
こんにちは、CData Software Japanテクニカルサポートの大川です。
本記事では、Salesforce上のリード情報から取引につながりそうなリードを機械学習を使って予測するというシナリオを、ノーコード分析ツールnehanを使って実行してみます。
はじめに
以前本blogで、弊社CData Python Connectorを使用してPython言語を使ってリードの特徴からそのリードが取引につながるかどうかを予測する方法をご紹介しました。
https://www.cdata.com/jp/blog/2020-06-11-091813
上記の記事では、機械学習に必要なデータの数値化などの前処理や機械学習によるモデルの構築、そしてそのモデルを使った予測の処理をPython言語によるプログラミングで実現しました。Python言語は機械学習やデータの処理・分析に広く用いられており、このような処理に最適な言語です。しかし、プログラミング未経験者にとってはどうしても敷居が高く感じてしまうことも事実です。
この度、弊社のパートナーであるnehan社から分析ツールnehan(以下、単にnehanとします)でSalesforceのデータをダイレクトに連携できる機能がリリースされました。
prtimes.jp
これにより、Salesforce上のデータをnehan上で直接扱えるようになりました。また、nehanでは分析処理はもちろんのこと、そのためのデータの前処理・後処理もGUI上でノーコードで構築することが出来ます。本記事では、以前Python言語で実現したシナリオと同じシナリオをnehanを使いノーコードで実現してみます。
シナリオ
シナリオは以前のblogと同じです。各リードの特徴からそのリードが取引につながるかどうかを予測します。
学習と予測の流れは下図の通りです。予測モデルは既にクローズしたリードをもとに構築し、そのモデルを使ってまだクローズしていないリードの結果を予測します。
