ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →こんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
AWS Glue はAmazon が提供するETL サービスで、ビジネスデータをストレージやアナリティクスプラットフォームに簡単にロード・加工ができます。CData Glue Connectors を使うことで、Glue Studio でノーコード・ローコードでETL ジョブを作成することが可能になります。この記事では、CData Glue Connector for AmazonAthena を使って、Amazon Athena データ連携を行うAWS Glue ジョブを作成していきます。
AWS Glue ジョブを作成するには、AWS のIAM ロールを設定する必要があります。 IAM ロールは、Glue ジョブが関連するすべてのリソース(Amazon S3 のリソース、ターゲット、スクリプト、テンポラリーディレクトリ、AWS Glue Catalog オブジェクトを含む)にアクセス権限を持つ必要があります。また、AWS Glue Marketplace で購入するCData Glue Connector for AmazonAthena へのアクセス権限も必要です。
ミニマムで、以下のポリシーをIAM ロールに追加する必要があります:
Amazon S3 データにアクセスする場合は以下を追加:
接続プロパティの保存にAWS Secrets Manager を使う場合、インラインでポリシーを追加して、Glue ジョブに必要な特定のsecrets へのアクセスを許容:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"secretsmanager:GetResourcePolicy",
"secretsmanager:GetSecretValue",
"secretsmanager:DescribeSecret",
"secretsmanager:ListSecretVersionIds"
],
"Resource": [
"arn:aws:secretsmanager:us-west-2:111122223333:secret:aes128-1a2b3c",
"arn:aws:secretsmanager:us-west-2:111122223333:secret:aes192-4D5e6F",
"arn:aws:secretsmanager:us-west-2:111122223333:secret:aes256-7g8H9i"
]
}
]
}
AWS Glue Studio およびGlue Job でのアクセス権限についての詳細情報は、「Setting up IAM Permissions for AWS Glue in the AWS Glue」ドキュメントを参照してください。
Amazon S3 バケットへのアクセス権限についての詳細情報は、「Amazon Simple Storage Service Developer Guide」を参照してください。
シークレットへのアクセスコントロール設定については、AWS Secrets Manager ドキュメントの「Authentication and Access Control for AWS Secrets Manager」および「Limiting Access to Specific Secrets」を参照してください。AWS Secret Manager から取得されたクレデンシャル(key-value ペアの文字列)は、CData Glue Connector がデータソースに接続する際に使われます。
