こんにちは。CData Software Japanリードエンジニアの杉本です。
今回はETLツールのASTERIA Warpを利用し、Salesforceで生成されたサポートケースのデータを元にBacklogの課題を自動生成する方法を紹介します。
Backlog とは?
株式会社ヌーラボが提供するチームが協力しながら作業を進めるためのコラボレーション型プロジェクト管理ツールです。企画・マーケティング・総務の各種業務から、製造・開発のプロジェクトまで、様々なタスク管理に活用できます。
backlog.com
Backlog は、外部データ連携の仕組みとしてWeb APIを公開しており、APIを通して、Backlog のデータにアクセスすることが可能です。
developer.nulab.com
ASTERIA Warpとは
ASTERIA Warpは簡単なGUIを用いて作成するフローによって既存のデータベース、ファイルシステム、各種業務システム、各種クラウドサービスと簡単に接続、連携することのできるデータ連携ツールです。
www.asteria.com
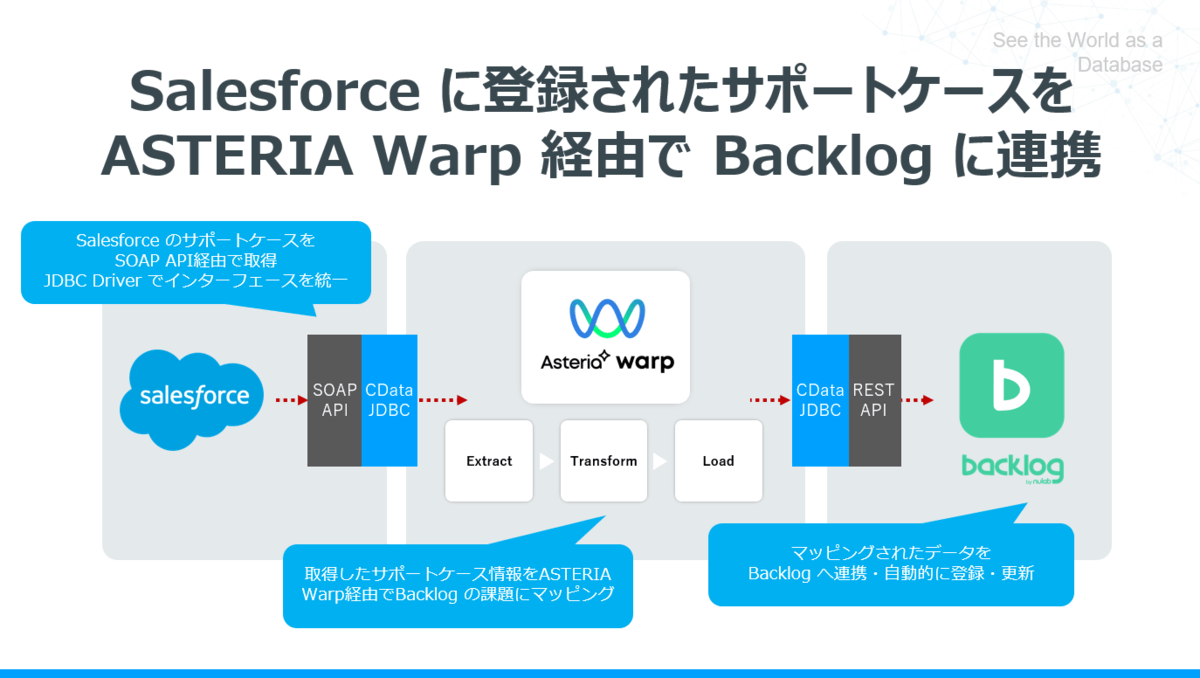
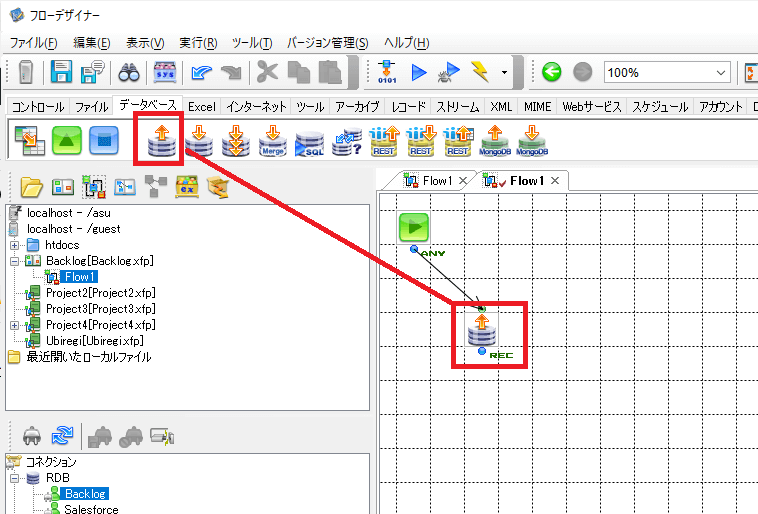
実現イメージ
