各製品の資料を入手。
詳細はこちら →


PyCaretとPower BI Desktopでトピック分析:CData Sync
皆さんこんにちは。CData Software Japanインサイドセールスの加藤です。
文書データがたくさんあるけど、ここからどうやってインサイトを引き出したらいいんだろう?文書データの特徴をまとめてきれいに可視化したい。こんなお悩みはありませんか?この記事ではPower BI Desktop とPython ライブラリのPyCaret、CData Sync を組み合わせ、ローコードで簡単に文書データのトピック分析をする方法をご紹介します。データはarXiv という論文ホスティングサイトからAPIに関する最新論文を取得して分析していきます。

目次
PyCaretとトピックモデル
PyCaretとは?
PyCaret は、ローコードで機械学習モデルを実装できるPythonライブラリです。回帰や分類用のモデル自体はもちろん、前処理、モデルの訓練、評価といった機械学習のパイプライン構築のための基本的なツールセットがすべて揃っています。今回はこのライブラリのNLPモジュール上のトピックモデルを使用します。今回はマシンにPython環境が整っていることは前提とします。
トピックモデルとは?
文書データが手元にあったら、まず知りたいのは文書中でどのような内容が扱われているか、ではないでしょうか。こうした分析を行うための有効な手段として、トピックモデルがあります。トピックモデルとは、文書が様々な「トピック」(話題、主題)から構成されると考え、そうしたトピックを推定することを目的としたモデルです。例えば、WikipediaのAPIの記事は、「ウェブサービス」、「システム」、「プロトコル」などのトピックから構成されると考えてもよいでしょう。
トピックモデルで扱われるトピックとは、より正確には単語の確率分布のことです。例えば、「OAuth」、「認証」、「Web」などの単語の出現確率が高い確率分布は、「API」というトピックのことだ、と考えられます。トピックモデルにはLatent Dirichlet Allocation (LDA)、Latent Semantic Indexing (LSI)などいくつか種類がありますが、基本的には文書中での単語の出現頻度をもとに確率分布を推定します。文書Aでは「OAuth」という語が5回現れた、文書Bでは0回だった、といった情報を使うわけですが、使い方は手法によって様々です。より詳しくは、例えばこちらのスライドなどが参考になります。
まとめると、トピックモデルは文書中での単語の出現頻度を参考に各単語を「トピック」と呼ばれる確率分布に分類していく手法です。
CData Sync からarXivの最新論文を取得
