CData Architecture: Supporting Multiple Technologies
In my previous post, I described how we use several factors to evaluate the complexity of building a driver for a new data source. Today, I would like to give you a glimpse of our driver architecture.
Let's start with a high-level overview:
At the top of the diagram below are technologies we support, referred to as the driver front-end interfaces. These adapt our driver model to each different driver/technology interface.
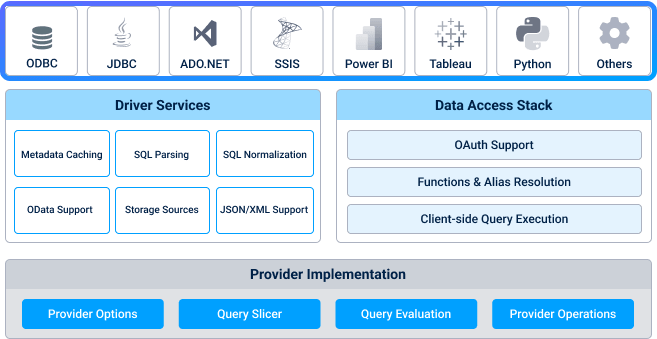
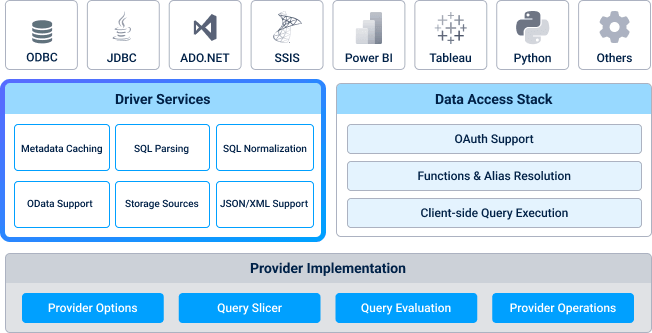
In the middle, we have our core driver code, which is divided into two big categories. The first one is made up of the driver support services, which apply functionality that’s commonly used across many CData Drivers. We will dive into some of these further in this post.
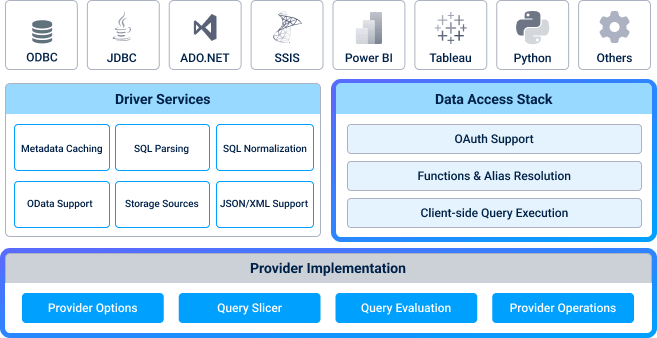
The second part of the driver core is the data access stack, which is a vital part of our architecture. This allows us to extend the driver core by adding layers above and below throughout the execution of most queries.
Finally, at the bottom, we have the provider-specific code, which includes implementations for some of the extensibility points in the layers above that attach the driver-specific code to the query execution pipeline. This includes a driver-specific implementation of the data access stack.
Front-End Technologies
The driver front-end interface is the data access technology. This is the layer that the user or application interacts with that will be exposed by the driver. Each front-end technology is implemented in two parts:
- Core implementation shared by all drivers: This contains all the data source-agnostic code and is implemented as an internal framework on which data source-specific code plugs in. For example, our CData JDBC Drivers include base implementations of core JDBC concepts such as
Statement or ResultSet.
- Data source-specific implementation of the interface: This part is accomplished entirely through automatic code generation and is extremely flexible.
This last part is a key ingredient of our technology stack, allowing us to support new editions or new technologies in our drivers quickly.
A brief overview of how this works:
- For each data source, we define key metadata using declarative language. This includes basic information such as:
- Driver name, description, and other descriptive metadata
- All the supported connection properties and associated documentation
- Editions (front-end technologies) that are supported by this data source
- Data source supported operations and syntaxes, such as INSERT/UPDATE/DELETE, bulk operations, server-side JOIN support, and SQL syntaxes
- This is generated from the metadata at build time:
- All driver-specific code for each supported edition
- All HTML documentation for the product
- Installers and installation scripts
This layer provides tremendous flexibility and simplifies the development process. Let’s examine how.
For each data source, we can choose which front-end technology we want to support. For example, it might not make sense to publish a Microsoft Power BI connector for a given data source, so we might choose to publish only traditional data access providers for it.
We can easily define standard configuration options or connection properties once and reuse them across many drivers. This makes it easy to build a consistent interface and expected behavior across all of them. For example, almost every one of our drivers has connection-level properties for configuring firewall and proxy server properties. We define these just once in a central location, ensuring consistent definitions and documentation across all drivers.
If we want to introduce a new connection property or option in a driver, we can declare it once and have it available across all supported editions and technologies without extra work. At the same time, we can still define edition-specific options or hide them as necessary to simplify the configuration
When creating a new CData Driver, the technology-specific frameworks and the data source-specific code are connected through common interfaces, allowing us to offer a provider in one of our supported technologies. If there is a bug in our technology-specific implementation or in a new feature we want to offer, we only need to adjust it once by updating our code-generation templates, which then resolves the issue across our entire driver lineup.
This model also makes us uniquely positioned to target new platforms and offer drivers across new technologies faster than before, because we build the necessary support code and templates only once and deploy them across our entire data source portfolio.
Conclusion
Our framework is based on code generation at the front end and allows us to build native drivers that support different driver/adapter technologies through a flexible and extensible model that makes it easy to support new ones.
This architecture allows us to create CData Drivers that function consistently across technologies, with updates and improvements being supported across the board.
In the next post in this series, we will cover some of the core driver services in our framework.