Amazon Athena リクエストの認証には、アカウントの管理のクレデンシャルか、IAM ユーザーのカスタムPermission を設定します。 AccessKey にAccess Key Id、SecretKey にはSecret Access Key を設定します。
AWS アカウントアドミニストレータとしてアクセスできる場合でも、AWS サービスへの接続にはIAM ユーザークレデンシャルを使用することが推奨されます。
IAM ユーザーのクレデンシャル取得は以下のとおり:
AWS ルートアカウントのクレデンシャル取得は以下のとおり:
EC2 インスタンスからCData 製品を使用していて、そのインスタンスにIAM ロールが割り当てられている場合は、認証にIAM ロールを使用できます。 これを行うには、UseEC2Roles をtrue に設定しAccessKey とSecretKey を空のままにします。 CData 製品は自動的にIAM ロールの認証情報を取得し、それらを使って認証します。
多くの場合、認証にはAWS ルートユーザーのダイレクトなセキュリティ認証情報ではなく、IAM ロールを使用することをお勧めします。 代わりにRoleARN を指定してAWS ロールを使用できます。これにより、CData 製品は指定されたロールの資格情報を取得しようと試みます。 (すでにEC2 インスタンスなどで接続されているのではなく)AWS に接続している場合は、役割を担うIAM ユーザーのAccessKeyと SecretKey を追加で指定する必要があります。AWS ルートユーザーのAccessKey およびSecretKey を指定する場合、 ロールは使用できません。
多要素認証を必要とするユーザーおよびロールには、MFASerialNumber およびMFAToken 接続プロパティを指定してください。 これにより、CData 製品は一時的な認証資格情報を取得するために、リクエストでMFA 認証情報を送信します。一時的な認証情報の有効期間 (デフォルトは3600秒)は、TemporaryTokenDuration プロパティを介して制御できます。
AccessKey とSecretKey プロパティに加え、Database、S3StagingDirectory、Region を設定します。Region をAmazon Athena データがホストされているリージョンに設定します。S3StagingDirectory をクエリの結果を格納したいS3内のフォルダに設定します。
接続にDatabase が設定されていない場合は、CData 製品はAmazon Athena に設定されているデフォルトデータベースに接続します。
CData Glue Connector for AmazonAthena で使用するので必要なプロパティの値をメモしておきます。
接続プロパティをセキュアに保存して使用するには、AWS Secrets Manager に保存することができます。
Note: AWS Glue ETL ジョブおよびシークレットは、同じリジョンにホストされる必要があります。リジョンをまたぐシークレットの取得はサポートされていません。
シークレットの作成については、AWS Secrets Manager User Guide のCreating and Managing Secrets with AWS Secrets Manager を参照してください。
