Databricks は、データと AI の融合と活用を支援するデータインテリジェンスプラットフォームです。
今回は CData が提供するデータパイプラインツール「CData Sync」を使い、SAP S/4HANA Cloud (SAP Netweaver Gateway) のデータを Microsoft Azure 上に用意したDatabricks 環境「Azure Databricks」にノーコードでレプリケーションしてみたいと思います。
Azure Databricks はDatabricks をMicrosoft Azure 環境向けに最適化し、Data Lake Storage、Azure Synapse Analytics、Power BI 等と密接に統合したクラウドサービスで、Azureサービスと連携した拡張性の高さが特徴です。
CData Sync について
CData Sync は、Databricks をはじめとするSaaS やRDB のデータを各種DB・DWH にノーコードで手軽にレプリケーション、データ転送できるデータパイプラインツールです。
一般的に外部のSaaS やDB などのデータソースをDatabricks と連携する場合はETL パイプラインを構築・運用することになりますが、CData Sync を使うことでChange data capture (CDC) による差分同期を含むデータ連携がノーコードでシンプルに実現でき、すぐにDatabricks の利用が開始できます。
CData Sync はDatabricks を活用する上で中核の機能となる「Unity Catalog」に対応しているため、データに対するアクセス制御などデータガバナンスへの対応やリネージデータによる変更履歴の把握、生成AI によるメタ情報の自動生成の利用が標準で可能です。
レプリケーションまでの流れ
CData Sync を使ったレプリケーションの手順は以下です。
- CData Sync に SAP Netweaver Gateway への接続情報を登録
- CData Sync に Databricks への接続情報を登録
- CData Sync に「ジョブ」と呼ばれるデータソースと同期先の情報を登録
- 登録した「ジョブ」に 実際のレプリケーション処理を行う「タスク」を追加
- タスクを実行してレプリケーションを実施
