
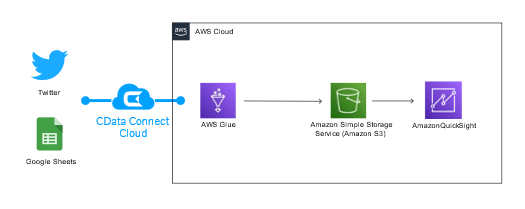
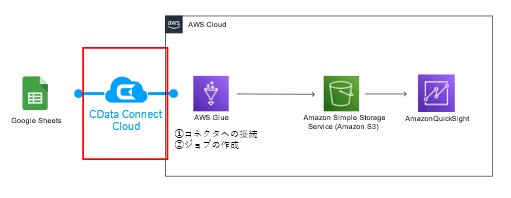
こんにちは。マーケティング担当の對馬です。データ分析ニーズが増えている中、データの収集・加工フェーズでETL ツールの利用を検討している方も多いのではないでしょうか。AWS が提供する「AWS Glue」は、フルマネージドのETL ツールです。2020年にAWS Glue のビジュアルインターフェース「AWS Glue Studio」がリリースされ、ローコードでのプロセス記述が可能になったことで、多くのユーザーが利用しやすくなりました。
CData Software では、2022年6月にクラウドサービス「CData Connect Cloud」をリリースし、併せてAWS Glue で利用できる「CData AWS Glue Connector for CData Connect Cloud」をリリースしました。本コネクタを利用することで、AWS Glue の外部接続を100+ 拡張し、あらゆるSaaS データをAWS Glue 上で扱うことが実現できます。
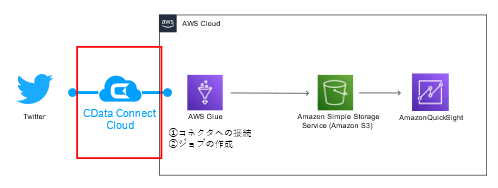
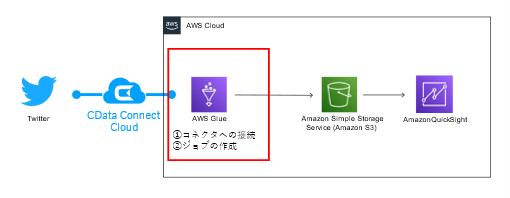
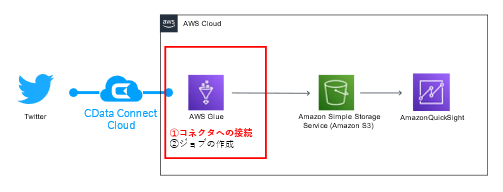
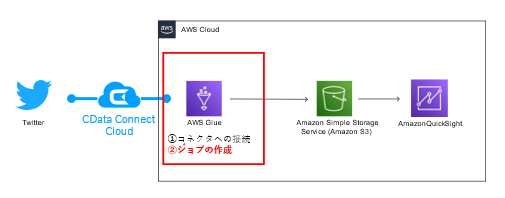
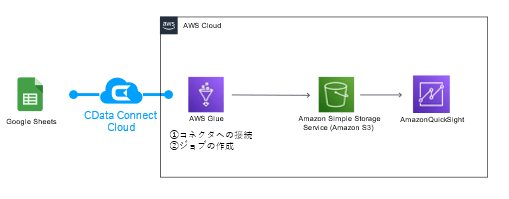
本記事では、CData Connect Cloud を利用してAWS Glue からTwitter とGoogle スプレッドシートに接続し、指定したデータをCSV 形式でそれぞれS3 に出力するジョブの作成方法をご紹介します。
事前準備: Google スプレットシートへのデータセットとS3 構築
ハンズオンで利用するGoogle スプレットシートとS3 を準備します。
1:Google スプレットシートへのデータセット
Google スプレットシートに格納されているデータを、AWS Glue で利用します。用意したCSV ファイルを以下リンクからダウンロードし、Google スプレットシートにインポートします。
CSV ファイル取得
Google スプレッドシートを開き、空白のシートを作成します。
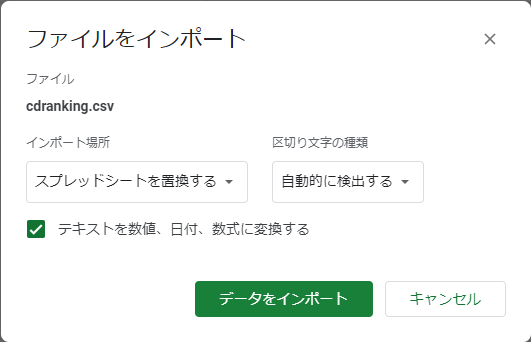
ファイル名を「cdranking」に変更し、「ファイル」メニューから「インポート」を選択します。
インポート画面が開かれますので、「アップロード」タブを開きCSV ファイルを指定します。
デフォルトのまま、「データをインポート」を押下します。
CD 売上ランキングデータがインポートされました。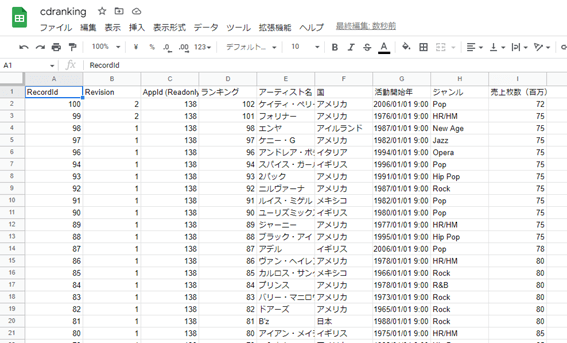
2:S3 構築
AWS Glue からデータを格納するための、S3 を構築します。
AWS コンソールにログインします。サービスの検索窓から「S3」を検索し、S3 を選択します。
バケットを作成します。「バケットを作成」ボタンを押下します。