この記事では Backlog APIに対してETLツールのASTERIA Warpから接続します。しかしながら、各APIは単純にツールと接続・連携することはできません。
各ツールがどのようにWeb API側へリクエストを投げるべきかの判断材料や各種認証方法の処理、メタデータの情報等が無いためです。そのためには基本的にカスタムコネクタを作るか、プログラムを組まなければいけません。
そこで、CData Driver を用いて、このボトルネックを解決します。
まず、各ツール(今回の記事ではASTERIA Warp)からはODBCやJDBCインタフェースでSQL(Select文)をCData API Driverに向けて発行してもらいます。そのリクエストを受け取った CData API Driverは、Backlog の API のエンドポイントに対して、SQL文を解釈し、HTTPリクエスト発行します。
リクエスト後、JSONフォーマットで返ってきたデータをCData Driverが各種インタフェースフォーマットにデータを変換してツールに返します。
これにより、各種ツールからアドホックにSQLによるリクエストがあったタイミングで最新のデータをBacklog API から取得することが可能となります。
今回はこのAPI Driver と ETLツールのASTERIA Warpを組み合わせて、Salesforce のサポートケースを自動的にBacklog に登録するフローを作成してみました。
出来上がりイメージは以下のようになります。
手順
Backlog のAPIKey取得
Backlogへの接続にはAPIKeyを利用します。APIKeyの取得方法は以下の記事をご参照ください。
www.cdatablog.jp
CData JDBC Driverのインストール
次に、CData Driverの準備を行います。以下のダウンロードページからAPI、 SQL Server のJDBC Driver インストーラをそれぞれダウンロードしてください。
ダウンロードしたフォルダの中にあるsetup.jarをダブルクリックするとインストーラが起動しますので、それぞれウィザードに従ってインストールを行ってください。
コネクションの追加
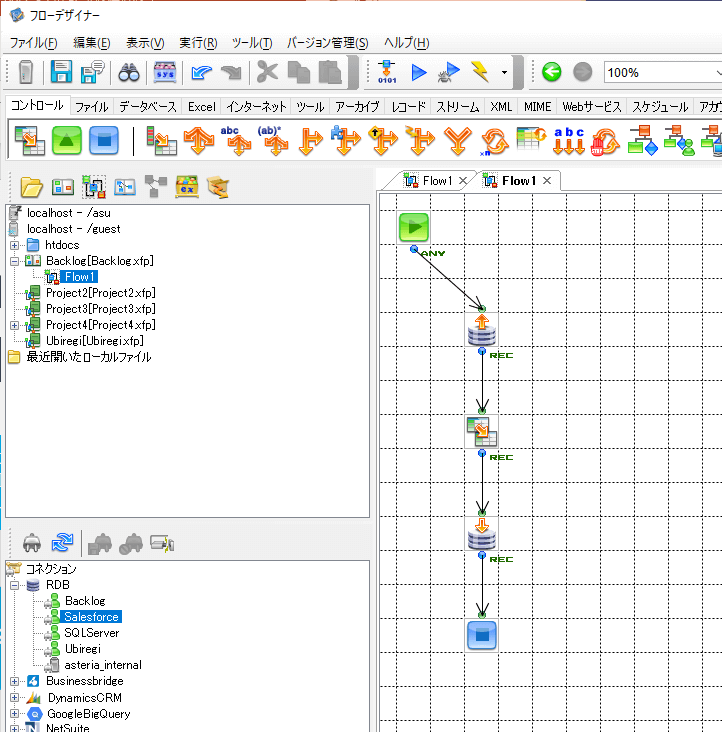
それでは、ASTERIA Warpでの操作を進めていきましょう。
ASTERIA Warpでは、フローデザイナーを使って、データ処理のプロセスを作成します。
フローデザイナーの基本的な利用方法についてはWarpのフローデザイナー操作ガイドをご覧ください。
まずASTERIA WarpでCData JDBC Driverを使用するために接続を追加します。
