Pentaho Report Designer にSpark データに連携して分析
Pentaho BI ツールでSpark のレポートを作成。
加藤龍彦
デジタルマーケティング
最終更新日:2022-03-16
CData

こんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
CData JDBC Driver for SparkSQL はダッシュボードや帳票ツールからリアルタイムSpark データへの連携を可能にします。この記事では、Spark をJDBC データソースとして接続する方法と、Pentaho でSpark を元に帳票を作成する方法を説明します。
接続と帳票の作成
- インストールディレクトリの[lib]サブフォルダ内のJAR ファイルをコピーし、Pentaho のディレクトリ内の\Report-Designer\lib\jdbc\ フォルダに配置します。
- \Report-Designer\ フォルダのreport-designer.bat ファイルを起動し、Report-Designer UI を開きます。
以下の手順でドライバーを新しいデータソースに設定します。[Data]>[Add Data Source]>[Advanced]>[JDBC (Custom)]とクリックし、新しいSpark 接続を作成します。ダイアログが表示されたら、次のように接続プロパティを設定します。
Custom Connection URL property:JDBC URL を入力。初めに以下を入力し jdbc:sparksql: 次にセミコロン区切りで接続プロパティを入力します。
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、
「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
以下は一般的なJDBC URL です:
jdbc:sparksql:Server=127.0.0.1;
- Custom Driver Class Name:cdata.jdbc.sparksql.SparkSQLDriver と入力。
- User Name:認証するユーザーネーム。
- Password:認証するパスワード。
![Required connection properties defined in the JDBC URL. (Salesforce is shown.)]()
レポートに Spark データを追加
これで、Spark の帳票を作成する準備が整いました。
-
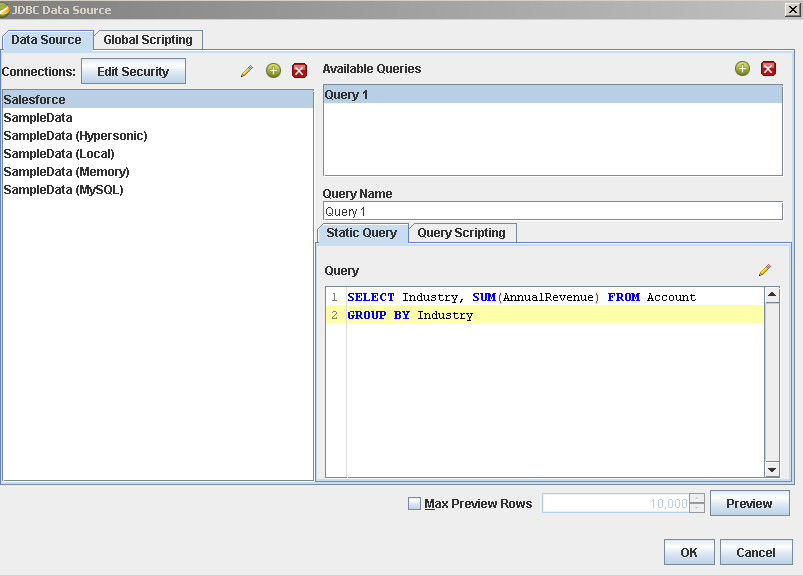
帳票にSpark データソースを追加します:[Data]>[Add Data Source]>[JDBC]をクリックし、データソースを選択します。
クエリを設定します。この記事では次を使います:
SELECT City, Balance FROM Customers
![The query to retrieve data, specified in the JDBC data source configuration wizard. (Salesforce is shown.)]()
- 帳票にチャートをドラッグし、ダブルクリックしてチャートを編集します。帳票を実行して、チャートを表示します。このクエリ結果を使って、Customers テーブルのシンプルなチャートを作成することができます。
- 帳票を実行して、チャートを見てみましょう。
![A chart generated from up-to-date data. (Salesforce is shown.)]()
関連コンテンツ