各製品の資料を入手。
詳細はこちら →Apache Spark ODBC Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへ製品の詳細
Apache Spark ODBC Driver は、ODBC 接続をサポートするさまざまなアプリケーションからApache Spark データへの接続を実現するパワフルなツールです。
標準SQL とSpark SQL をマッピングして、SQL-92 で直接Apache Spark にアクセス。
CData


こんにちは!ドライバー周りのヘルプドキュメントを担当している兵藤です。
SQL 開発ツールといえば「A5:SQL Mk-2」が有名です。Windows ODBC に強い!というイメージです。多くのエンジニアやIT 担当者に利用されています。 本記事では、Spark データをCData ODBC ドライバを使って、A5:SQL MK-2 からクエリする方法を説明します。
CData ODBC ドライバは、以下のような特徴を持った製品です。
CData ODBC ドライバでは、1.データソースとしてSpark の接続を設定、2.A5:SQL Mk-2 側でODBC Driver との接続を設定、という2つのステップだけでデータソースに接続できます。以下に具体的な設定手順を説明します。
まずは、本記事右側のサイドバーからSparkSQL ODBC Driver の無償トライアルをダウンロード・インストールしてください。30日間無償で、製品版の全機能が使用できます。
ODBC ドライバーのインストール完了時にODBC DSN 設定画面が立ち上がります。または、Microsoft ODBC データソースアドミニストレーターを使ってDSN を作成および設定できます。
SparkSQL への接続を確立するには以下を指定します。
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
「データベース」→「データベースの追加と削除」を開きます。
「64bit ODBCシステムデータソースを列挙する」にチェックを入れます。システムデータソースを利用するか、ユーザーデータソースを利用するかはどちらでもかまいません。
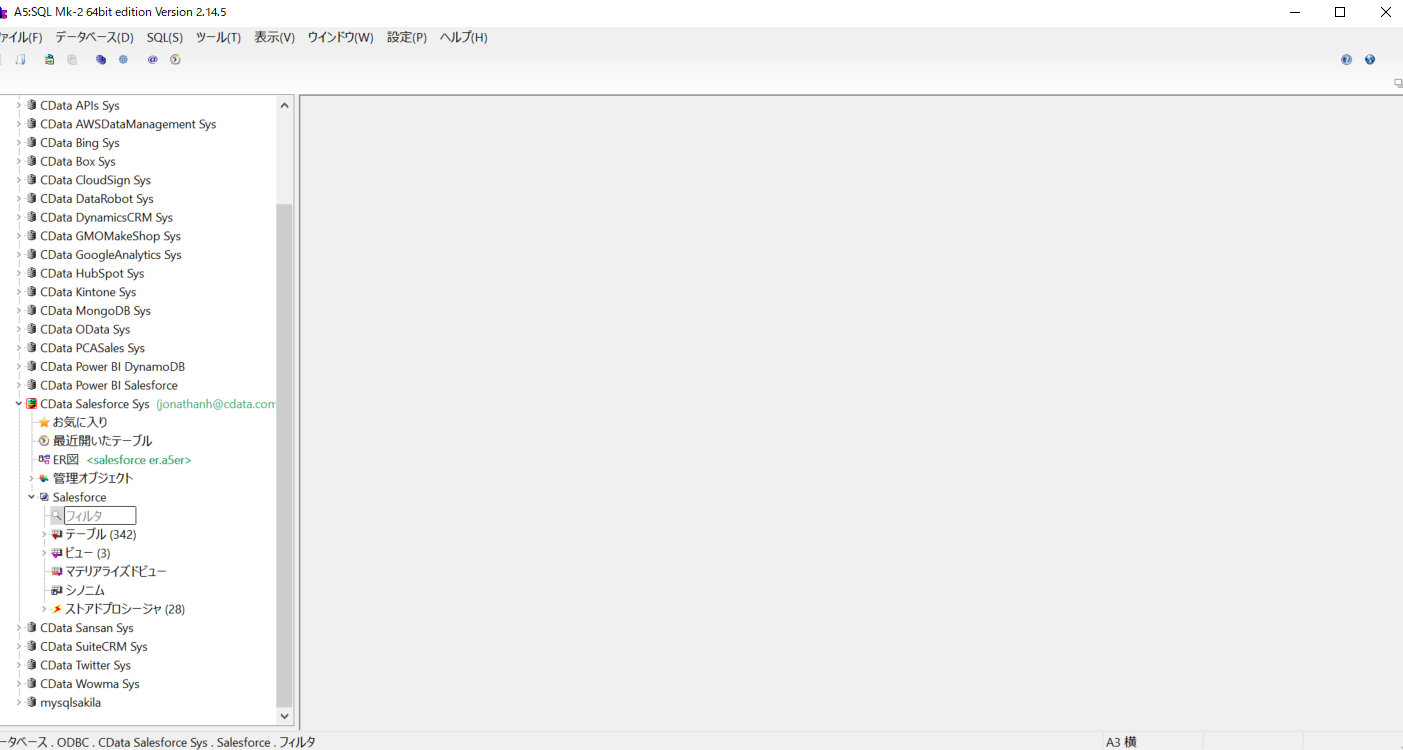
データベースとして、設定しているODBC DSN がツリービューで表示されます。CData ODBC ドライバで設定されたDSN もここに表示されます。