ここではBacklog Driver へのコネクションの作成方法を紹介しますが、Salesforce についても同様の手順でコネクションを作成します。
画面左のコネクションペイン上にある電源ボタンをクリックをクリックすると、「コネクションの作成」ダイアログが表示されます。
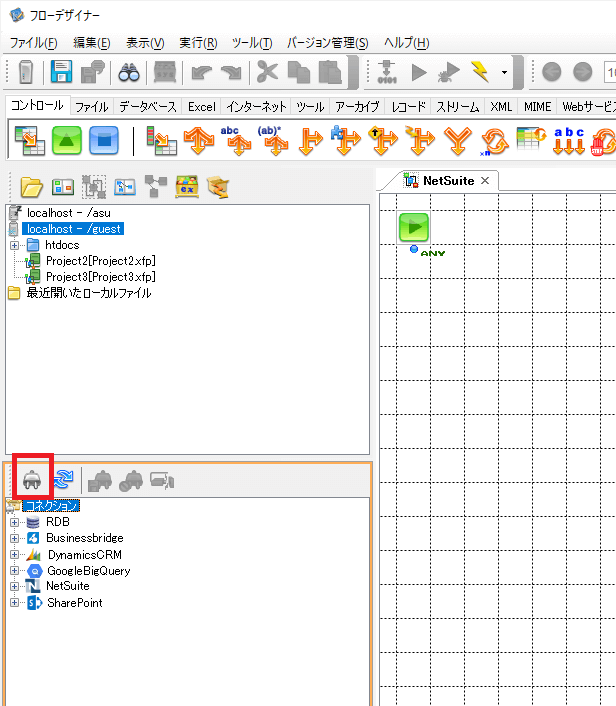
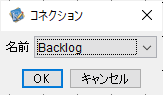
「接続種別」として「RDB」を選択、「名前」に分かりやすい名前を設定し「OK」をクリックします。
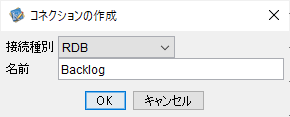
作成したコネクションをダブルクリックすると、画面右のインスペクタに接続プロパティが表示されます。
「基本」タブでドライバーのパスとURLをそれぞれ設定します。
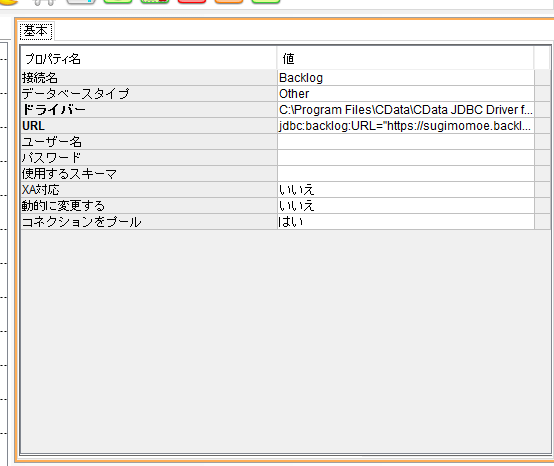
ドライバーのパス
前節でインストールした API JDBC Driverファイルへの参照を指定します。
デフォルトではC:\Program Files\CData\CData JDBC Driver for Backlog 2020J\lib\cdata.jdbc.backlog.jarです。
URL