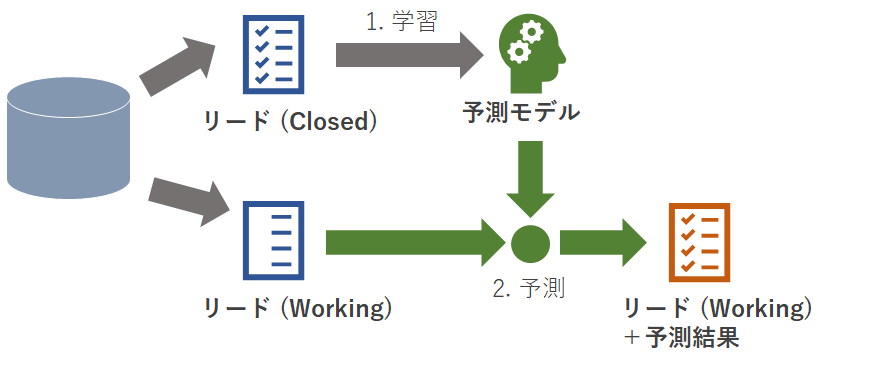
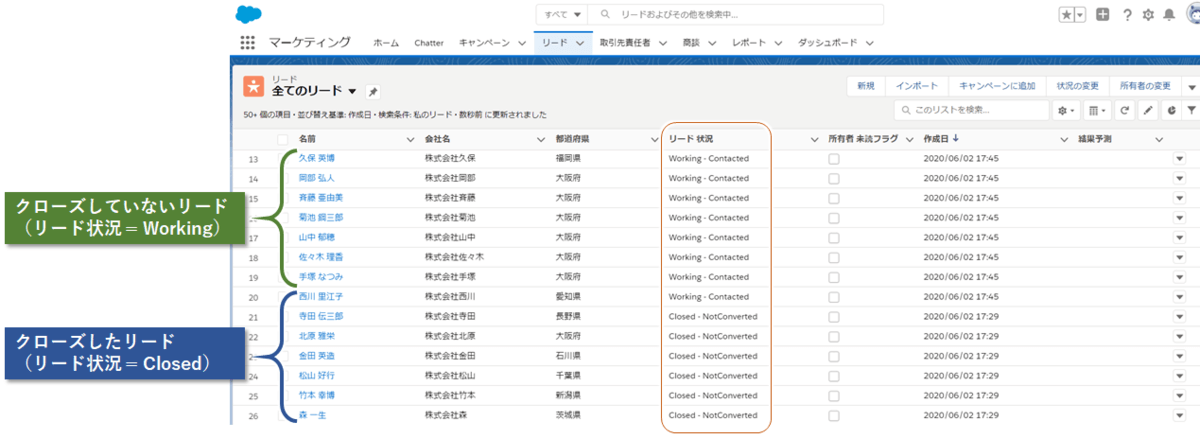
リードがクローズしたかどうかの判別には「リード状況」フィールドを見ます。
リード状況が「Closed」のものをクローズしたリードとみなします。
学習モデル
今回の課題は「教師あり」の「分類課題」に区分けされます。いくつかのアルゴリズムがありますが、今回はロジスティック回帰を使います。
用いた特徴量と目的変数は以下の通りです。
特徴量
| 項目名 |
説明 |
| LeadSource |
リードソース |
| Industry |
業種 |
| AnnualRevenue |
年間売上高 |
| NumberOfEmployees |
従業員数 |
| Rating |
案件の評価 |
目的変数
| 項目名 |
説明 |
| Status |
取引へ変換されたかどうか |
手順
それでは、実際にnehanで上記のシナリオを実行してみます。
接続情報の作成
まずはSalesforceの接続情報を作成していきます。nehanにログインします。
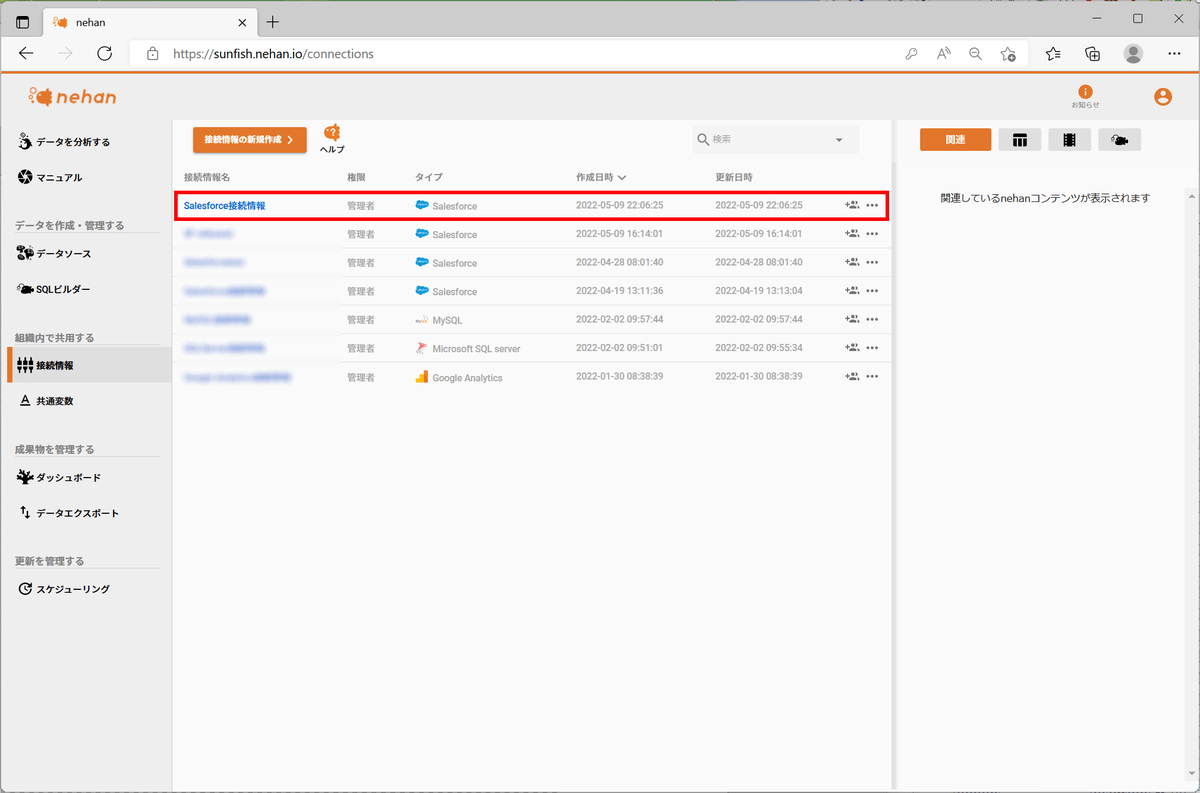
左ペインの「接続情報」をクリックします。
「接続情報の新規作成」をクリックします。
「Salesforce」のアイコンをクリックします。
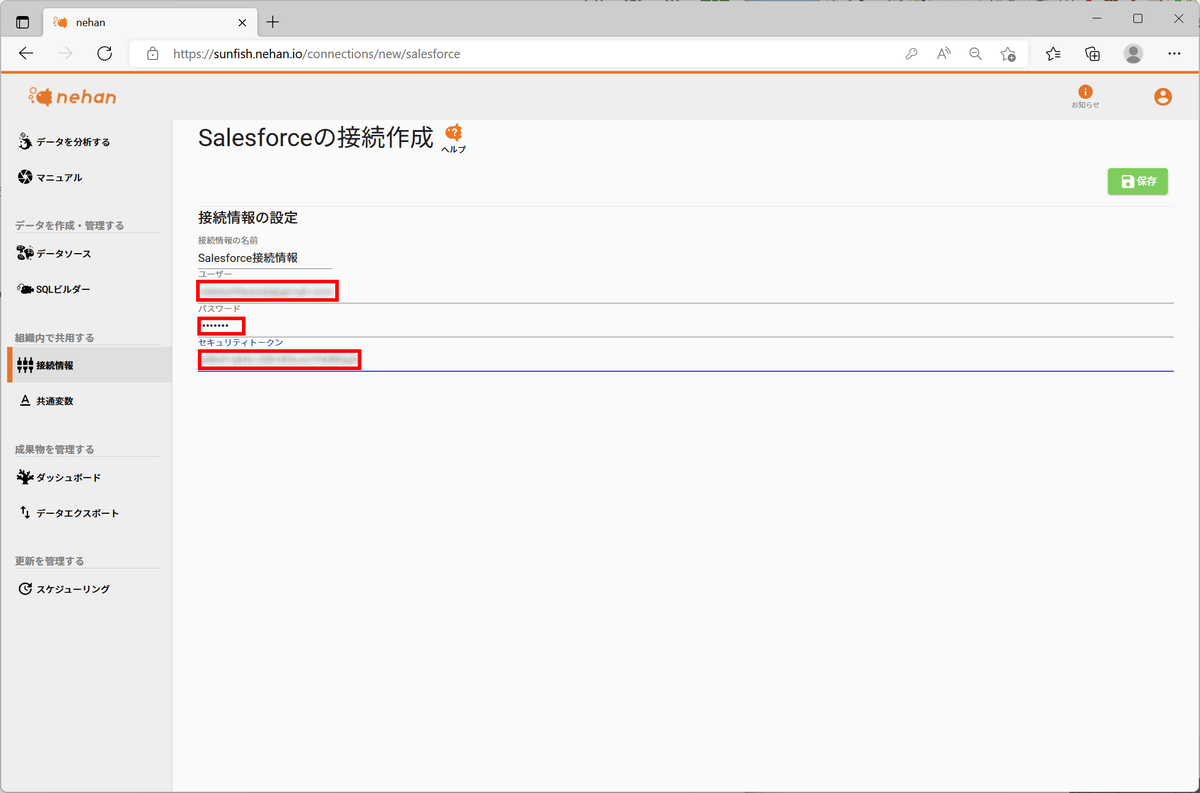
接続に必要な情報を入力し、「保存」をクリックします。
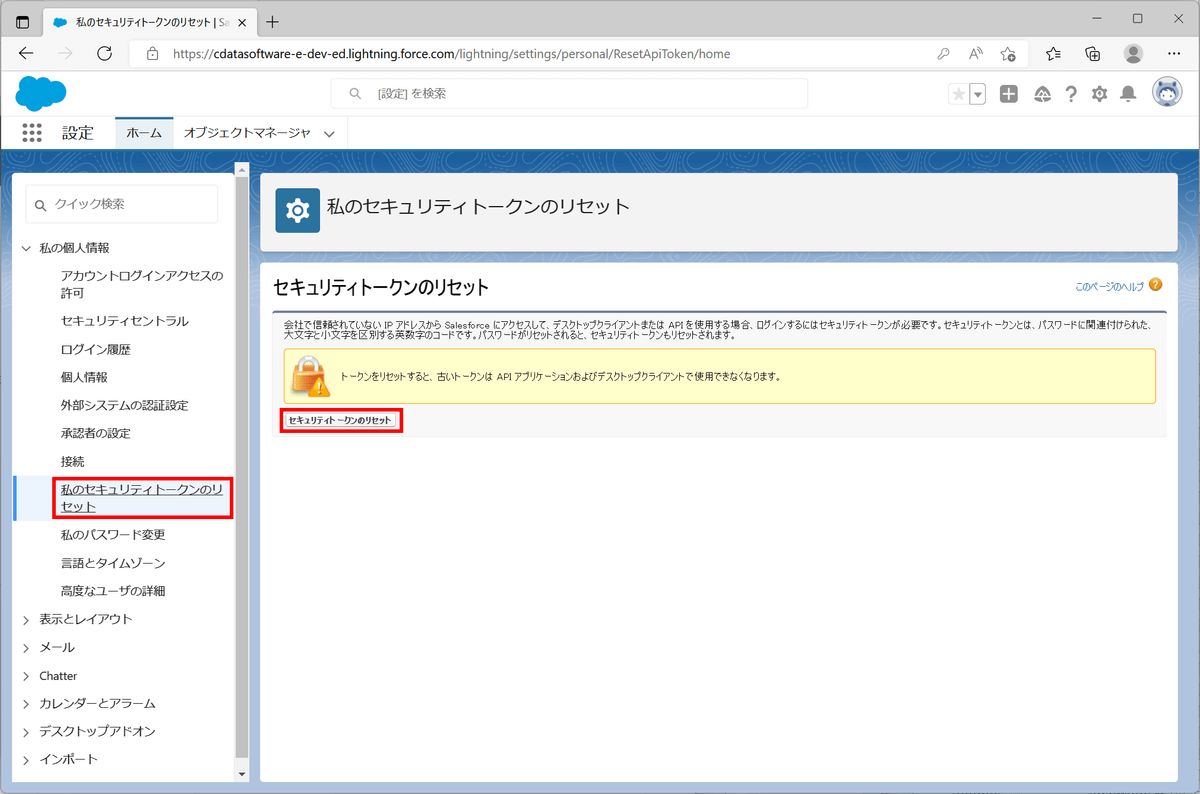
ちなみに、セキュリティトークンはSalesforce上の以下の設定画面で発行できます。
これで、Salesforceの接続情報が作成できました。
SQLビルダーによるデータソースの作成
