各製品の資料を入手。
詳細はこちら →Apache Spark ODBC Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへ製品の詳細
Apache Spark ODBC Driver は、ODBC 接続をサポートするさまざまなアプリケーションからApache Spark データへの接続を実現するパワフルなツールです。
標準SQL とSpark SQL をマッピングして、SQL-92 で直接Apache Spark にアクセス。
こんにちは!ドライバー周りのヘルプドキュメントを担当している古川です。
この記事では、CData ODBC Driver for SparkSQL をTIBCO Spotfire で使う方法を説明します。データインポートウィザードを使ってのDSN(データソース名)に接続し、サンプルビジュアライゼーション上でビルドして簡単なダッシュボードを作成します。
CData ODBC ドライバは、以下のような特徴を持ったリアルタイムデータ連携ソリューションです。
CData ODBC ドライバでは、1.データソースとしてSpark の接続を設定、2.TIBCO Spotfire 側でODBC Driver との接続を設定、という2つのステップだけでデータソースに接続できます。以下に具体的な設定手順を説明します。
まずは、本記事右側のサイドバーからSparkSQL ODBC Driver の無償トライアルをダウンロード・インストールしてください。30日間無償で、製品版の全機能が使用できます。
Microsoft ODBC データソースアドミニストレーターで必要なプロパティを設定する方法は、ヘルプドキュメントの「はじめに」をご参照ください。
SparkSQL への接続を確立するには以下を指定します。
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
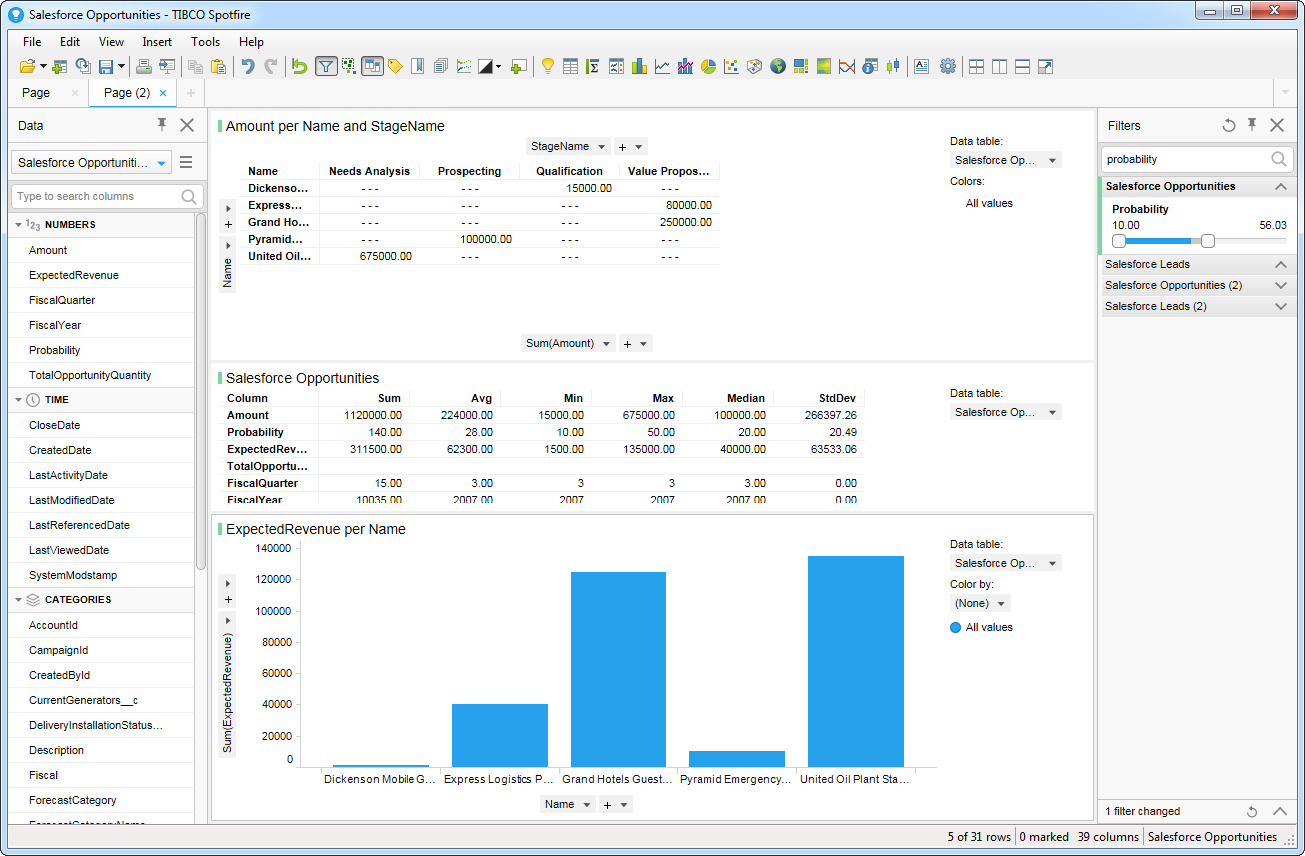
データをメモリにロードしてローカルで処理したい場合は、[Import Data Table]オプションをクリックします。このオプションは、オフラインでの使用、またはスローなネットワーク接続によりダッシュボードがインタラクティブでない場合に使用します。
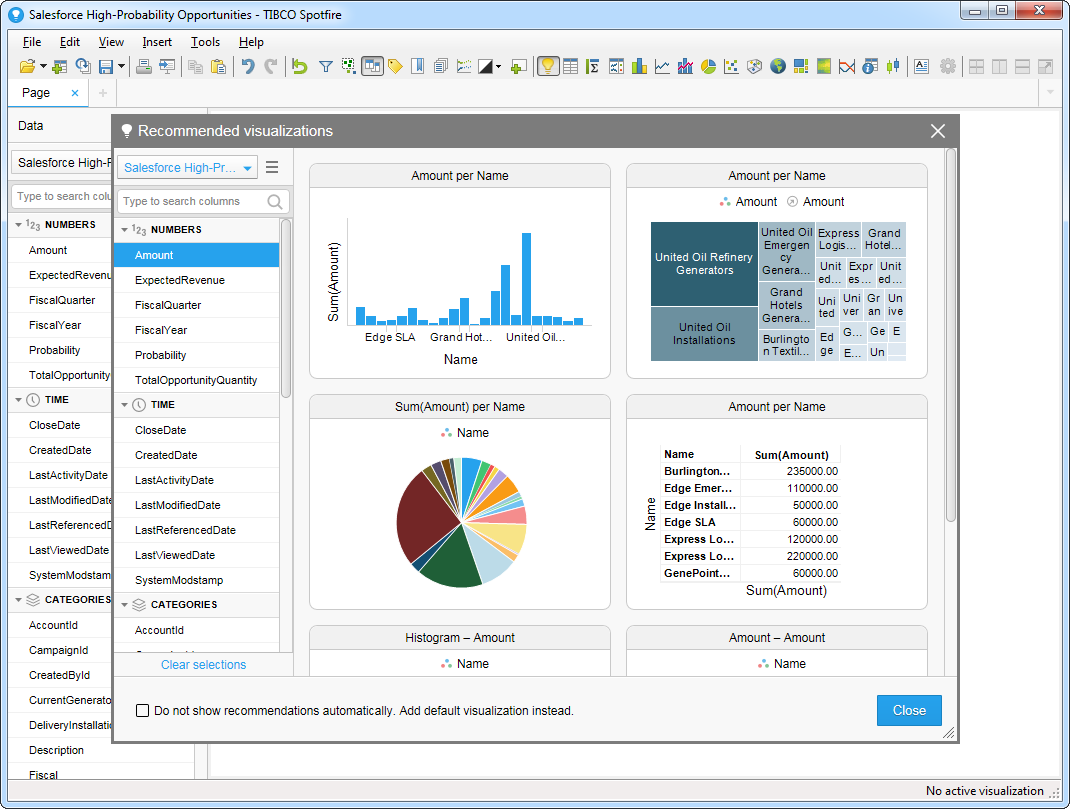
[Recommended Visualizations]ウィザードでいくつかビジュアライズしたら、ダッシュボードにその他の修正を加えられます。例えば、ページにフィルタを適用することで、高確率なopportunities にズームインできます。フィルタを追加するには、[Filter]ボタンをクリックします。各クエリで利用可能なフィルタは、[Filters]ペインに表示されます。
このようにCData ODBC ドライバと併用することで、270を超えるSaaS、NoSQL データをコーディングなしで扱うことができます。30日の無償評価版が利用できますので、ぜひ自社で使っているクラウドサービスやNoSQL と合わせて活用してみてください。
CData ODBC ドライバは日本のユーザー向けに、UI の日本語化、ドキュメントの日本語化、日本語でのテクニカルサポートを提供しています。