Backlogに接続するための接続文字列を指定します。
jdbc:backlog:URL=https://XXXXX.backlog.com;ApiKey=XXXXX;
Salesforce の接続情報
Salesforce のコネクションも同様の手順で作成してください。設定情報は以下の通りです。
ドライバーのパス
前節でインストールしたSalesforce JDBC Driverファイルへの参照。
デフォルトではC:\Program Files\CData\CData JDBC Driver for Salesforce 2020J\lib\cdata.jdbc.salesforce.jarです。
URL
Salesforce に接続するための接続文字列を指定します。CData Salesforce JDBC Driverのヘルプ
プロジェクトの作成
コネクションを追加したら、実際にフローを作成していきましょう。
フローデザイナーのメニューから「新規作成」→「プロジェクト」をクリックし
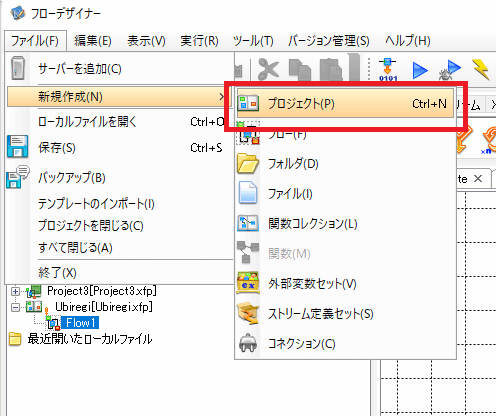
任意の名称で新規フローを作成します。
データの読み込み処理の構成
フローでは、はじめにSalesforce が保持するサポートケースのデータを読み込みます。
データベースタブにある「RDBGet」のコンポーネントをフローに配置し、ダブルクリックします。
