こんにちは!ドライバー周りのヘルプドキュメントを担当している古川です。
CData ODBC Driver の特徴の一つは、多くのアプリケーションを幅広くサポートしている点です。この記事では、FileMaker Pro でODBC ドライバーを設定してSpark を使ってデータビジュアライゼーションを作成します。
FileMaker とSpark のデータを連携する3つの方法
FileMaker からSpark と連携するには大きく3つの方法があります。本記事では①の方法を解説しますが、②や③の方法を解説する記事も用意していますので、必要に応じて参照してください。
- ODBC インポート機能を活用:本記事で解説する方法です。ODBC プロトコルを活用してFileMaker にデータを取り込みます。最も簡単な方法ですが、データに変更があった場合に全件再取り込みが必要になります。定期的にデータを更新する場合には、②の方法がベターです。
- スクリプト機能を活用:FileMaker に搭載されているスクリプト機能を活用することで、初回だけ全件データを取り込み、その後は変更のあったデータだけを取り込む差分更新でデータを更新できます。詳しくはこちらの記事をご確認ください。
- ESS(External SQL Source)機能を活用:ESS はFileMaker から外部データソースにリアルタイム接続できる機能です。接続設定は少し面倒ですが、ESS ではリアルタイム接続が可能なので、データ変更をすぐに反映したい、という場合にはベストな方法です。詳しくはこちらの記事をご確認ください。
CData ODBC ドライバとは?
CData ODBC ドライバは、以下のような特徴を持ったリアルタイムデータ連携ソリューションです。
- Spark をはじめとする、CRM、MA、会計ツールなど多様なカテゴリの270種類以上のSaaS / オンプレミスデータソースに対応
- 多様なアプリケーション、ツールにSpark データを連携
- ノーコードでの手軽な接続設定
- 標準 SQL での柔軟なデータ読み込み・書き込み
CData ODBC ドライバでは、1.データソースとしてSpark の接続を設定、2.FileMaker Pro 側でODBC Driver との接続を設定、という2つのステップだけでデータソースに接続できます。以下に具体的な設定手順を説明します。
CData ODBC ドライバのインストールとSpark への接続設定
まずは、本記事右側のサイドバーからSparkSQL ODBC Driver の無償トライアルをダウンロード・インストールしてください。30日間無償で、製品版の全機能が使用できます。
接続プロパティが未設定の場合は、まずODBC DSN(データソース名)で設定します。これはドライバーのインストールの最後の手順です。Microsoft ODBC データソースアドミニストレーターを使ってODBC DSN を作成および設定できます。
Microsoft ODBC データソースアドミニストレーターで必要なプロパティを設定する方法は、ヘルプドキュメントの「はじめに」をご参照ください。
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、
「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
これで、Filemaker Pro のテーブルにSpark をロードできます。
-
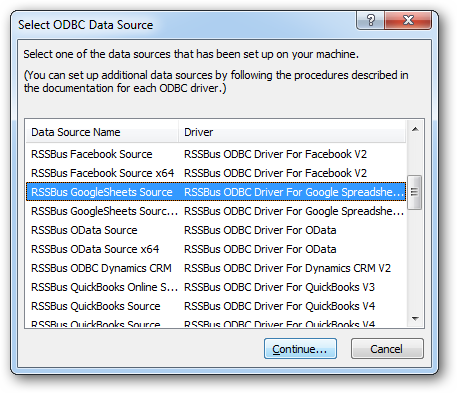
新しいデータベースで[File]→[Import Records]→[Data Source]をクリックし、CData Spark DSN を選択します。
![CData ODBC Data Sources to be added to a FileMaker Pro database.]()
-
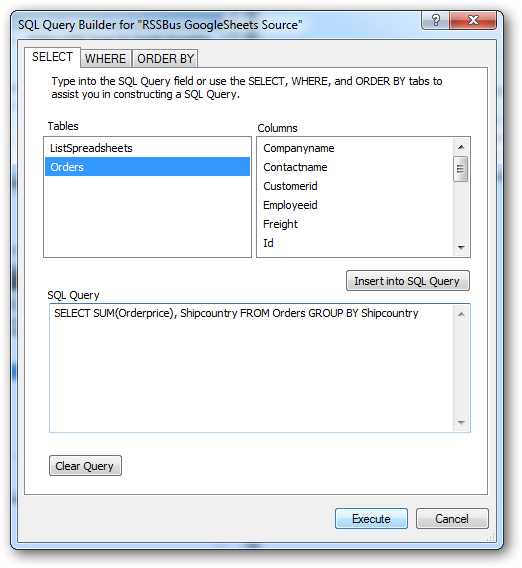
[SQL Query Builder]ウィザードが表示されたら、テーブルと列を選択して[Insert into SQL Query]をクリックします。このクエリは直接編集できます。テーブルからすべての行を選択するには、次のクエリを使います。
SELECT * FROM Customers