なお、Azure Databricks 上で ワークスペース、カタログ、スキーマ と、Unity Catalog にデータにアクセスするための SQLウェアハウス クラスターは事前に作成されている前提になります。
まだDatabricks 環境がない場合は公式のチュートリアルの手順に従って準備を行なっていただくことをお勧めいたします。
1 CData Sync に SAP Netweaver Gateway への接続情報を登録
まずはSAP S/4HANA Cloud のデータにアクセスするためのハブとなるSAP Netweaver Gateway への接続設定を行います。
CData Sync の「接続」メニューにて「接続を追加」をクリックし、「SAP Gateway」を検索します。
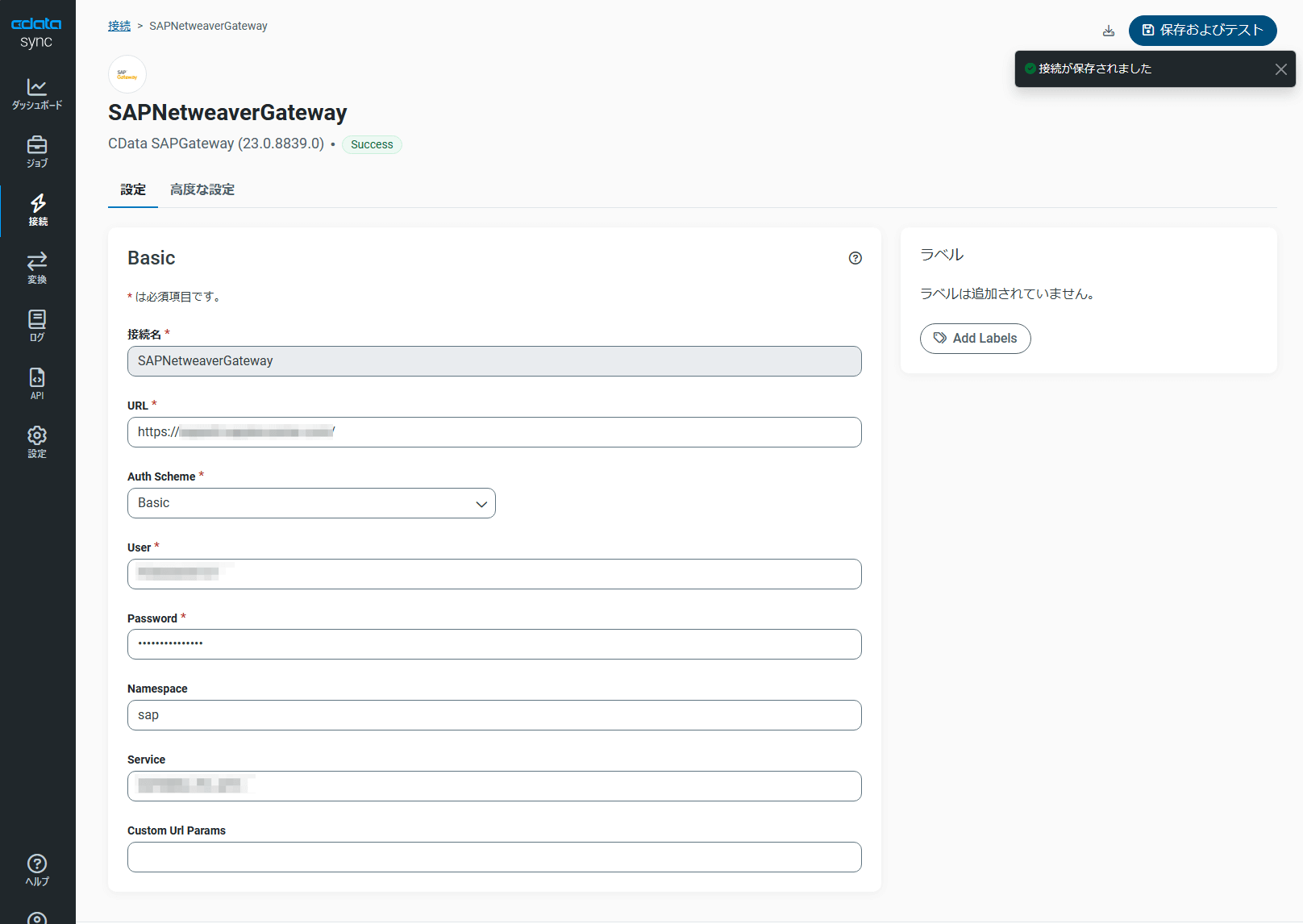
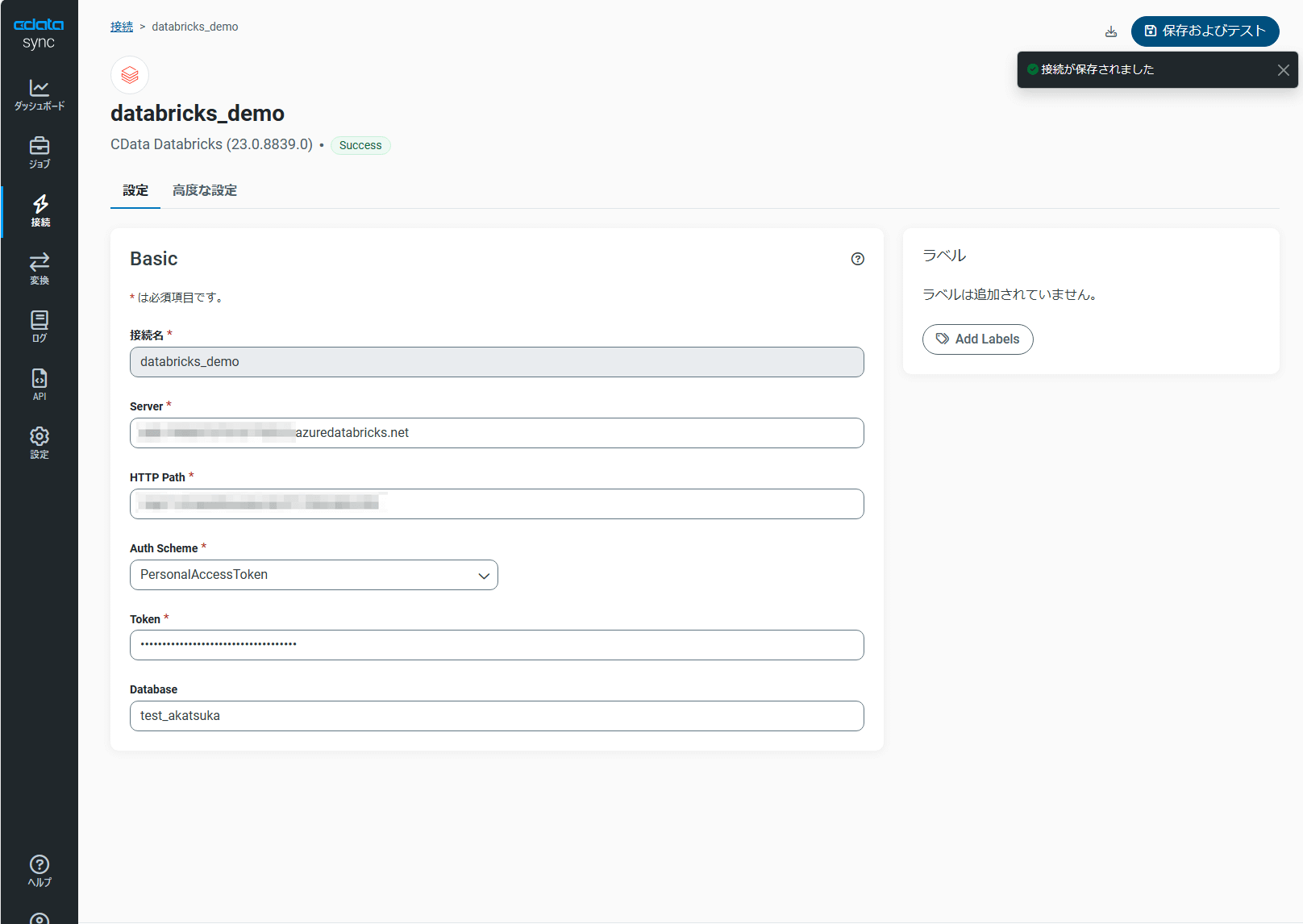
必要な情報を登録後、「保存およびテスト」をクリックして接続が成功することを確認します。
これでSAP S/4HANA Cloud のデータを標準化されたOData 形式で取得可能になりました。
