こんにちは。CData Software Japan リードエンジニアの杉本です。
CData Software では、JSON/XMLといったスキーマレスなテキストファイルを、RDBのようにモデル化・スキーマ情報を与えて、ODBC/JDBC/ADO.NETといったDB接続用のフレームワークを経由して、アクセスできるようにするという製品を提供しています。
www.cdata.com
www.cdata.com
これらのドライバーでは、表形式ではないデータ構造を如何にテーブルライクに扱うことができるか? どのようにモデリングするか? に重きを置いて開発されています。今回はの記事ではこのモデル化のアプローチを中心に解説をしたいと思います。
なお、記事では、JSONファイルをベースとして、解説していますが、基本的な概念はJSON/XMLで共通です。
スキーマレスなJSON/XMLを扱う上での課題点
JSONもXMLも、一応JSON Schema・XML Schemaといったスキーマ定義が別途存在しますが、世の中にあふれているAPI等から提供されるJSON/XMLファイルは、一律単一なテキストファイルで、基本的にはスキーマが存在しない、ユーザーが好きに汲み取ってください、というものが多数かと思います。
もちろん、この自由さゆえに、作りやすさの敷居は低いのですが、いざ他のツールやアプリケーションから読み取ろうとした場合に、スキーマが無いことがボトルネックとなり、どのように読み取るべきか? どこまで階層・配列・オブジェクトが存在しているのか、把握しづらい・処理しづらい、といったことがよく発生すると思います。
それをCDataでは、外付けでスキーマ定義を自動的に与えて、RDBライクな操作性を実現しています。
この機能により、例えば以下のようなJSONファイルに対して、「Select * from documents」といった形でそれぞれのデータを取得したり、挿入したりということを実現します。
{
"documents": [
{
"title": "SampleTitle1",
"updated_at": "2018-09-10T05:22:26Z",
"files": [
{
"name": "SampleFile1-1",
"language_code": "en"
},
{
"name": "SampleFile1-2",
"language_code": "ja"
}
]
}
]
}
そしてここで一つ疑問に出てくるところが、どのようにRDBライクにスキーマを定義しているのか? というところだと思います。
型はどうしているのか? 配列はどんな形式になるのか? ネスト構造は?
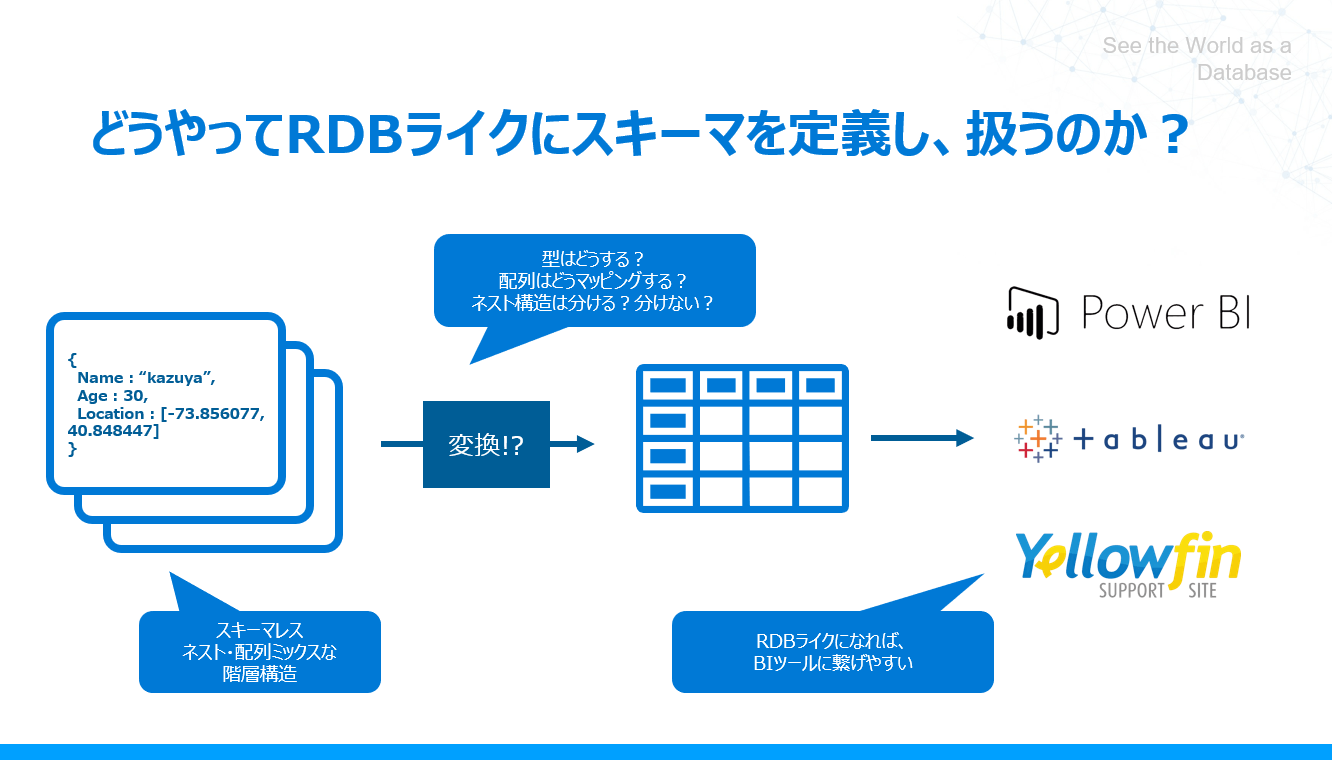
今回の記事では、そういったRDBライクに扱う上での、JSON/XML Driverの基本的なアプローチを解説したいと思います。
もし、MongoDBのようなJSON(正しくはBSONですが)ベースのドキュメント型NoSQL DBを扱いたい場合は、私の以下のBlogも参考になるかと思いますので、参照してみてください。
CData MongoDB Driverを使ってドキュメント指向NoSQLであるMongoDBをRDBライクに扱う方法
基本的な利用方法
本記事ではCData JSON\XML JDBC Driverをベースとして解説します。それぞれ、以下のURLより30日間のトライアルが利用できますので、是非試してみてください。
https://www.cdata.com/jp/drivers/json/jdbc/
https://www.cdata.com/jp/drivers/xml/jdbc/
インストール後、それぞれサンプルで掲載している接続文字列を使用してもらえれば、実際のJSON/XML ファイルをSQLでコントロールすることができることをイメージいただけるかと思います。
JSON/XMLファイルの DataModel 化パターン
まず今回の最も大事な要素となる、JSON/XML のモデル化パターンをお伝えします。
CData JSON/XML Driverでは、以下の3種類の DataModel 化パターンをサポートしており、それぞれ向き不向きがあります。