バケット名を指定します。グローバルに一意である必要があるので、「awshandson氏名」など利用可能なもの、かつ後ほどバケット名は利用するのでわかりやすいものを指定します。
AWS リージョンは「アジアパシフィック(東京)」を選択します。
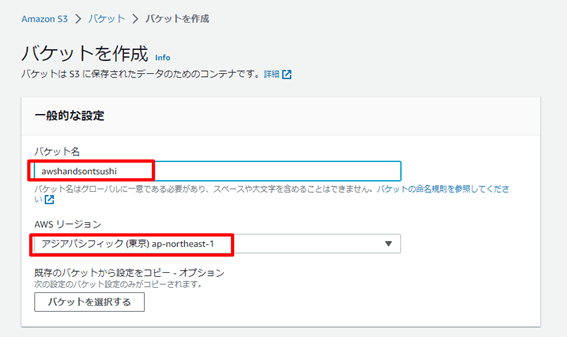
その他の設定はデフォルトのまま、「バケットを作成」ボタンを押下します。
これで事前準備は完成です。
AWS Glue の外部データ接続機能
AWS Glue Studio では、AWS Marketplace やカスタムコネクタを使って、データソースへの接続を構築することができます。
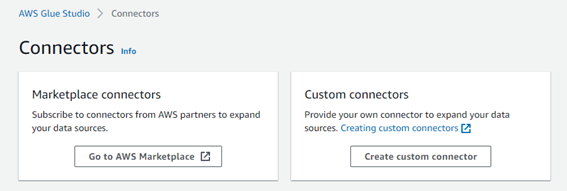
Marketplace では、AWS が提供しているコネクタやサードパーティーコネクタを選択できます。
多くのコネクタの中から、接続したい先を選んでコネクタを取得します。
CData Connect Cloud コネクタ
CData Connect Cloud で利用するGlue コネクタも、Marketplace から選ぶことができます。
CData Connect Cloud では、100を超えるデータソースへの接続をノーコードで可能にし、外部クラウドサービスのデータ標準化を行います。利用者はサービスの違いを意識することなく、データを利用することができます。

今回は、CData AWS Glue Connector for CData Connect Cloud を利用して、AWS Glue の接続先拡張を体験していただきます。
ハンズオンのシナリオ
今回はGoogle スプレットシートとTwitter のデータを利用して、Glue での接続先拡張を体験します。まずはTwitter データを使った処理を構築します。
1:Twitter データをGlue のジョブで利用し、S3 に格納する
1-1:CData Connect Cloud での設定
CData Connect Cloud を使って、データソースへの接続を作成します。
1-1-1:アカウント取得
CData Connect にアクセスしてみましょう。
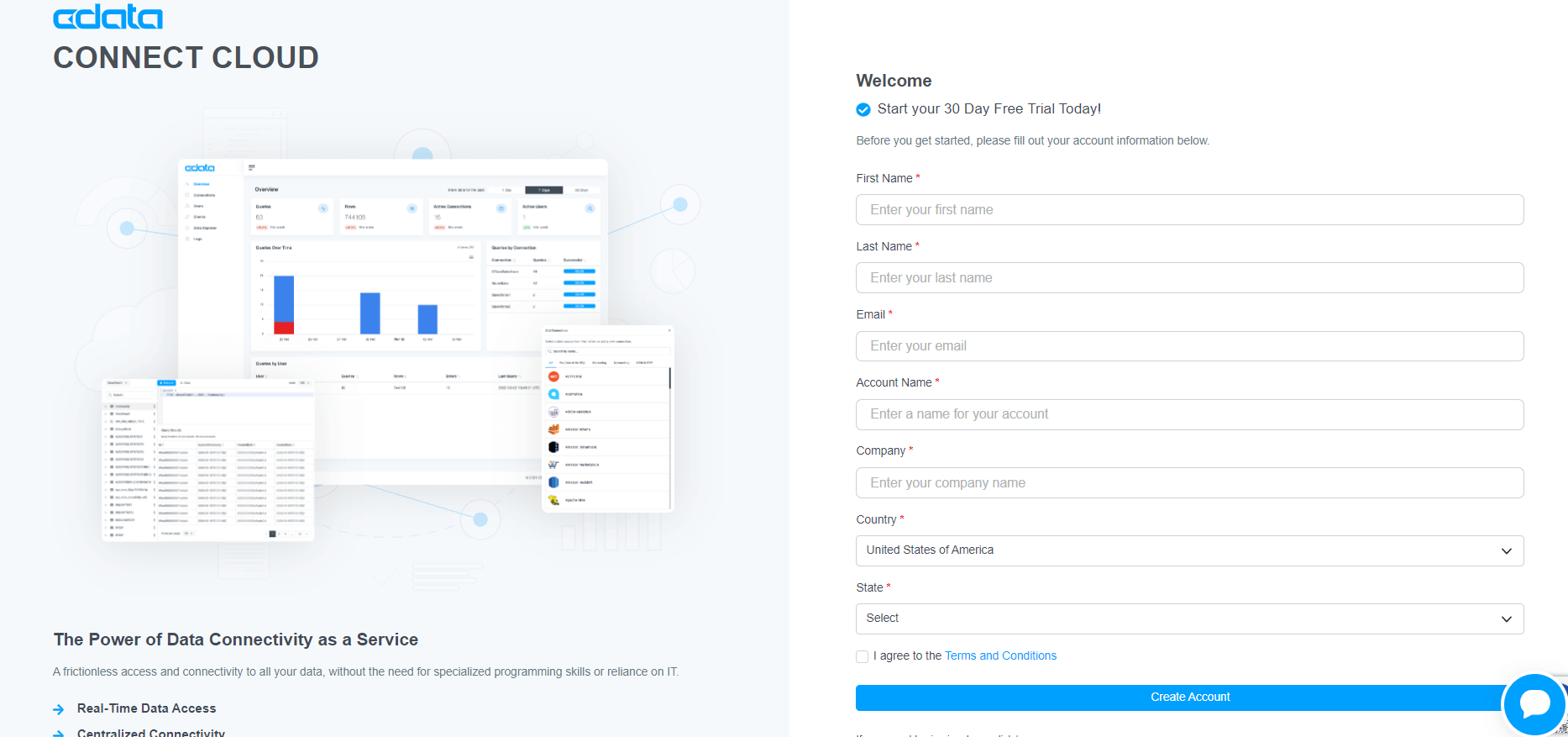
CData Connect Cloud は、30日間の無償トライアルがあります。製品ページからお申込みください。
https://www.cdata.com/jp/cloud/
アクセスするとアカウント情報を登録する画面が開かれますので、適宜入力して画面下部のCreate Account ボタンをクリックします。
アカウントが作成されましたら CData Connect Cloud にログインします。ログイン直後、コネクション選択の画面が開かれますが、左上のCData ロゴを押下してトップ画面に戻ってください。
1-1-2:Twitter接続設定
CData Connect Cloud からTwitter への接続を作成します。
CData Connect Cloud にログインし、左メニューの「Connections」を開きます。
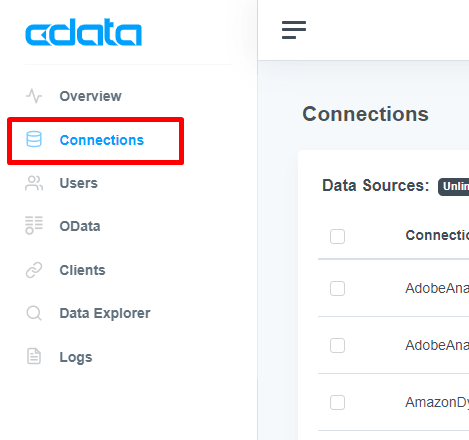