2 CData Sync に Databricks への接続情報を登録
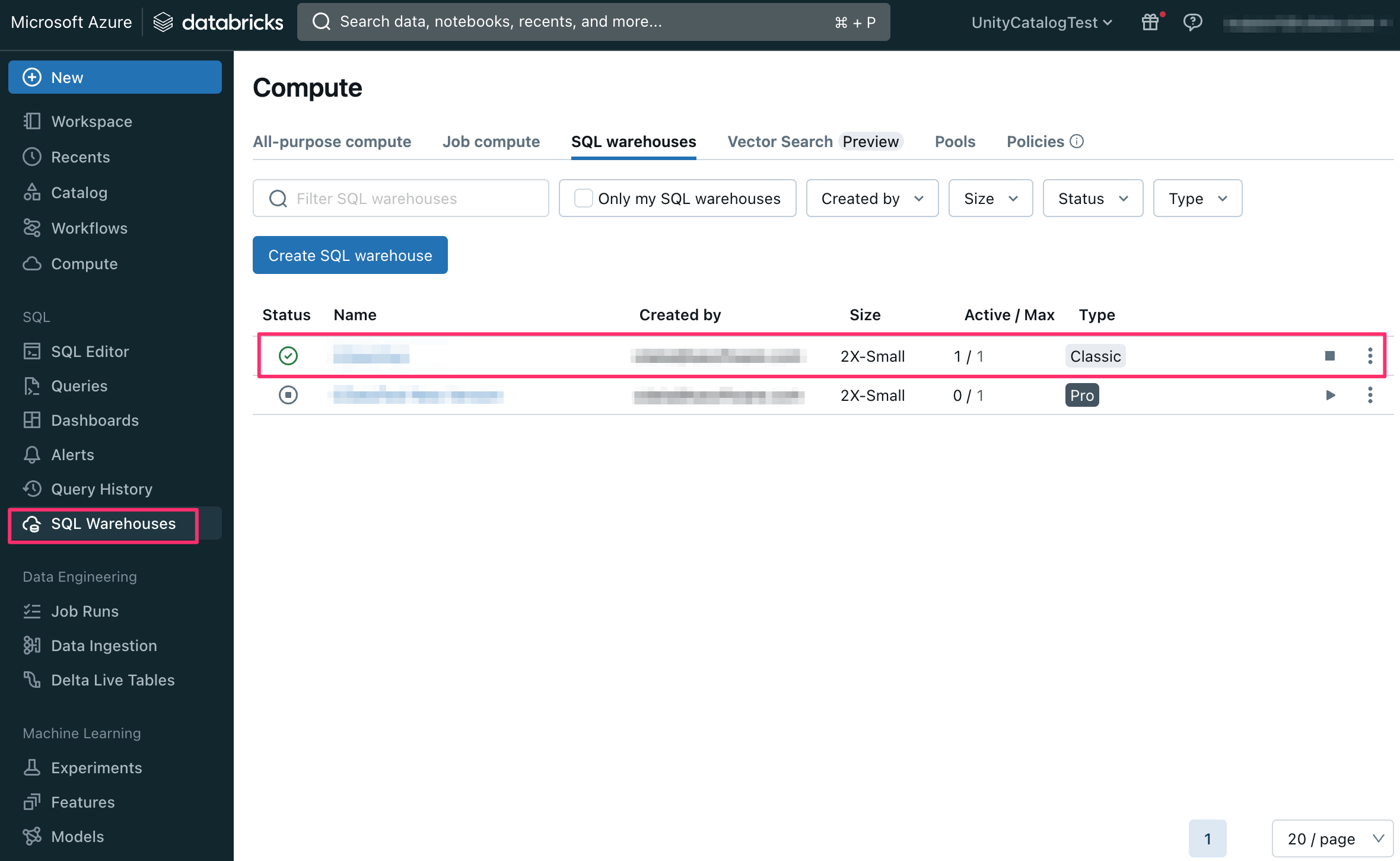
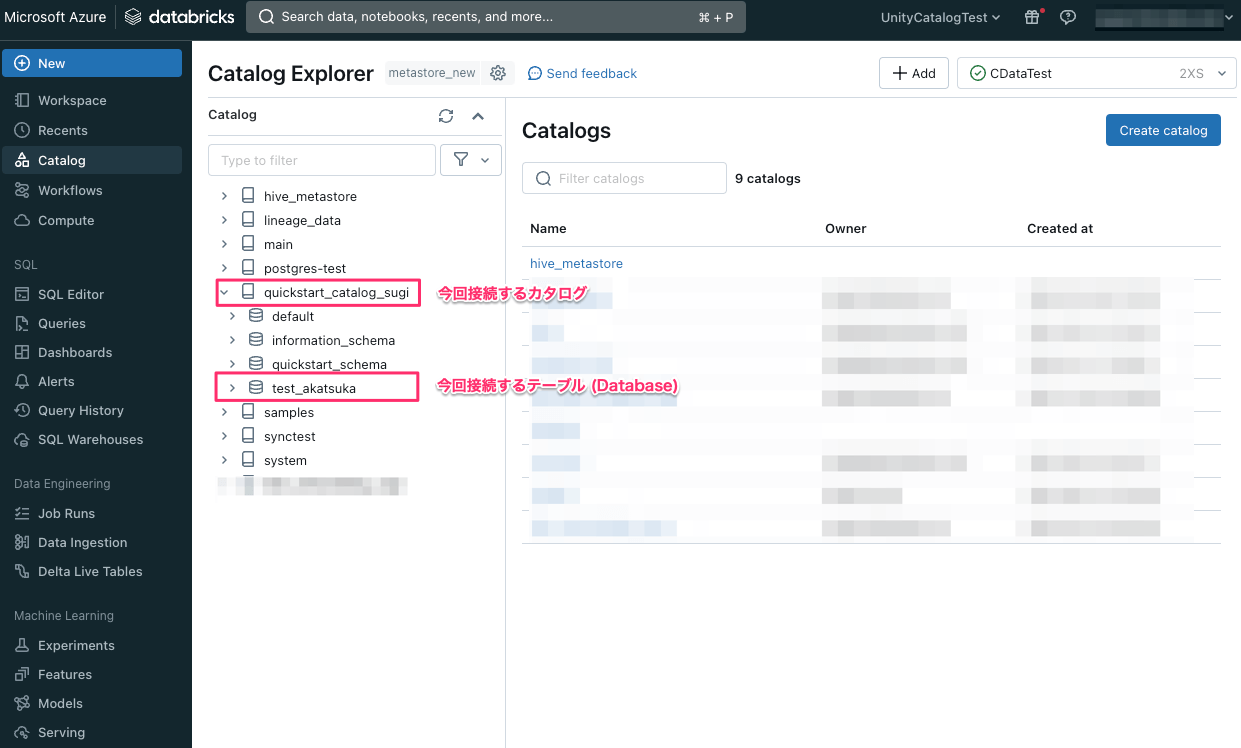
CData Sync との接続を確認するために、Azure Databricks 側で事前に作成した SQLウェアハウスのクラスターを起動します。
また、Azure Databricks 側で接続したいカタログ名やテーブル名を確認しておきましょう。
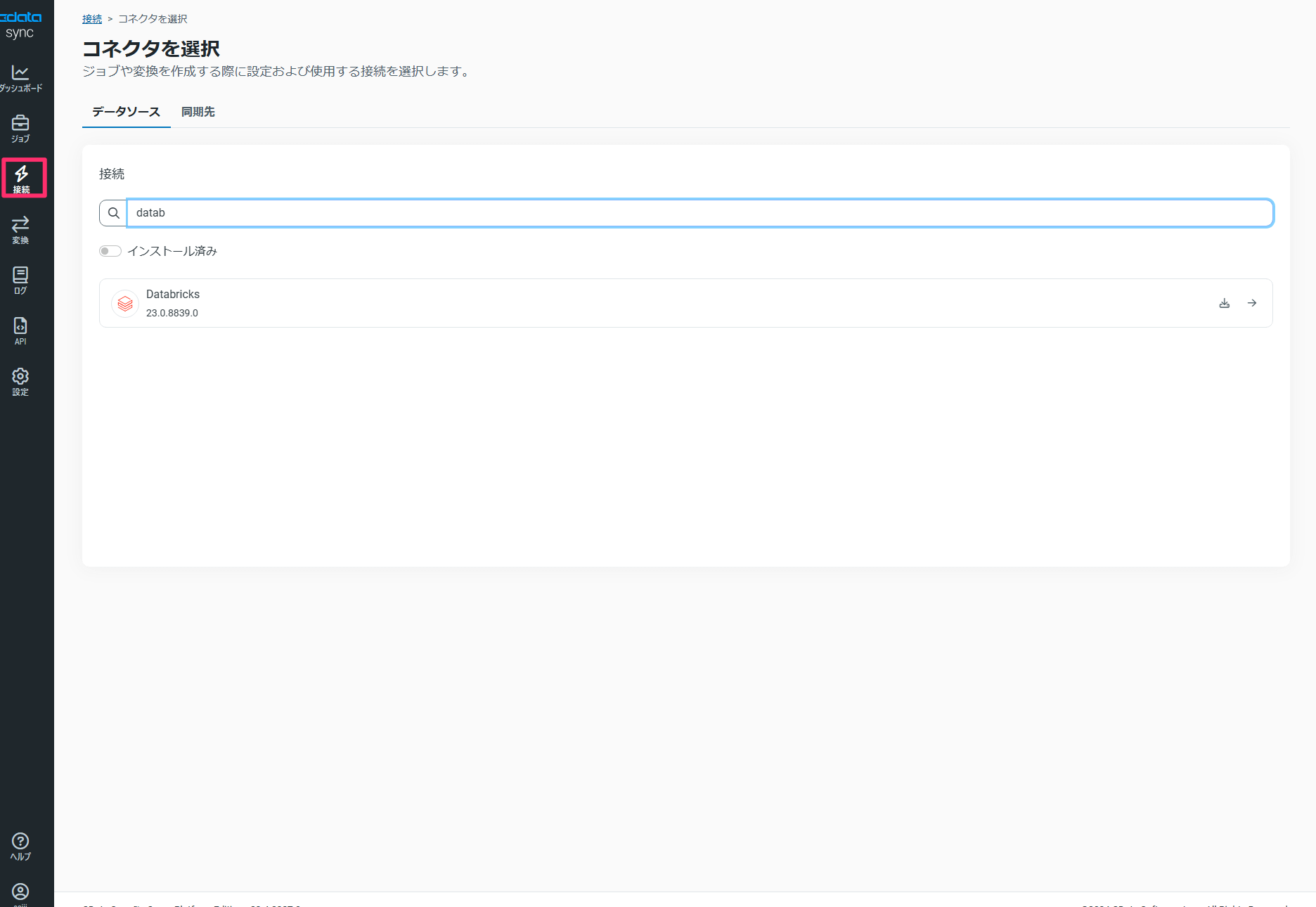
1の手順と同様にCData Sync の接続メニューにて「Databricks」を検索して必要な情報を登録します。
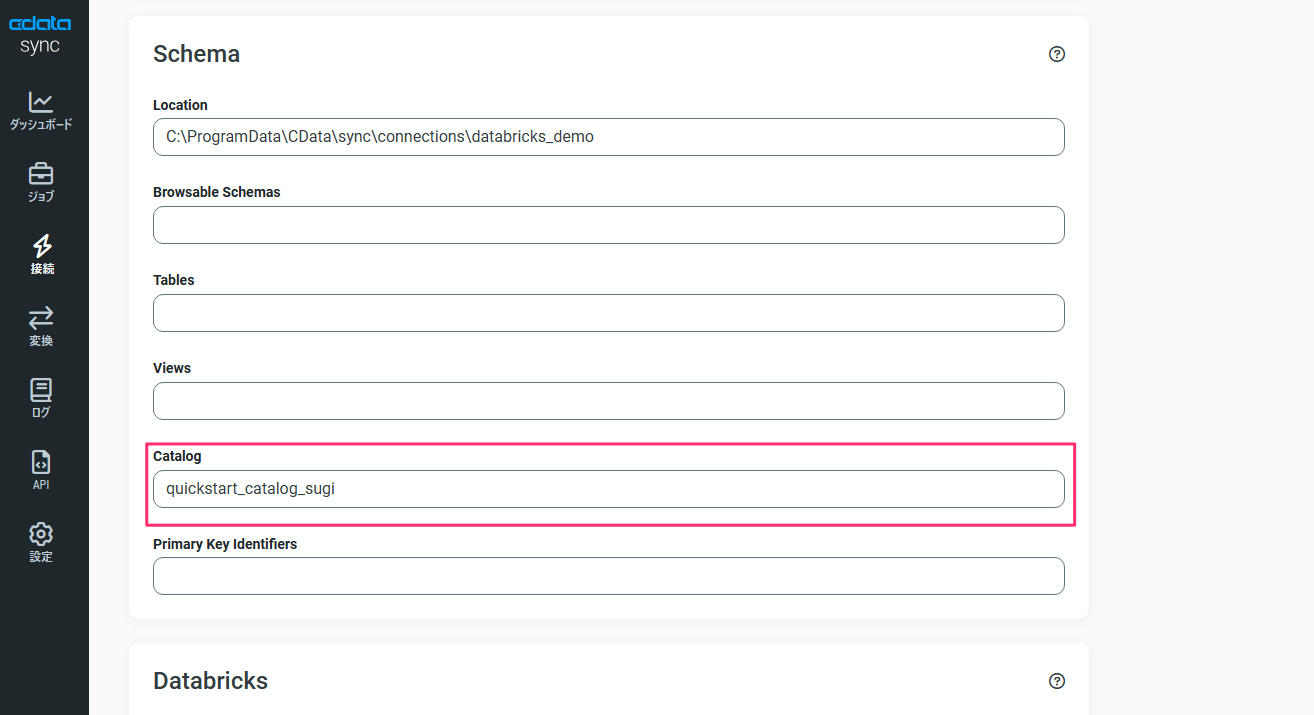
CData Sync でUnity Catalog にアクセスするために、「高度な設定」タブ内にある「Schema」の項目にて「Catalog」の値を初期値の「hive_metastore」から今回用に作成したカタログ名に変更します。
