こんにちは!テクニカルサポートエンジニアの宮本です!
皆さんは Yellowbrick Data というサービスをご存知でしょうか?
この Yellowbrick Data は次世代のフラッシュストレージに最適化されたデータウェアハウスということで、USの記事などを見るとこれまでのDWHサービスに比べ格段とパフォーマンスが向上されているようです。
今回は ETL/ELT ツールのCData Sync を使って Salasforce のデータをレプリケートしてみたところ、ちゃんと Yellowbrick に連携することができましたので、この実現方法をご紹介していこうと思います。
Yellowbrick Data とは
Yellowbrick Data はハイパフォーマンスかつ低価格が特徴のインメモリデータベース型クラウドデータウェアハウスです。この DB には PostgreSQL の JDBC や ODBC からアクセスできるので、中は PostgreSQL が動いているようです。
Data Warehouse for Distributed Data Cloud - Yellowbrick
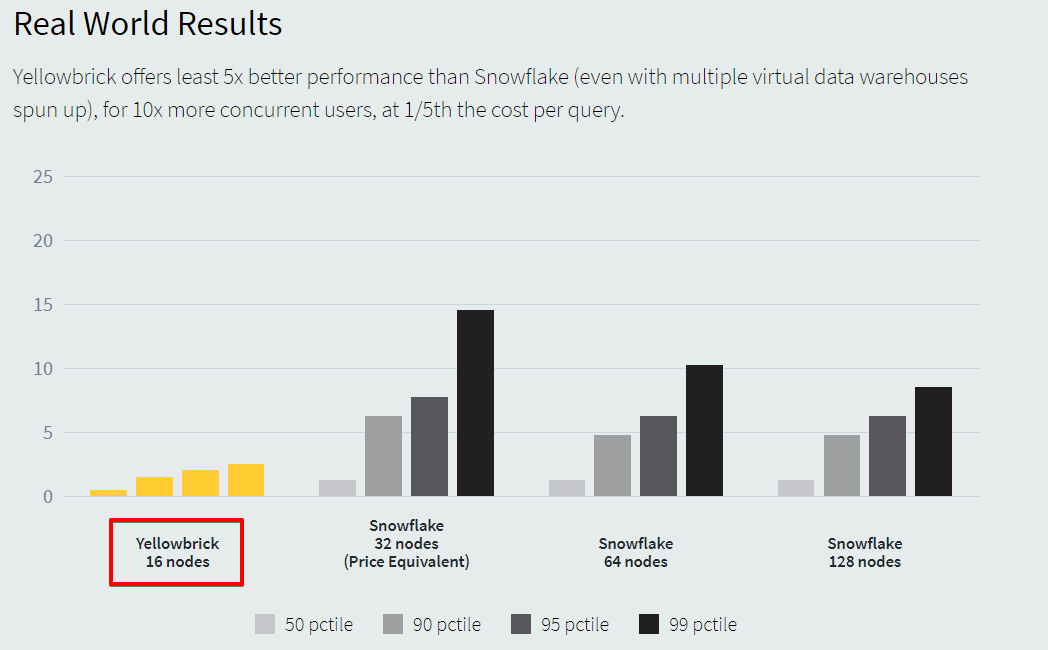
公式サイトにも価格やパフォーマンスの比較が出ていて、Snowflake との比較結果を見る限りでは相当パフォーマンスが高いことがわかります。
https://www.yellowbrick.com/performance/
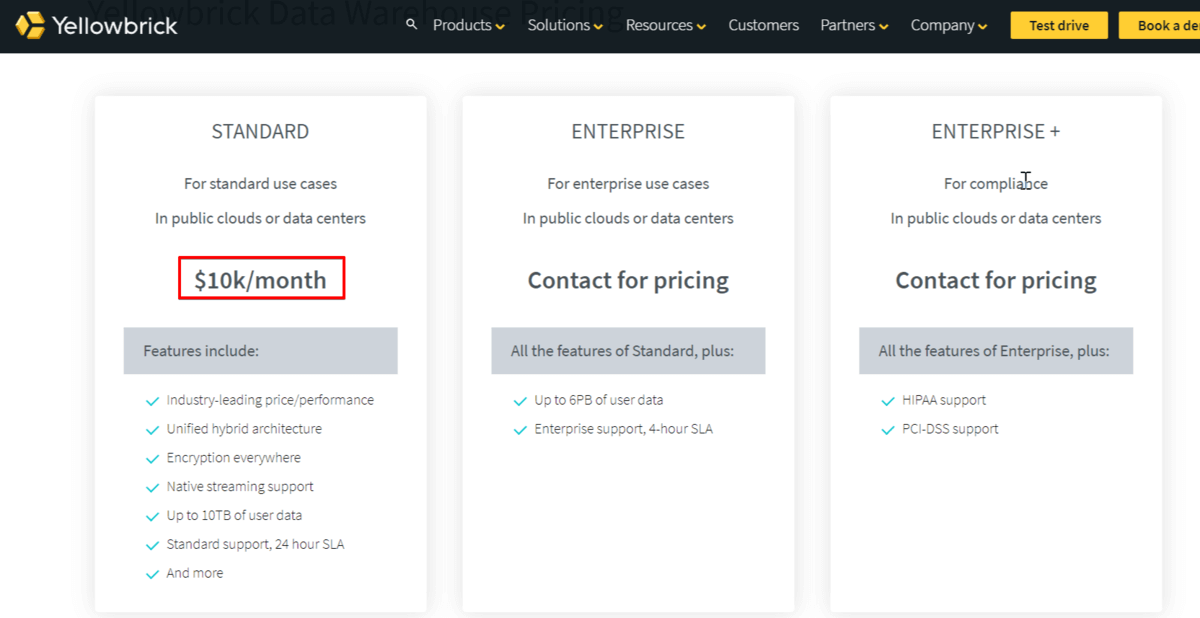
コストは3レベルあり、提示されているのは STANDARD だけですが、月に $10K からということなので、判断材料としてはわかりやすいですね。
また、Yellowbrick はAWSへのホスティングの他、近々 Azure や GCP 上でも利用できるようになるようです。
やってみること
 Yellowbrick がネイティブの PostgreSQL Driver で接続できるということから、CData Sync のPostgreSQL コネクタを使って Salesforce のデータを Yellowbrick が保持している DB にレプリケートしてみます。
