各製品の資料を入手。
詳細はこちら →Apache Spark Data Provider の30日間無償トライアルをダウンロード
30日間の無償トライアルへこんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
CData ADO.NET Provider for SparkSQL は、Crystal Reports for Visual Studio 開発環境に統合されています。標準のADO.NET コンポーネントを使用して、SQL Server と同じようにレポートを作成でき、さらにSpark とリアルタイムで連携できます。この記事では、開いたときに更新されるレポートにSpark のデータを追加するために必要な3つのステップを完了する方法を説明します。
Note:このチュートリアルを実行するには、Crystal Reports とVisual Studio のデベロッパーバージョンをインストールしてください。
この記事を実行するにはVisual Studio Crystal Reports プロジェクトが必要になります。この記事では、WPF アプリケーションにレポートを追加します。「File」->「New Project」とクリックし、Crystal Reports WPF Application テンプレートを選択することで、作成できます。表示されるウィザードで空のレポートを作成するオプションを選択します。
Server Explorer からSpark のADO.NET データソースを作成すると、Crystal Reports ウィザードおよびCrystal Reports Designer で使用できるDataSet を簡単に作成できます。Server Explorer でSpark のデータを操作するためのガイドは、ヘルプドキュメントの「はじめに」の章を参照してください。
SparkSQL への接続を確立するには以下を指定します。
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
接続を構成する際に、Max Rows 接続プロパティも設定できます。これにより返される行数が制限されるため、レポートやビジュアライゼーションをデザインするときのパフォーマンスを向上させることができます。
以下のステップに従ってVisual Studio ADO.NET DataSet Designer を使用し、ADO.NET DataSet オブジェクトを作成します。Crystal Reports はSpark テーブルのメタデータを含むDataSet オブジェクトにバインドします。またこのアプローチでは、App.config に接続文字列が追加されることに注意してください。後にこの接続文字列を使用してデータをレポートにロードします。
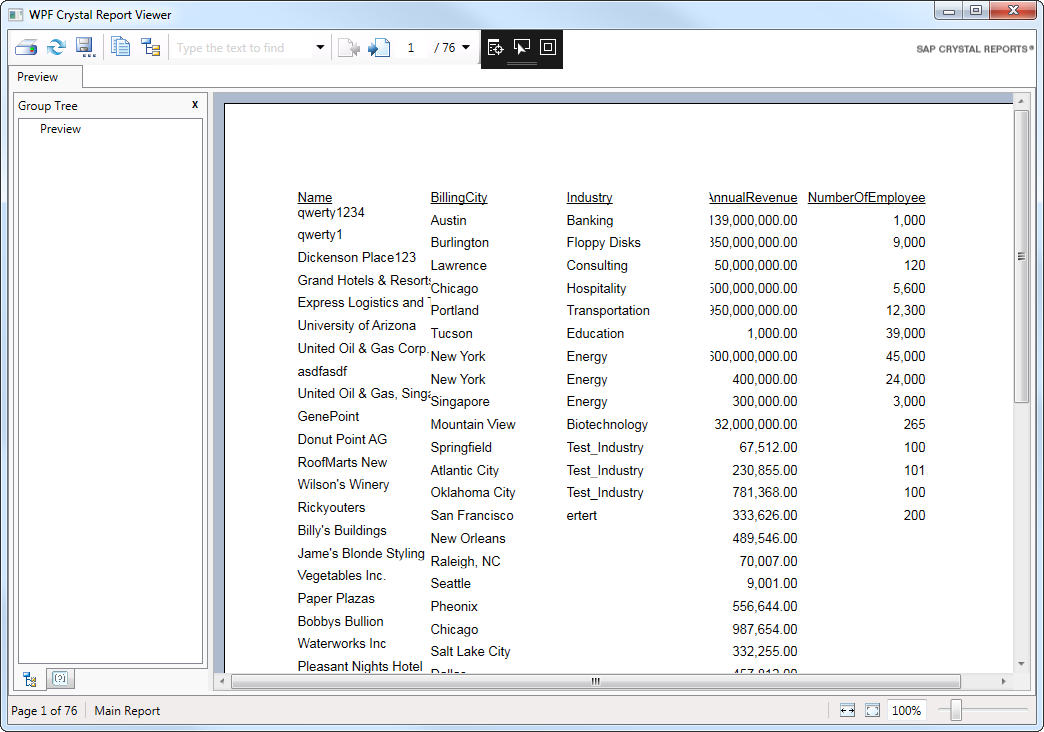
以下のステップに従って、DataSet からレポートにカラムを追加します。
メタデータのみを含むDataSet を作成したら、実際のデータを含むDataTable を作成する必要があります。SparkSQLDataAdapter を使用して、SQL クエリの結果をDataTable に入力できます。
<startup useLegacyV2RuntimeActivationPolicy="true">
<supportedRuntime version="v4.0" sku=".NETFramework,Version=v4.0"/>
</startup>
Window.xaml.cs ファイルに以下の参照を追加します。
