc:adls:Schema=ADLSGen2;Account=myAccount;FileSystem=myFileSystem;AccessKey=myAccessKey;InitiateOAuth=GETANDREFRESH
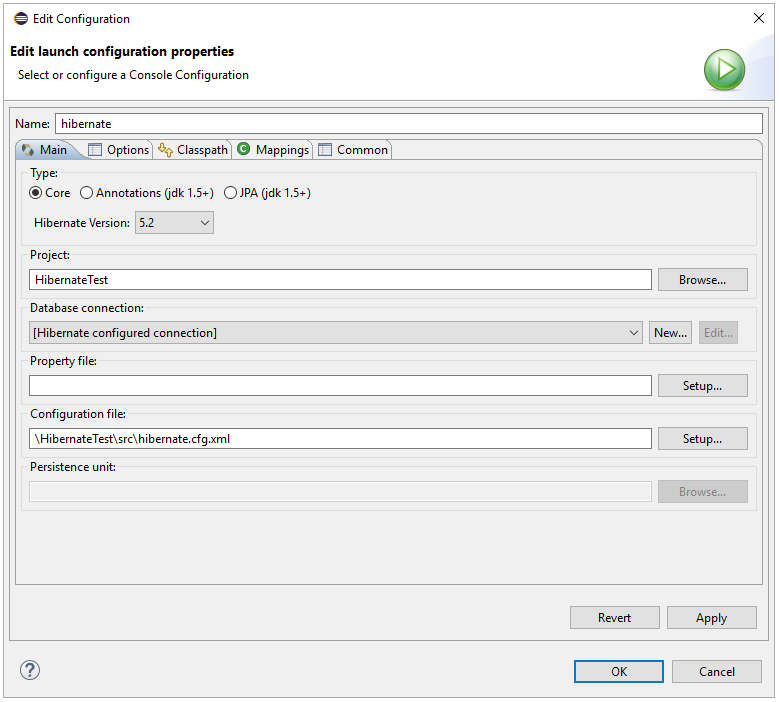
以下のステップに従って、前の手順で作成した構成を選択します。
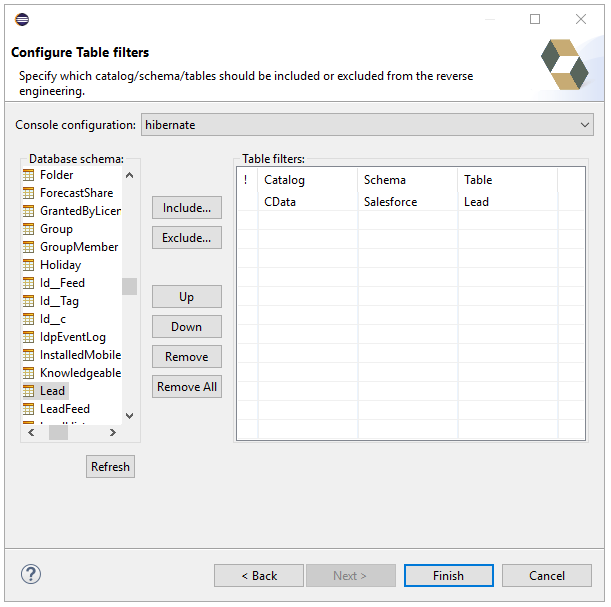
以下のステップに従って、reveng.xml 構成ファイルを生成します。アクセスするテーブルをオブジェクトとして指定します。
以下のステップに従って、plain old Java objects (POJO) をAzure Data Lake Storage テーブルに生成します。
POJO は、前のステップのリバースエンジニアリング設定に基づいて作成されます。
生成したマッピングごとにhibernate.cfg.xml にマッピングタグを作成し、Hibernate がマッピングリソースを指定するようにする必要があります。hibernate.cfg.xml を開き、次のようにマッピングタグを挿入します。
cdata.adls.ADLSDriver
jdbc:adls:Schema=ADLSGen2;Account=myAccount;FileSystem=myFileSystem;AccessKey=myAccessKey;InitiateOAuth=GETANDREFRESH
org.hibernate.dialect.SQLServerDialect
前の手順で作成したエンティティを使用して、Azure Data Lake Storage のsearchを行うことができます。
import java.util.*;
import org.hibernate.Session;
import org.hibernate.cfg.Configuration;
import org.hibernate.query.Query;
public class App {
public static void main(final String[] args) {
Session session = new
Configuration().configure().buildSessionFactory().openSession();
String SELECT = "FROM Resources R WHERE Type = :Type";
Query q = session.createQuery(SELECT, Resources.class);
q.setParameter("Type","FILE");
List<Resources> resultList = (List<Resources>) q.list();
for(Resources s: resultList){
System.out.println(s.getFullPath());
System.out.println(s.getPermission());
}
}
}