Yellowbrick がネイティブの PostgreSQL Driver で接続できるということから、CData Sync のPostgreSQL コネクタを使って Salesforce のデータを Yellowbrick が保持している DB にレプリケートしてみます。
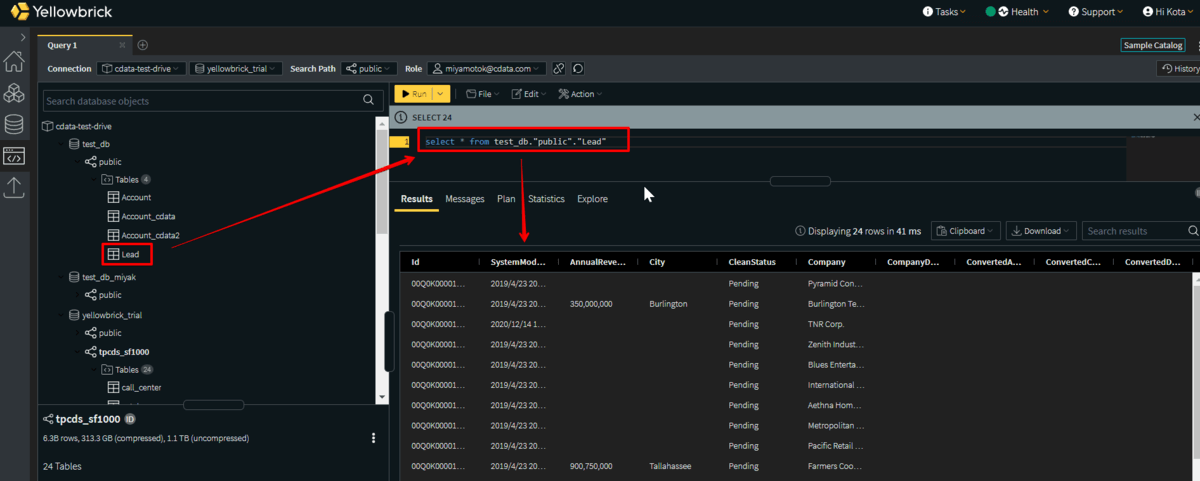
以下は Yellowbrick の管理コンソールです。最終的にはこの Yellowbrick の DB に Salesforce のオブジェクトがそのままテーブルとして追加されるようになります。
ではさっそくやっていきましょう。
手順
用意するものは下記になります。
- Yellowbrick のアカウント
- CData Sync ※30日間無料トライアルあり
- Salesforce アカウント
CDataSync 準備
CData Sync を以下リンクからダウンロードします。
www.cdata.com
ダウンロードしましたらそのままインストーラーを実行してインストールを開始します。