つぎに、Salesforce上の様々なデータの中から、分析に使用するデータをデータソースとして作成します。データソースの作成はSQL言語を記述して作成する方法もありますが、SQLビルダー機能を使用することでSQLさえも記述せずにデータソースを作成することができます。
今回はSQLビルダーを使ってデータソースを作成してみます。
左ペインの「SQLビルダー」をクリックし、「データソースの新規作成」をクリックします。
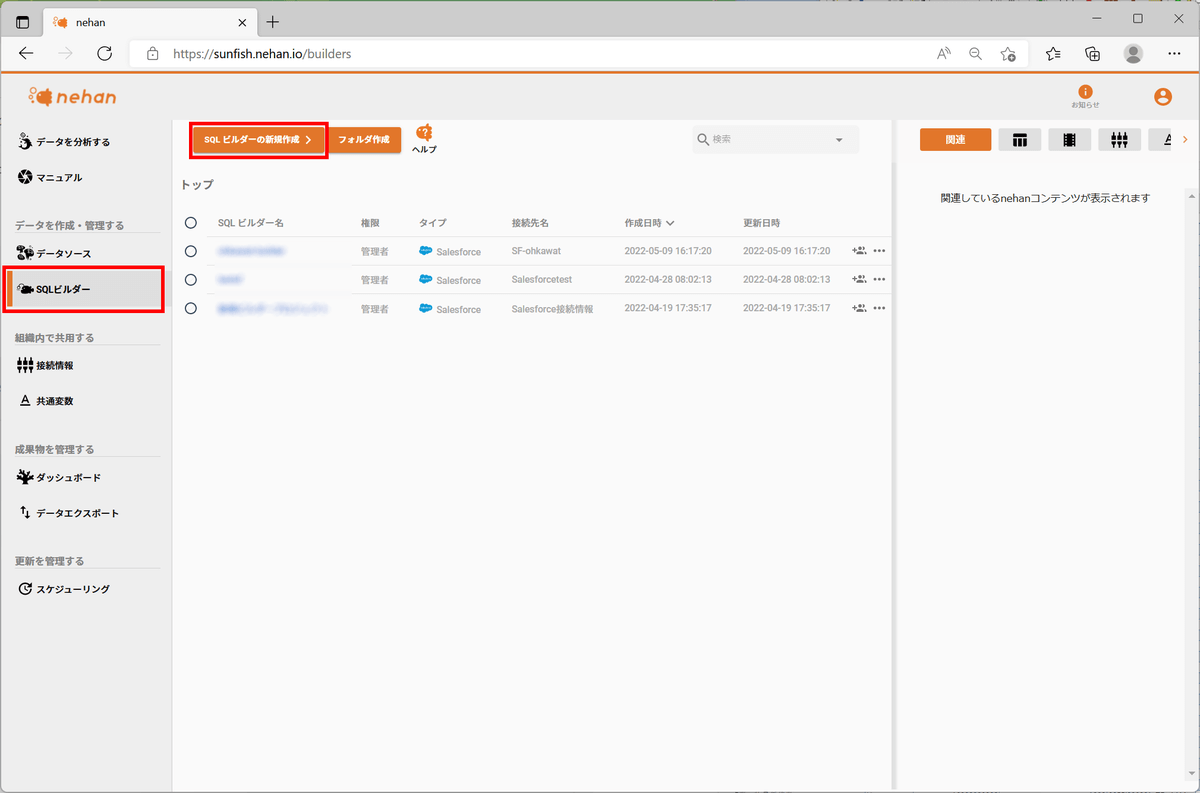
データタイプにSalesforceを選択して「次へ」をクリックします。

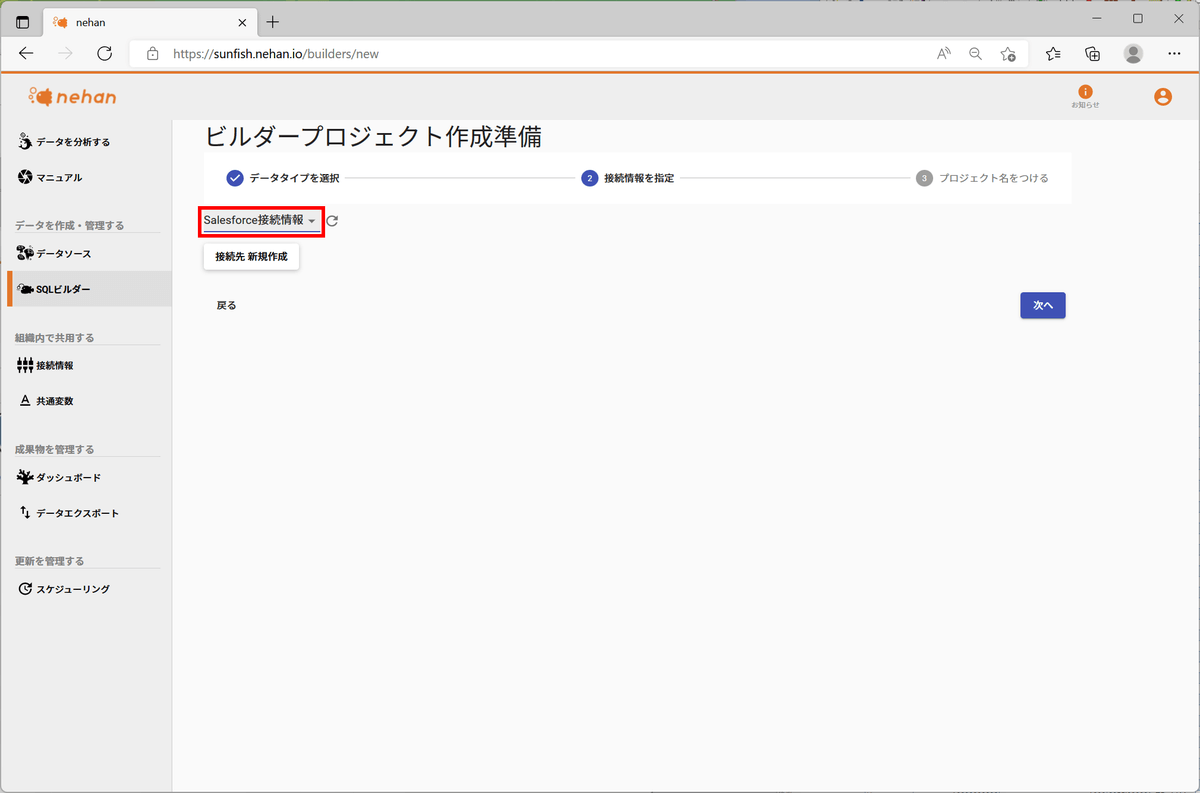
先ほど作成した接続情報を選択し、「次へ」をクリックします。
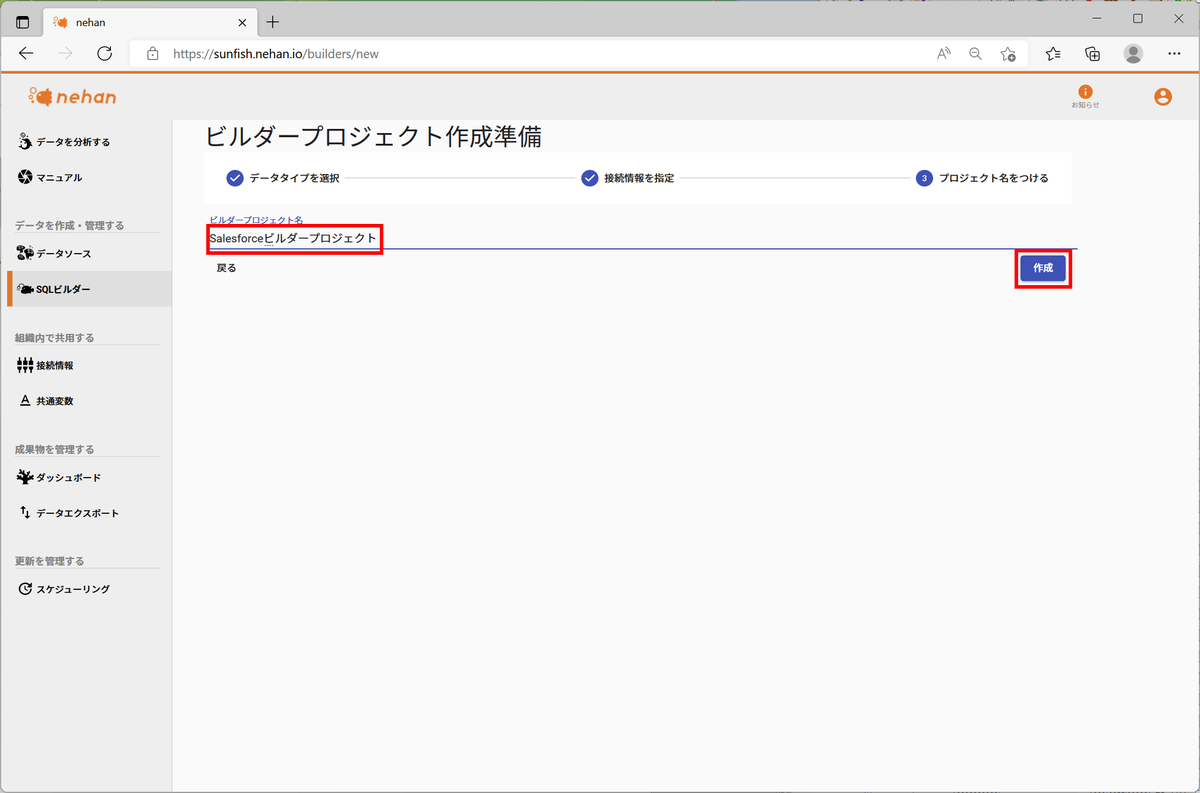
SQLビルダーのプロジェクトに適当な名前を入力し、「作成」をクリックします。
すると、以下のようにSQLビルダーの画面が表示されます。
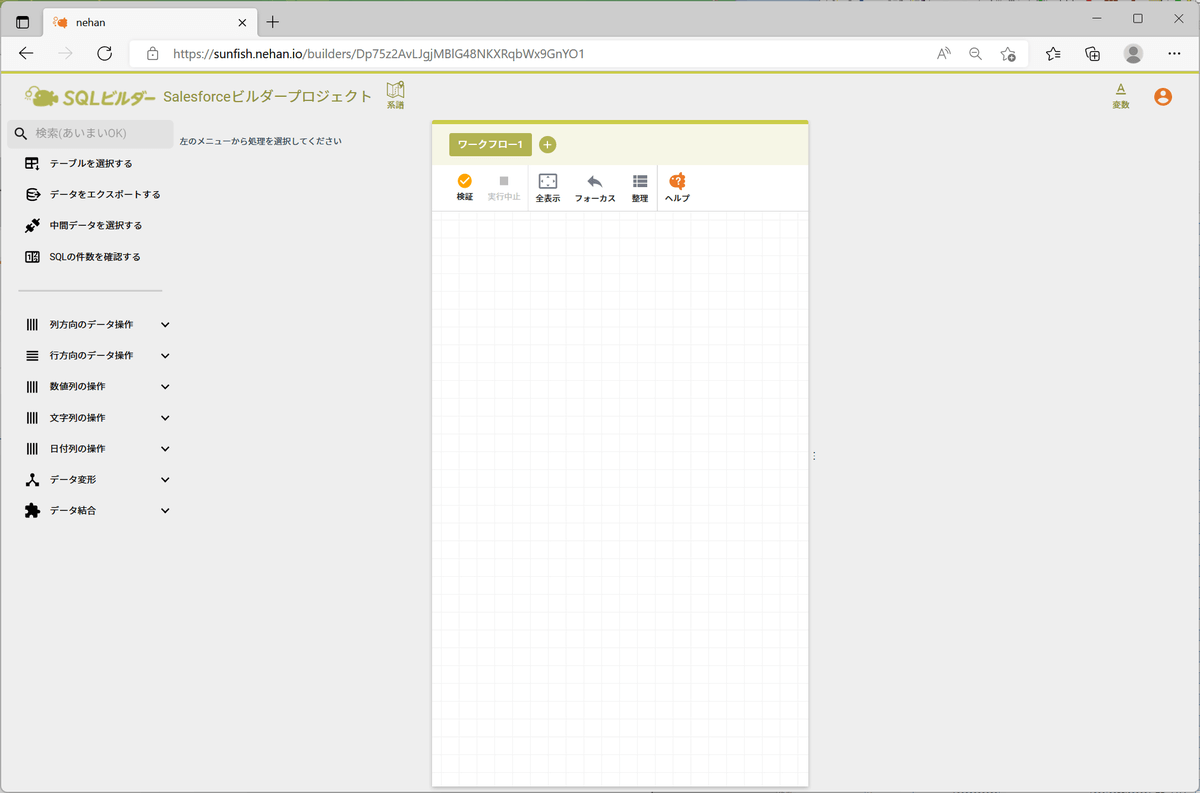
まずはテーブルを選択します。左ペインの「テーブルを選択する」をクリックし、一覧から「Lead」をクリックして「テーブルを読み込む」をクリックします。すると、右側ペインに読み込み結果が表示されます。
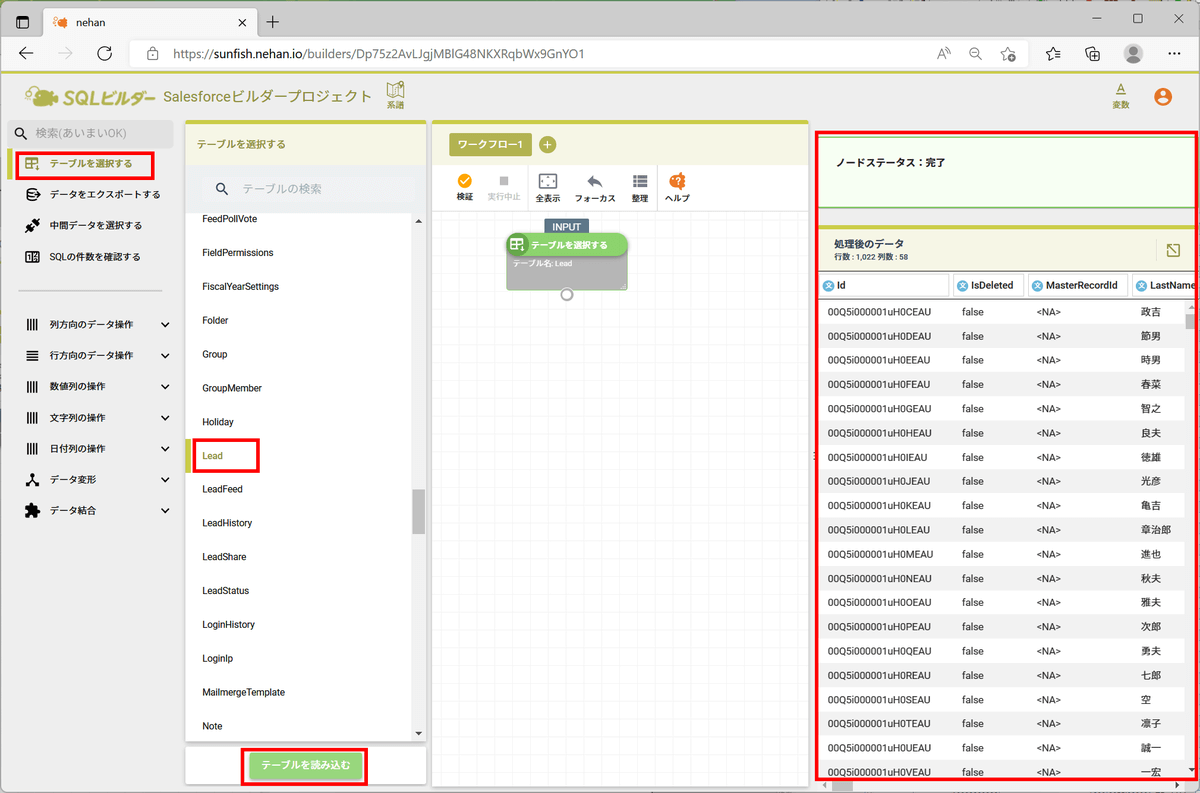
今回はテーブルのデータのうち国が「Japan」のものをデータソースとして使用することにします。左ペインの「行方向のデータ操作」セクションの「条件で行を絞り込み」をクリックし、フィルタ条件を以下のように設定し、「SQLの実行」をクリックします。すると、右側ペインに絞り込み結果が表示されます。今回は1022件中1000件が選択されています。
| 設定項目 |
設定値 |