Connections では、データソースへの接続を設定できます。Connections 画面右の「Add Connection」ボタンを押下し、新規接続を作成します。
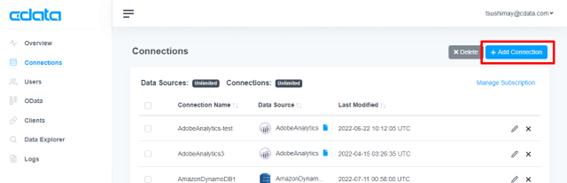
接続できるデータソースの一覧が表示されます。検索窓から「Twitter」を検索し、アイコンを選択します。
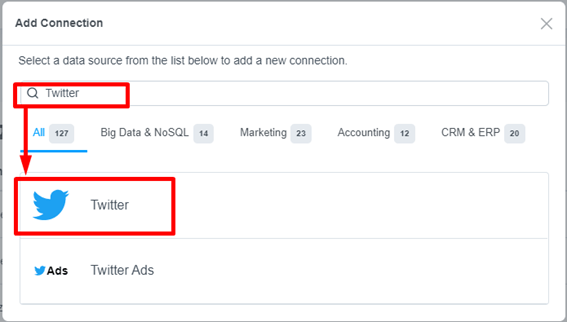
Twitter 接続設定画面が表示されます。接続名はわかりやすい任意の名前で設定(デフォルト:Twitter1)し、下の「Sign in」ボタンを押下しTwitter に接続します。
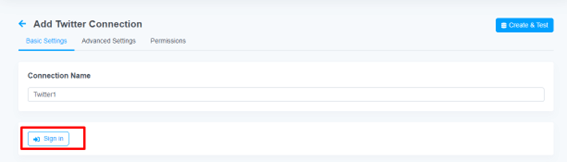
Twitter 画面が開き、アクセス許可を求められます。「連携アプリを認証」ボタンを押下し、認証します。
自動的にCData Connect Cloud の画面に戻ります。
緑のメッセージが出ると、Twitter への接続は成功です。

1-1-3:検索キーワードの設定
Twitter から取得するデータの設定をします。今回は「#awsbasics」のツイートを取得します。
CData Connect Cloud 画面左メニューから「Data Explorer」を開きます。Data Explorer では、取得データの確認やクエリの保存ができます。
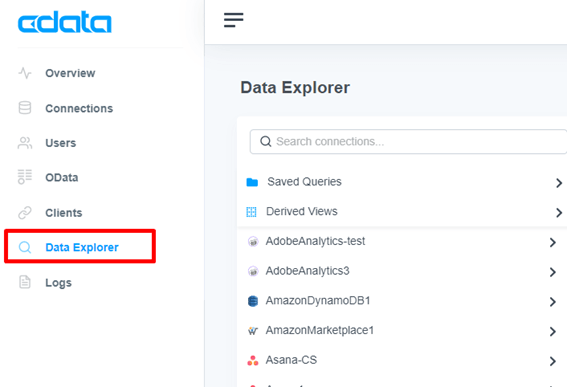
作成した接続設定がData Explorer 左に表示されます。検索窓から「Twittter」を検索し、先ほど作成したTwitter の接続情報をクリックします。(作成の都合上、記事では別名になっています)
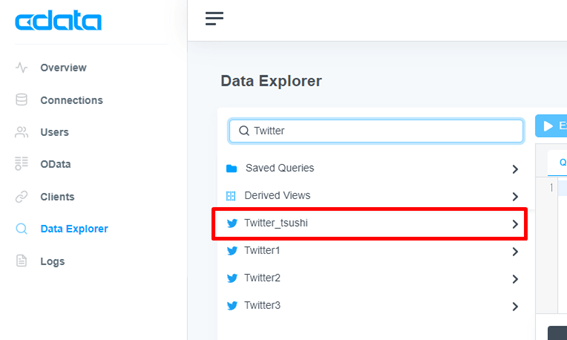
Twitter から取得できるデータがテーブル構造で表示されます。CData 製品ではこのように、SaaS データをテーブル型で扱うことが可能です。今回はツイート情報を取得するため、「Tweets」テーブルを利用します。Tweets の3点リーダーを開き、「Query」を選択します。クエリ記述エリアにTweets データを全件取得するクエリが表示されます。
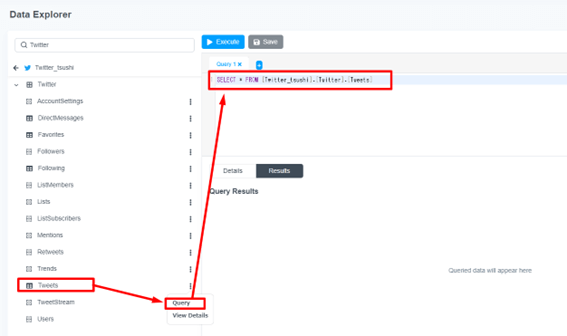
検索キーワードとして、「SearchTerms」で「#awsbasics」を指定します。そしてリツイートされたツイートも取得されるため、「Reteeted_Status_Id」がNull であること、そして取得データを100件で指定する以下のクエリを利用します。以下クエリをクエリ記述エリアに貼り付けます。
SELECT * FROM [Twitter1].[Twitter].[Tweets]WHERE ([SearchTerms] = '#awsbasics') AND ([Retweeted_Status_Id] IS NULL) LIMIT 100
クエリが正常に動くかどうか確認します。「Execute」ボタンを押下し、クエリを実行します。下部のクエリ結果画面にデータが表示されますので、想定通りのデータが取得できているかどうか確認します。