基本的にそのまま進めちゃって大丈夫です。
ちなみにCDataSyncの基本的な操作方法はこちらのハンズオン記事をご参照ください。
CData Sync ハンズオン - CData Software Blog
接続設定
Salesforce の接続設定
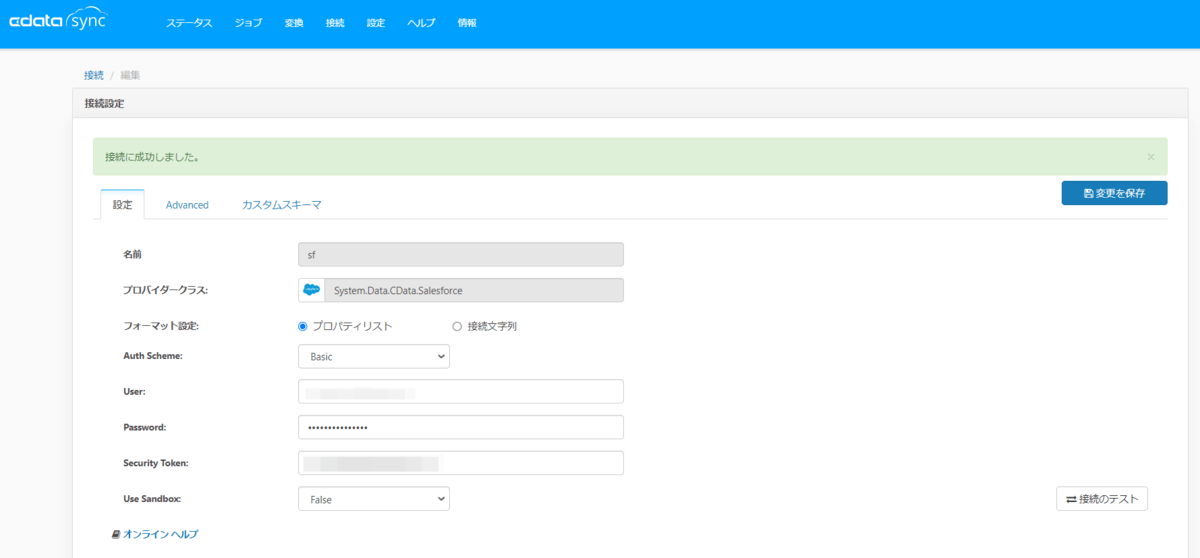
起動しましたら、接続設定を行います。Salesforce アイコンをクリックし、

以下の接続情報を入力したら、接続のテスト→保存を行います。
| 項目 |
設定値 |
| 名前 |
任意の接続情報 |
| フォーマット設定 |
プロパティリスト |
| Auth Scheme |
Basic ※OAuthも可能 |
| User |
Salesforceのユーザー情報 |
| Password |
Salesforceのパスワード |
| Security Token |
Salesforceのセキュリティトークン |
| Use Sandbox |
False |
Yellowbrick の接続設定
Yellowbrick への接続には最初に少しだけ設定が必要になります。