| 対象列 |
Country |
| 比較タイプ |
等しい(=) |
| 値 |
Japan |
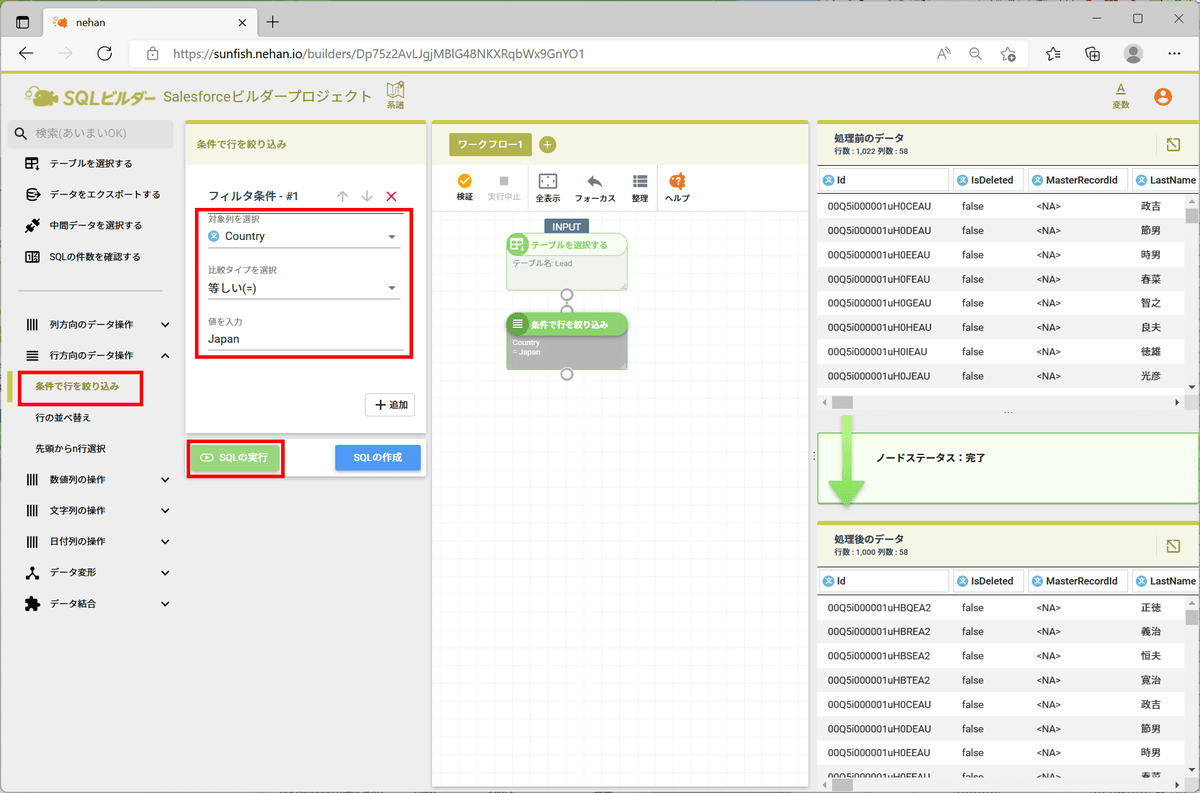
最後に結果をデータソースとして登録します。左ペインの「データをエクスポートする」をクリックし、エクスポート先を「データソースとして登録する」に設定して適当なデータソース名を入力して、「実行」をクリックします。
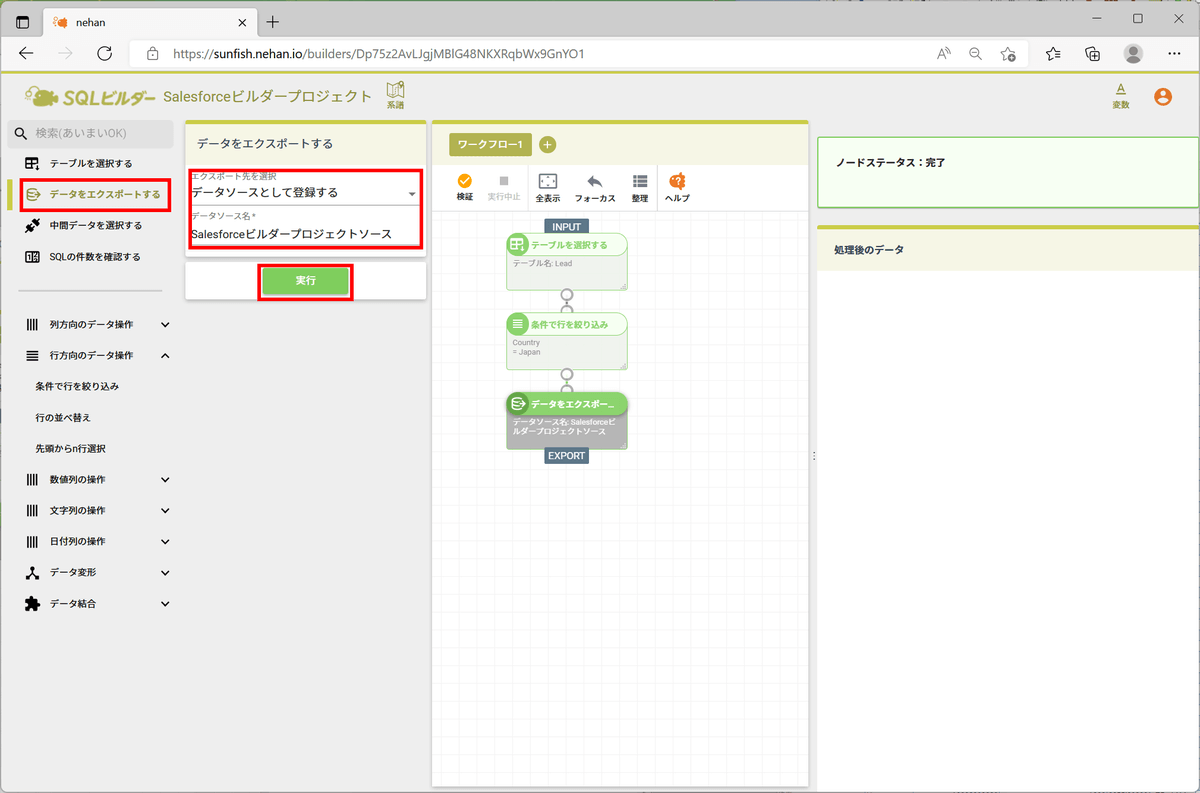
これで、データソースが登録されました。画面左上の「SQLビルダー」をクリックしてトップメニューに戻り、左ペインの「データソース」をクリックすると作成されたデータソースが確認できます。
データ分析プロジェクトの作成
ここまでで分析に用いるデータの準備ができましたので、実際にデータ分析のプロジェクトを作成していきます。
左ペインの「データを分析する」をクリックし、「分析プロジェクトの新規作成」をクリックします。
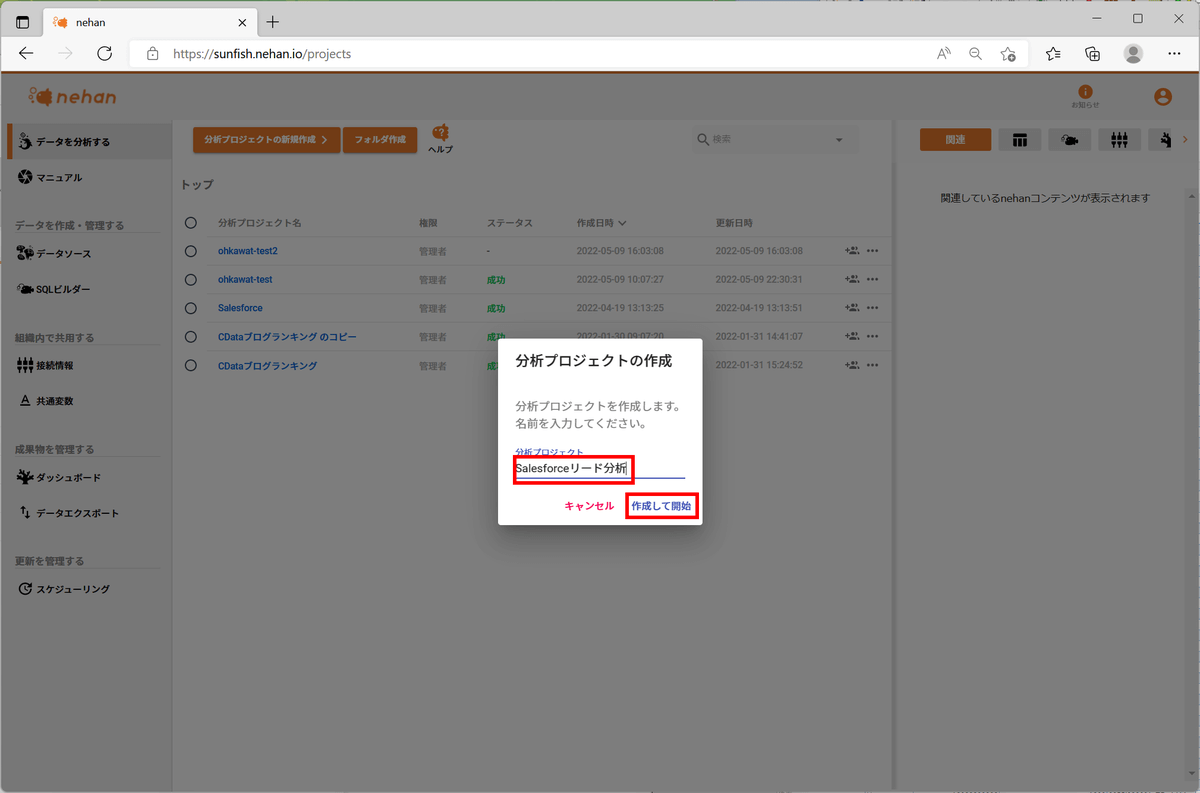
適当な分析プロジェクト名を入力して「作成して開始」をクリックします。
すると以下のようなプロジェクトの作成画面に切り替わります。
機械学習モデルの構築
まずは機械学習モデルを構築していきます。左ペインの「分析するデータを配置する」をクリックすると以下のようなダイアログが表示されます。作成したデータソースを選択すると、右側ペインにデータの内容が表示されますので、確認して「データを読み込む」をクリックします。
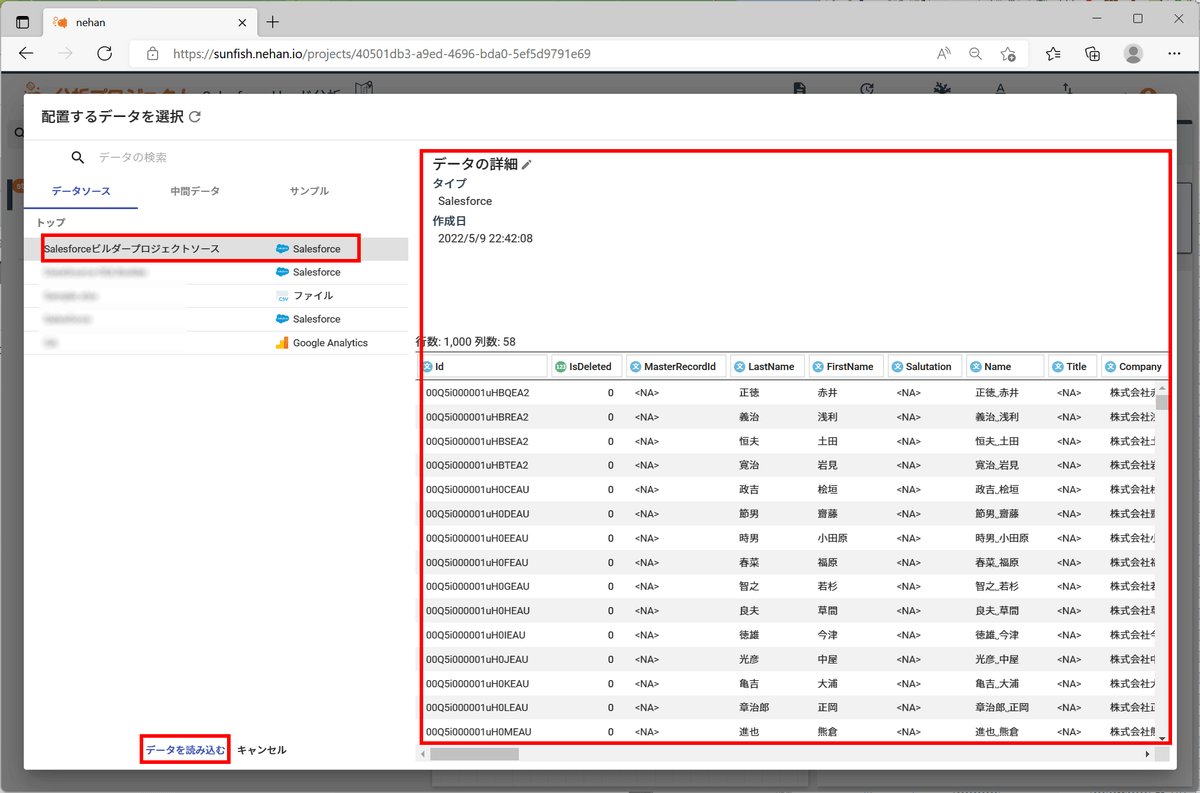
すると以下のようにプロジェクトにノードが追加されます。
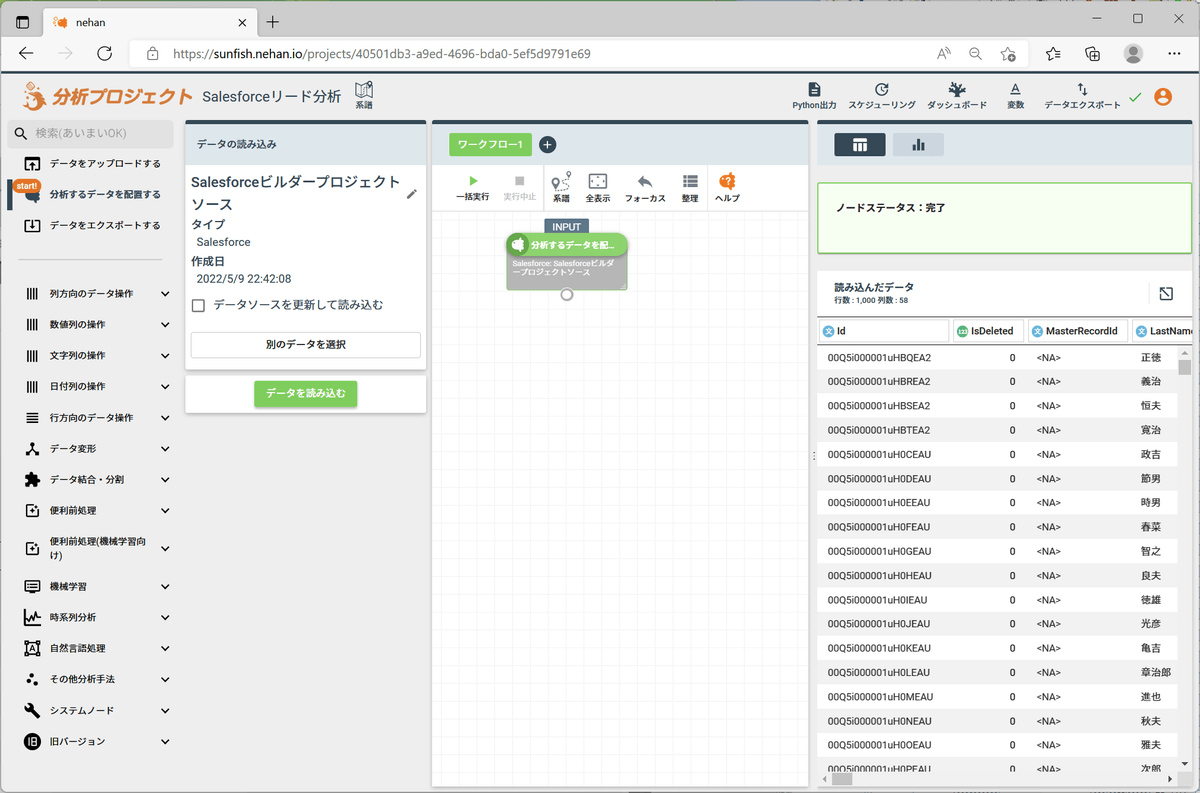