AWS Glue Studio でCData Glue Connector for AmazonAthena を利用するには、AWS Marketplace でコネクタのサブスクリプションを行う必要があります。すでにCData Glue Connector for AmazonAthena のサブスクリプション契約をしている場合には、この部分はスキップしてください。
AWS Glue でCData Glue Connector for AmazonAthenaを使うためには、AWS Glue Studio でサブスクライブしたコネクタをアクティベートする必要があります。アクティベートすることで、AWS アカウントにコネクタオブジェクトが作成されます。
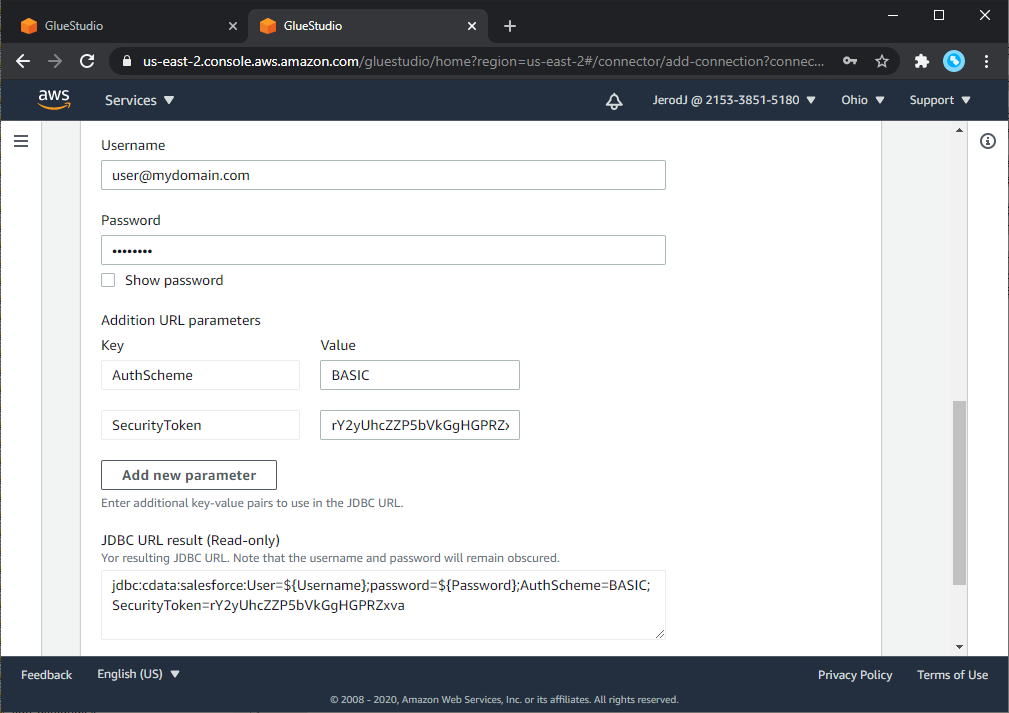
Connection アクセスで、JDBC URL 形式を選択し、接続設定を行います。以下が一般的なAmazon Athena への接続のJDBC URL 接続文字列フォーマットです。Amazon Athena への接続の詳細については、Connector のヘルプドキュメントを参照してください。
AWS Secrets Manager でのシークレットの保管をしている場合には、プレースホルダーの値 (e.g. ${Property1}) は空白になります。そうでない場合には、入力した値はAWS Glue Connection インターフェースはRead-only のJDBCURL として表示されます。
jdbc:cdata:AmazonAthena:AuthScheme=AwsRootKeys;AWSAccessKey=${AWSAccessKey};AWSSecretKey=${AWSSecretKey};Database=${Database};S3StagingDirectory=${S3StagingDirectory};AWSRegion=${AWSRegion};S3StagingDirectory=${S3StagingDirectory};
jdbc:cdata:AmazonAthena:AuthScheme=TemporaryCredentials;AWSAccessKey=${AWSAccessKey};AWSSecretKey=${AWSSecretKey};AWSSessionToken=${AWSSessionToken};Database=${Database};S3StagingDirectory=${S3StagingDirectory};AWSRegion=${AWSRegion};S3StagingDirectory=${S3StagingDirectory};
jdbc:cdata:AmazonAthena:AuthScheme=AwsEC2Roles;AWSRoleARN=${AWSRoleARN};AWSExternalID=${AWSExternalId};Database=${Database};S3StagingDirectory=${S3StagingDirectory};AWSRegion=${AWSRegion};S3StagingDirectory=${S3StagingDirectory};
CData Glue Connector for AmazonAthena のログ機能を利用する場合、JDBC URL に以下の2つのプロパティを追加しま:
接続設定の完了後、Glue ジョブを作成することができます。
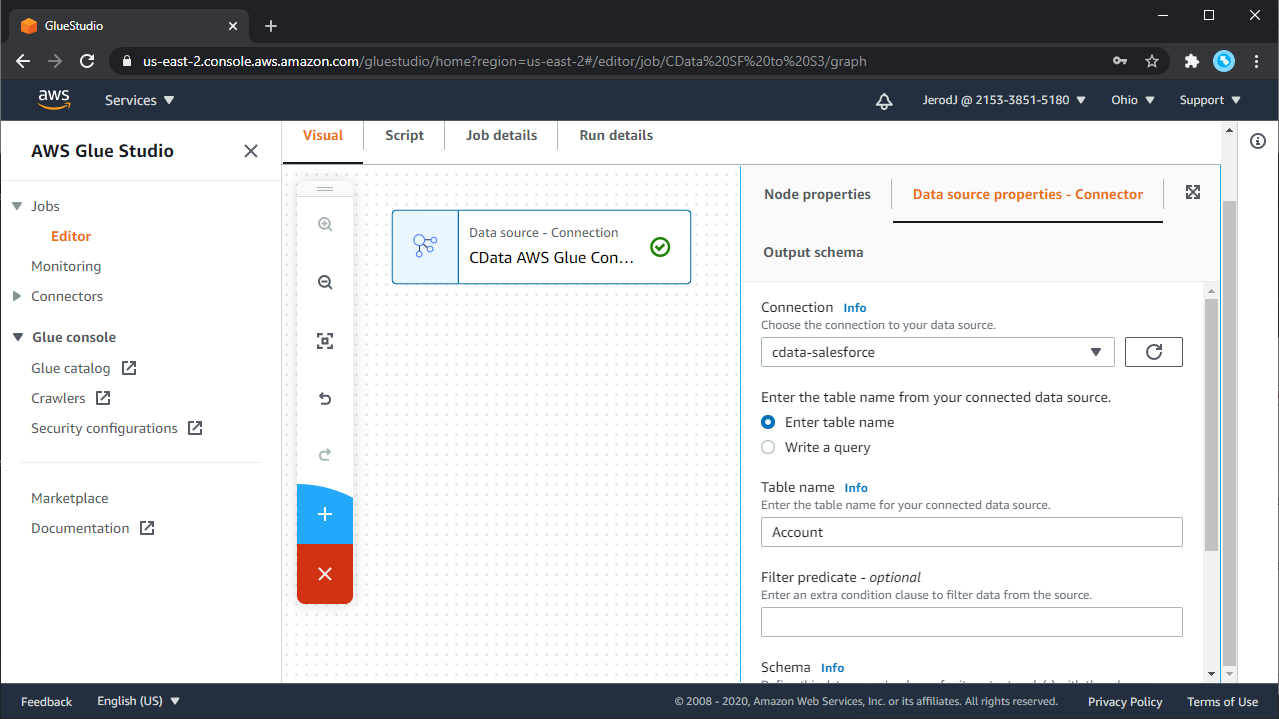
ジョブエディタが開くので、新しいNode を追加します。Node 詳細パネルの右にSource Properties タブがあります。