とはいえやることは、Yellowbrick 内の PostgreSQL に任意の DB とユーザー権限を付与するだけになります。
①DBの作成
create database Salesfocre_DB;
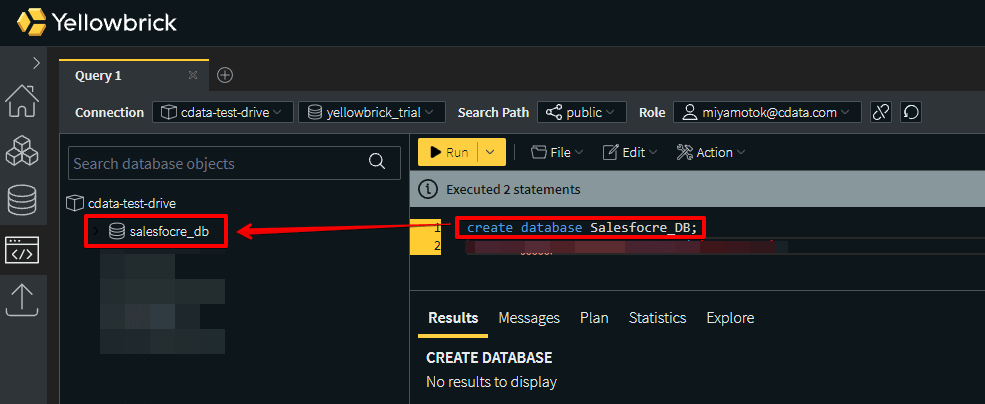
②ユーザーの作成
DB を切り替えた後にユーザー作成
create user sfuser password 'sfpass';
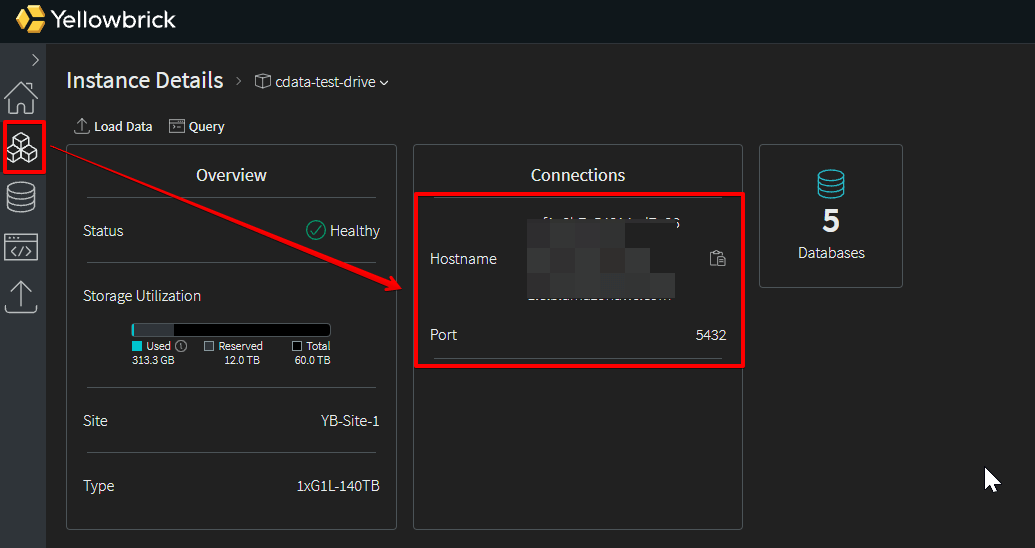
③Yellowbrick のホスト名を確認
ここでホスト名とポートを確認します。後ほど CData Sync の接続設定で使用するのでコピーしておきます。
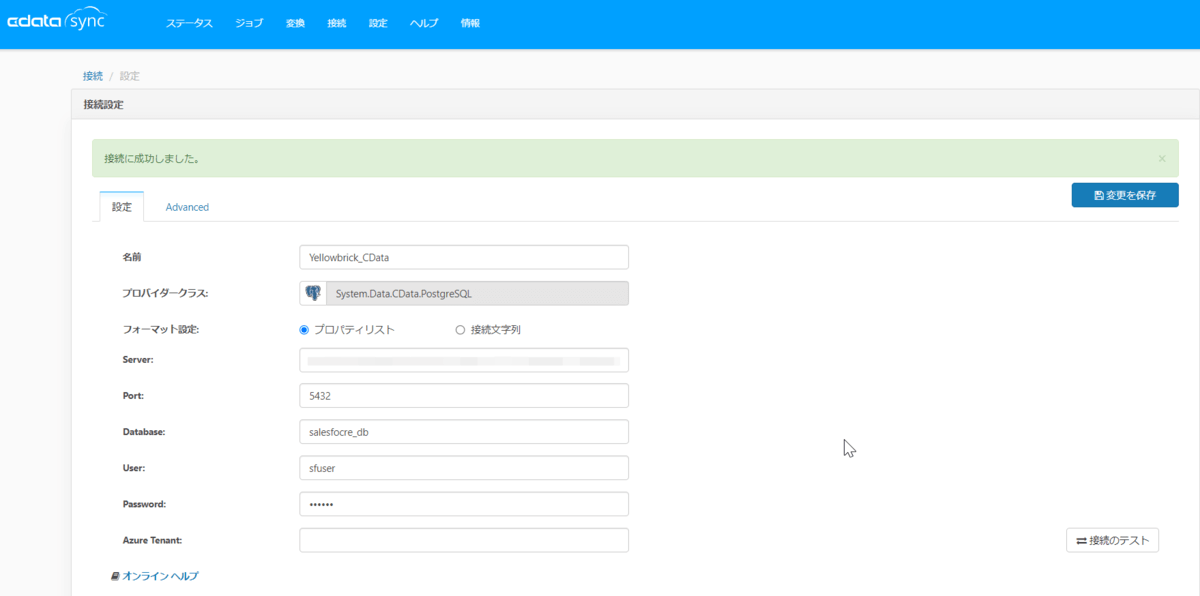
では CData Sync に戻り、Yellowbrick の接続情報を作成します。
接続情報画面にて同期先→PostgreSQL アイコンをクリックします。

以下の内容を設定します。
| 項目 |
設定値 |