つぎに、カテゴリ変数を数値化します。「LeadSource」「Industry」「Rating」をOne-hotベクトル化(ダミー変数化)します。左ペインの「便利前処理(機械学習向け)」セクションの「ダミー変数列の作成」をクリックし、「列選択」をクリックします。
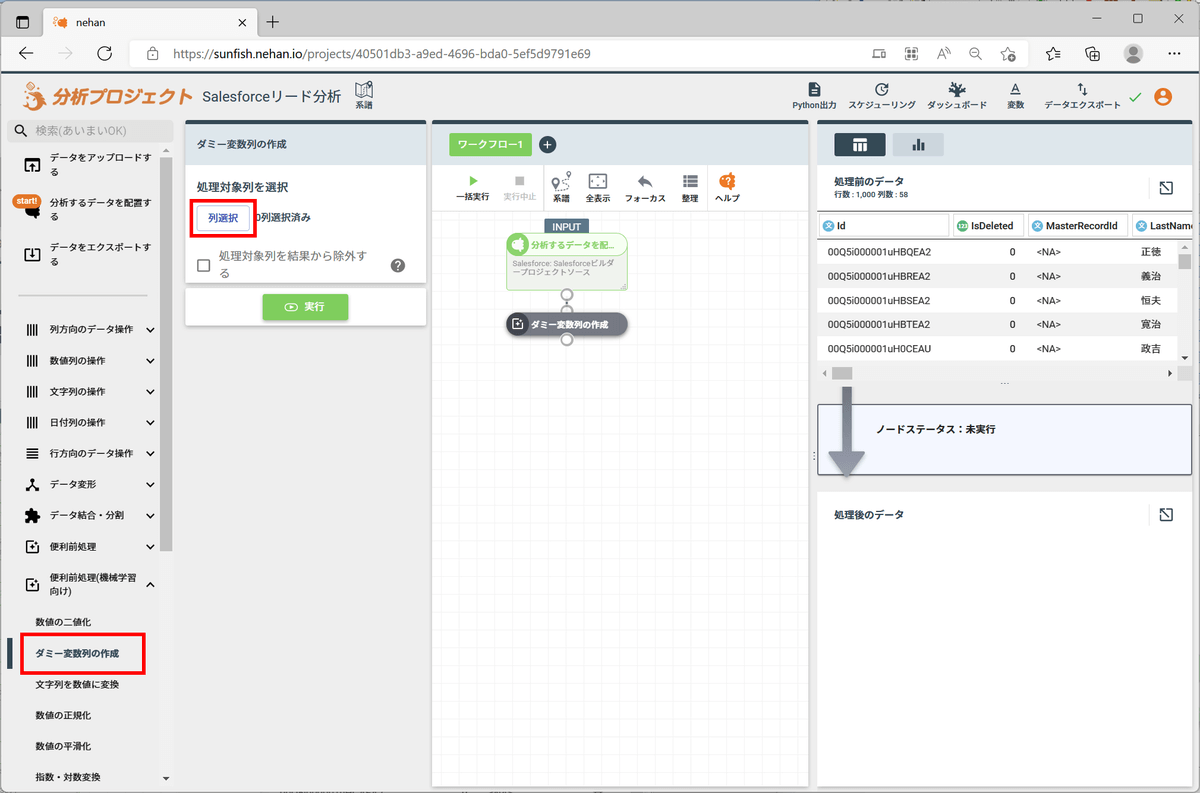
列名の指定で「LeadSource」「Industry」「Rating」を選択し、「OK」をクリックします。
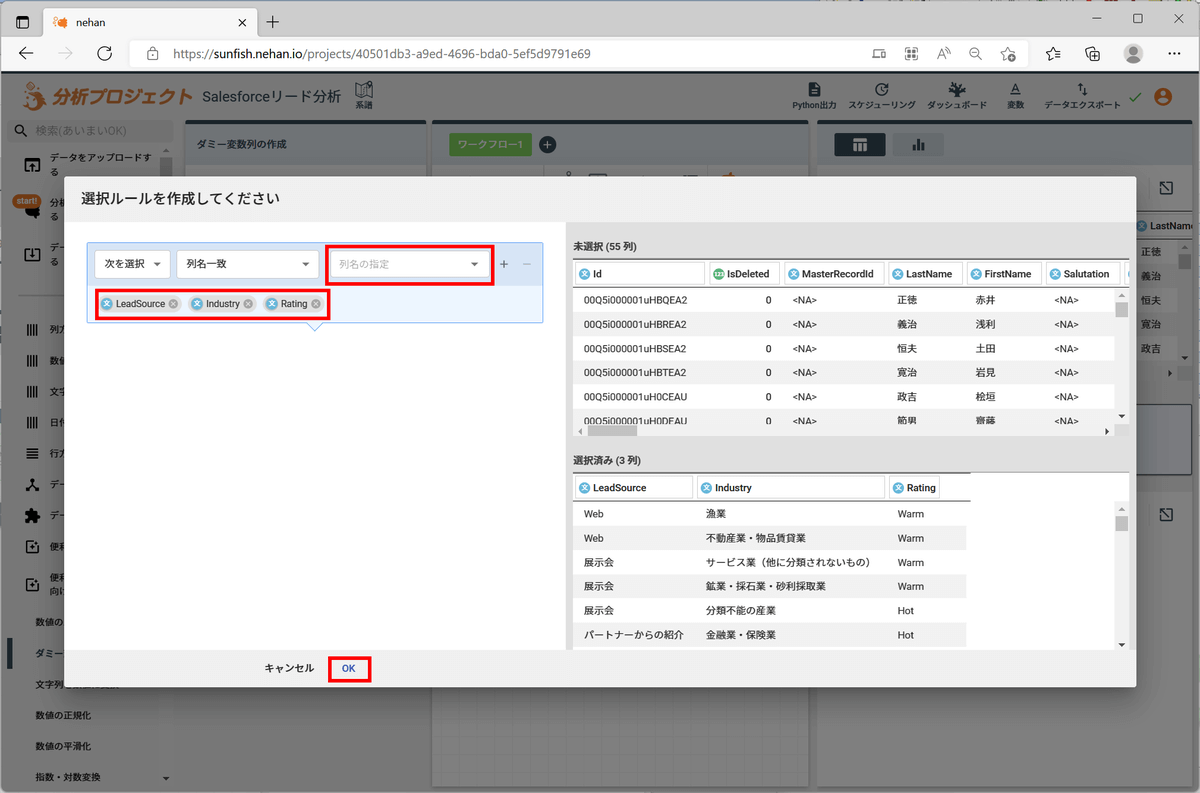
つづいて、学習データを抽出します。今回は「Status」列の文字列が「Closed」で始まっているものが学習データとなります。
左ペインの「行方向のデータ操作」セクションの「条件で行をフィルタ」をクリックし、フィルタ条件を以下のように設定して「実行」をクリックします。
| 設定項目 |
設定値 |
| 対象列 |
Status |
| 比較タイプ |
[条件値]から始まる(starts_with) |
| 条件値 |
Closed |
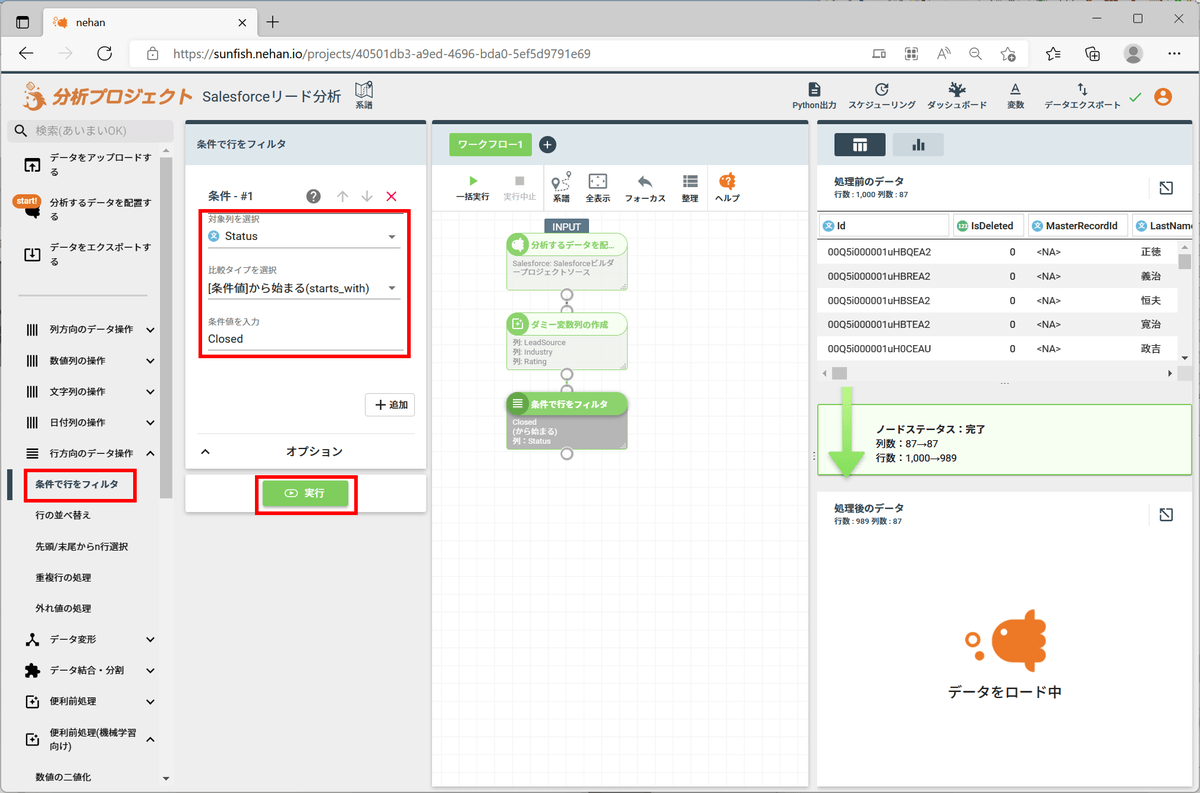
これで、目的変数であるStatus列の値は「Closed - Not Converted」と「Closed - Converted」の2種類のみとなります。これを数値化します。
左ペインの「便利前処理(機械学習向け)」セクションの「文字列を数値に変換」をクリックし、列選択で「Status」を選択して「実行」をクリックします。これで、「Status_変換後」という列に変換後の値が格納されます。
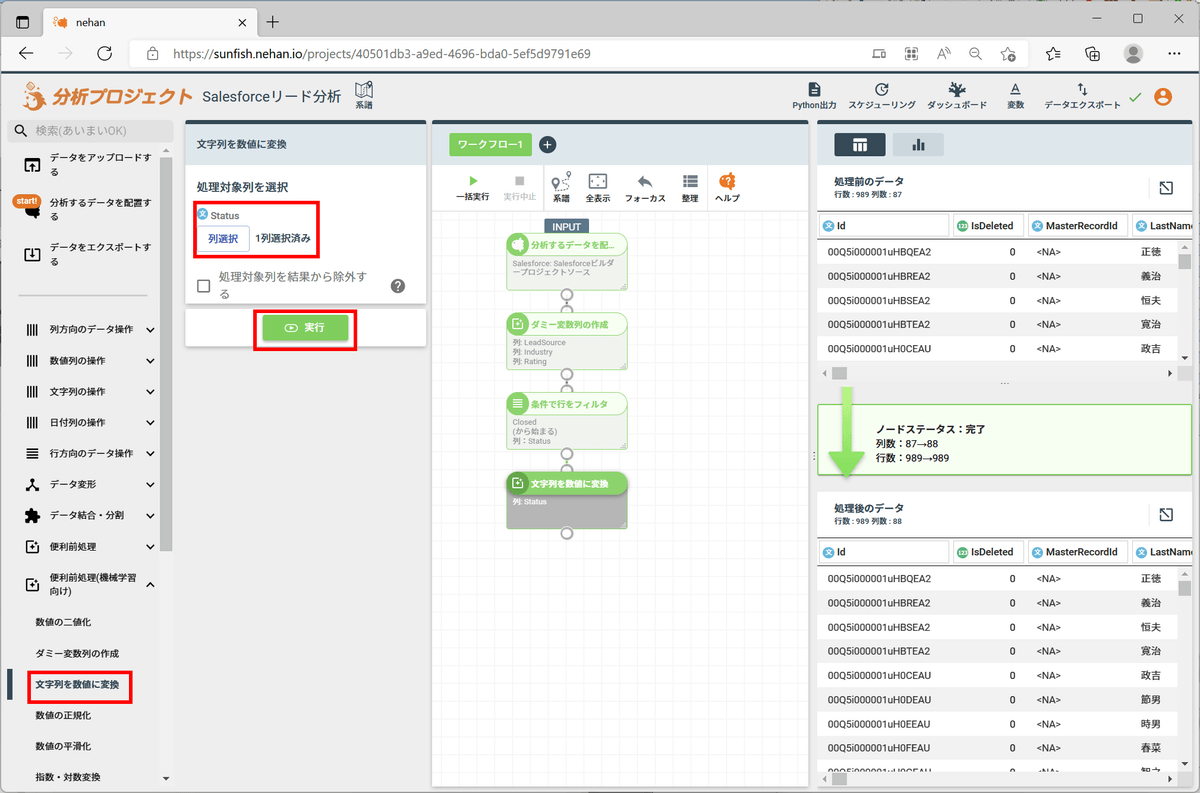
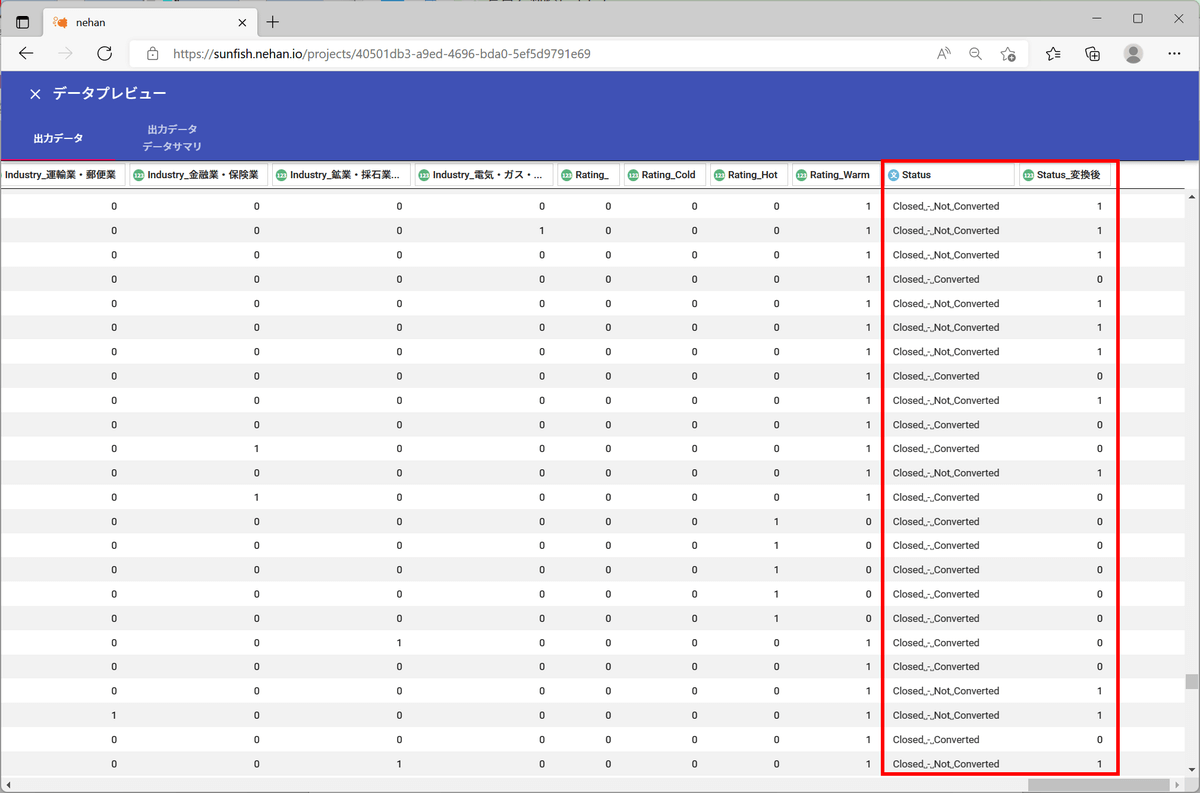
データのプレビューを確認すると、以下のように変換されていることが分かります(辞書順)。
| 「Status」列 |
「Status_変換後」列 |