また、「設定」タブ内にある「Database」の値についても、今回用に作成したカタログ配下のテーブル名を設定します。
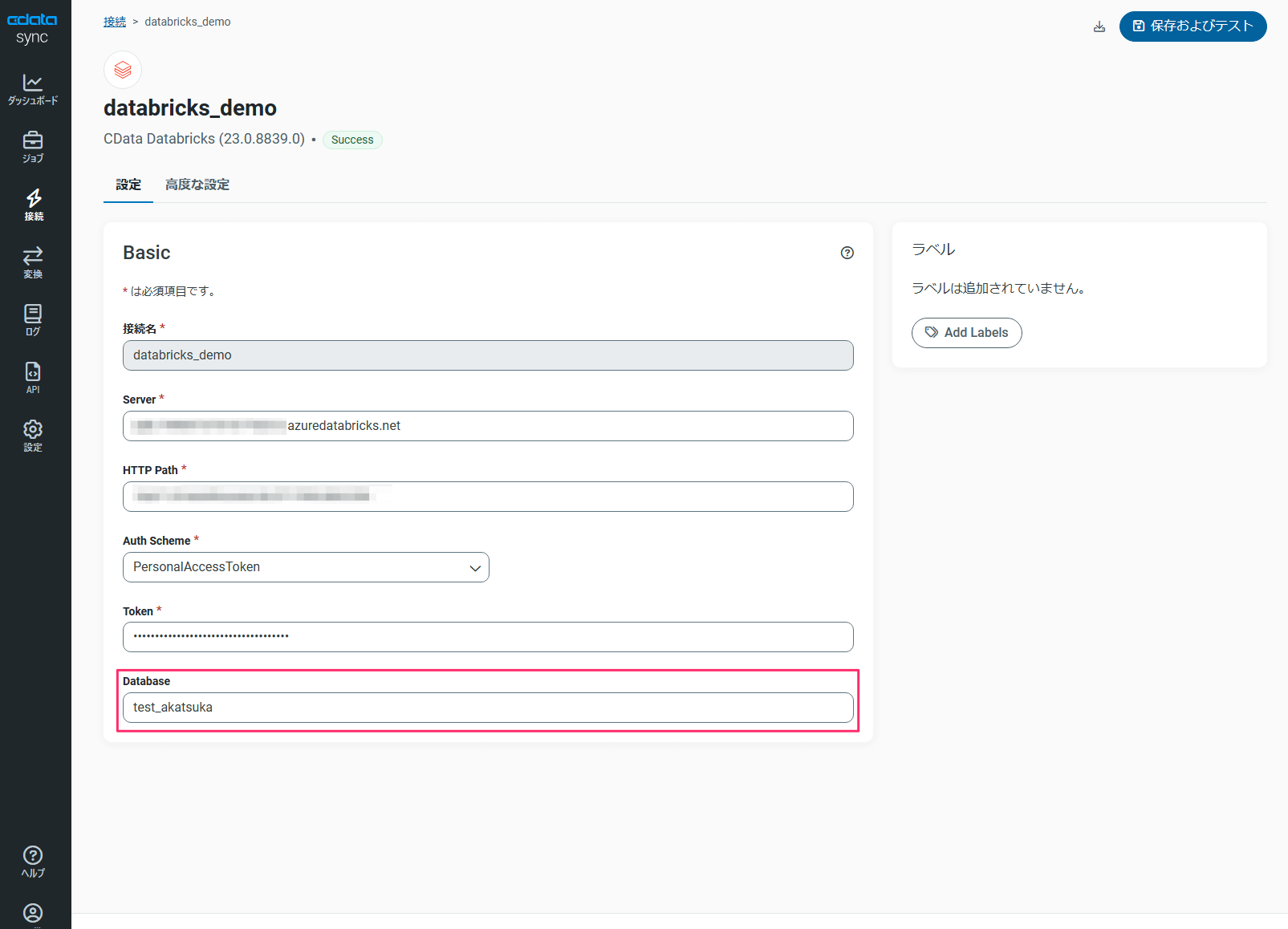
接続情報の登録ができたら「保存およびテスト」をクリックして接続が成功することを確認します。
なお、Unity Catalog への接続用に設定した「高度な設定」タブ内にある「Schema」の項目や「設定」タブ内にある「Database」の値を初期値のままにしてレプリケーションを実施した場合はレガシー Hive metastore となる「hive_metasore」カタログ内の「default」スキーマ配下にテーブルが作成されてデータが同期されます。
Unity Catalog と レガシー Hive metastore の違いの詳細については公式のドキュメントをご参照ください。
3 CData Sync に「ジョブ」を登録
「ジョブ」にはソースへの接続情報と同期先への接続情報を登録します。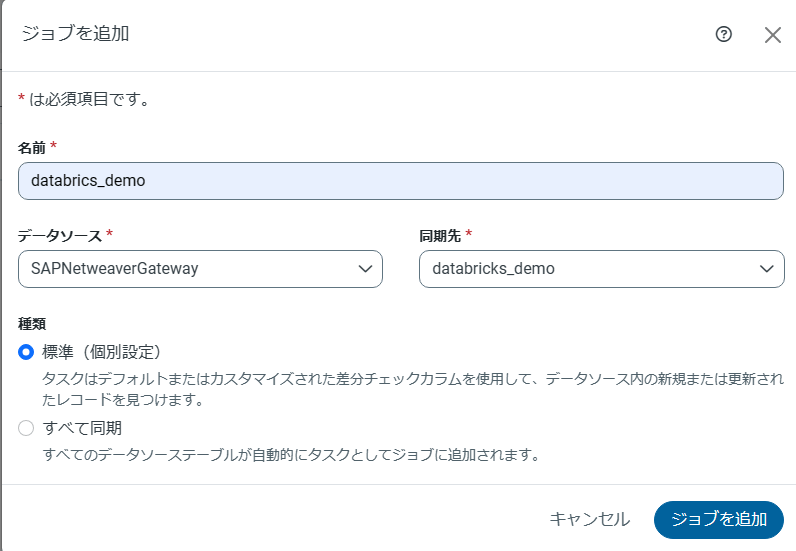
4 登録した「ジョブ」に 実際のレプリケーション処理を行う「タスク」を追加