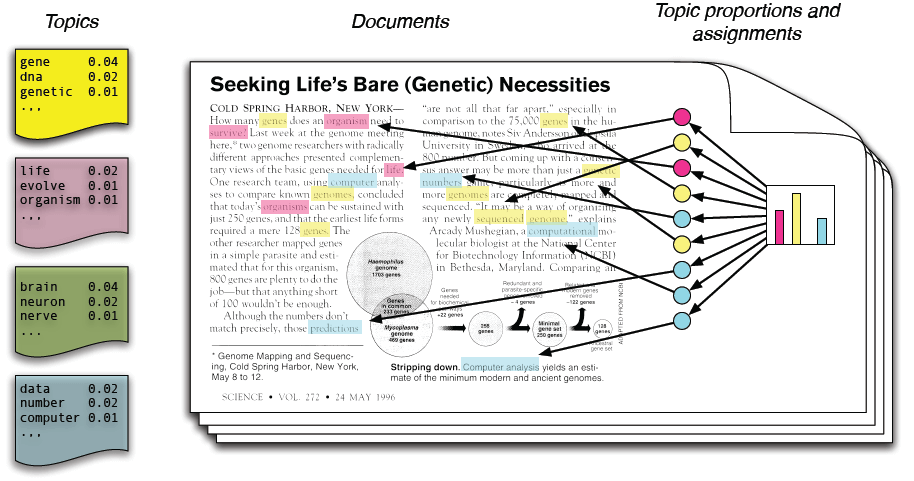
CData Sync の基本的なセットアップについては、例えば[こちらの記事(https://www.cdata.com/jp/blog/arxiv_csv)をご覧ください。今回は、弊社リードエンジニアの杉本さんがarXivのAPI Profileを用意してくださったので(感謝!こちらからダウンロードできます)それを使って論文を取得するための設定をしてみます。「...CData Sync\www\app_data\profiles」に適切に作成した.apipファイルを配置することで自分で作成したAPI 連携を追加することができます。CData Sync の「接続」タブを開くと、確かに「arXiv Profile」という名前のデータソースが追加されています。

それではアイコンをクリックして設定していきます。といっても、Advanced タブからURLに「http://export.arxiv.org/api」を追加するだけです。
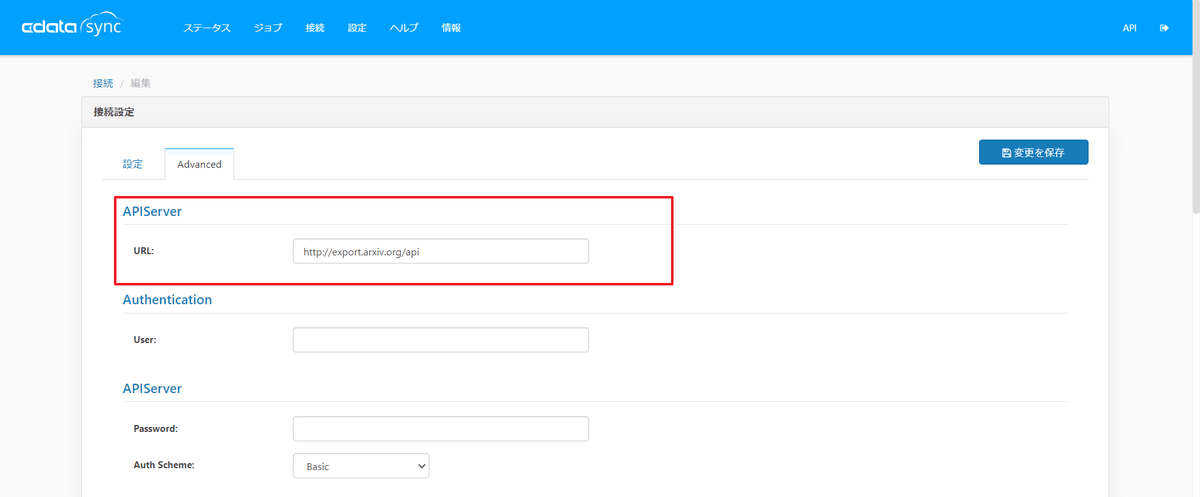
テストも成功です。
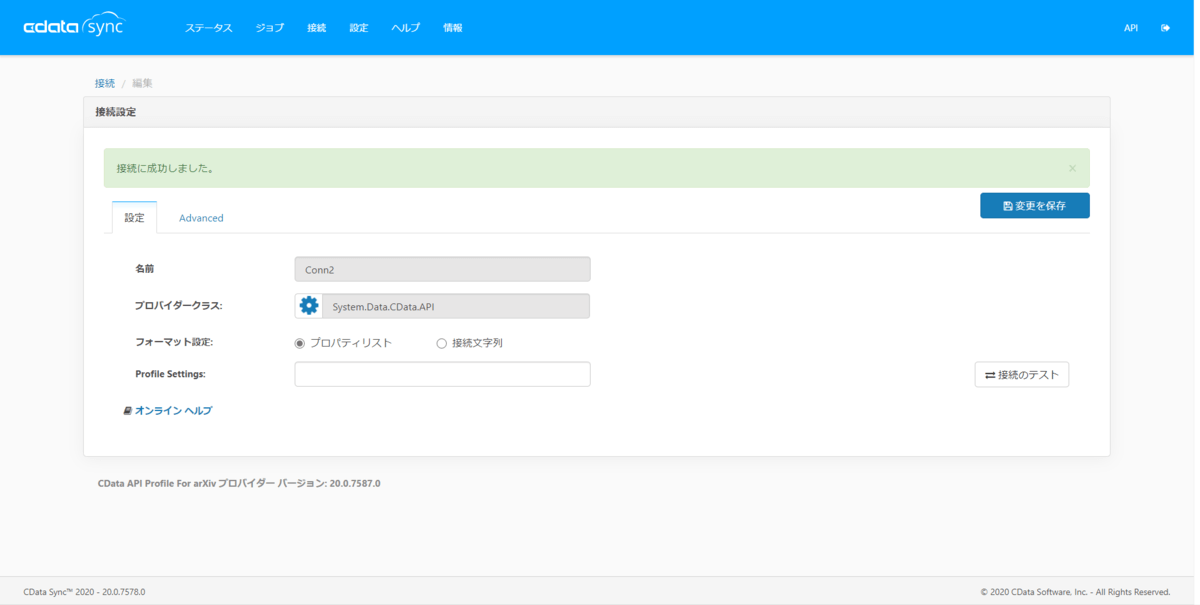