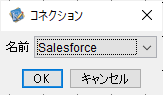
コネクションの選択ウインドウが表示されるので、先程作成したSalesforceのコネクションを選択しましょう。
その後、SQLビルダーが表示されるので、取得したいデータが格納されている、任意のテーブルとカラムを選択します。
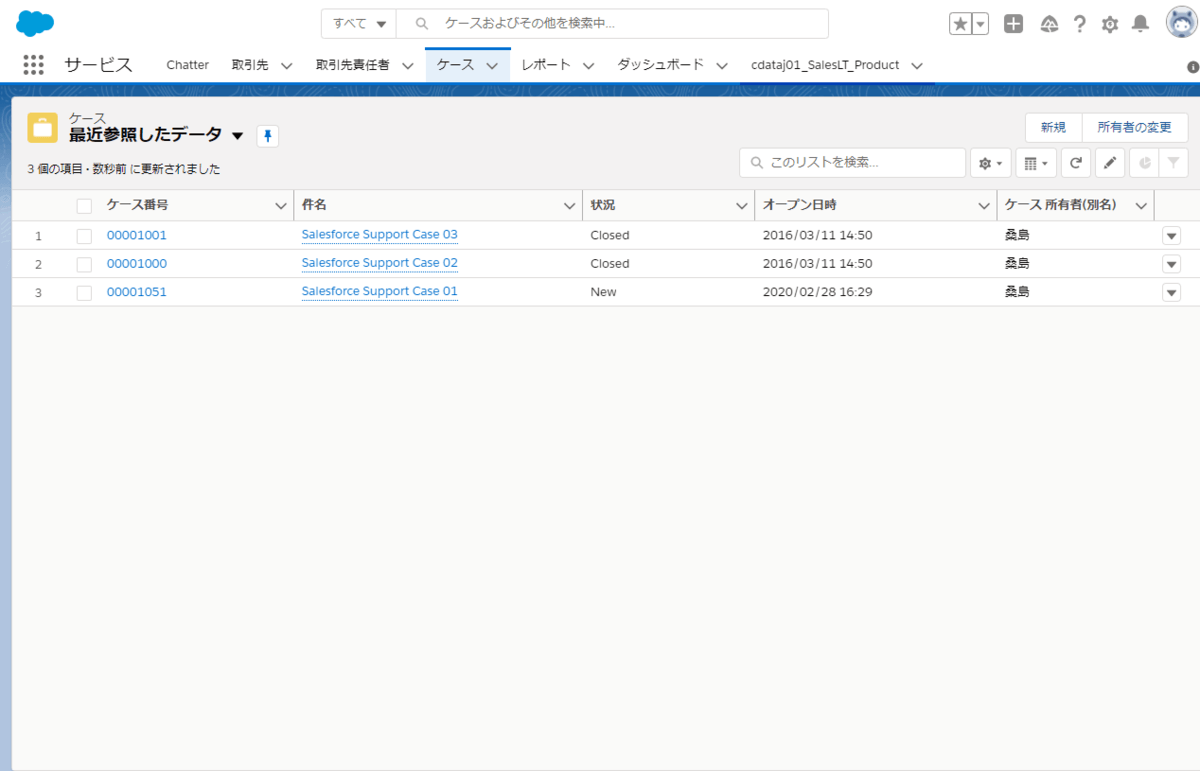
今回はサポートケースのデータを取得できる「Case」テーブルを以下のように選択しました。
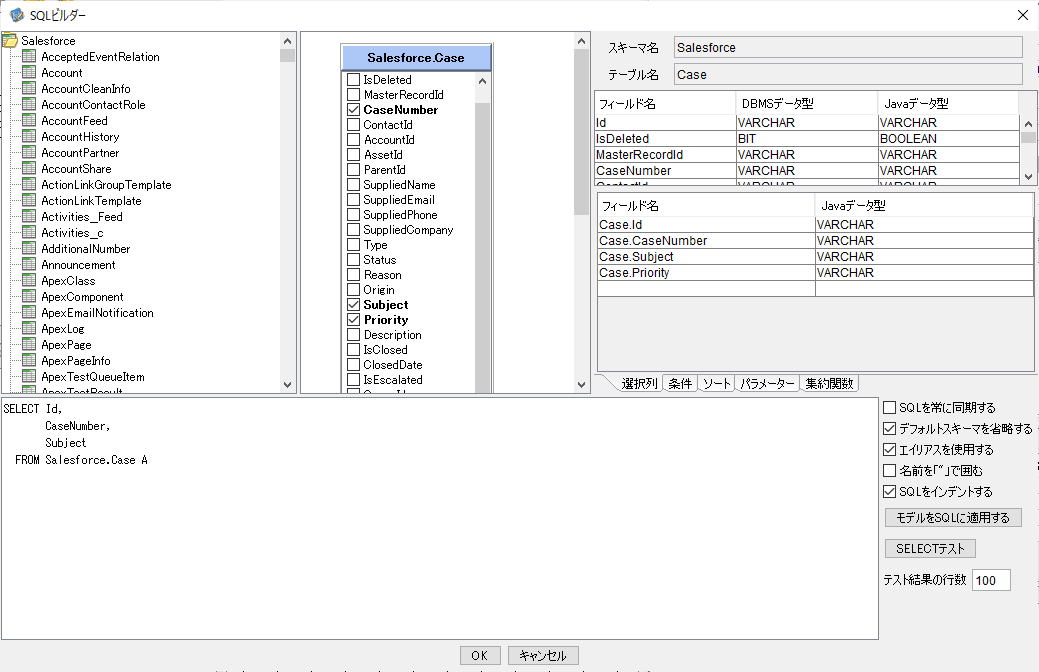
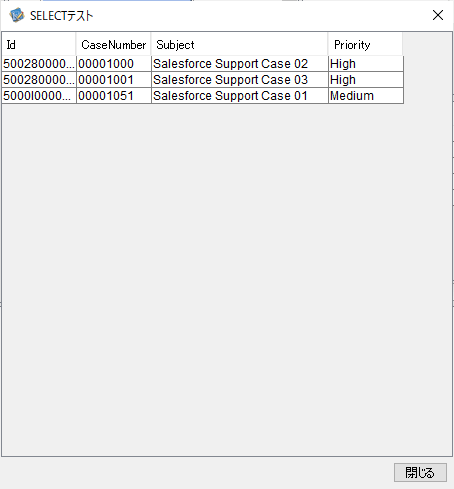
あとは、「モデルにSQLを適用する」をクリックし「SELECTテスト」でデータが正常に取得できているかを確認します。
以下のようにデータが参照できれいればOKです。設定を保存してSQLビルダーを閉じます。
データの追加処理の構成
続いてデータ追加処理部分を構成していきます。
データ追加のコンポーネントは「RDBPut」を使いますが、その前に連携先の項目にデータをマッピングするための「Mapper」コンポーネントを配置しておきましょう。
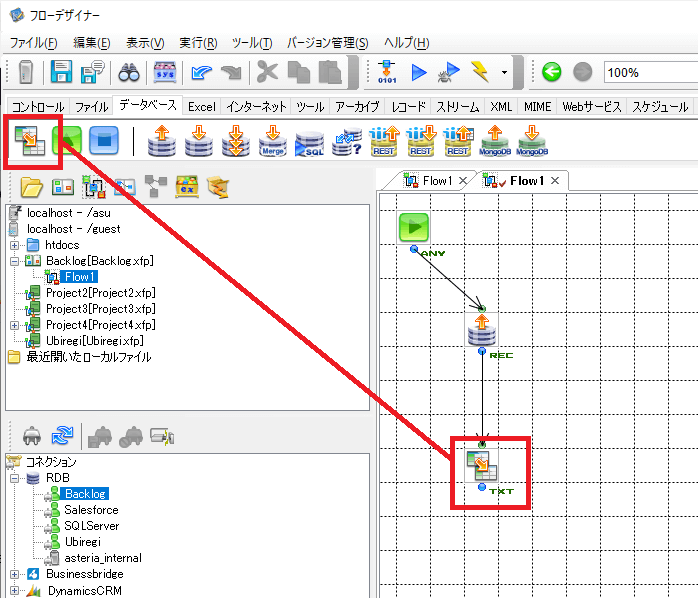
