各製品の資料を入手。
詳細はこちら →Apache Spark Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへCData


こんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
CData JDBC Driver for SparkSQL を使用することで、JDBC データソースとしてSpark にアクセスでき、IDE の迅速な開発ツールとの統合が可能になります。この記事では、データソース構成ウィザードを使用してIntelliJ のSpark に接続する方法を示します。
以下のステップに従ってドライバーJAR を追加し、Spark への接続に必要な接続プロパティを定義します。
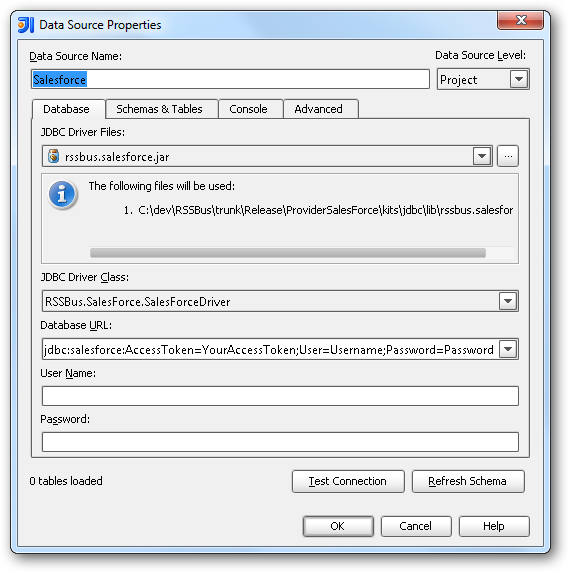
表示される[Data Source Properties]ダイアログでは、次のプロパティが必要です。
Database URL:JDBC URL プロパティで接続URL を入力します。URL は、jdbc:sparksql: で始まり、セミコロンで区切られた接続プロパティが含まれています。
SparkSQL への接続を確立するには以下を指定します。
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
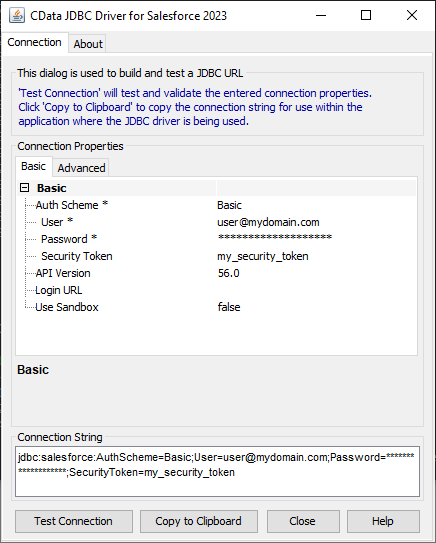
JDBC URL の構成については、Spark JDBC Driver に組み込まれている接続文字列デザイナを使用してください。JAR ファイルのダブルクリック、またはコマンドラインからJAR ファイルを実行します。
java -jar cdata.jdbc.sparksql.jar
接続プロパティを入力し、接続文字列をクリップボードにコピーします。
以下は一般的なJDBC URL です。
jdbc:sparksql:Server=127.0.0.1;
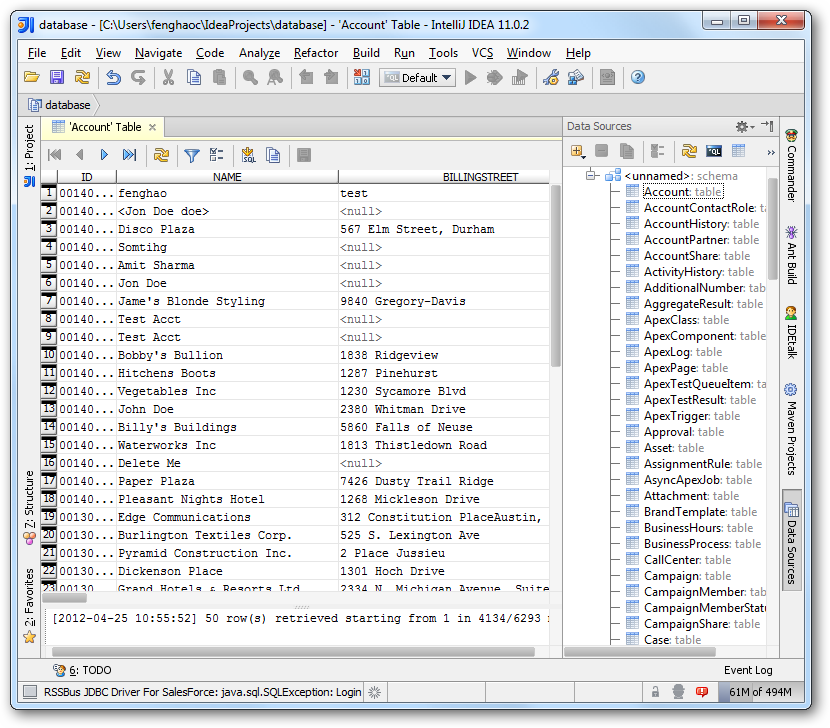
スキーマ情報を見つけるには、作成したデータソースを右クリックし、[Refresh Tables]をクリックします。 テーブルを右クリックし、[Open Tables Editor]をクリックして、テーブルをクエリします。 また、[Table Editor]でレコードを編集することもできます。