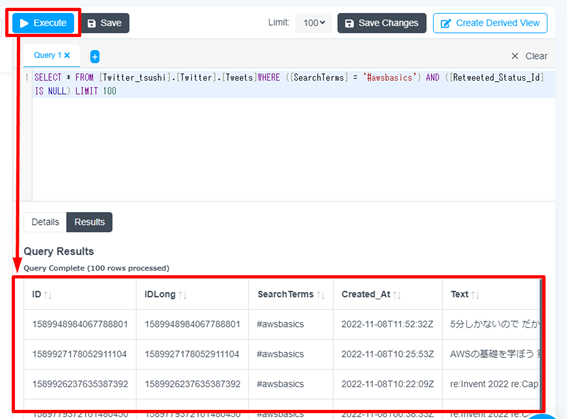
記述したクエリを保存し、外部から利用できるようにします。画面上部「Create Derived View」ボタンを押下します。
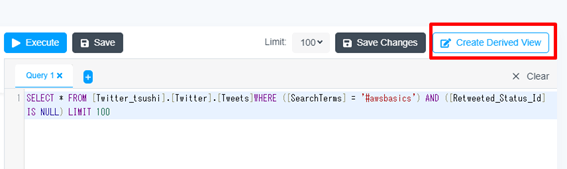
View の名前を指定します。(例:Awsbasics)Query を確認し、「Confirm」ボタンを押下します。
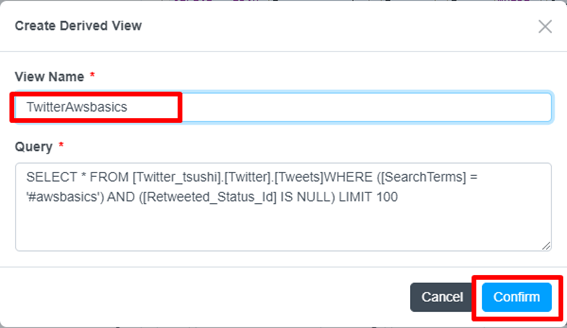
Derived View の設定はこれで完了です。
1-1-4:PAT 発行
AWS Glue からCData Connect Cloud に接続する際に利用する、個人用アクセストークンを発行します。
CData Connect Cloud 画面右上のユーザー名開き、「Settings」を開きます。
設定画面が開かれます。
「Access Tokens」タブを開き、「Create PAT」から新規PAT を発行します。
任意の名前を指定します。例:AWShandson
「Create」ボタンを一度だけ押下します。
PAT が発行され、画面に表示されます。一度しか表示されませんので、PAT は控えておいてください。
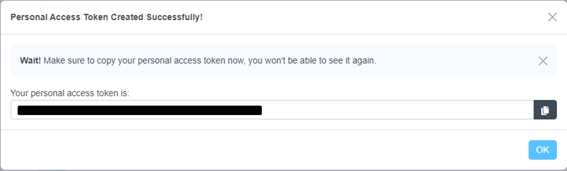
CData Connect Cloud での設定は以上です。
1-2:AWS:IAM ロール作成
続いてAWS での設定をします。
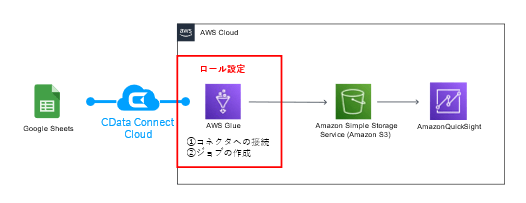
AWS Glue の利用には、以下アクセス権限を持つIAM ロールが必要です。
- AWSGlueServiceRole
- AmazonEC2ContainerRegistryReadOnly
- AmazonS3FullAccess
AWS コンソールを開き、Identity and Access Management (IAM) から、ロールの管理画面を開きます。
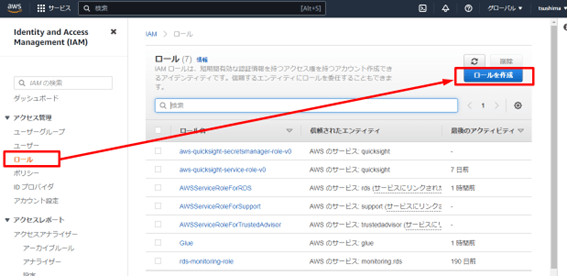
エンティティタイプを「AWS のサービス」で指定し、ユースケースでは「他のAWS のサービスのユースケース」で「Glue」を選択します。
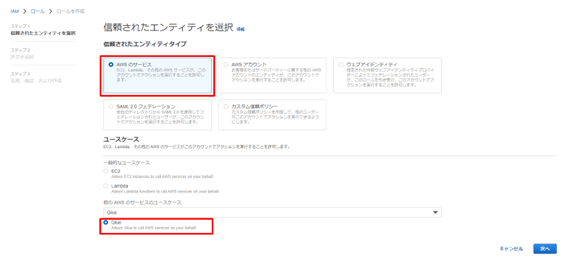
次の画面で、以下許可ポリシーを追加します。
- AWSGlueServiceRole
- AmazonEC2ContainerRegistryReadOnly
- AmazonS3FullAccess
次のページでロールの名前を指定し、設定内容を確認します。「ロールを作成」ボタンを押下し、ロールを作成します。
1-3:CData AWS Glue Connector の利用
AWS Glue からCData Connect Cloud に接続するため、コネクタを取得します。
CData AWS Glue Connector を以下AWS marketplace で取得します。
https://aws.amazon.com/marketplace/pp/prodview-zrpo2rdikze5k
「Continue to Subscribe」を押下します。