UI を使いWHERE タブをクリックすることで、WHERE 句にフィルタをビルドできます。
![The import query defined in the SQL Query Builder. (Google Spreadsheets is shown.)]()
-
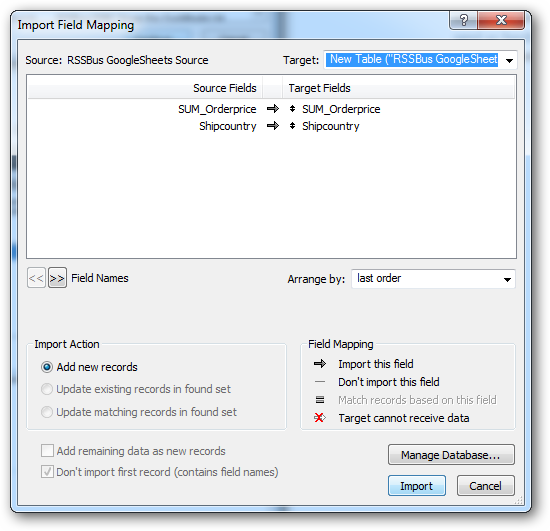
[Import Field Mapping]ウィザードが表示されたら、データソースの列からデスティネーションテーブルの列にマッピングを定義できます。クエリ結果に新しいテーブルを作成するには、[Target]ボックスから[New Table ("CData SparkSQL Source")]を選択し[Import]をクリックします。
![Mappings for a new table. (Google Spreadsheets is shown.)]()
ドライバーがサポートするSQL の詳細は、ヘルプドキュメントを参照してください。
デザイン時のデータ処理
テーブルをブラウズしながら、summary 関数の計算のみならずデータのソートや集計ができます。デザイン時にデータのビューを操作するには、まず以下2つの手順を行います。
- ブラウズモードに切り替える:アプリケーションのフッターにある[Mode]ポップアップメニューをクリックします。
- テーブルビューに切り替える:アプリケーションのメインツールバーにある[View As]メニューのテーブルアイコンをクリックします。
集計とサマライズ
下記の手順に従って、下図のように列の値をグループ化してサマリーを表示します。
- Sort:City 列を右クリックして[Sort Ascending]をクリックします。
- Group:City 列を右クリックし、[Add Trailing Group by City ]をクリックして値をグループ化し、その後にsummary 計算が挿入される行を作成します。[Add Leading Group]をクリックしてグループにサマリーを加えます。
- Summarize:グループ化された列を右クリックして[Trailing Subtotals]メニューからサマリーを選択します。
下図は、グループ内の行数およびランニングカウントを表します。
![Available data processing options in the Browse view. (Google Spreadsheets is shown.)]()
レポートにチャートを追加
下記の手順に従って、各City の全Balance を示す簡単な棒グラフを作成します。
- Balance を右クリックし[Chart by Balance]をクリックします。[Table]ビューで列をグループ化済みの場合、例えばCity は、City でBalance をチャートするオプションを選択できます。
- [Chart Setup]ウィンドウでチャートを描画する列を選択:x 軸に列を追加するには、[Data]ボックスの隣のボタンをクリックします。
x 軸とy 軸を選択するとチャートが描かれます。[Chart Setup]でもデータの処理が可能です。次のオプションを設定すると下図のチャートを作成できます。
- y 軸の合計を計算:[Data]ボックスとなりのy 軸のボタンをクリックして[Specify Calculation]を選択します。それからSUM 関数と、例えばcolumn、Shipcountry を選択します。
- [Summary]メニューでy 軸のサマリーを選択します。
- [Axis Options]セクションでチャートをカスタマイズ:'Show data points on chart' オプションを有効にするか、ラベルの角度を指定します。
![Up-to-date values in the Chart Setup dialog. (Google Spreadsheets is shown.)]()
おわりに
このようにCData ODBC ドライバと併用することで、270を超えるSaaS、NoSQL データをコーディングなしで扱うことができます。30日の無償評価版が利用できますので、ぜひ自社で使っているクラウドサービスやNoSQL と合わせて活用してみてください。
CData ODBC ドライバは日本のユーザー向けに、UI の日本語化、ドキュメントの日本語化、日本語でのテクニカルサポートを提供しています。