| Closed - Converted |
0 |
| Closed - Not Converted |
1 |
ここまでで学習データの前処理は完了です。ロジスティック回帰モデルを適用します。
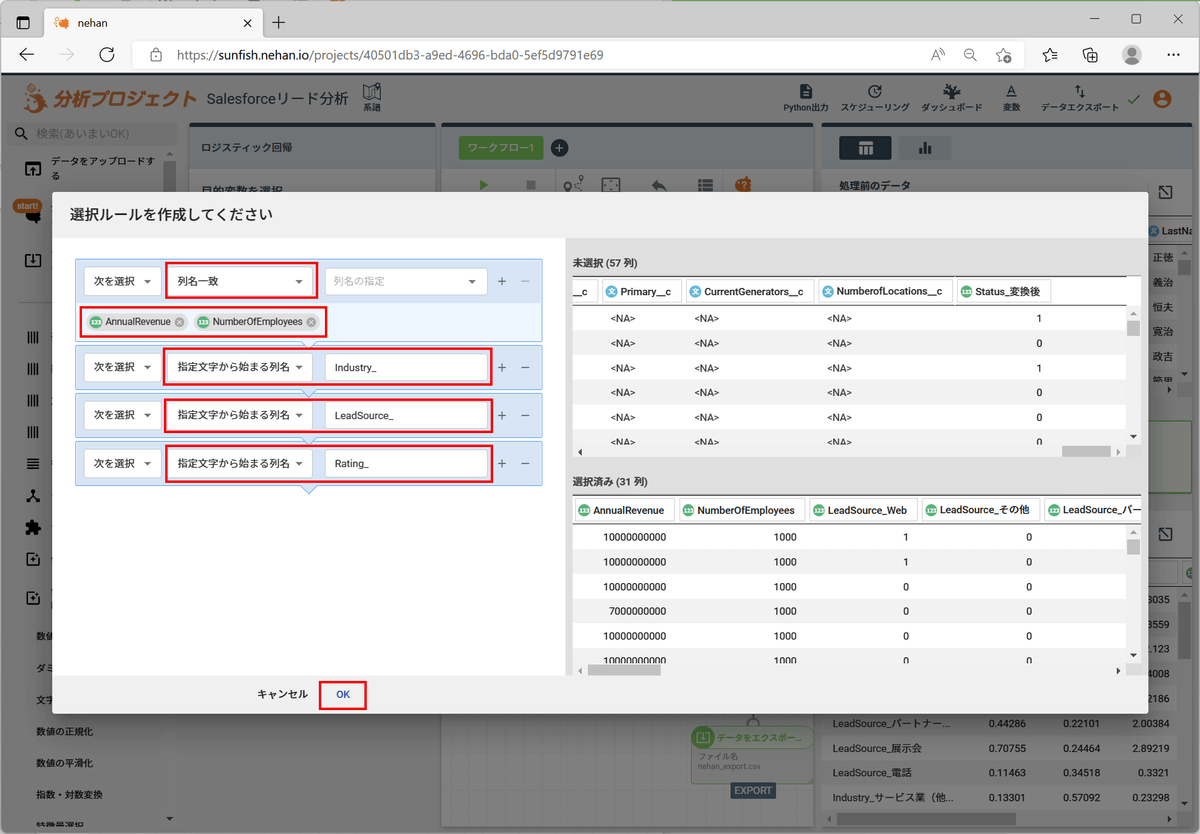
左ペインの「機械学習」「教師あり学習」セクションの「ロジスティック回帰」をクリックし、目的変数に「Status_変換後」を選択します。また、「列選択」をクリックして説明変数となる列を以下のように設定して「OK」をクリックします。
| 選択ルール |
設定値 |
| 次を選択:列名一致 |
AnnualRevenue, NumberOfEmployees |
| 次を選択:指定文字から始まる列名 |
Industry_ |
| 次を選択:指定文字から始まる列名 |
LeadSource_ |
| 次を選択:指定文字から始まる列名 |
Rating_ |
ダミー変数化した列はこのように「指定文字から始まる列名」を使うと、カテゴリ変数の種類が増えて列が増えた場合にも都度追加する必要がなくなります。
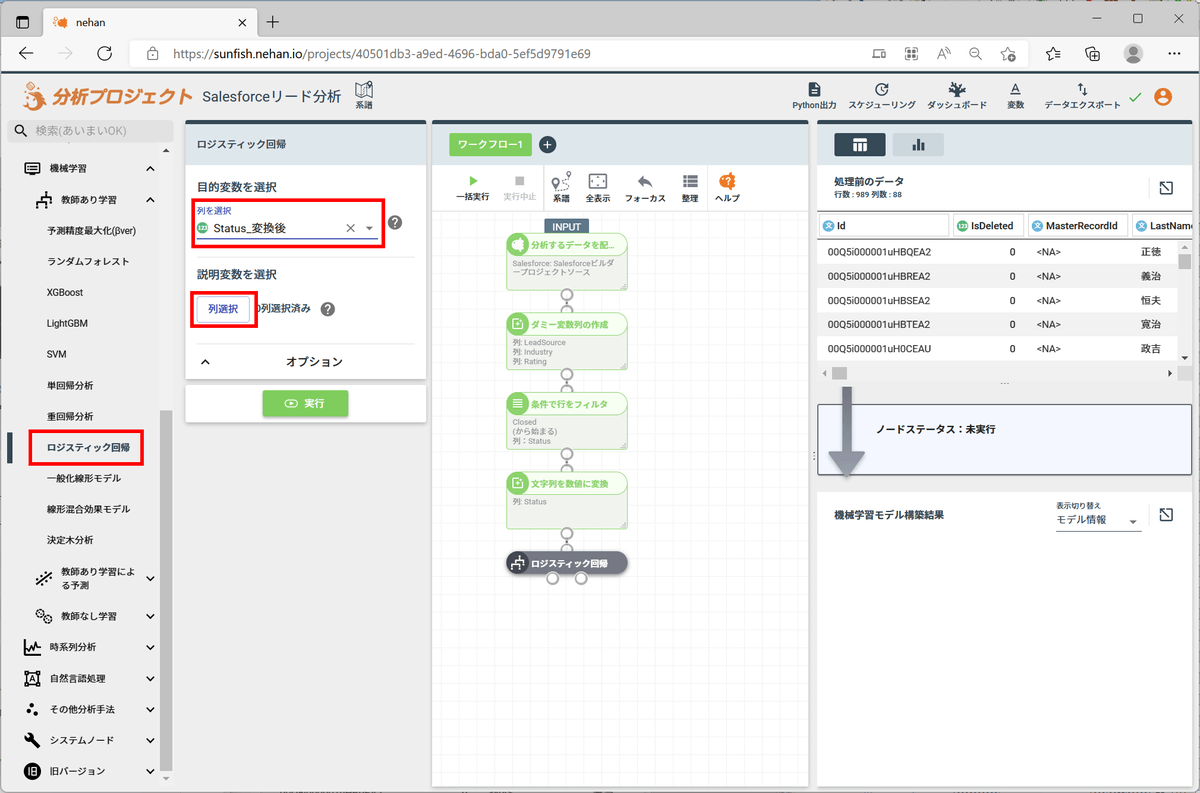
最後に「実行」をクリックすることで、機械学習モデルが構築されます。
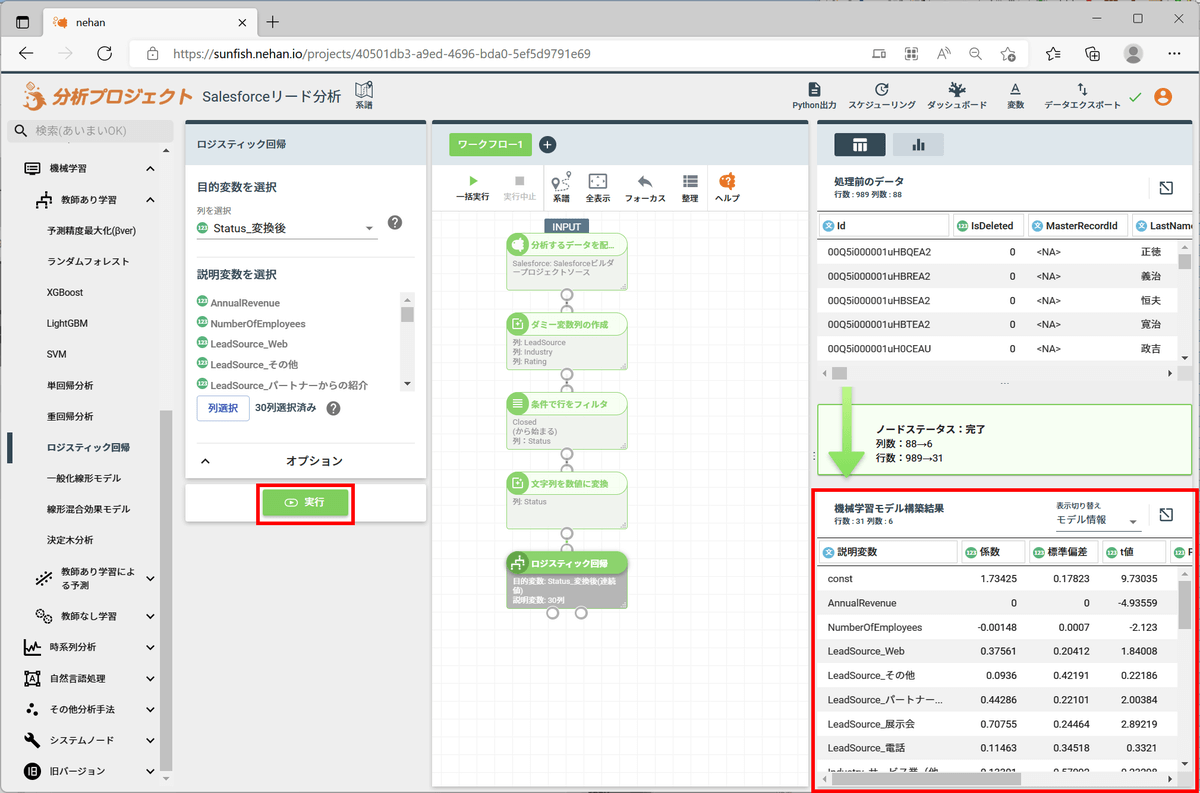
予測対象のデータに構築したモデルを適用
予測対象のデータは「Status」列の文字列が「Closed」で始まっていないデータになります。予測対象のデータを抽出します。
「ダミー変数列の作成」ノードをダブルクリックして選択します。
左ペインの「行方向のデータ操作」セクションの「条件で行をフィルタ」をクリックし、フィルタ条件を以下のように設定して「実行」をクリックします。
| 設定項目 |
設定値 |
| 対象列 |
Status |
| 比較タイプ |
