各製品の資料を入手。
詳細はこちら →Excel Add-In for Apache Spark の30日間無償トライアルをダウンロード
30日間の無償トライアルへ製品の詳細
Apache Spark Excel Add-In は、Microsoft Excel からApache Spark 連携を実現するパワフルなツールです。
標準SQL とSpark SQL をマッピングして、SQL-92 で直接Apache Spark にアクセス。大量データのインポート / エクスポート / 更新、データクレンジングおよび重複削除、Excel でのデータ分析などに最適です!
CData


こんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
CData Excel Add-In for SparkSQL を使えば、Excel から直接Spark のデータ取得、追加、編集が可能になります。Spark のデータを一度Excel にエクスポートして編集・データソースの一括更新を行えるだけではなく、Excel スプレッドシートに保存されているデータを一括でSpark にインポートすることも可能です。
この記事ではExcel Add-In の使い方を説明し、実際にSpark データを取得、追加、編集していきます。記事の例ではCustomers テーブルを使いますが、同じことがCData Excel Add-In で取得できるすべてのSpark データのテーブルに対して実行可能です。
まずは、本記事右側のサイドバーからSparkSQL Excel Add-In の無償トライアルをダウンロード・インストールしてください。30日間無償で、製品版の全機能が使用できます。
Spark への接続には、Excel Add-in をインストールした後にExcel を起動して、「CData」タブ ->「データの取得」->「取得元:Spark」とクリックしていきます。
接続エディタが表示されるので、接続プロパティを入力して「接続テスト」をクリックしてください。プロパティの取得方法について説明します。
SparkSQL への接続を確立するには以下を指定します。
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
接続設定が完了したら、いよいよSpark のデータを取得してみましょう。
これで、データの取得は完了です。ここからはデータ追加をやっていきましょう。今回は、CustomersSample という別シートにあるデータをSpark に追加していく、というシナリオで進めていきます。
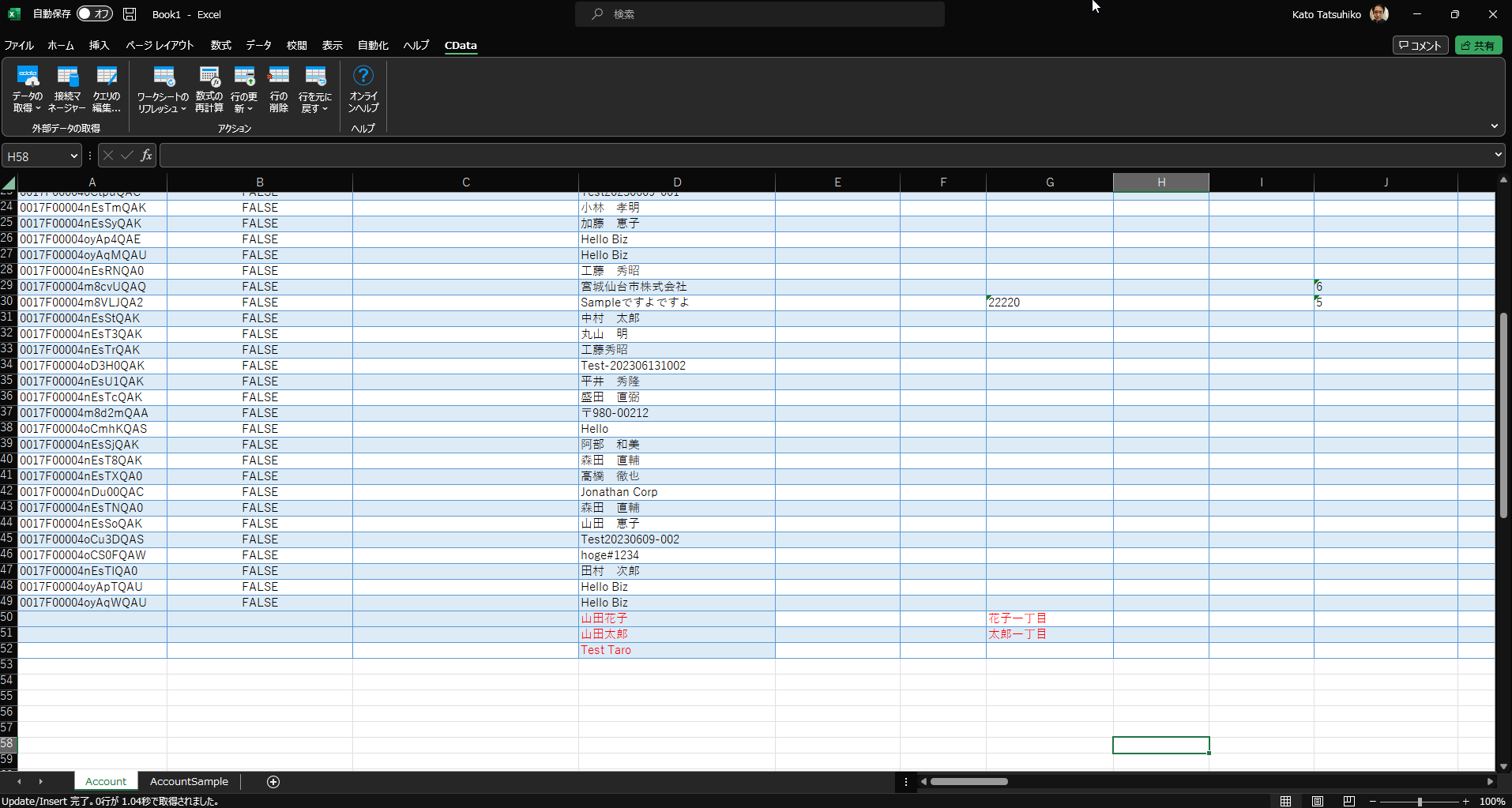
各行の追加が完了すると、追加した値の文字が赤から黒に変わります。もしエラーなく処理が完了しても文字の色が変わらなければ、「ワークアウトのリフレッシュ」を試してみてください。
追加と類似の方法でデータを更新できます。シートに取得したデータを編集すると赤文字になるので、あとは行の更新を実行するだけです。
このようにCData Excel Add-In と併用することで、270を超えるSaaS、NoSQL データをExcel からコーディングなしで扱うことができます。30日の無償評価版が利用できますので、ぜひ自社で使っているクラウドサービスやNoSQL と合わせて活用してみてください。
CData Excel Add-In は、日本のユーザー向けにUI の日本語化、ドキュメントの日本語化、日本語でのテクニカルサポートを提供しています。