「CData Spark Sys」をダブルクリップします。データベースログイン画面が開くので、ODBC DSN 設定時に使ったSpark のユーザーとパスワードでログインします。
Spark のオブジェクトがテーブル・ビュー・ストアドプロシージャにモデル化されて表示されます。
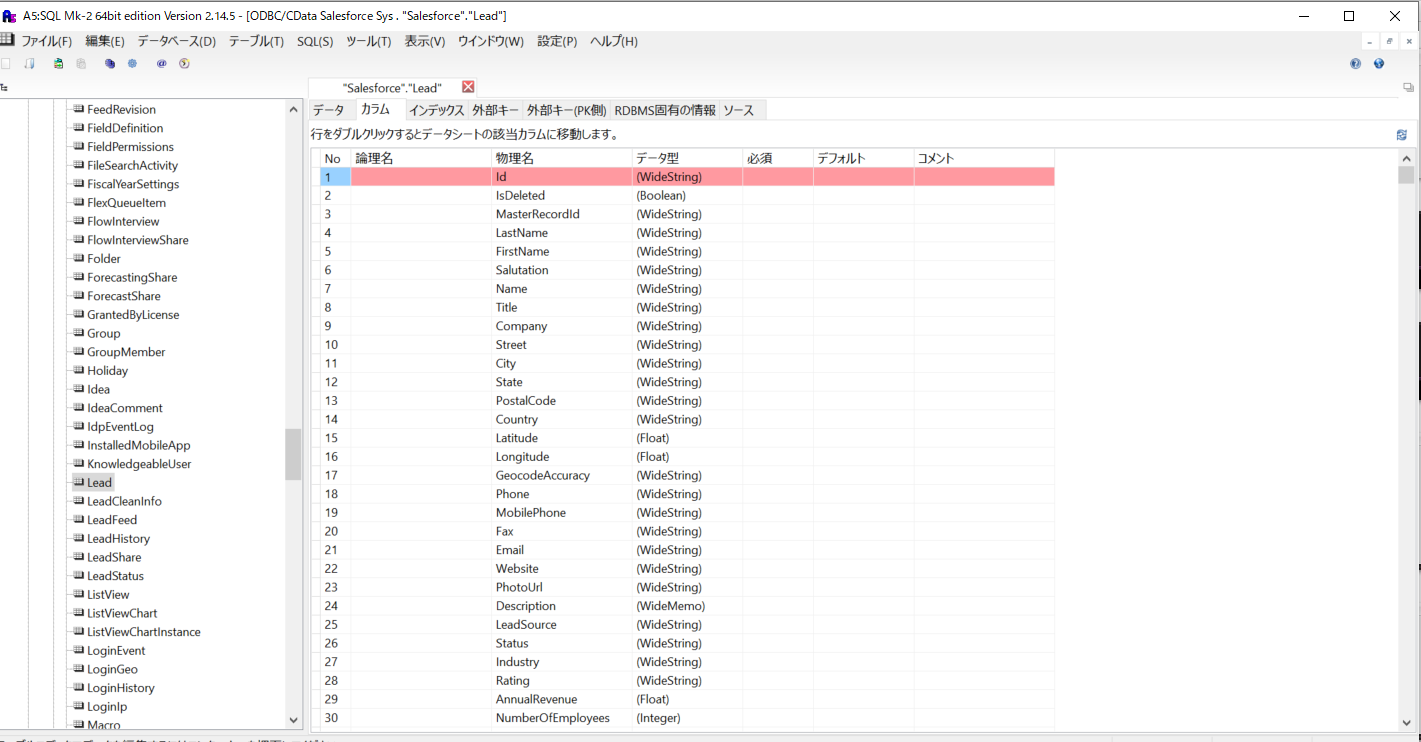
テーブルを開いてみます。オブジェクトで利用できるデータがカラムとしてモデル化されています。それぞれのカラムにはデータ型の情報も付いています。
これでA5:SQL Mk2 でSpark データがクエリできます。
対象のテーブル・ビューを右クリックして「SQL の作成」をクリックしてクエリ作成画面を開きます。
SELECT にチェックを入れます。とりあえず全カラムを指定して条件なしでクエリしてみます。
SQL クエリがA5M2 から生成されます。実行ボタンで実行するとSpark の選択したオブジェクトがクエリされ、データがテーブルとして返されます。
次にフィルタリング条件を付けてみます。SQL の作成画面で「絞り込み条件に利用するカラム」をドロップダウンから選択します。以下の絞り込み条件付きのSQL 文がA5M2から生成されるので、WHERE 句に条件を書いて実行します。
--*DataTitle "Spark"."(テーブル名)"
--*CaptionFromComment
SELECT
"Id" -- Id
, "LastName" -- LastName
, "FirstName" -- FirstName
, "Name" -- Name
, "Title" -- Title
, "Company" -- Company
, "Status" -- Status
, "Industry" -- Industry
FROM
"SparkSQL"."Lead"
WHERE
"Company" = '(フィルタリング条件を入力)'
同じ要領でSQL 作成UI から、SELECT だけでなく、INSERT、UPDATE、DELETE のクエリが作成できます。JOIN や集計クエリもANSI-92 のSQL で作れます。
このようにCData ODBC ドライバと併用することで、270を超えるSaaS、NoSQL データをA5:SQL Mk-2 からコーディングなしで扱うことができます。30日の無償評価版が利用できますので、ぜひ自社で使っているクラウドサービスやNoSQL と合わせて活用してみてください。
日本のユーザー向けにCData ODBC ドライバは、UI の日本語化、ドキュメントの日本語化、日本語でのテクニカルサポートを提供しています。