各製品の資料を入手。
詳細はこちら →Apache Spark ODBC Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへ製品の詳細
Apache Spark ODBC Driver は、ODBC 接続をサポートするさまざまなアプリケーションからApache Spark データへの接続を実現するパワフルなツールです。
標準SQL とSpark SQL をマッピングして、SQL-92 で直接Apache Spark にアクセス。
CData


こんにちは!ドライバー周りのヘルプドキュメントを担当している古川です。
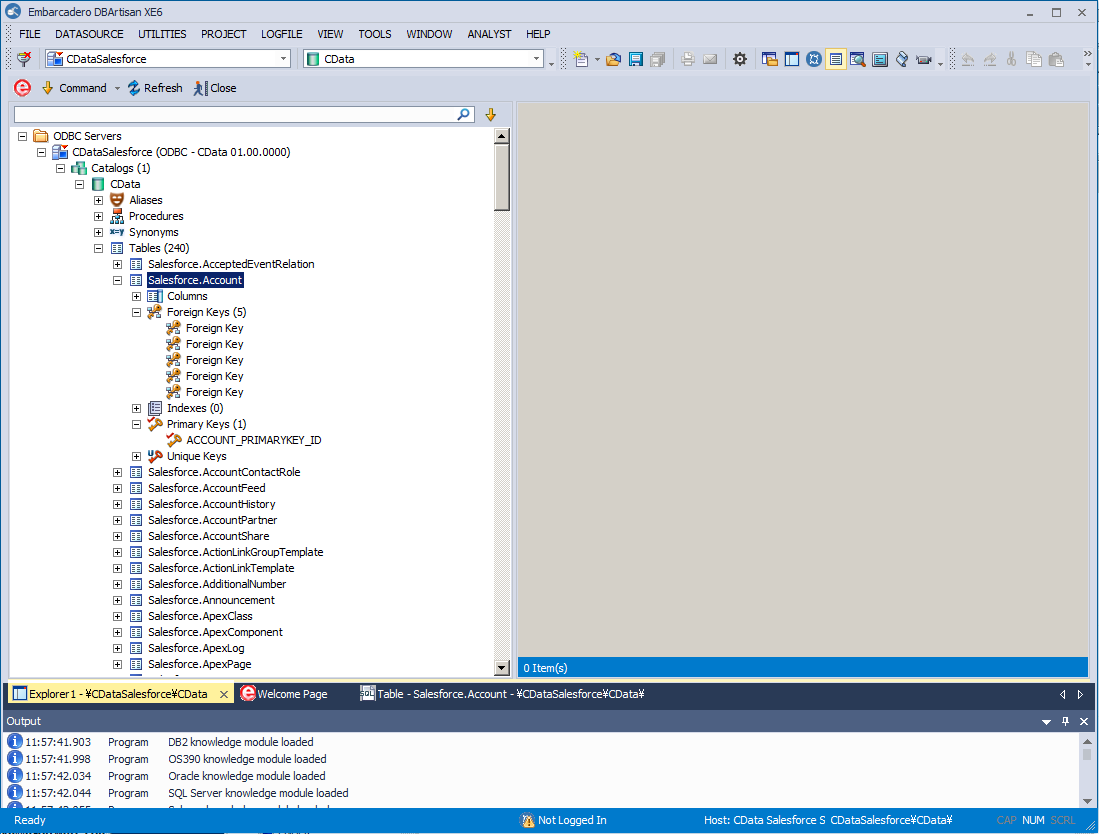
CData ODBC Driver for SparkSQL は、DBArtisan などのデータベースツールとSpark データ を連携し、RDB のような感覚でSpark データを扱えます。 本記事では、DBArtisan 上でSpark データソースを作成する方法とクエリの実行方法を説明します。
CData ODBC ドライバは、以下のような特徴を持ったリアルタイムデータ連携ソリューションです。
CData ODBC ドライバでは、1.データソースとしてSpark の接続を設定、2.DBArtisan 側でODBC Driver との接続を設定、という2つのステップだけでデータソースに接続できます。以下に具体的な設定手順を説明します。