| 名前 |
任意の接続情報 |
| フォーマット設定 |
プロパティリスト |
| Server |
先ほど確認したYellowbrickのホスト名 |
| Port |
上と同じく確認したポート |
| Database |
作成したDB |
| User |
作成したDBのユーザー |
| Password |
作成したDBのパスワード |
ジョブ作成~実行
ジョブ作成画面でジョブを追加ボタンをクリックし、ソースに Salesforce の接続情報、同期先に Yellowbrick の接続情報を指定してジョブを作成します。
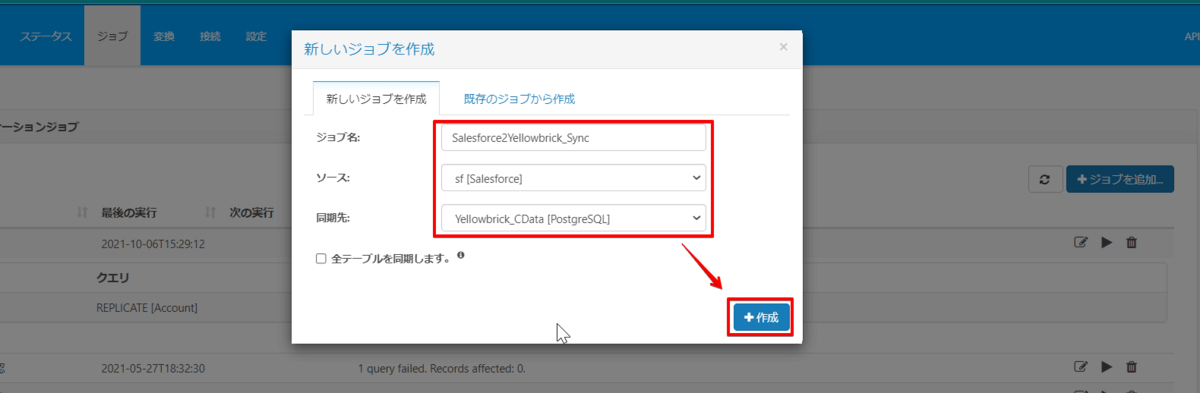
次に実行するクエリを作成します。テーブルを追加ボタンから Lead テーブルを選択してクリックします。
本来ならこれだけで良いのですが、Salesforce で設定されているLONGTEXT型の項目がYellowbrick(PostgreSQL) 上では利用できません。ですので、下記のように型変更の指定をクエリに入れてあげることでジョブが実行できるようになります。