そのまま「Continue to Configuration」を押下します。
ソフトウェア構成はデフォルトで進みます。
「Usage instructions」を開きます。
リンクからAWS Glue Studio を開くことができます。
1-4:AWS Glue Studio での設定
CData Connect Cloud で作成したTwitter 接続情報を、コネクタ経由でAWS Glue から利用し接続します。
| 大項目 |
設定項目 |
設定内容 |
| Connection properties |
Name |
わかりやすい名前 |
| Connection access |
Connection credential type |
connect_cloud |
| Credentials |
Username |
CData Connect Cloud ユーザー名(メールアドレス) |
|
Password |
PAT |
|
defaultCatalog |
CData Connect Cloud で作成したTwitter 接続名(Twitter1) |
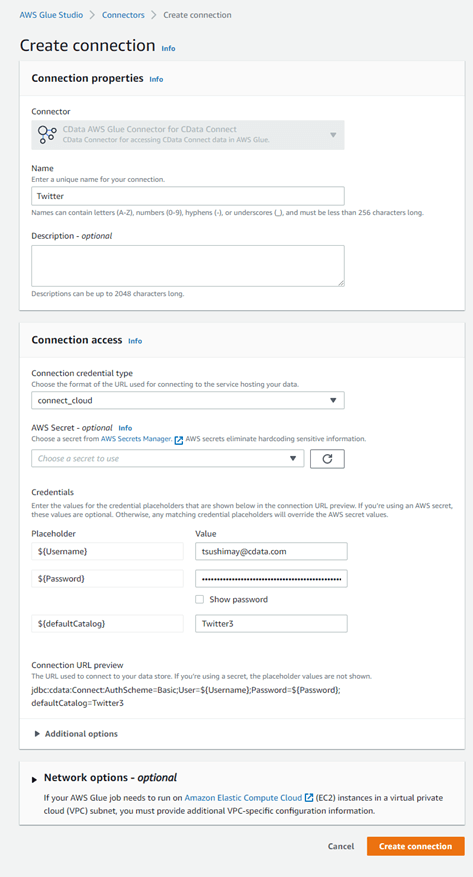
コネクションが追加されます。
1-4-1:ジョブの作成
ETL 処理のジョブを作成します。
左メニューを開き、「jobs」を選択します。
ジョブの管理画面が開かれます。
Create job にて「Visual with a source and target」を選択することで、データソースとターゲットが追加された状態からジョブを作成できます。
デフォルトではS3 で設定されているため、Source から「CData AWS Glue Connector for CData Connect Cloud」を選択し、上部「Create」ボタンを押下します。
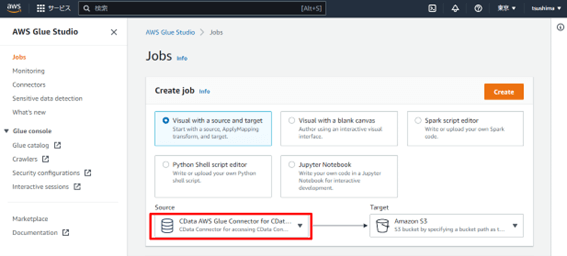
ジョブ作成画面が開かれます。
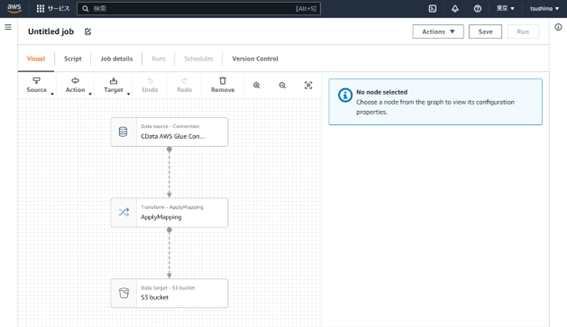
1-4-2:ジョブ設定
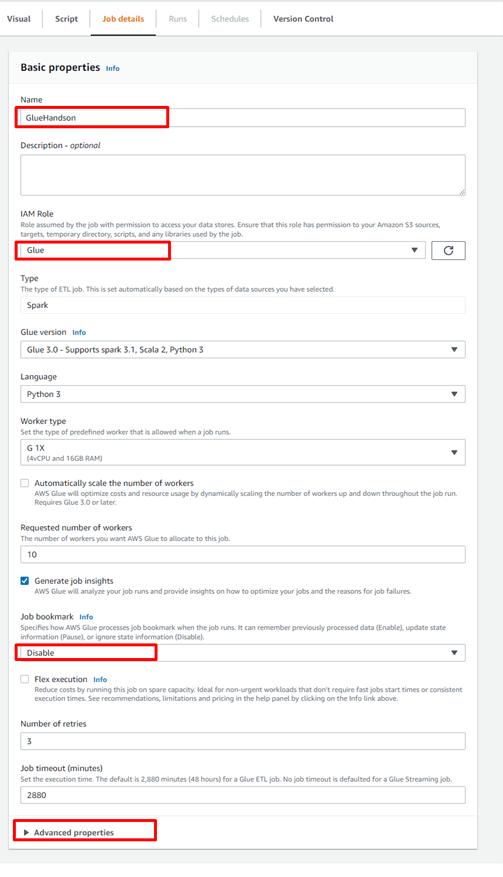
ジョブの基本設定をします。
| 設定項目 |
設定内容 |
| Name |
わかりやすい名前(例:Twitter2S3) |
| IAM Role |
事前に設定したIAM Role |
| Job bookmark |
Disable |
上記を設定し、Advanced propaties を開きます。
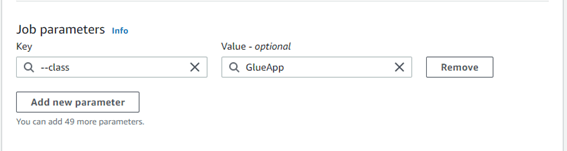
Job parameters でパラメータを追加します。
Glue のデフォルト設定でジョブを作成すると実行環境(Type)がSpark になります。そのときに実行スクリプトが「GlueApp」というクラス名でScala で生成されるため、Glue のジョブでクラス名を明示的に指定してあげる必要があります。
参考:https://docs.aws.amazon.com/ja_jp/glue/latest/dg/add-job.html
Key に「--class」、Value に「GlueApp」を手入力で指定します。