まずは、本記事右側のサイドバーからSparkSQL ODBC Driver の無償トライアルをダウンロード・インストールしてください。30日間無償で、製品版の全機能が使用できます。
インストール後にDSN 設定画面が開くので、Spark への接続に必要なプロパティを設定します。
SparkSQL への接続を確立するには以下を指定します。
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
次の方法で、プロジェクトにSpark データソースを登録します。
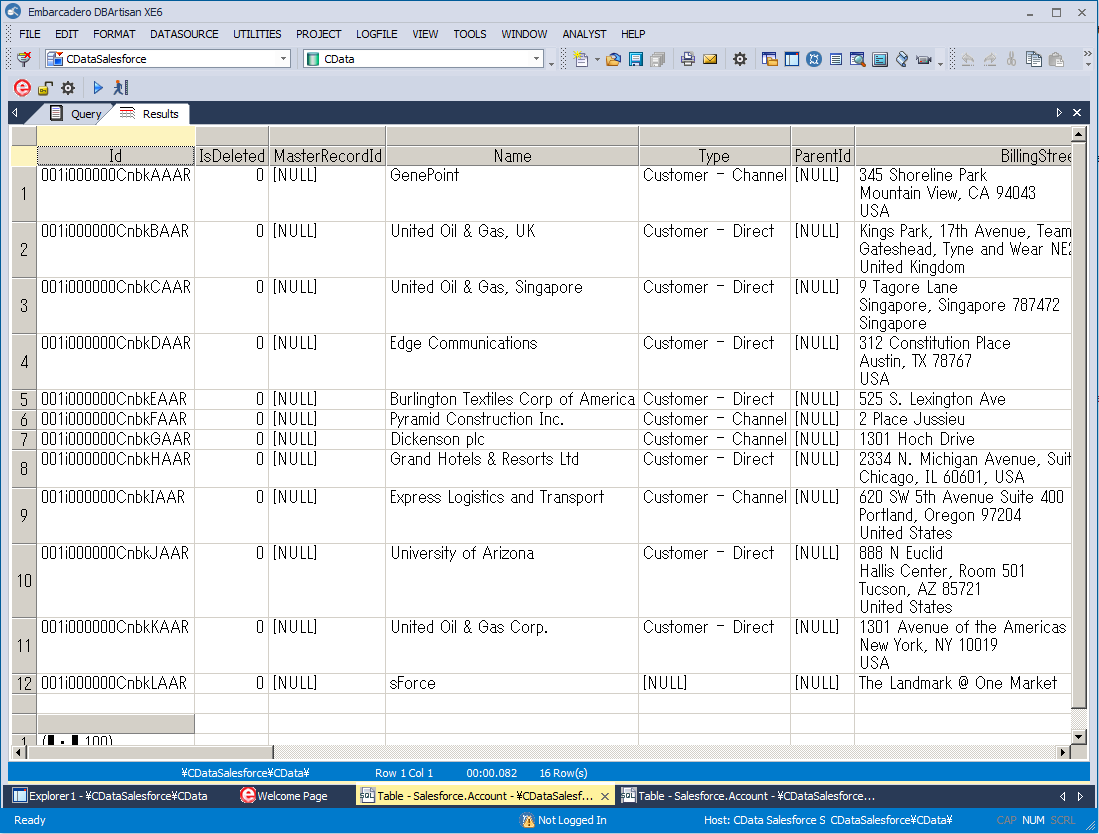
これで、他のデータベースと同じようにSpark データを扱うことが可能になります。 サポートされるSQL クエリは、ドライバーのヘルプドキュメントを参照してください。
このようにCData ODBC ドライバと併用することで、270を超えるSaaS、NoSQL データをコーディングなしで扱うことができます。30日の無償評価版が利用できますので、ぜひ自社で使っているクラウドサービスやNoSQL と合わせて活用してみてください。
CData ODBC ドライバは日本のユーザー向けに、UI の日本語化、ドキュメントの日本語化、日本語でのテクニカルサポートを提供しています。