各製品の資料を入手。
詳細はこちら →Confluence ODBC Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへ製品の詳細
Confluence ODBC Driver を使って、ODBC 接続をサポートするあらゆるアプリケーション・ツールからConfluence にデータ連携。
Confluence データにデータベースと同感覚でアクセスして、Confluence のAttachments、Comments、Groups、Users に使い慣れたODBC インターフェースで連携。
こんにちは!ドライバー周りのヘルプドキュメントを担当している古川です。
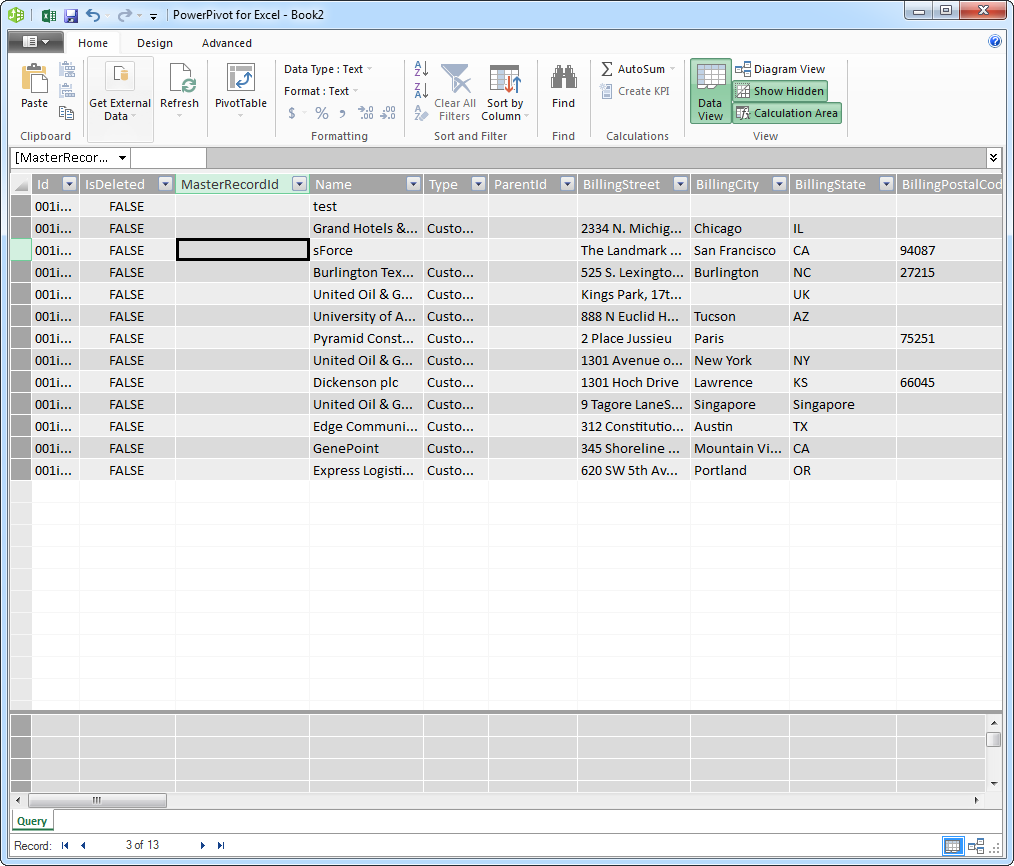
ODBC プロトコルは多くのBI および帳票ツールで多様なデータベースのデータにアクセスするために使われています。CData ODBC Drive を使って、簡単にConfluence をデータ連携できます。この記事では、CData Driver for Confluence を使ってPowerPivot にデータをインポートします。
CData ODBC ドライバは、以下のような特徴を持ったリアルタイムデータ連携ソリューションです。
CData ODBC ドライバでは、1.データソースとしてConfluence の接続を設定、2.PowerPivot 側でODBC Driver との接続を設定、という2つのステップだけでデータソースに接続できます。以下に具体的な設定手順を説明します。
まずは、本記事右側のサイドバーからConfluence ODBC Driver の無償トライアルをダウンロード・インストールしてください。30日間無償で、製品版の全機能が使用できます。
接続プロパティが未設定の場合には、DSN(データソース名)の設定を行います。Microsoft ODBC データソースアドミニストレーターを使ってODBC DSN を作成および設定できます。
未指定の場合は、初めにODBC DSN (data source name) で接続プロパティを指定します。ドライバーのインストールの最後にアドミニストレーターが開きます。Microsoft ODBC Data Source Administrator を使用して、ODBC DSN を作成および構成できます。