それでは「ジョブ」タブから新しいジョブを作成してきます。今回はローカルのCSVファイルにデータを連係します。
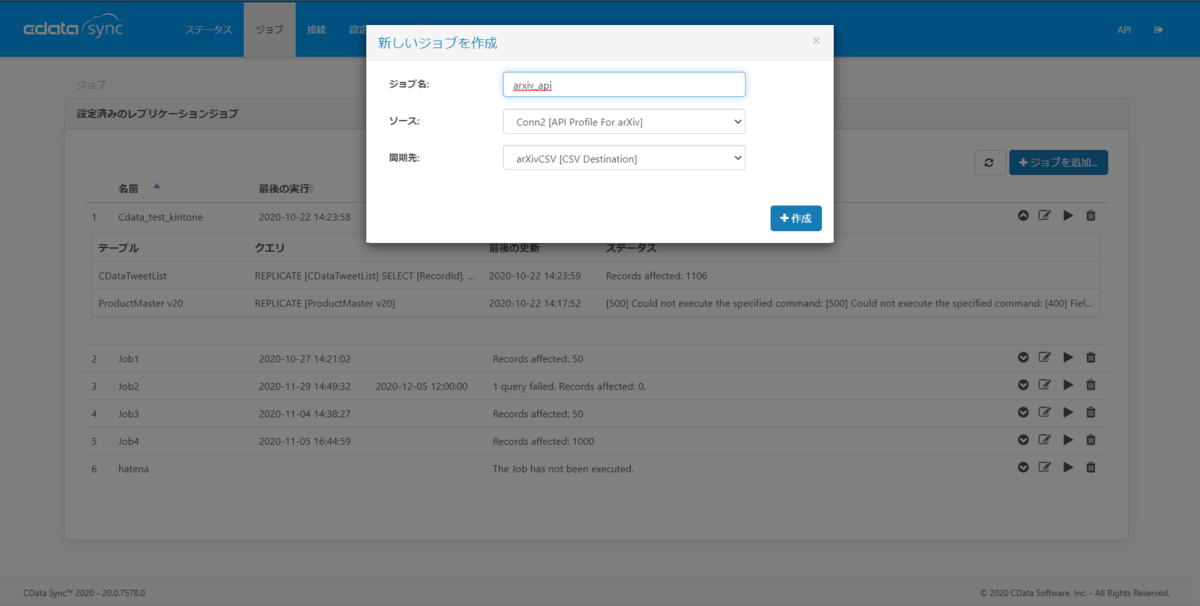
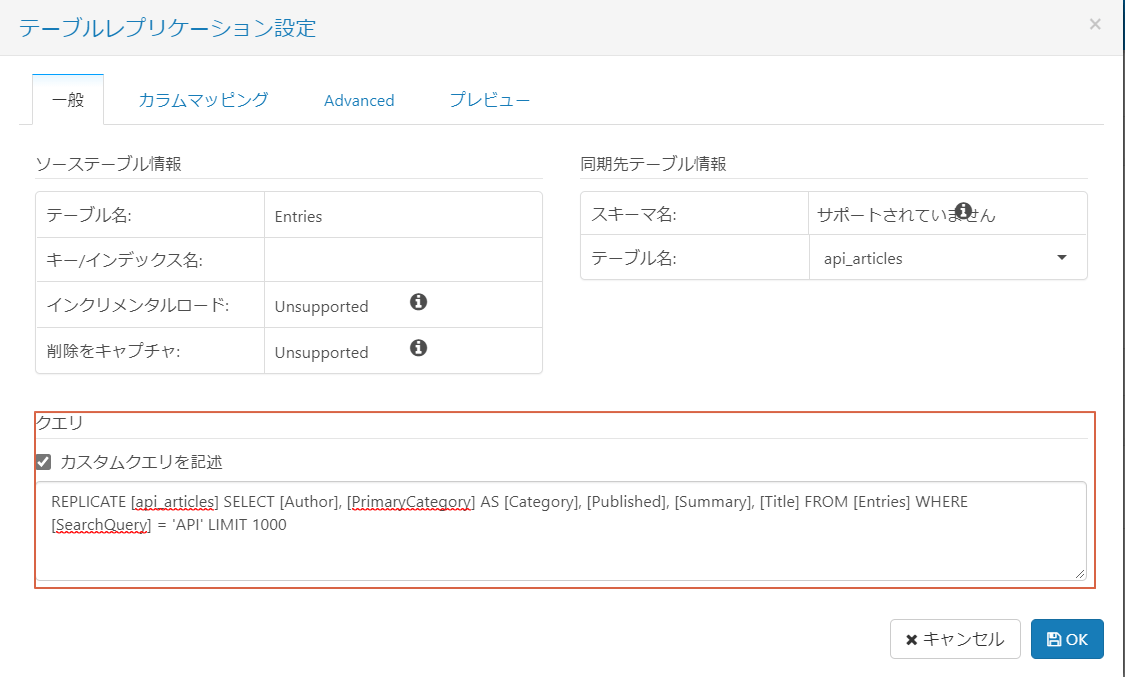
以下のようなカスタムクエリを使用します。今回はタイトルに"API"を含む論文を取得して分析します。
REPLICATE [api_articles] SELECT [Author], [PrimaryCategory] AS [Category], [Published], [Summary], [Title] FROM [Entries] WHERE [SearchQuery] = 'API' LIMIT 1000
分析に必要となりそうなカラムだけを残していること、WHERE句で検索用のクエリ("API")を設定していることに注意してください。このクエリにマッチした論文のデータを取得します。
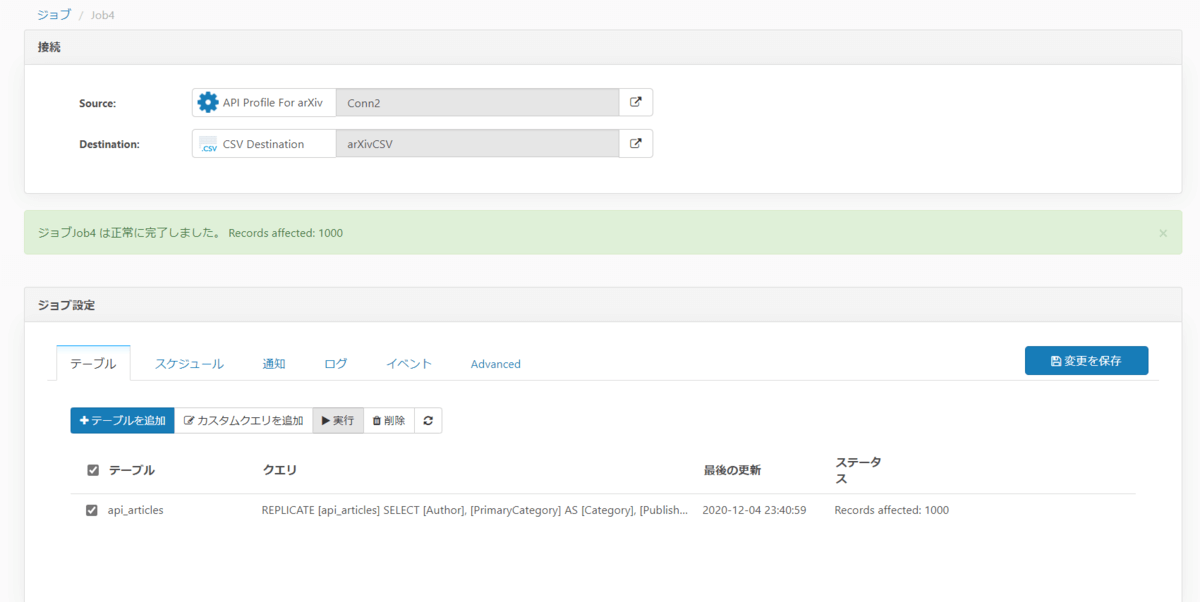
「OK」を押して「実行」すると、無事にジョブが実行されました。CData Sync ではジョブを定期的に実行する設定もできるので、例えば一週間毎にデータを取得してその都度新しいデータに分析を適用する、といった運用もできるでしょう。
Power BI Desktopへのデータ読み込みと分析