REPLICATE [Lead_SF] (Description VARCHAR2(3000)) SELECT * FROM [Lead]
作成したクエリにチェックを入れて実行します。成功するとステータスにレプリケートした件数が表示されるようになります。
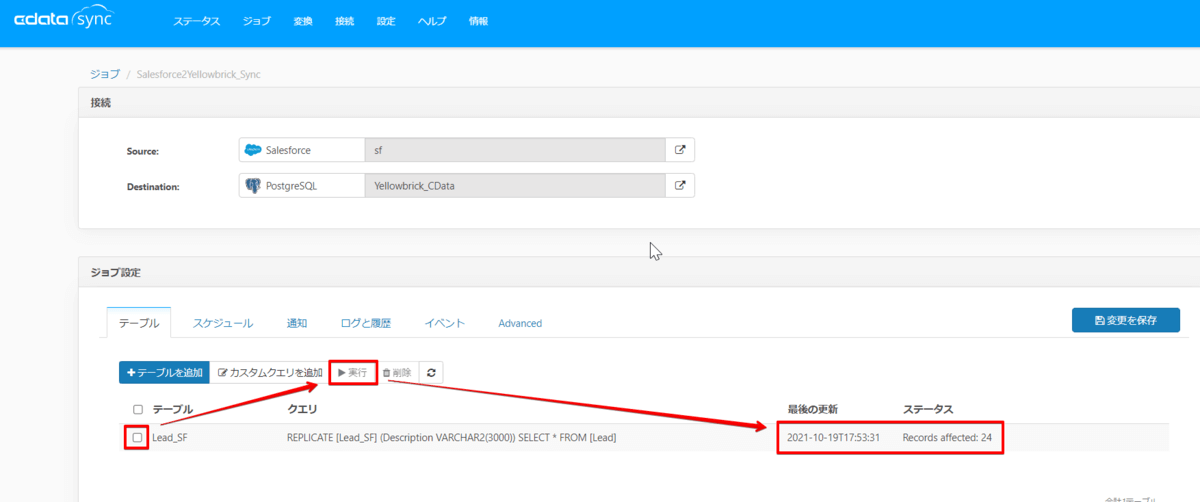
では Yellowbrick のDBを確認してみましょう。
Yellowbrick 上で連携データ確認
Databases からデータベース一覧を表示させ、対象DBをクリックしてみます。
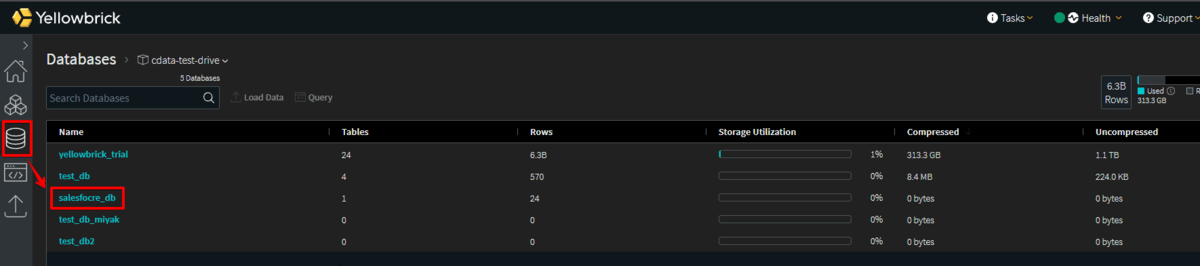
そうすると、本来あるはずのレプリケートしたテーブルが表示されていません。
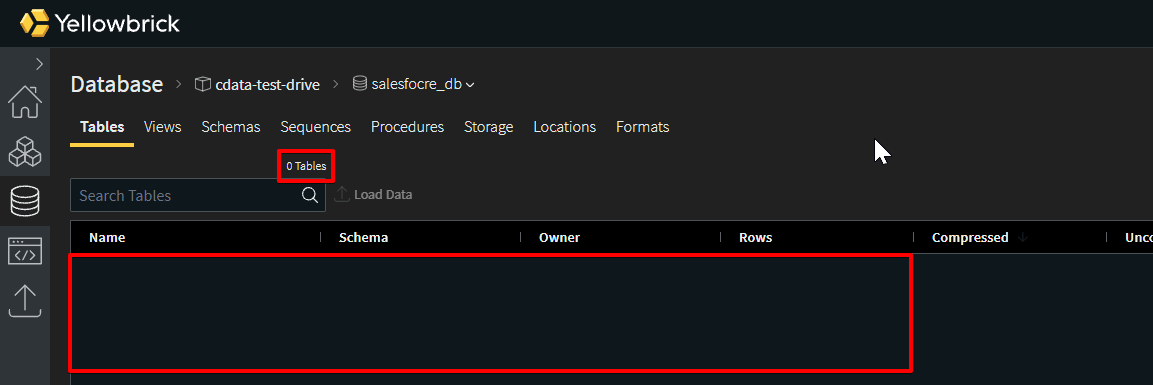
これは対象DBへの権限が、このYellowbrick 管理画面にログインしているアカウントに振られていないことが原因です。
この管理画面へのログインアカウントは恐らく1つだけになるので、そのアカウントへ権限付与してあげることでテーブルが表示されるようになります。