設定が終わりましたら、上部の「Save」ボタンで設定内容を保存します。
1-4-3:データソース設定
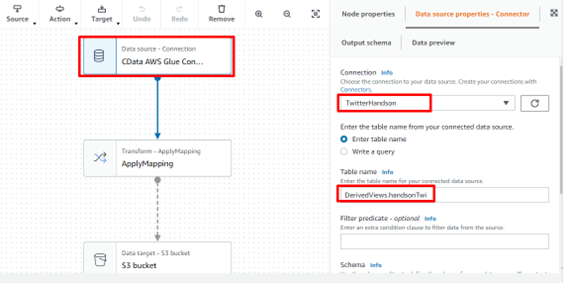
データソースアイコンを選択し、プロパティ画面から設定を行います。
Connection では先ほど作成したTwitter 接続設定を選択します。
CData Connect Cloud で作成したDerived View を利用してツイートの情報を取得するため、テーブル名は「DerivedViews.View名」(例:DerivedViews.TwitterAwsbasics)を指定します。
1-4-4:ターゲット設定
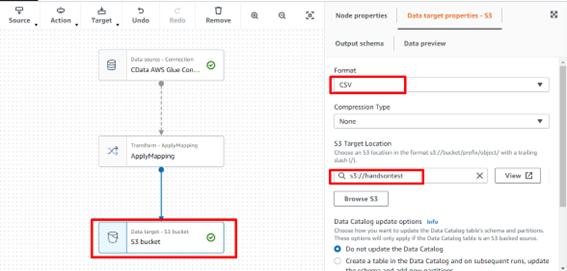
続いてターゲットであるS3 を設定します。
ターゲットアイコンを選択し、プロパティ画面から設定を行います。Format はCSVを選択します。S3 Target Location では作成したS3 を設定します。例:s3://handsontest
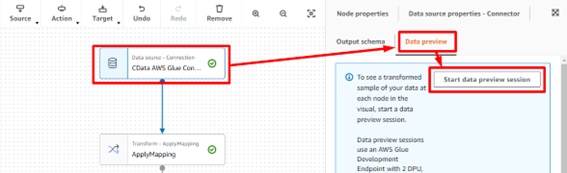
1-4-5:スキーマ取得
マッピングで利用するスキーマを取得します。データソースアイコンを開き、「Data preview」タブから「Start data preview session」を押下します。
「Confirm」を押下します。
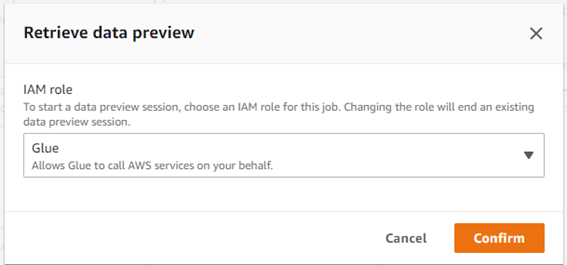
Twitter のデータをプレビューできます。
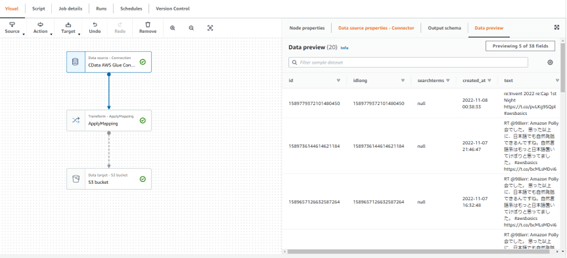
「Output schema」タブに移動し、「Use datapreview schema」を押下します。
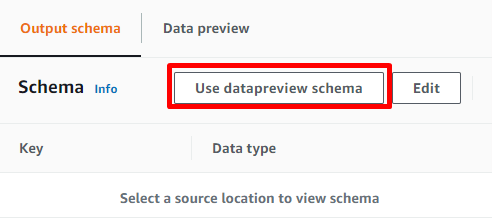
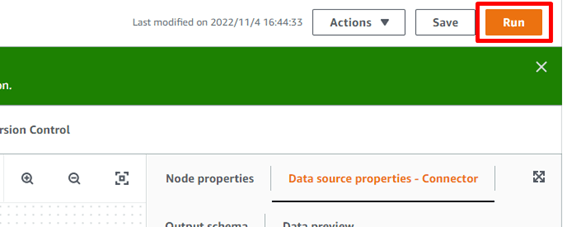
ジョブの設定は完了です。ジョブを保存し、実行します。
左メニューの「Monitoring」で、実行内容を確認できます。
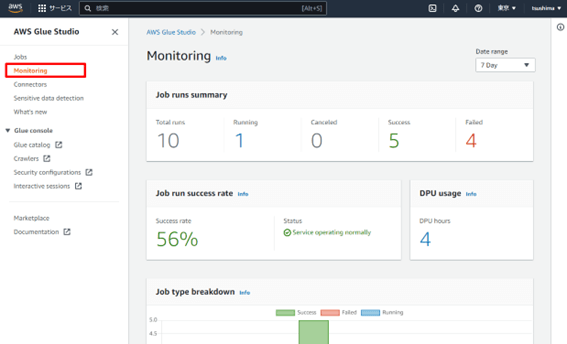
ジョブの成功が確認できたら、S3 を見てみます。
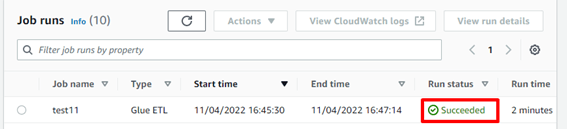
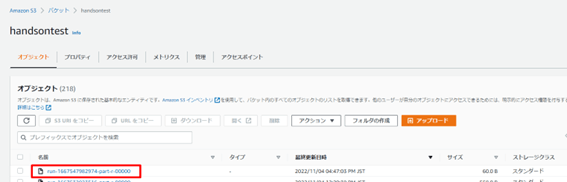
ファイルが格納されています。
Twitter のデータがCSV 形式で出力されています。
2:Google スプレットシートデータをGlue のジョブで利用し、S3 に格納する
続いて、Google スプレットシートのデータにGlue で接続し、S3 に格納するジョブを作成します。
まずはCData Connect Cloud を使って、データソースへの接続を作成します。
2-1:Google スプレッドシート接続設定
CData Connect Cloud からGoogle スプレッドシートへの接続を作成します。
CData Connect Cloud にログインし、左メニューの「Connections」を開きます。
Connections では、データソースへの接続を設定できます。