3 で登録した「ジョブ」にある「タスク」タブを開いて「タスクを追加」をクリックし、データソースとなるテーブル名を選択します。
データの同期先となるDatabricks 側のテーブルはCData Sync 側が自動的に作成するため設定は不要です。
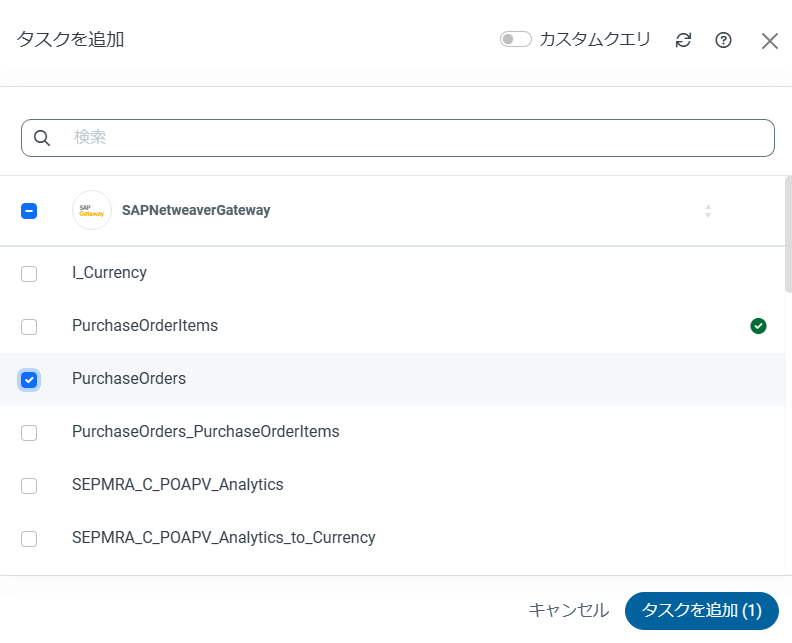
なおCData Sync のジョブには複数のタスクの登録が可能ですので、必要に応じて設定を追加します。
5 タスクを実行してレプリケーションを実施
ソースデータへの接続、同期先への接続、およびデータフローとなるジョブとタスクが作成されましたので、実際にタスクを実行してレプリケーションを行なってみます。
タスクの実行前に、Azure Databricks 側の SQL Warehouse クラスターが停止している場合は起動します。
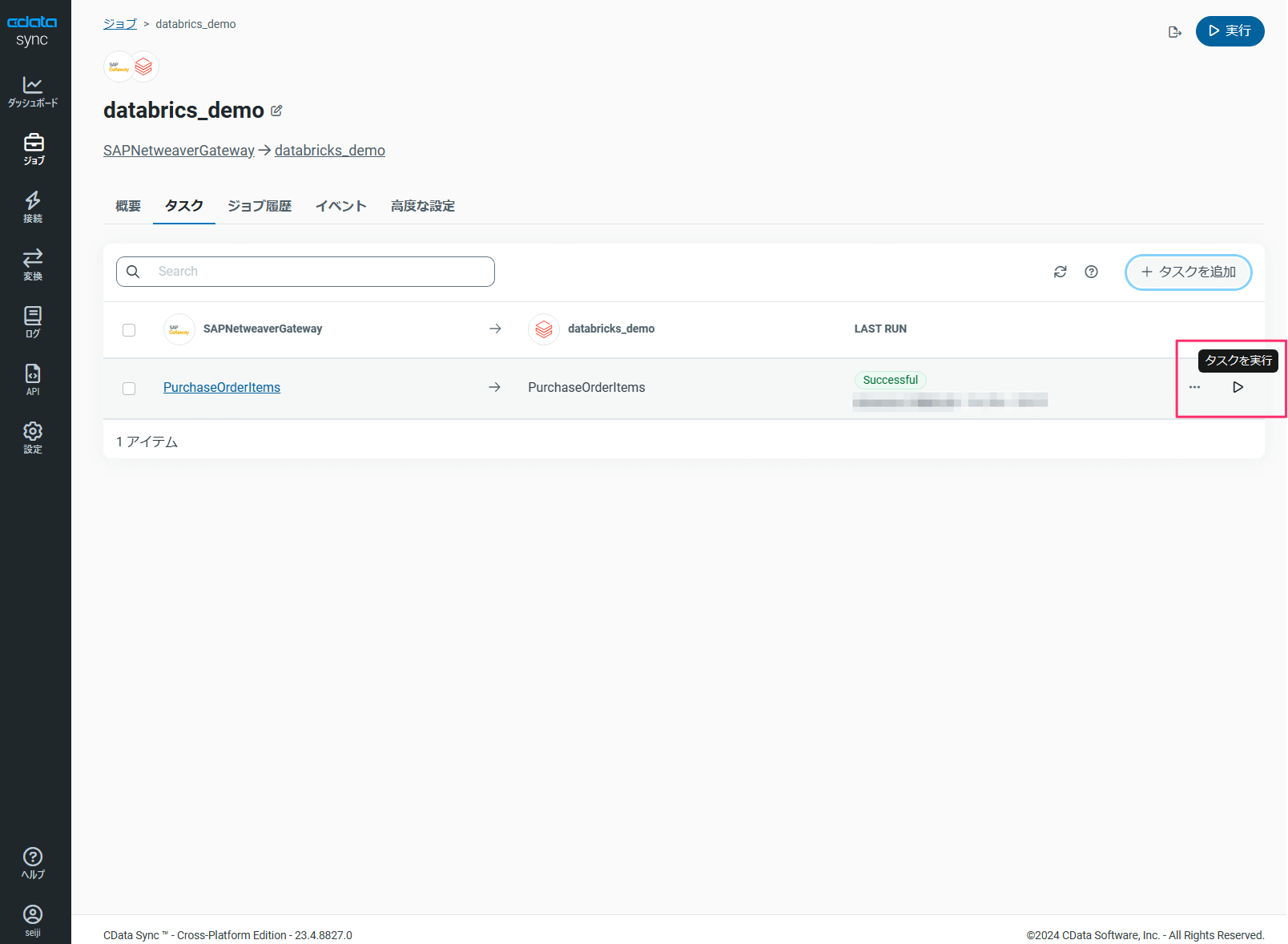
タスクの処理が完了したのでAzure Databricks 側にレプリケーションが行われているかを確認しましょう。