[条件値]から始まる(starts_with) |
| 条件値 |
Closed |
| オプション |
「条件に一致しないデータを残す」にチェック |
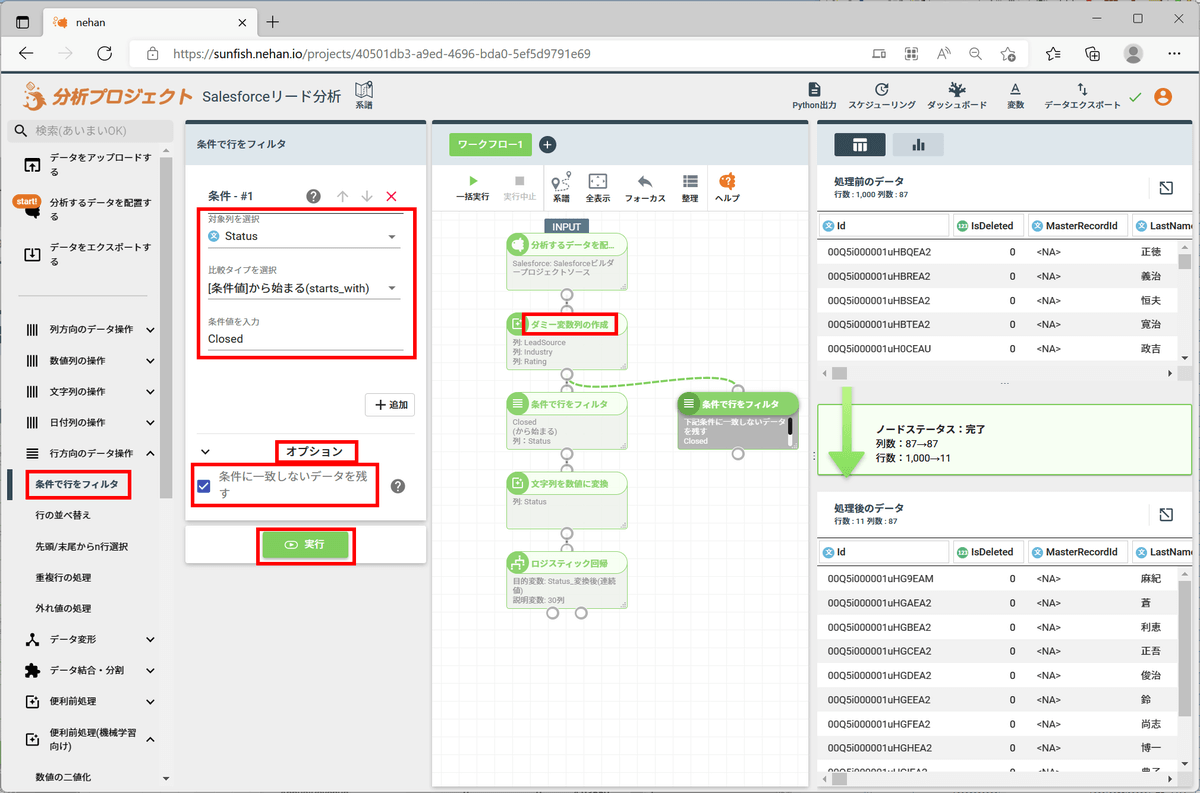
これで抽出された予測対象データに対し、構築済みの機械学習モデルを適用します。
左ペインの「機械学習」「教師あり学習による予測」セクションの「モデルで予測値算出」をクリックします。すると入力データは自動的に先ほどフィルタリングしたデータになりますので、「ロジスティック回帰」ノードの「機械学習モデル」出力(ノード下部の左側の接続ポイント)を「モデルで予測値算出」ノードの「機械学習モデル」入力(ノード上部の左側の接続ポイント)にドラッグして接続します。
その後、「実行」をクリックすると予測対象データに機械学習モデルが適用され、「予測値」列が追加されたデータが出力されます。
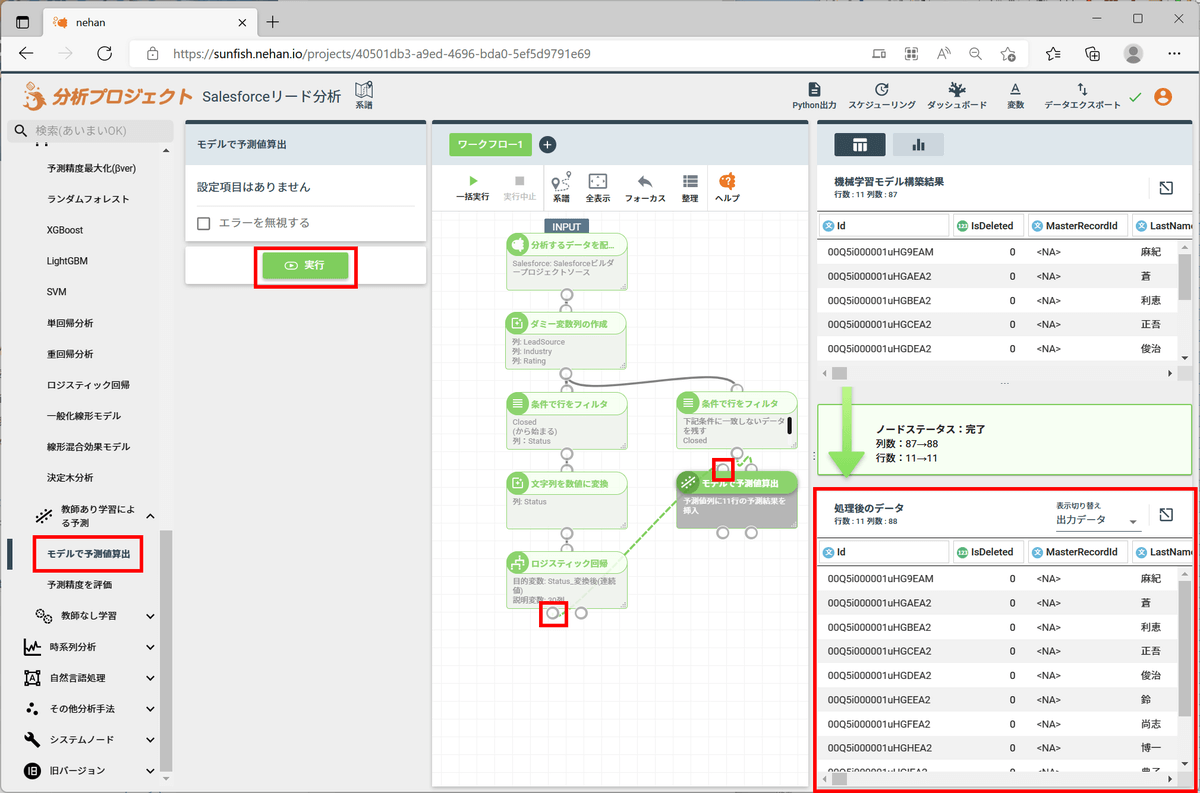
データをプレビューしてみると、「予測値」列に数値が出力されていることが確認できます。
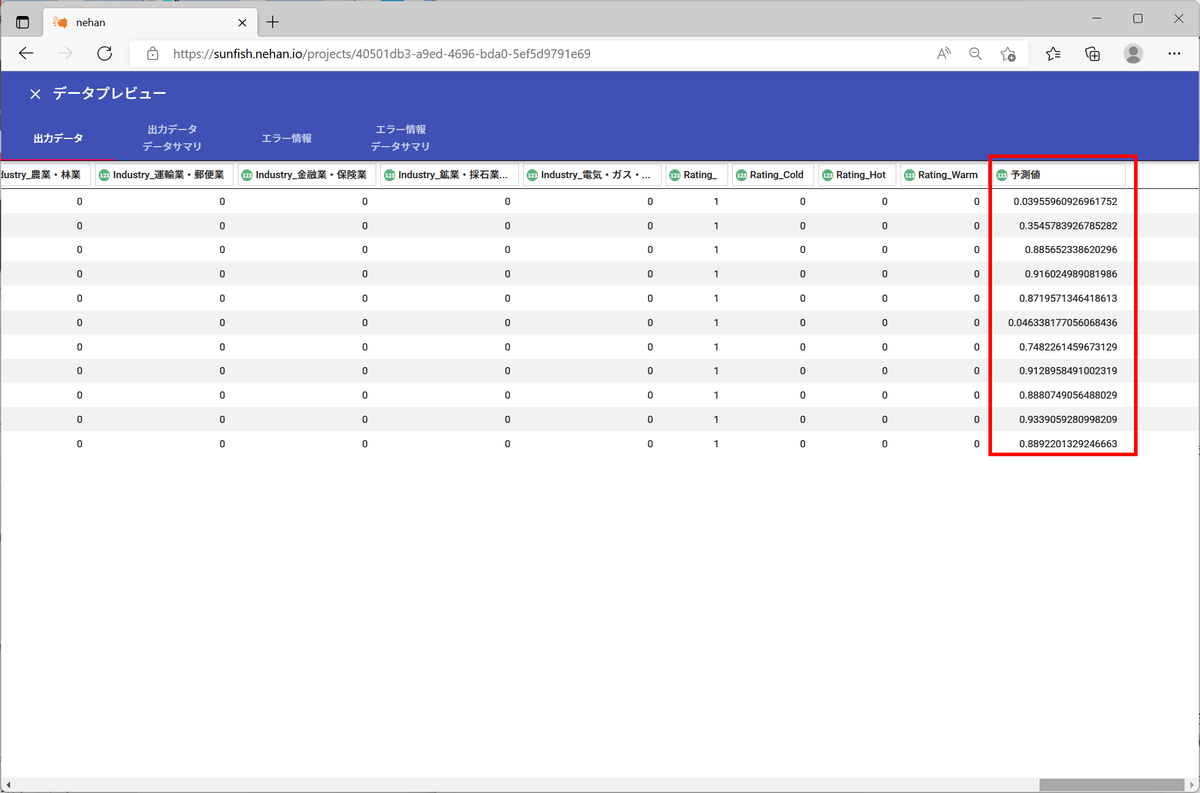
目的変数は0が「Closed - Converted」、すなわち取引に繋がったリードであり、1が「Closed - Not Converted」、すなわち取引には繋がらなかったリードとなります。よって、「予測値」が0に近ければ取引に繋がりやすいリード、という予想になります。
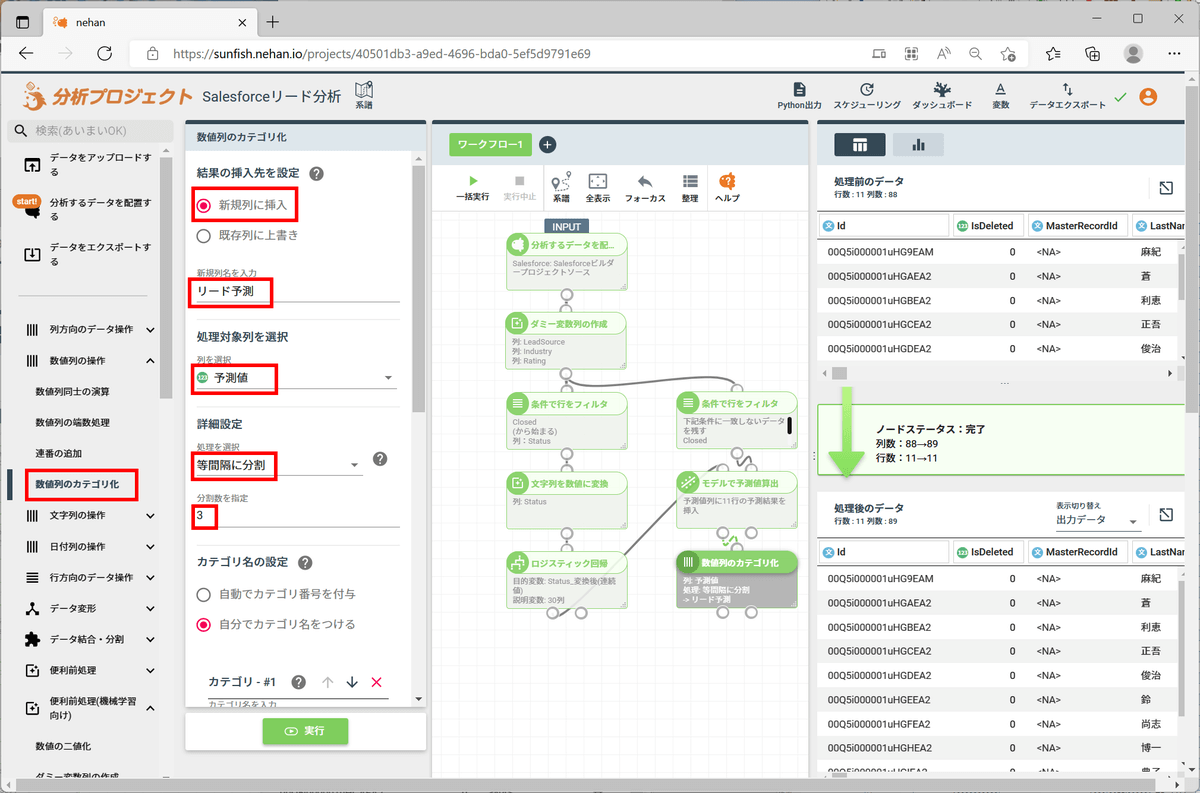
わかりやすいようにこの「取引への繋がりやすさ」を「高」「中」「低」に分けてみます(ここでは簡単のため「等間隔に分割」を使いますが、実際の分析では分割方法を吟味してください)。
左ペインの「数値列の操作」セクションの「数値のカテゴリ化」をクリックし、以下のように設定して「実行」をクリックします。