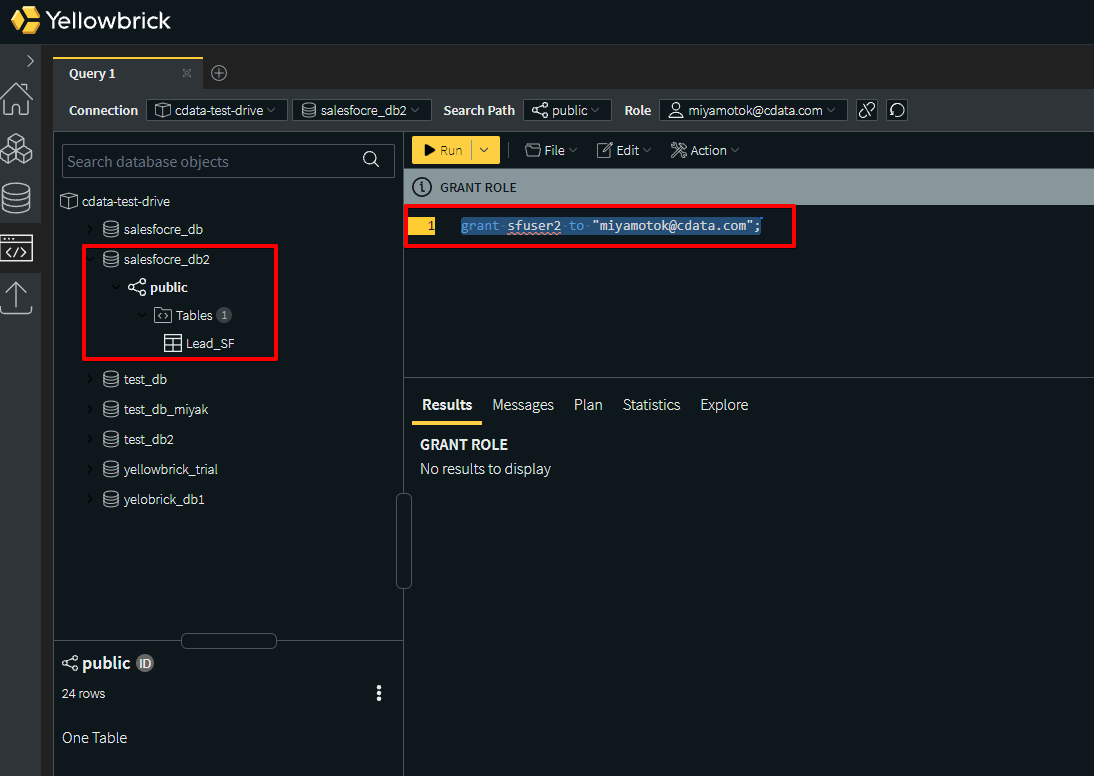
権限付与のために以下のクエリを実行するとログインアカウントでテーブルまで見れるようになります。
grant sfuser to "[email protected]";
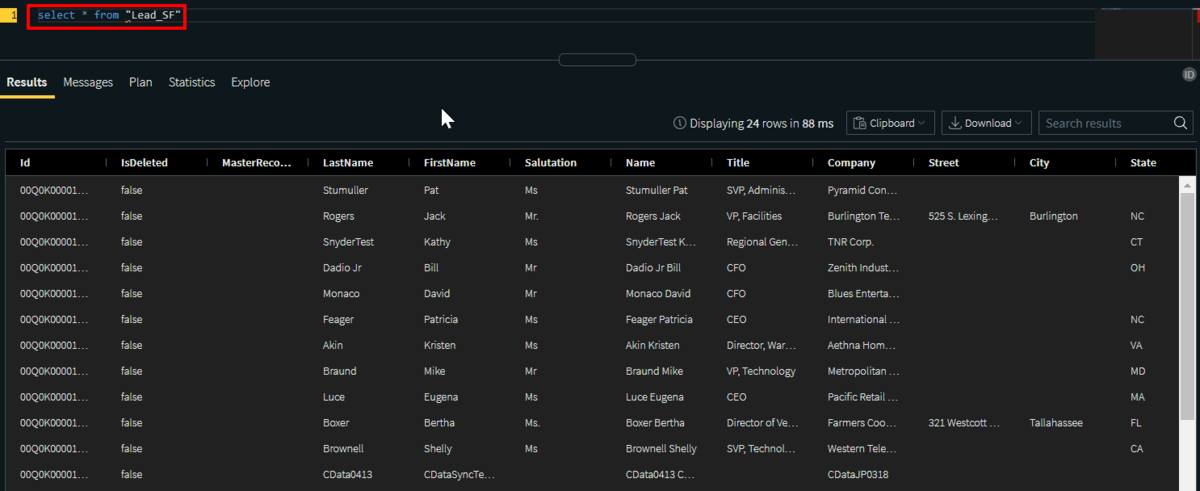
あとはクエリを実行してみるとレプリケートしたレコードが表示されます。
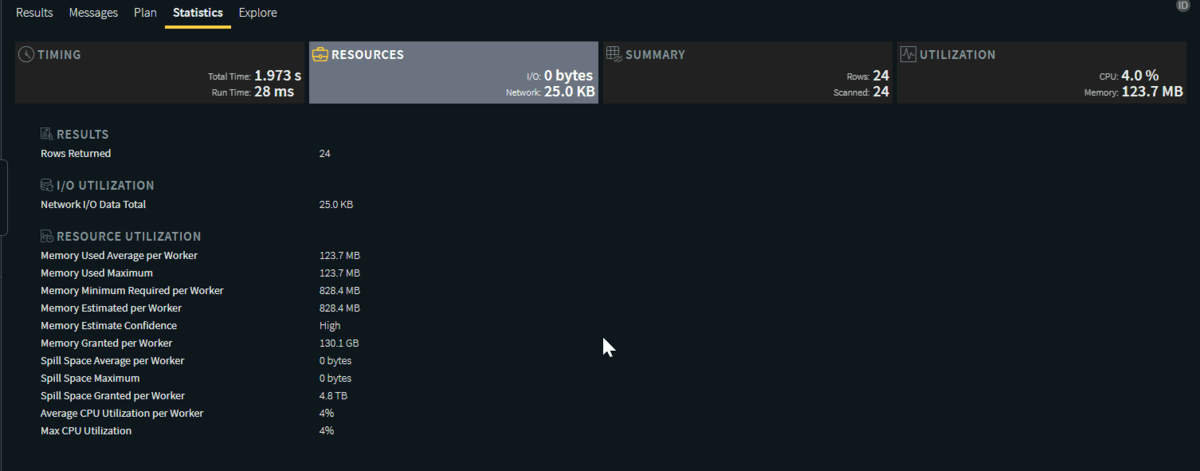
また、実行結果からYellowbrick上のCPUやメモリの利用状況を確認することができるようですね。
おわりに
Salesforce から Yellowbrick への連携はいかがでしたでしょうか。大量データを扱っていてこれからどのDWHを使うか選定中であれば、一度試してみてはいかがでしょうか? また、CData Sync は 30日間の無償トライアルが可能です。是非お試しください!
www.cdata.com
関連コンテンツ