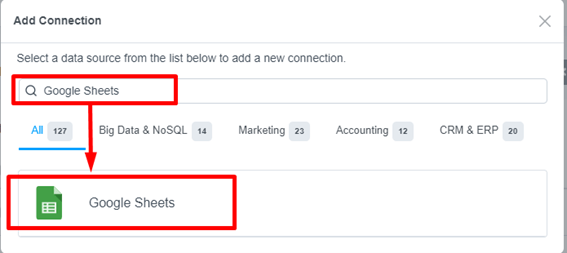
Connections 画面右の「Add Connection」ボタンを押下し、新規接続を作成します。
接続できるデータソースの一覧が表示されます。検索窓から「Google Sheets」を検索し、アイコンを選択します。
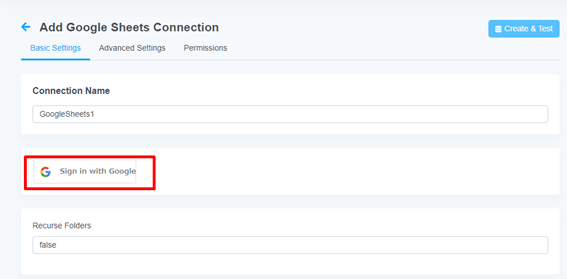
Google Sheets 接続設定画面が開かれます。
任意の接続名を設定できます。今回はデフォルトの「GoogleSheets1」で作成します。
接続認証は、OAuth 認証で行います。「Sign in with Google」ボタンを押下し、接続を確立します。
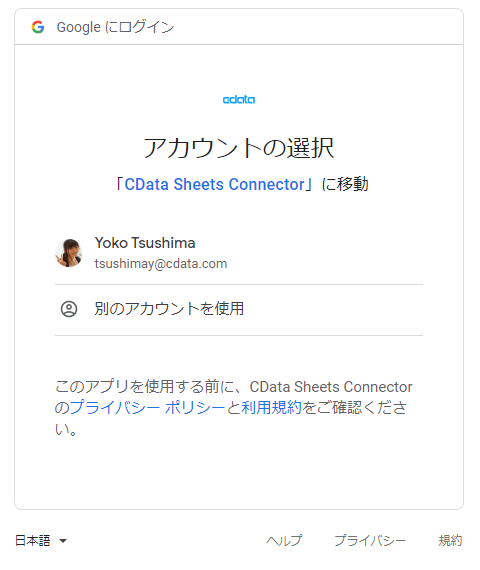
接続するアカウントを選択します。
アクセス権限を付与します。
正常に接続できたことを確認します。
CData Connect Cloud 画面右の「Create & Test」を押下し、接続設定内容を保存します。
2-1-1:PAT の作成
個人用アクセストークンは、Twitter 接続時に発行したものを利用します。
2-2:AWS Glue Studio の設定
CData Connect Cloud で作成したGoogle Sheets への接続を、コネクタ経由でAWS Glue から利用します。
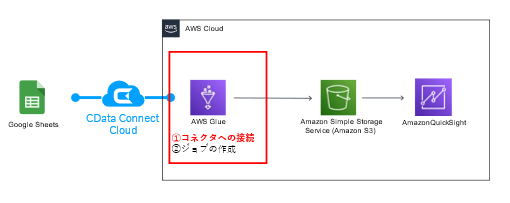
2-2-1:コネクタ追加
AWS Glue の接続設定を作成します。
接続情報を設定します。
AWS Glue の左メニューから「Connectors」を開き、「CData AWS Glue Connector for CData Connect Cloud」を開きます。
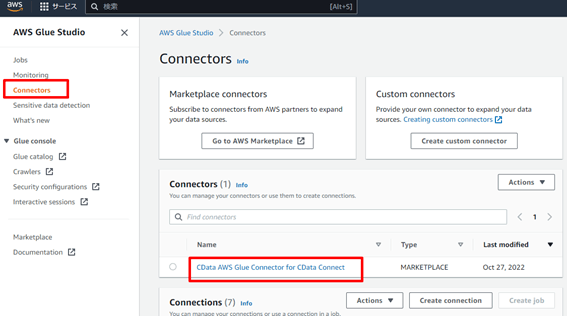
コネクタ画面上部「Create connection」ボタンを押下します。ここからCData AWS Glue コネクタを使った接続を作成できます。
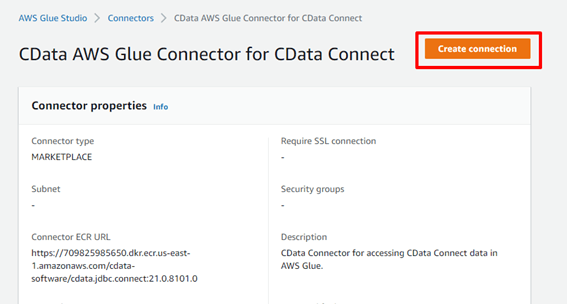
接続作成画面が開かれますので、情報を入力します。
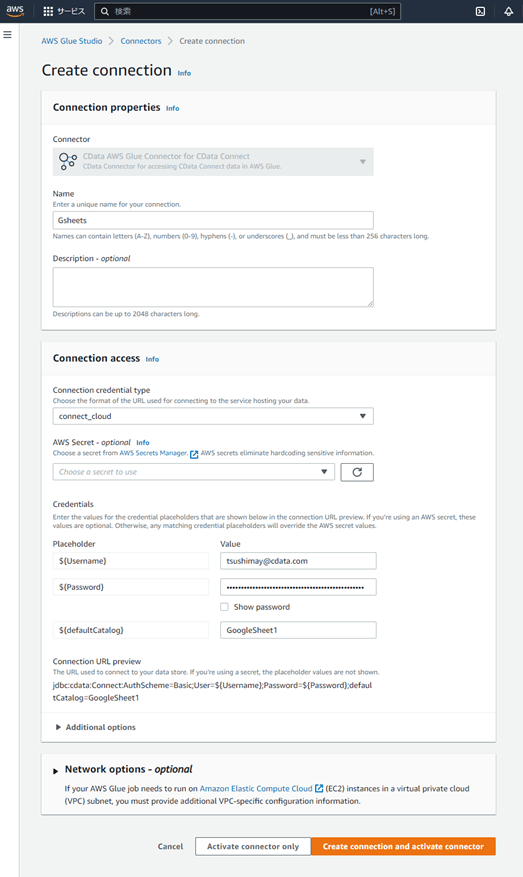
| 大項目 |
設定項目 |
設定内容 |
| Connection properties |
Name |
わかりやすい名前(例:GSheets) |
| Connection access |
Connection credential type |
connect_cloud |
| Credentials |
Username |
CData Connect Cloud ユーザー名(メールアドレス) |
|
Password |
PAT |
|
defaultCatalog |
CData Connect Cloud で作成したGoogle スプレッドシート接続名(GoogleSheets1) |
接続情報を入力したら、「Create connection and activate connector」を押下します。
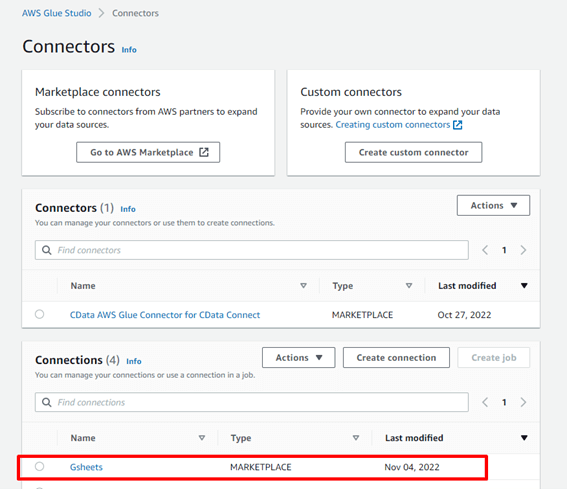