Unity Catalog にソースデータの「purchaseorderitems」テーブルが作成され、「Sample Data」タブでデータが同期されていることが確認できました。
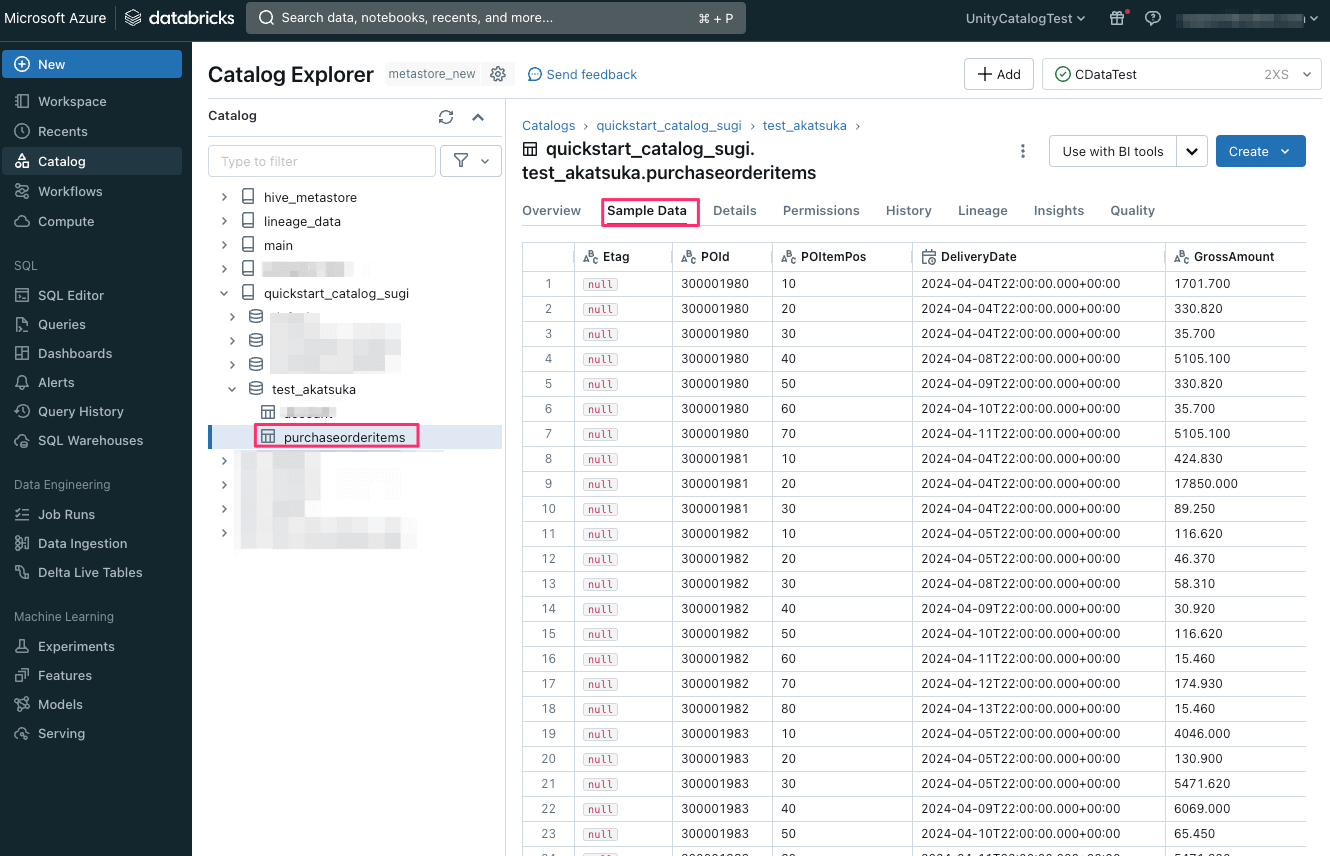
続いてAzure Databricks 上でどのようなことが出来るようになったか確認してみましょう。
生成AI によるデータのドキュメンテーション
追加されたテーブルの「Over view」タブでは、生成AI によるデータのドキュメンテーションが確認できます。
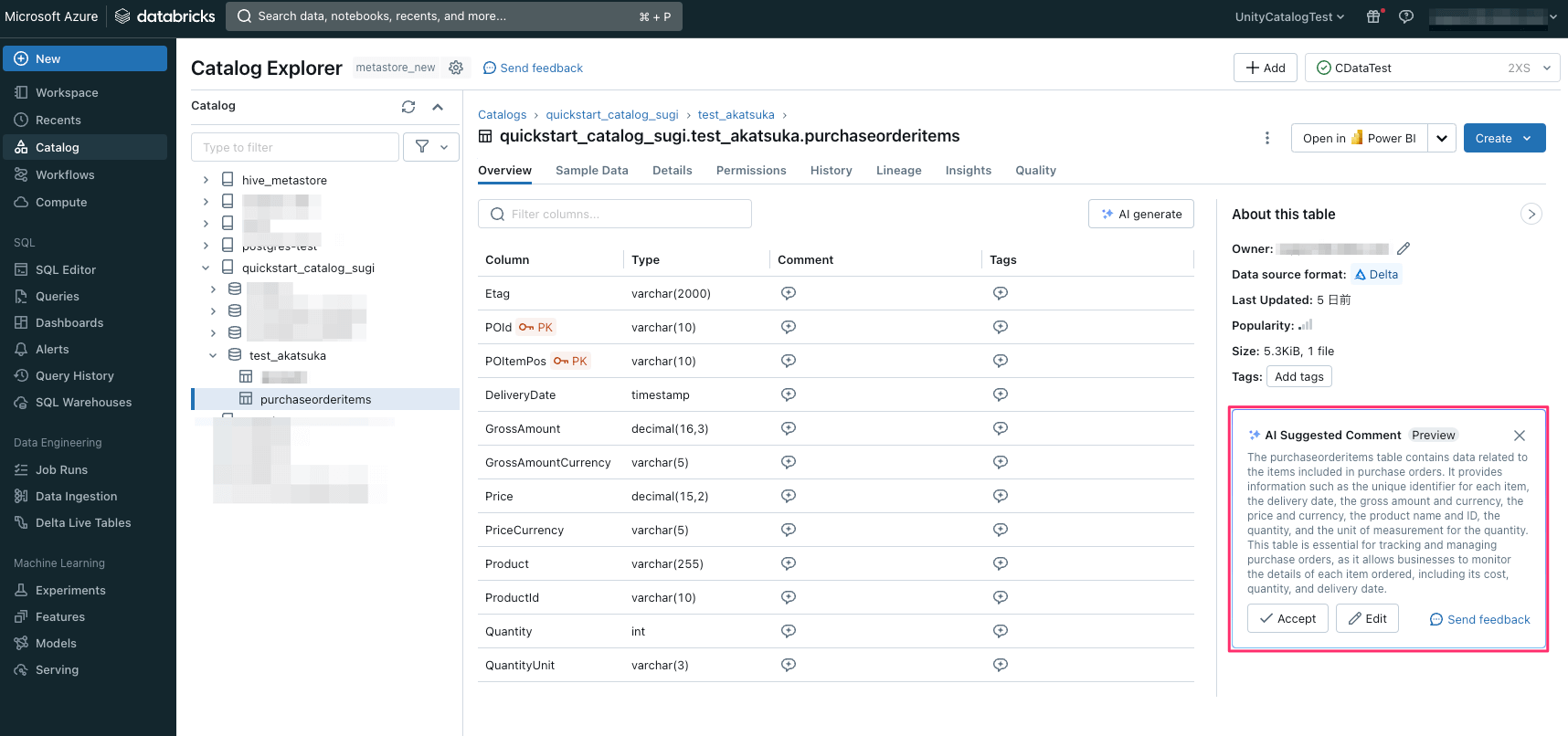
こちらは現時点ではパブリックプレビューで公開中ですが、生成された説明文を必要に応じて修正して「Accept」をクリックすると情報がUnity Catalog に保存されます。
テーブルやカラムに関する適切なメタデータの付与により、データの信頼性・検索性が向上します。
データリネージ
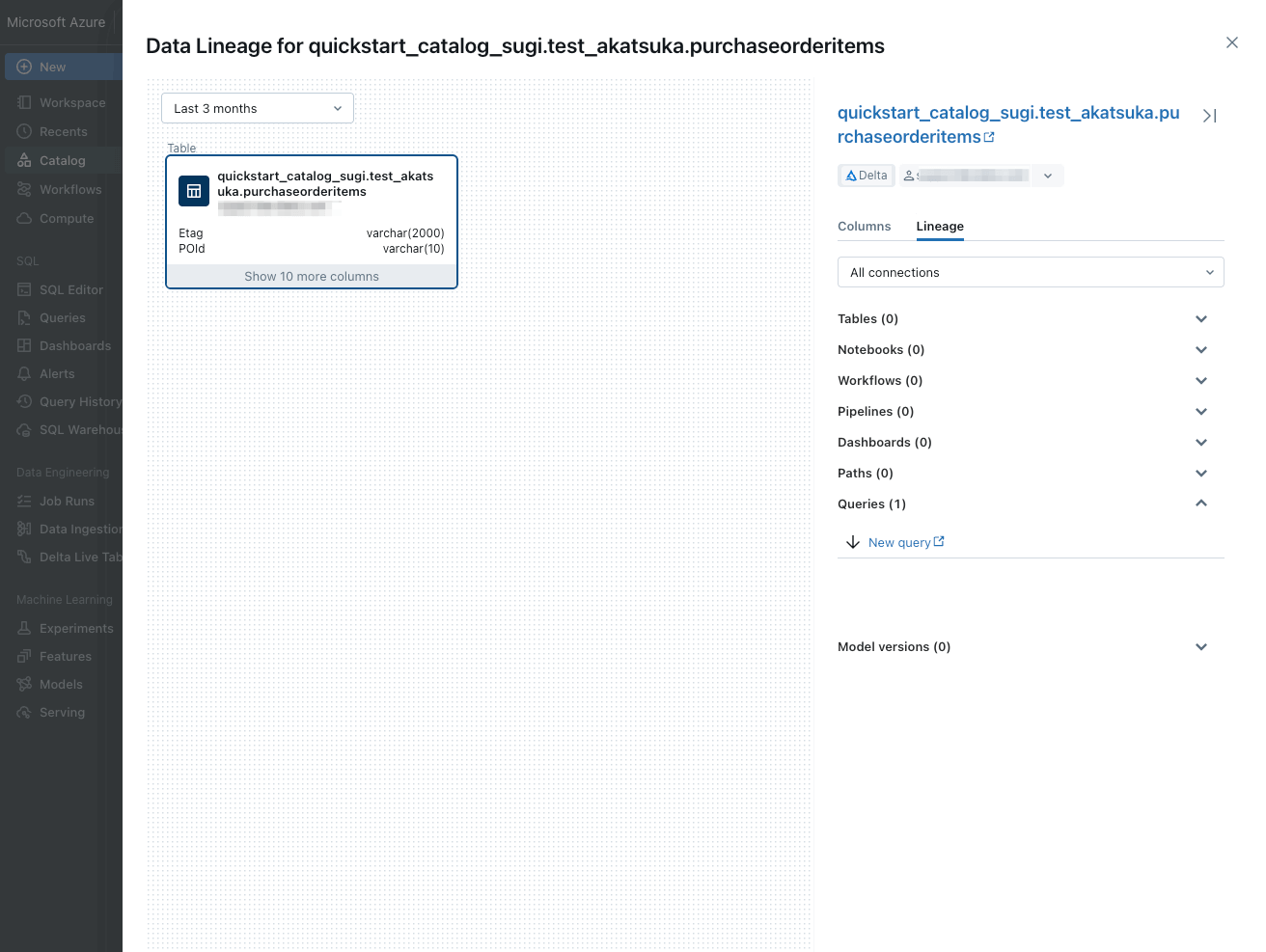
「Lineage タブを表示すると、データがどのような処理をされたかなどのデータリネージが参照できます。