| 設定項目 |
設定値 |
| 結果の挿入先 |
新規列に挿入 |
| 新規列名 |
リード予測 |
| 処理対象列 |
予測値 |
| 詳細設定処理 |
等間隔に分割 |
| 分割数 |
3 |
| カテゴリ名の設定 |
自分でカテゴリ名を付ける |
| カテゴリ#1 カテゴリ名 |
高 |
| カテゴリ#2 カテゴリ名 |
中 |
| カテゴリ#3 カテゴリ名 |
低 |
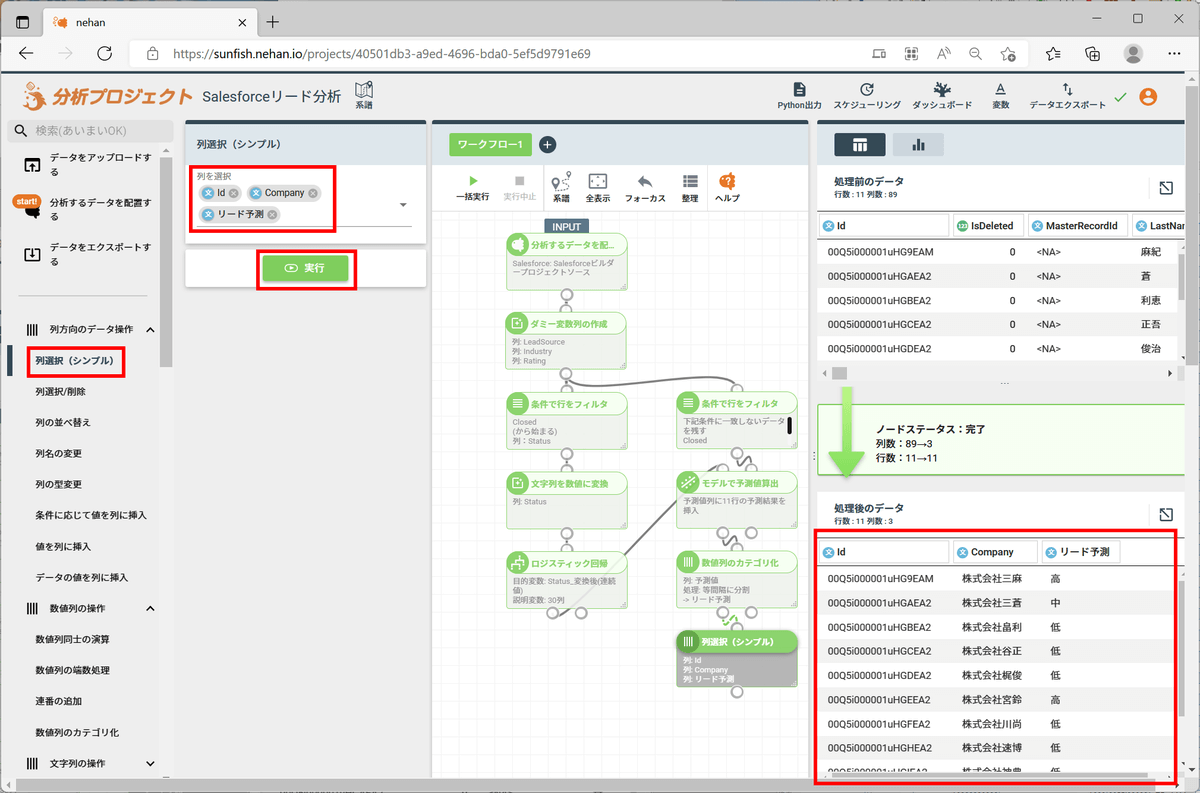
更に、列選択で結果を見やすくしてみます。
左ペインの「列方向のデータ操作」セクションの「列選択(シンプル)」をクリックし、「Id」「Company」「リード予測」の列を選択して「実行」をクリックすると、画面右下に会社名とリード予測が表示されます。
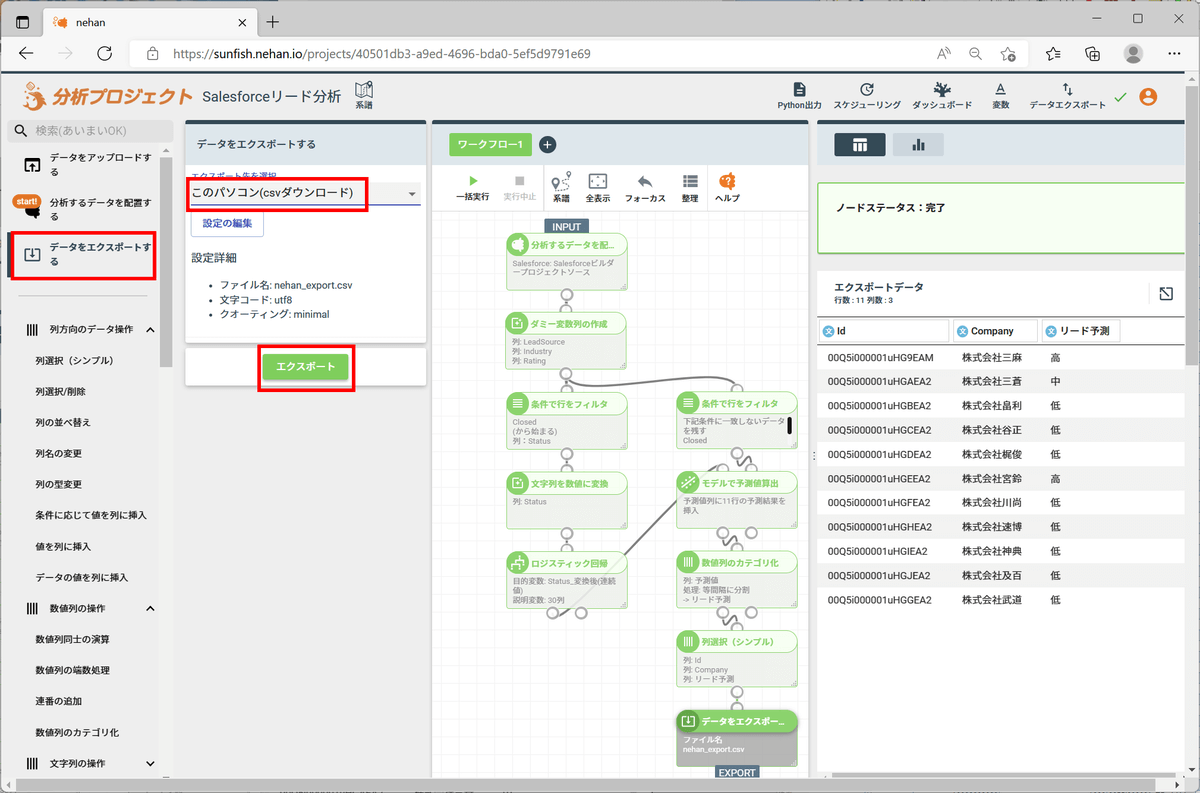
最後に結果をCSVファイルに出力してみます。左ペインの「データをエクスポートする」をクリックし、エクスポート先に「このパソコン(csvダウンロード)」を選択して「エクスポート」をクリックすると、CSV結果のCSVファイルをダウンロードできます。
さいごに
以上のように、nehanを使用すると一切コードを書かずに高度な分析処理を行うことが可能です。私はこのような機械学習によるデータ分析処理を初めて経験しましたが、GUI上でとても簡単に処理を構築することができることに感銘を受けました。またスクリーンショットをご覧になってもわかるように大変すぐれたUIとなっており、初めての方でもすぐに分析処理が出来るようになると思います。
今回ご紹介したnehanについては以下のサイトにより詳しい情報がありますので、同じような分析をしたい!という方はnehan社にお問い合わせしてみてはいかがでしょうか。
nehan.io
関連コンテンツ