PyCaretのインストールとPower BI Desktopの設定
まずはPyCaretをインストールしましょう。pipからインストール可能です。
pip install pycaret
それではPower BI Desktopを立ち上げましょう。Power BIからPythonスクリプトを使用するので、そのための設定をします。「ファイル」メニューを開いて、「オプションと設定」→「オプション」と進みます。
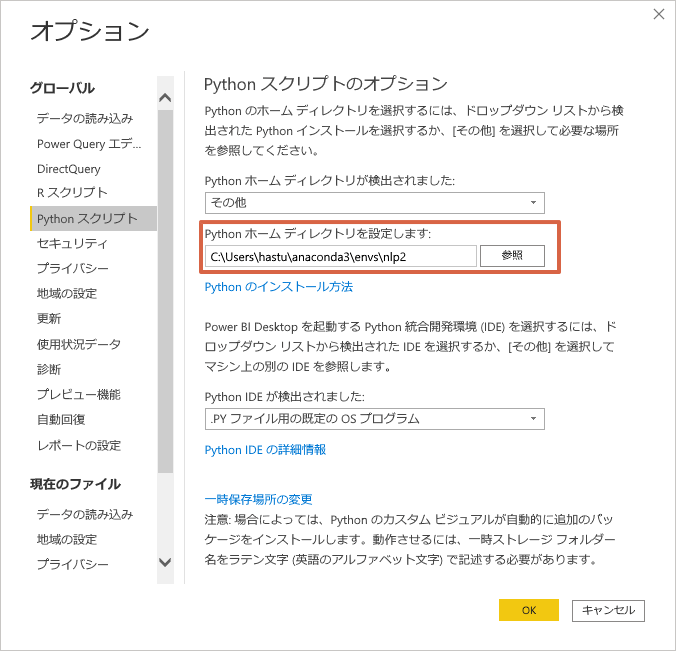
オプション画面が表示されるので、自身のPythonバイナリがあるディレクトリを設定しましょう。以上で基本設定は完了です。
データの読み込みと変換
Power BI Desktopのスタート画面(または上部のリボン)から「データを取得」を選択し、「データを取得」画面が表示されたら「テキスト/CSV」を選択します。
CData Syncで連携したCSVファイルを選択しましょう。取得した論文のデータが表示されます。今回はこのデータにPython スクリプトを適用して変換していくので、読み込まずに「データの変換」をクリックしましょう。データが表示されたら、「変換」タブから「Pythonスクリプトを実行」をクリックしましょう。
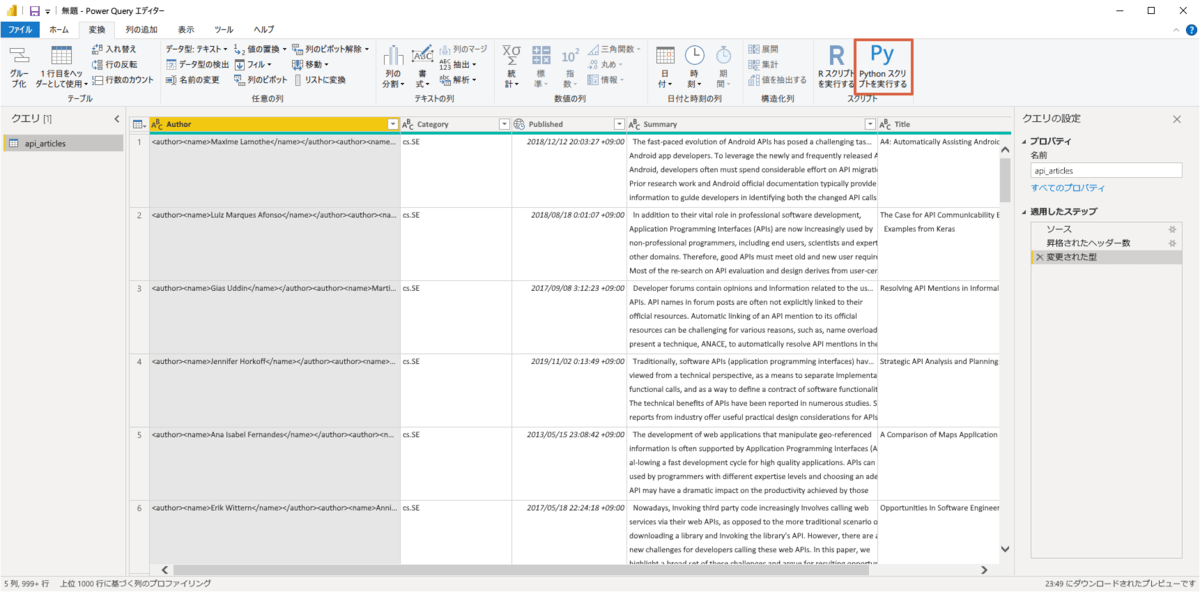