続いて、「RDBPut」を配置してコンポーネントをダブルクリックします。
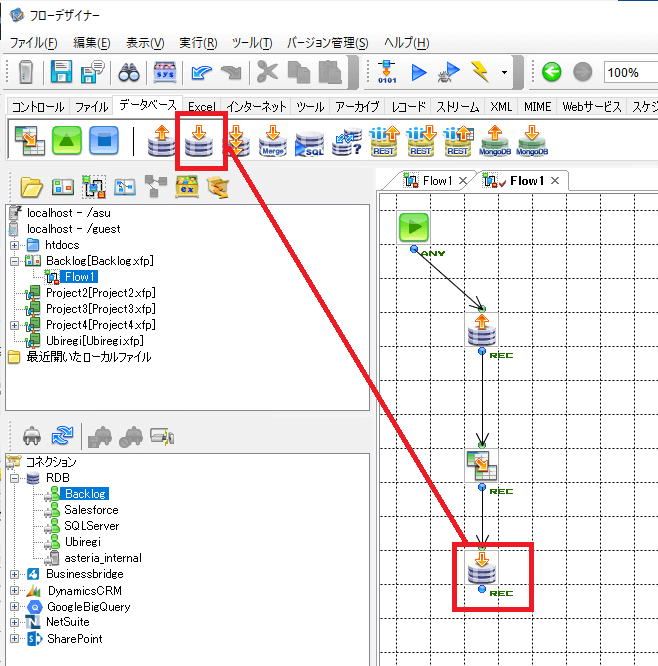
事前に構成していたBacklog コネクションを選択します。
コネクション選択後、データ追加を行う対象のテーブルとフィールドの設定画面が表示されるので、追加先となる任意のテーブルとカラムを指定します。
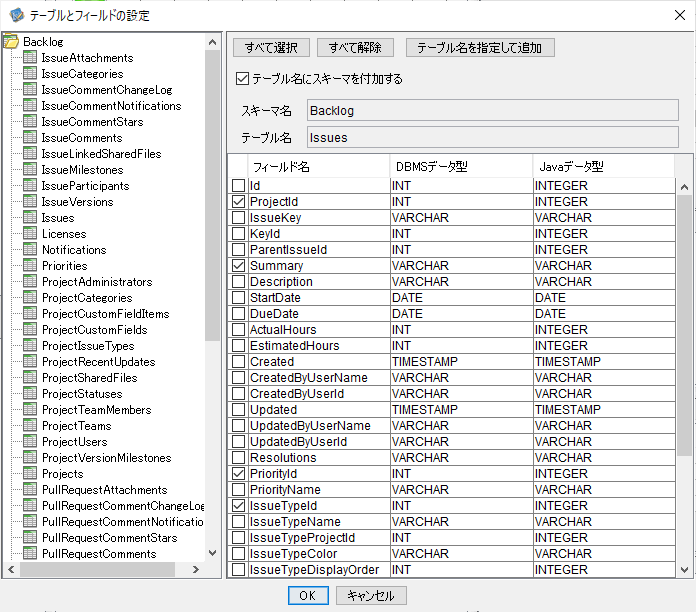
マッピングの構成
追加先テーブルとフィールドの設定が完了したら、最後にMapperを編集します。
ただ、マッピングを行う前に注意しなければいけないことは、Backlogの必須項目をSalesforceが持っていない点です。例えば、課題を登録するためにProjectIdやIssueTypeIdなどが必須となりますが、Salesforce側ではその識別子を持っていません。
そのため、今回はあらかじめフロー変数に静的な値として下記のように値を保持しました。
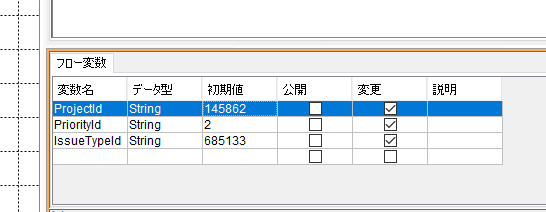
変数の準備が整ったら、Mapperの編集画面を開きましょう。
以下のように各項目のマッピング画面が表示されるので、取得元から追加先に対して、項目を合わせます。