コネクションが追加されます。
2-2-2:ジョブの作成
ETL 処理のジョブを作成します。
左メニューを開き、「jobs」を選択します。
ジョブの作成画面が開かれます。
Create job のSource から「CData AWS Glue Connector for CData Connect Cloud」を選択し、上部「Create」ボタンを押下します。
ジョブ作成画面が開かれます。
それぞれのアイコンの設定をします。
2-2-3:データソース設定
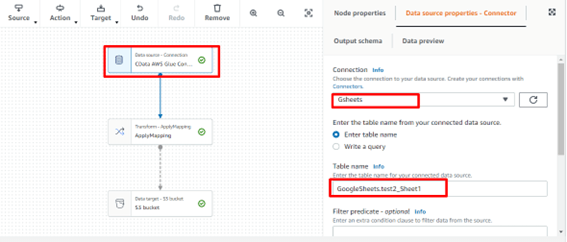
データソースアイコンを選択し、プロパティ画面から設定を行います。
Connection では先ほど作成した接続設定を選択します。
テーブル名は「GoogleSheets.ファイル名_シート名」(例:GoogleSheets.cdranking_cdranking)を指定します。
2-2-4:ターゲット設定
続いてターゲットであるS3 を設定します。
ターゲットアイコンを選択し、プロパティ画面から設定を行います。Format はCSVを選択します。S3 Target Location では作成したS3 を設定します。例:s3://handsontest
2-2-5:ジョブ設定
ジョブの基本設定をします。
| 設定項目 |
設定内容 |
| Name |
わかりやすい名前(例:GSheets2S3) |
| IAM Role |
事前に設定したIAM Role |
| Job bookmark |
Disable |
上記を設定し、Advanced propaties を開きます。
Job parameters でパラメータを追加します。
Key に「--class」、Value に「GlueApp」を手入力で指定します。
設定が終わりましたら、上部の「Save」ボタンで設定内容を保存します。
2-2-6:スキーマ取得
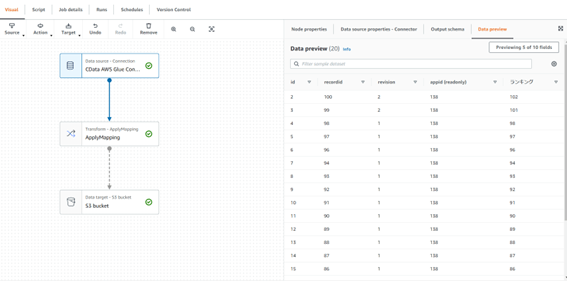
マッピングで利用するスキーマを取得します。データソースアイコンを開き、「Data preview」タブから「Start data preview session」を押下します。
「Confirm」を押下します。
Google スプレットシートのデータをプレビューできます。
「Output schema」タブに移動し、「Use datapreview schema」を押下します。
ジョブの設定は完了です。ジョブを保存し、実行します。
左メニューの「Monitoring」で、実行内容を確認できます。
ジョブの成功が確認できたら、S3 を見てみます。
ファイルが格納されています。
Google スプレットシートのデータがCSV 形式で出力されています。
まとめ
AWS Glue でGoogle スプレッドシートのデータを扱い、S3 にデータ格納するジョブを作成できました。CData Connect Cloud でデータ接続を行うことで、ローコードでの接続先拡張を実現できます。
CData Connect Cloud は30日間の無償トライアルを用意しています。ぜひ体感してください。
https://www.cdata.com/jp/cloud/
関連コンテンツ