using System.Configuration; using CrystalDecisions.CrystalReports.Engine; using CrystalDecisions.Shared; using System.Data.CData.SparkSQL; using System.Data;
以下のWindow_Loaded メソッドをWindow.xaml.cs に追加し、DataTable を返すSQL クエリを実行します。最低でも、レポートで使用されているカラムと同じカラムは選択する必要があることに注意してください。
private void Window_Loaded(object sender, RoutedEventArgs e) {
ReportDocument report = new ReportDocument();
report.Load("../../CrystalReport1.rpt");
var connectionString = ConfigurationManager.ConnectionStrings["MyAppConfigConnectionStringName"].ConnectionString;
using (SparkSQLConnection connection = new SparkSQLConnection(connectionString)) {
SparkSQLDataAdapter dataAdapter = new SparkSQLDataAdapter(
"SELECT City, Balance FROM Customers", connection);
DataSet set = new DataSet("_set");
DataTable table = set.Tables.Add("_table");
dataAdapter.Fill(table);
report.SetDataSource(table);
}
reportViewer.ViewerCore.ReportSource = report;
}
Window.xaml ファイルでLoaded イベントを追加し、Window タグを以下のようにします。
<Window x:Class="CrystalReportWpfApplication4.Window1"
xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
xmlns:cr="clr-namespace:SAPBusinessObjects.WPF.Viewer;assembly=SAPBusinessObjects.WPF.Viewer"
alt="WPF Crystal Report Viewer" Height="600" Width="800" Loaded="Window_Loaded">
...
</Window>
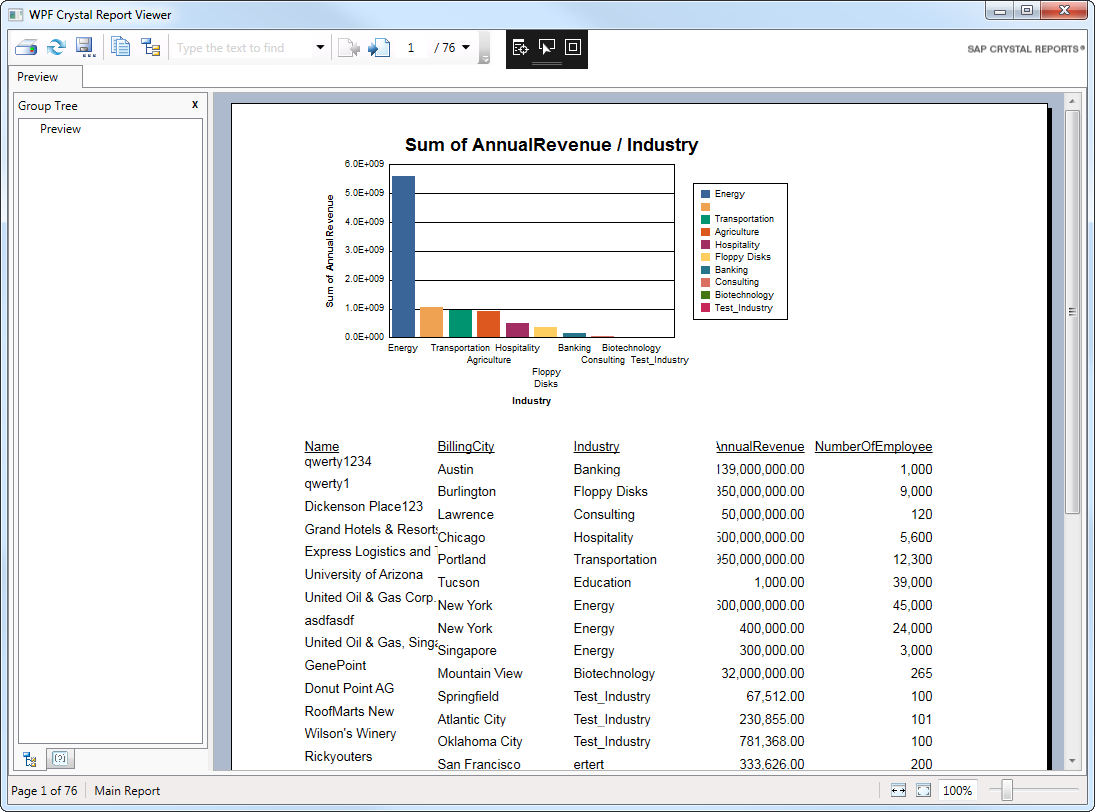
Chart Expert などのエキスパートとともにDataSet を使用することもできます。
Crystal Reports は、Spark API などに対してGROUP BY を実行する代わりに、DataTable にロード済みのデータに対して集計を実行することに注意してください。これは、レポート作成ウィザードにも当てはまります。
別のDataSet を作成し、他のクエリを入力することで、Spark に対して実行されるクエリをより細かく制御できます。ドライバのSQL エンジンの詳細については、ヘルプドキュメントを参照してください。