Source properties タブでデータソースへの接続オプションを選択できます。AWS Glue Studio ヘルプで詳細を確認してください。ここではシンプルな例を示します。
これらのオプションの詳細については"Use the Connection in a Glue job using Glue Studio" を参照してください。
ジョブグラフでNode を追加・編集することでジョブを変更することができます。詳細は、Editing ETL jobs in AWS Glue Studio を参照してください。
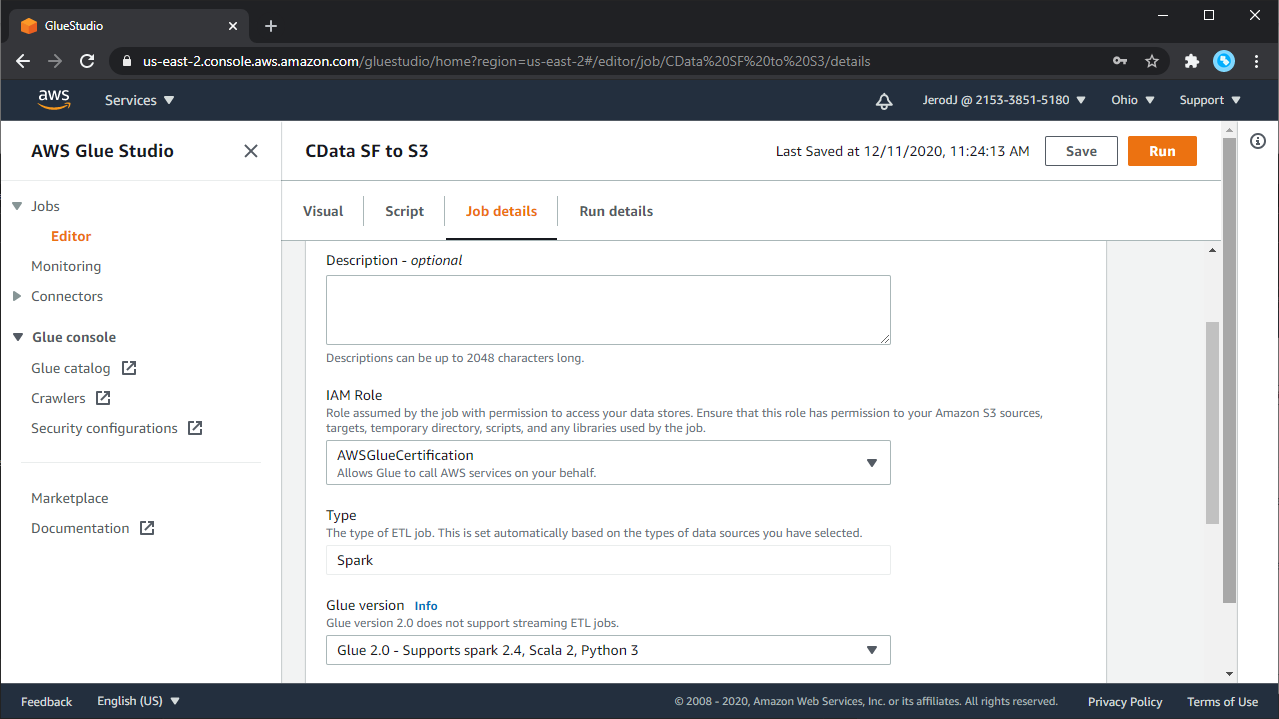
ジョブの編集が終わったら、Job Properties を入力します。
ジョブ作成において、Script タブをクリックし、Glue Studio が作成するスクリプトを確認することができます。シンプルなAmazon Athena データのS3 バケットへの書き込みの場合、スクリプトは以下のようになります:
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
## @type: DataSource
## @args: [connection_type = "marketplace.jdbc", connection_options = {"dbTable":"Customers","connectionName":"cdata-athena"}, transformation_ctx = "DataSource0"]
## @return: DataSource0
## @inputs: []
DataSource0 = glueContext.create_dynamic_frame.from_options(connection_type = "marketplace.jdbc", connection_options = {"dbTable":"Customers","connectionName":"cdata-athena"}, transformation_ctx = "DataSource0")
## @type: DataSink
## @args: [connection_type = "s3", format = "json", connection_options = {"path": "s3://PATH/TO/BUCKET/", "partitionKeys": []}, transformation_ctx = "DataSink0"]
## @return: DataSink0
## @inputs: [frame = DataSource0]
DataSink0 = glueContext.write_dynamic_frame.from_options(frame = DataSource0, connection_type = "s3", format = "json", connection_options = {"path": "s3://PATH/TO/BUCKET/", "partitionKeys": []}, transformation_ctx = "DataSink0")
job.commit()
CData Glue Connector for AmazonAthena をAWS Glue Studio で使って、簡単にAmazon Athena データをS3 バケットや他の同期先にETL するジョブを作成することができます。 また、Glue Connector を使って、Amazon Athena にデータを挿入、更新、削除を行うGlue ジョブを作ることもできます。.