各製品の資料を入手。
詳細はこちら →Azure DevOps Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへCData


こんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
AWS Glue はAmazon のETL サービスであり、簡単にデータプレパレーションを実行してストレージおよび分析用に読み込むことができます。AWS Glue と一緒にPySpark モジュールを使用すると、JDBC 接続経由でデータを処理するジョブを作成し、そのデータをAWS データストアに直接読み込むことができます。ここでは、CData JDBC Driver for AzureDevOps をAmazon S3 バケットにアップロードし、Azure DevOps からデータを抽出してCSV ファイルとしてS3 に保存するためのAWS Glue ジョブを作成・実行する方法について説明します。
CData JDBC Driver for AzureDevOps をAWS Glue から使用するには、ドライバーの.jar ファイル(および必要なライセンスファイル)をAmazon S3 のバケットに配置する必要があります。
CData JDBC driver でAzure DevOps に接続するには、JDBC URL を作成します。さらにライセンスとしてJDBC URL にRTK プロパティを設定する必要があります。RTK は通常のライセンスと異なりますので、CData まで直接ご連絡をください。
Azure DevOps アカウントに接続するには、Profile -> Organizations に移動して、アカウント内の組織名であるOrganization を指定します。
例: Organization=MyAzureDevOpsOrganization
NOTE :Analytics スキーマに接続する場合は、Organization と一緒にProjectId を指定する必要があります。
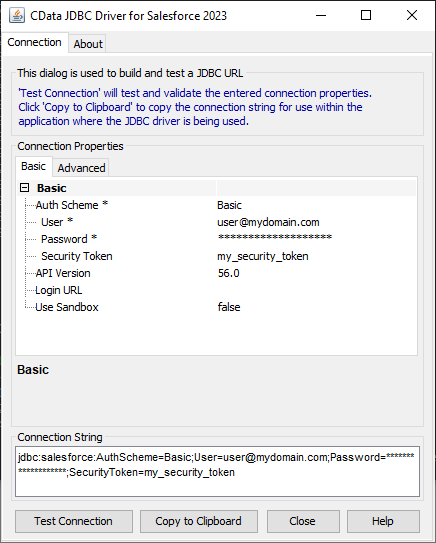
JDBC URL の作成をサポートするビルトインの接続文字列デザイナーがあります。ドライバーの.jar ファイルをダブルクリックするか、コマンドラインで.jar ファイルを実行するとデザイナーが開きます。
java -jar cdata.jdbc.azuredevops.jar
必要項目を入力すると、デザインs-下部に接続文字列が生成されますのでクリップボードにコピーして使います。
CData JDBC driver をPySpark で使用して、AWS Glue モジュールでAzure DevOps データを取得して、S3 にCSV 形式で保存するシンプルなスクリプト例は以下です。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.dynamicframe import DynamicFrame
from awsglue.job import Job
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sparkContext = SparkContext()
glueContext = GlueContext(sparkContext)
sparkSession = glueContext.spark_session
##Use the CData JDBC driver to read Azure DevOps データ from the Builds table into a DataFrame
##Note the populated JDBC URL and driver class name
source_df = sparkSession.read.format("jdbc").option("url","jdbc:azuredevops:RTK=5246...;AuthScheme=Basic;Organization=MyAzureDevOpsOrganization;ProjectId=MyProjectId;PersonalAccessToken=MyPAT;").option("dbtable","Builds").option("driver","cdata.jdbc.azuredevops.AzureDevOpsDriver").load()
glueJob = Job(glueContext)
glueJob.init(args['JOB_NAME'], args)
##Convert DataFrames to AWS Glue's DynamicFrames Object
dynamic_dframe = DynamicFrame.fromDF(source_df, glueContext, "dynamic_df")
##Write the DynamicFrame as a file in CSV format to a folder in an S3 bucket.
##It is possible to write to any Amazon data store (SQL Server, Redshift, etc) by using any previously defined connections.
retDatasink4 = glueContext.write_dynamic_frame.from_options(frame = dynamic_dframe, connection_type = "s3", connection_options = {"path": "s3://mybucket/outfiles"}, format = "csv", transformation_ctx = "datasink4")
glueJob.commit()
スクリプト記述後、Glue ジョブを実行します。実行した取得/ロードのジョブが完了するとAWS Glue コンソールのジョブページでステータスが確認できます。成功するとS3 バケットにAzure DevOps データのCSV ファイルが生成されています。
このようにCData JDBC Driver for AzureDevOps をAWS Glue で使用することで、Azure DevOps データをAWS Glue で自在に扱うことができます。Glue の外部データへの接続性を拡張するJDBC Driver を是非お試しください。