モデルの学習・トピックの推定に必要なのは以下の二行のコードだけです。
from pycaret.nlp import * dataset = get_topics(dataset, text='Title', model='lda', num_topics=4)
一行目でPyCaretのNLP モジュールから全ての関数を呼び出し、二行目でデータからトピックを推定しています。"text"パラメータに学習に使用するカラム名を、"num_topics"パラメータでトピックの数を指定します。今回は各論文のタイトルをデータとして扱います。トピックモデルを学習する際に最適なトピックの数はデータによって変わってきます。今回は4としています。PyCaretではLDA、LSIなどいくつかのトピックモデルが実装されていますが、今回はスタンダードなLDAを使用します。
無事学習・推定が終わると"Topic_[数字]"、"Dominant Topic"、"Perc_Dominant_Topic"といったカラムが追加されています。"Topic_[数字]"のカラムは、その行のデータがどの程度の確率であるトピックに所属していると推定されたか、"Dominant Topic"はその確率が最も高いトピックの番号を表示しています。
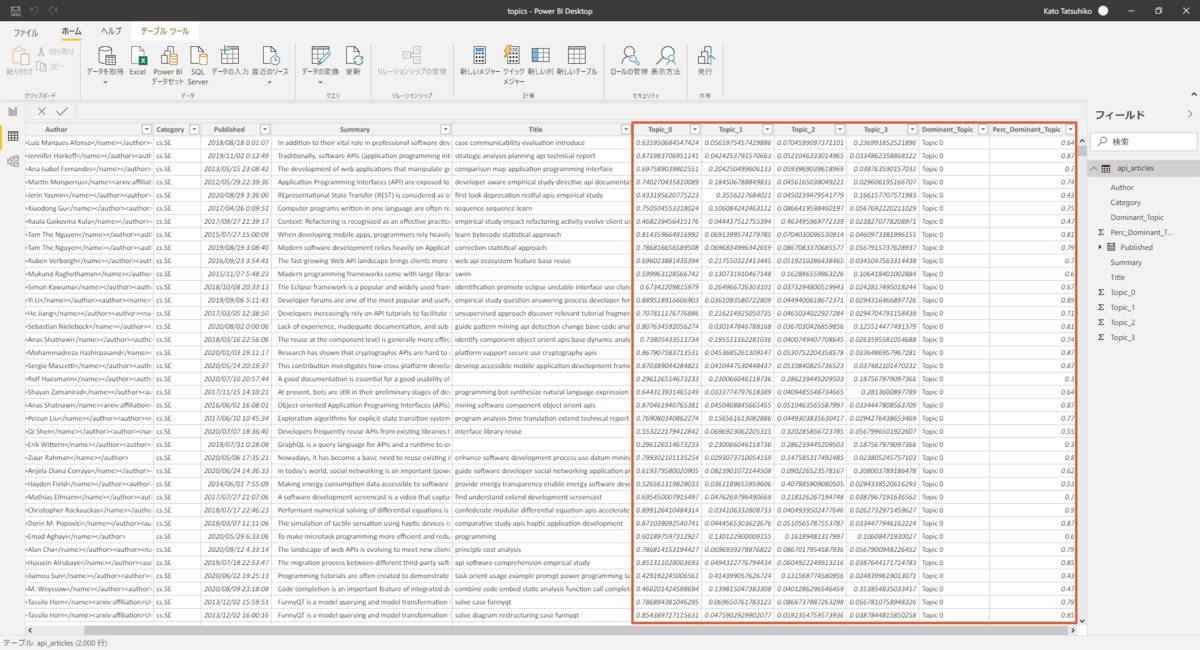