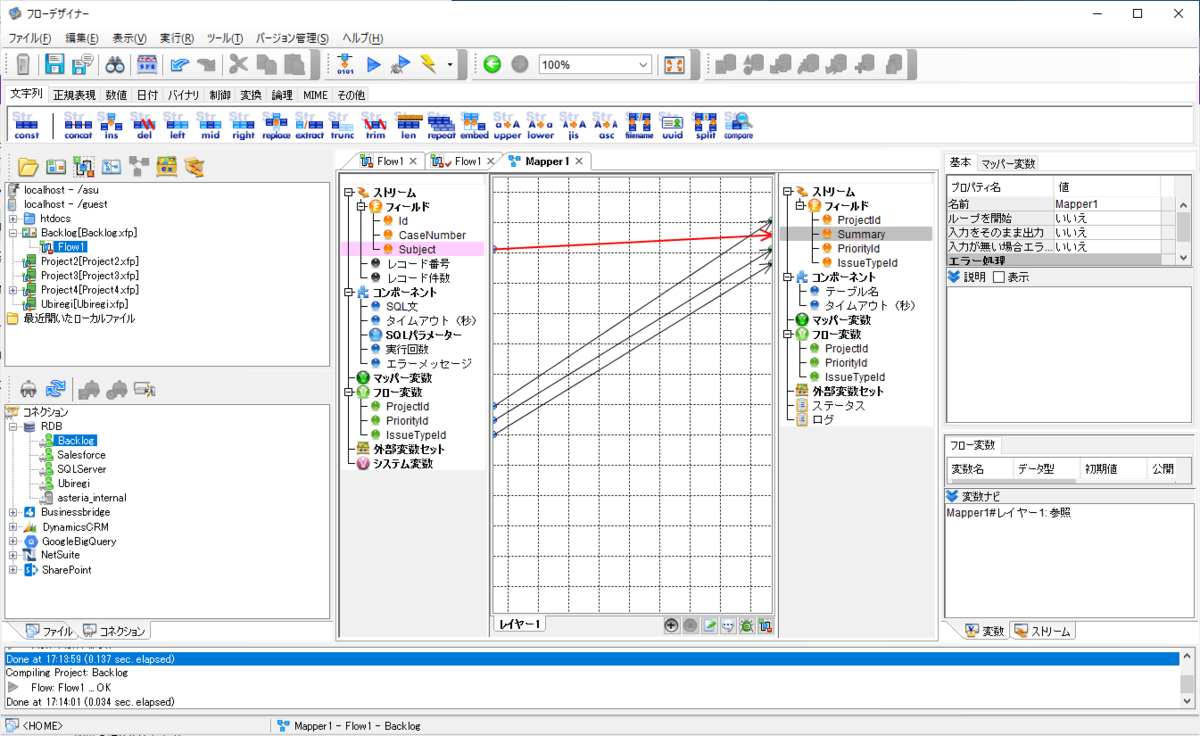
あとは、フローを終了するためのコンポーネントを配置すれば、フローの完成です。
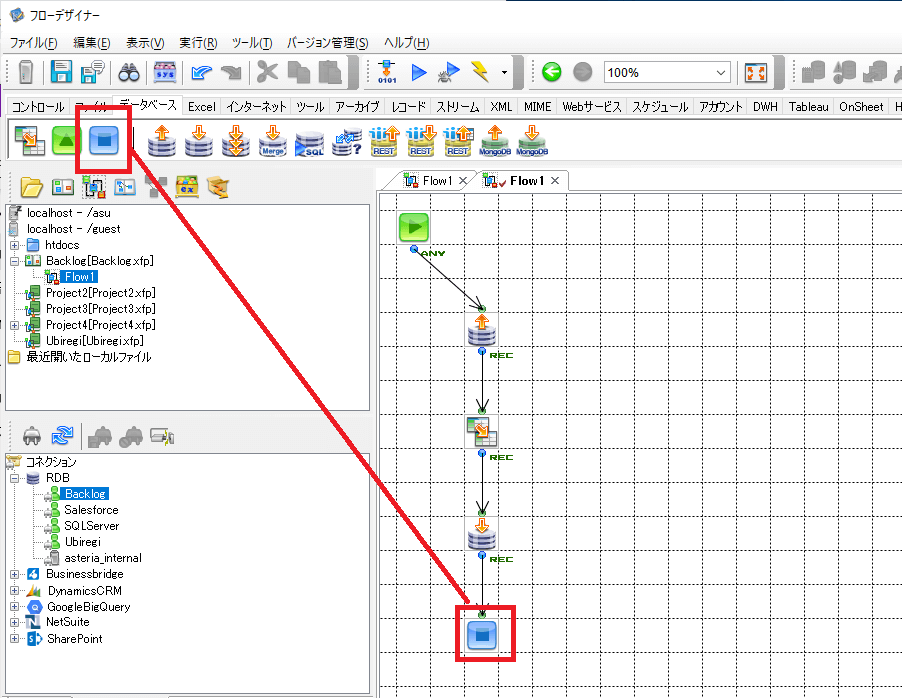
実行
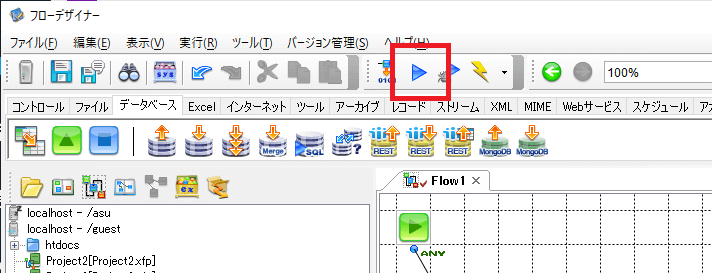
それでは実際にフローを動かしてみましょう。
画面上の「実行」ボタンから、フローを実行できます。
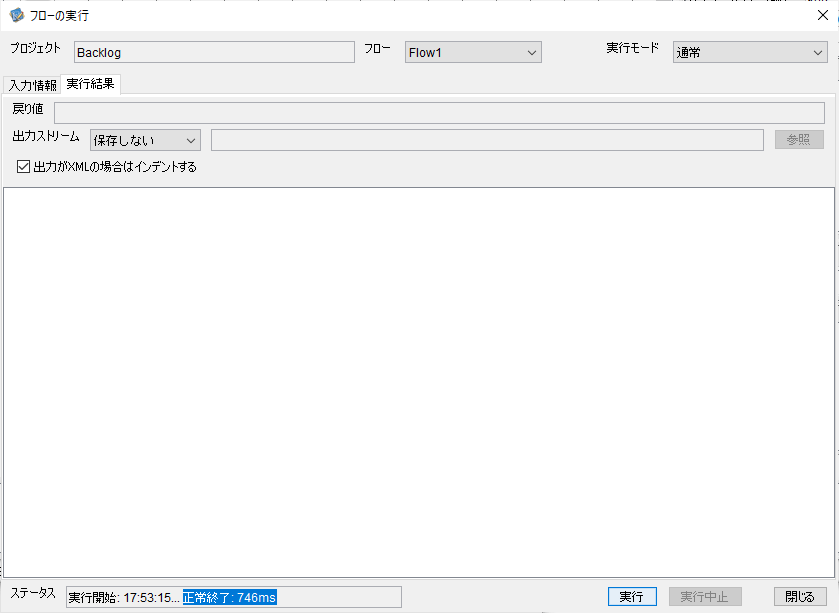
実行後、以下のようにステータスに「正常終了」と表示されれば完了です。
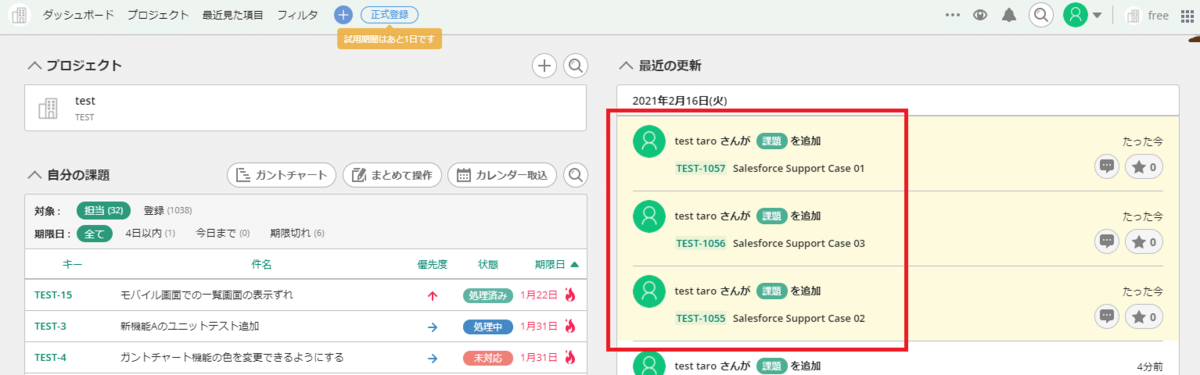
実際にBacklogを確認してみると、以下のように新しく課題が作成されていました。
おわりに
今回はASTERIA WarpとCData JDBC Driverを用いてSalesforce のデータをBacklogに連携する方法を紹介しました。
Salesforce 以外にも、CData JDBC Driver・ASTERIA Warpを利用することで、Backlog と200を超えるクラウドサービスとのデータ連携がノーコードで実現できます。

是非自社で利用しているサービスに合わせて、連携を実現してみてください。
関連コンテンツ