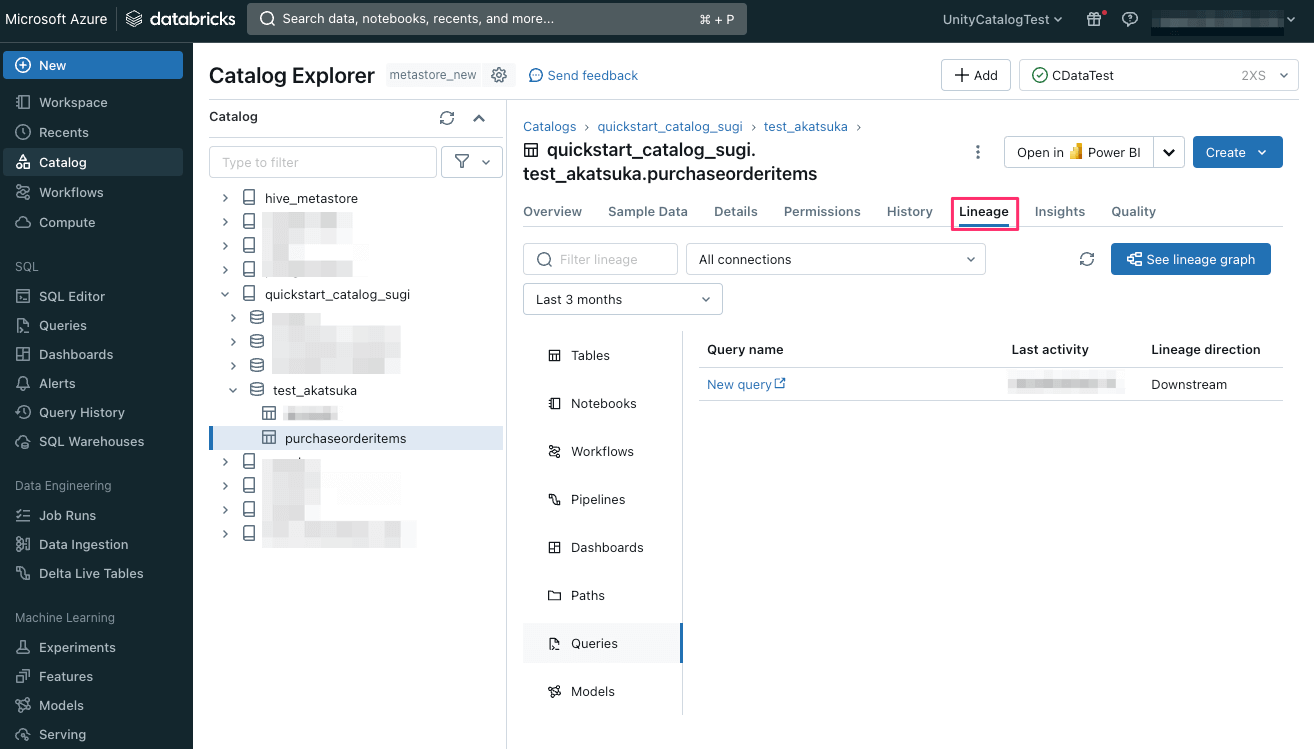
データリネージはデータサイエンティストなどデータの利用者が適切な判断をするために最も重要視する情報の一つです。
分析情報
「Insights」タブでは、過去 30 日間にテーブルで実行されたクエリとテーブルにアクセスしたユーザーの確認が可能です。
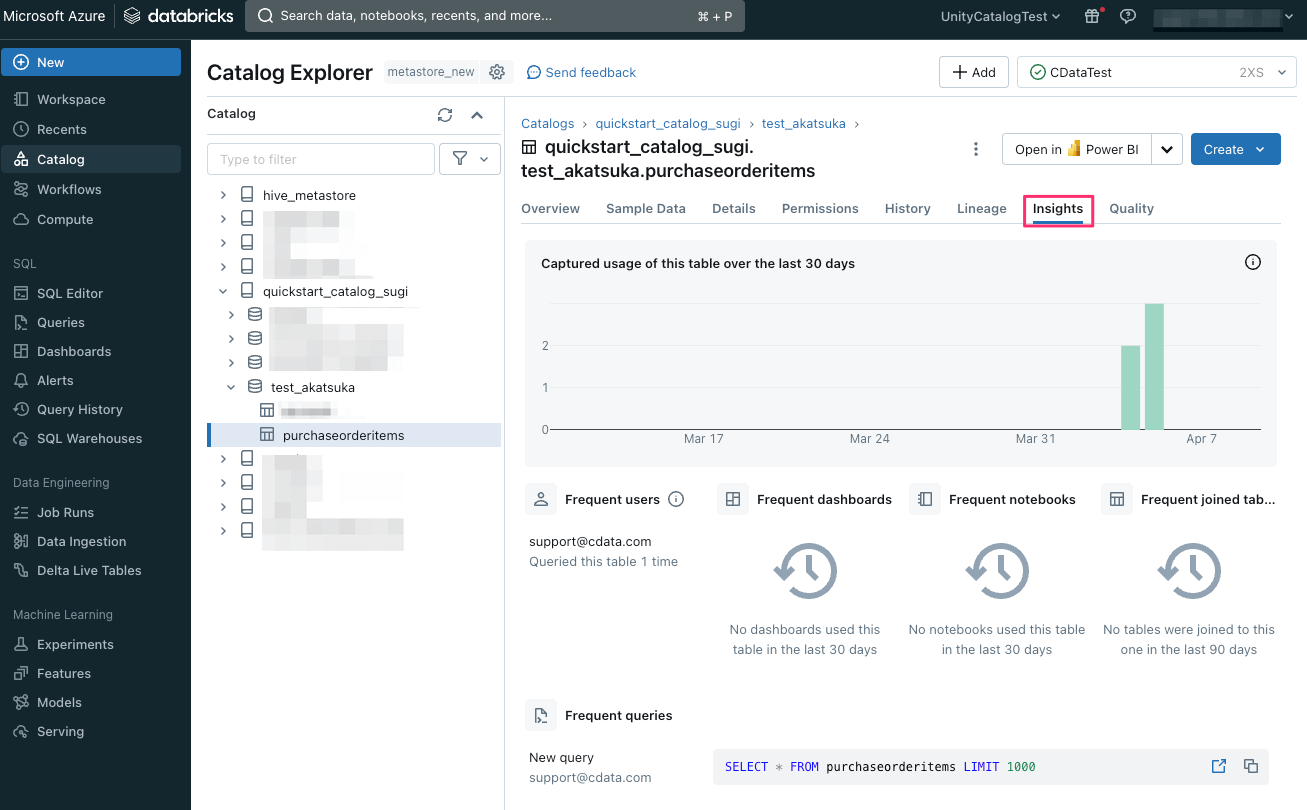
また、Unity Catalog によって管理されているシステムテーブルの情報を活用し、ユーザーのアクセス情報の確認ができました。
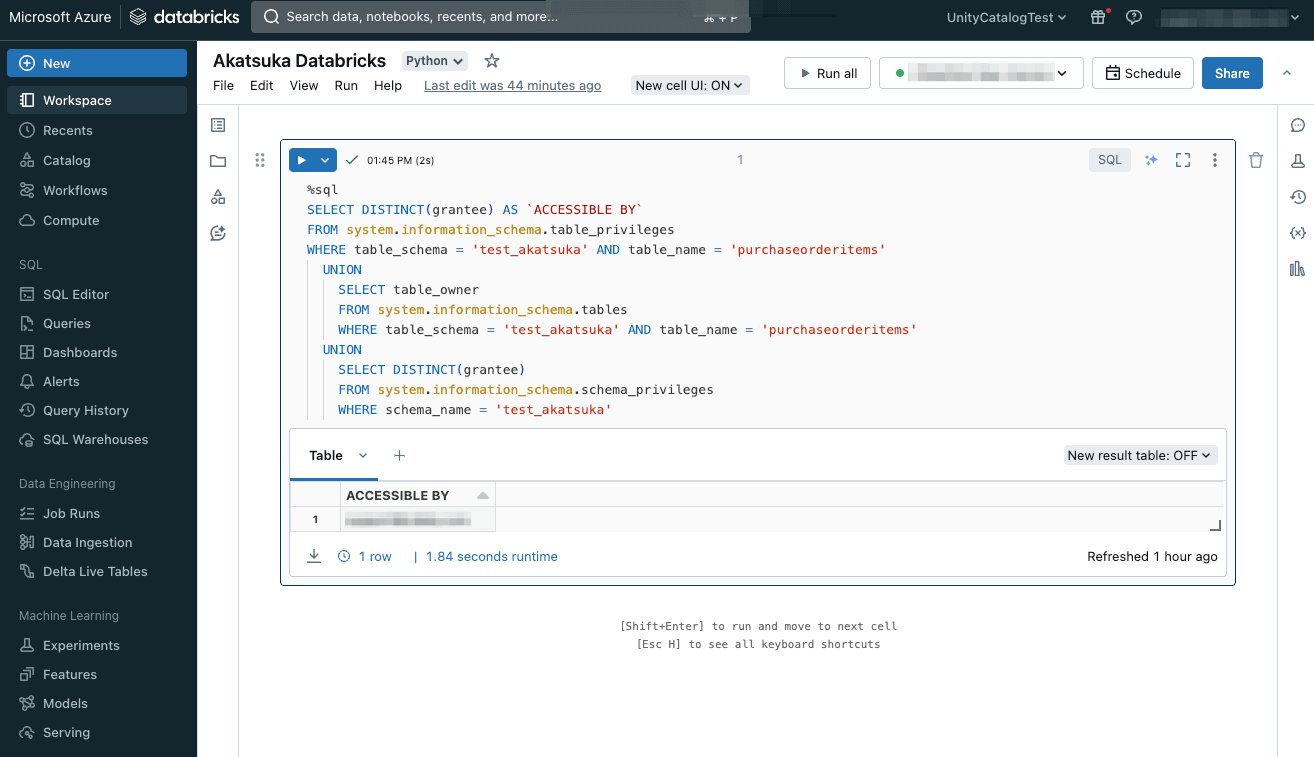
システムテーブルの活用により、データの利用分析、消費/コスト予測、侵害の兆候(IoC)等の高度な監査も可能です。
以上でCData Sync を使って既存のデータソースをAzure Databricks にレプリケーションし、高度な分析や生成AIの活用が可能になりました。
CData Sync は30日間の無料トライアルも可能です。
ぜひお気軽にお試しください!
関連コンテンツ