分析・可視化
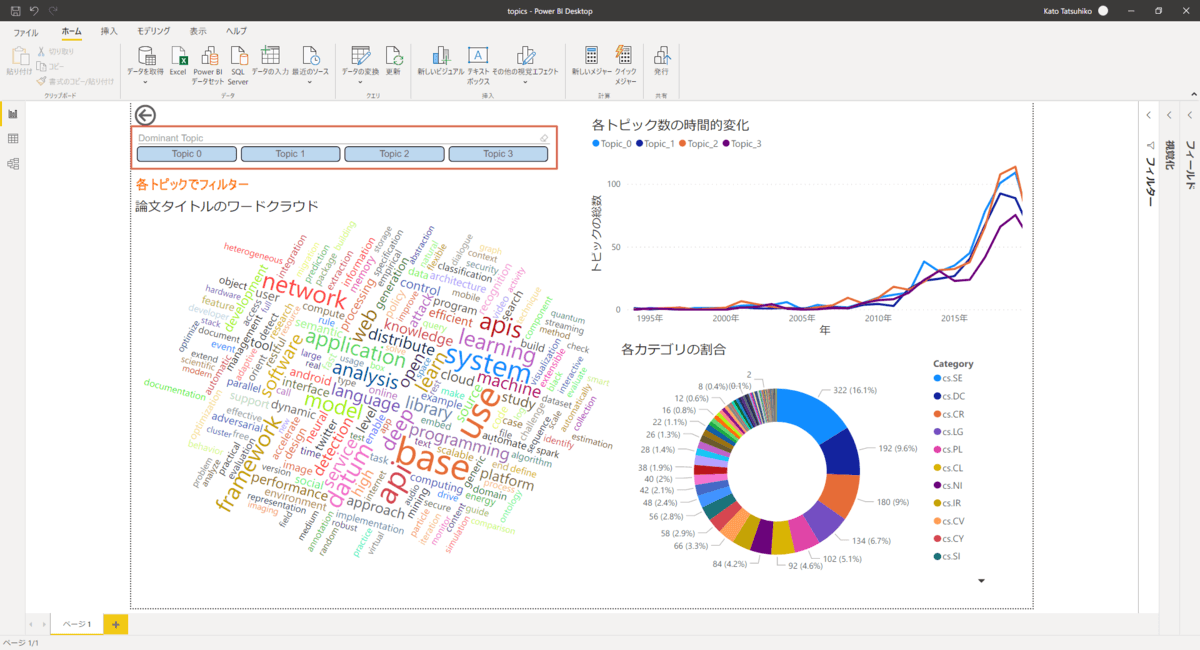
作成したダッシュボードです。ワードクラウドと左上のフィルタボタンで各トピックがどのような特徴を持っているかがわかります。例えば、Topic 0はアプリケーションよりのトピックで、Topic 1は機械学習関連のトピックのようです。右上のグラフでは各トピックの人気度合いの時間的な変化がわかります。最近はTopic 0とTopic 2が特に人気があるようです。右下の円グラフでは、各論文がarXivで設定されているカテゴリに所属している割合を見ることができます。API関連の論文はソフトウェア工学(cs.SE)や分散コンピューティング(cs.DC)、セキュリティ系(cs.CR)のカテゴリに属するものが多いようです。納得感はありますね。
作成したPBIXファイルをアップロードしたので皆さんもよければ触ってみてください。
おわりに
データ連携ツールのCData Sync とPower BIの可視化にPyCaretのモデリングを組み合わせて、論文をトピック分析してみました。手順自体はかなり単純ですが、本格的なトピック分析ができそうですね。データを変えれば他の文書データにも比較的簡単に応用できるはずなので、皆さんのデータ分析にも役立ててもらえればと思います。