API token は、アカウントへの認証に必須です。トークンの生成には、Atlassian アカウントでサービスにログインし、API tokens > Create API token に進みます。生成されたトークンが表示されます。
Cloud アカウントへの接続には、以下のプロパティを設定します(Password は、Server Instance への接続時のみ必要で、Cloud Account への接続には不要になりました。):
Server instance への接続には以下を設定します:
Microsoft ODBC データソースアドミニストレーターで必要なプロパティを設定する方法は、ヘルプドキュメントの「はじめに」を参照してください。
[外部データソースの取り込み]から[その他のソース]ボタンをクリックします。
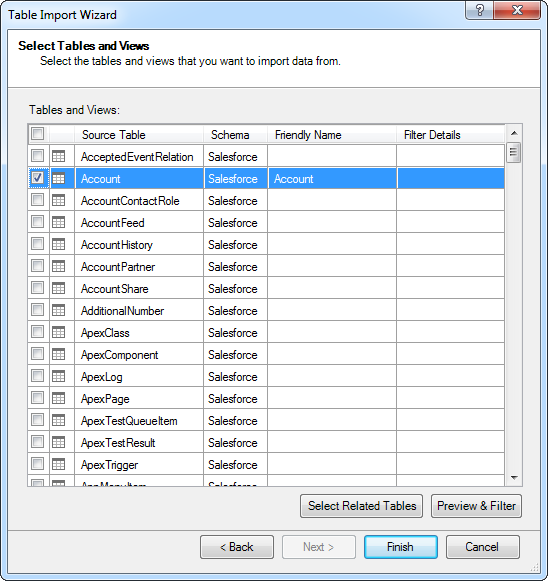
下記の手順に従って、ウィザードを使ってConfluence のテーブルからデータをロードします。Confluence のカラムをウィザードを使って選択、フィルタ、およびソートすると、PowerPivot は実行されるクエリを生成します。
インポートするテーブルを選ぶ以外に、特定のカラムをインポートするクエリの指定やフィルタの定義もできます。ドライバーは元になるConfluence API に相当する、シンプルで直観的なSQL ダイアレクトをサポートします。
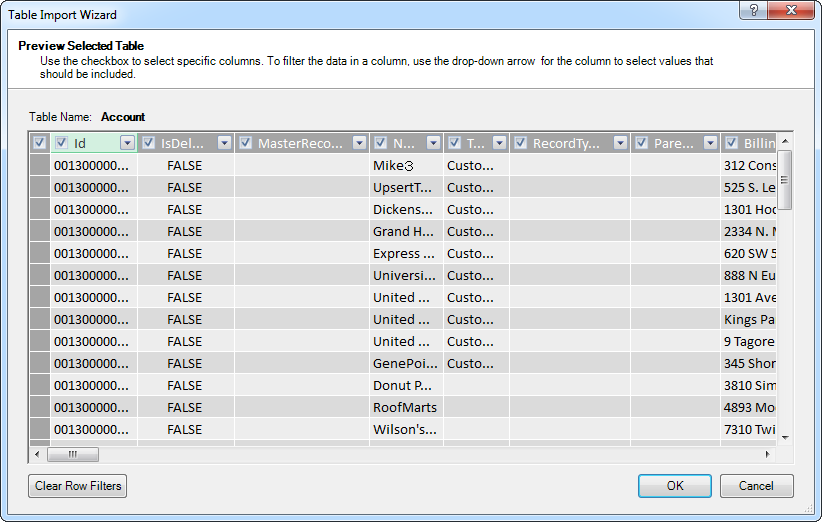
[SQL ステートメント]ボックスにクエリを入れます。[検証]をクリックしてクエリステートメントが有効かどうかを確認します。[デザイン]をクリックして結果をプレビューし、インポートする前にクエリを直します。
WHERE 句を使ってフィルタライテリアクを指定できます。利用可能なSQL 機能の例については、ヘルプドキュメントの「サポートされるSQL」を参照してください。
このようにCData ODBC ドライバと併用することで、270を超えるSaaS、NoSQL データをコーディングなしで扱うことができます。30日の無償評価版が利用できますので、ぜひ自社で使っているクラウドサービスやNoSQL と合わせて活用してみてください。
CData ODBC ドライバは日本のユーザー向けに、UI の日本語化、ドキュメントの日本語化、日本語でのテクニカルサポートを提供しています。