1.Document:トップレベルのドキュメントモデル
JSON/XML ドキュメントのトップレベルの配列をベースとしてテーブル化を行うモデルです。ネストされたオブジェクト配列は JSON/XML 文字列として返されます。
2.Relational:リレーショナルモデル
親オブジェクトにリンクするそれぞれの配列データを、主キーと外部キーを含む個々のテーブルとしてモデル化し、リレーショナル・データベースのように扱うことができるようにするモデルです。
3.FlattenedDocuments:フラット化されたドキュメントモデル
ネストされたオブジェクト配列を暗黙的に単一のテーブルに結合し、提供するモデルです。
なかなか言葉尻ですと、伝わりづらい部分があると思いますので、次のセクションで実際の動きを見ながら、解説していきます。
各 DataModel の実際の動作イメージ
それでは、実際に以下のサンプルJSONファイルを使いながら、このモデル化のアプローチを確認してみたいと思います。
http://myjson.com/13801o
使用するのは、シンプルな構造体のJSONです。階層のTOPにDocumentsという配列のオブジェクトがあり、Title・Updated_at・Filesというプロパティを持っています。Filesはさらに配列構造になっており、Name・Language_codeというプロパティを持ちます。
{
"documents": [
{
"title": "SampleTitle1",
"updated_at": "2018-09-10T05:22:26Z",
"files": [
{
"name": "SampleFile1-1",
"language_code": "en"
},
{
"name": "SampleFile1-2",
"language_code": "ja"
}
]
},
{
"title": "SampleTitle2",
"updated_at": "2018-09-05T05:22:26Z",
"files": [
{
"name": "SampleFile2-1",
"language_code": "ja"
},
{
"name": "SampleFile2-2",
"language_code": "en"
}
]
}
]
}
1.Document
まず、Documentモデルです。Documentモデルは対象の配列オブジェクトを読み取り、そこを行分割の軸としてテーブル化して提供します。

サンプル接続文字列
jdbc:json:URI=https://api.myjson.com/bins/13801o;DataModel=Document;
前述した通り、上記のJSONは「Documents」という配列構造があり、その配列のオブジェクトの中に各種プロパティと共に、子の配列構造「Files」を保持しています。
Documentモデルは、この最初のDocuments配列をベースにモデル化とレコード化を行い、ユーザーへデータを提供します。
なお、ネストされた配列構造の JSON/XML は、JSON/XML のまま値として提供します。
2.Relational
Relationalモデルは、JSON/XML ファイルから、複数の配列構造を読み取り、RDBモデルのように、それぞれ配列をテーブル化するというアプローチです。

サンプル接続文字列
jdbc:json:URI=https://api.myjson.com/bins/13801o;DataModel=Relational;
上記のように、Topレベルの配列オブジェクトが「Documents」で、配下に「Files」という配列オブジェクトがあれば
「Documents 1 : N Files」という2つのテーブルに分割し提供されます。
また、各テーブルに分割するにあたって、それぞれidの自動振り分けも行いますので、分割されたテーブルをJOINする場合は、このidを利用します。
3.FlattenedDocuments
最後に、ちょっとわかりづらい FlattenedDocuments。FlattenedDocuments はネストされた配列構造をすべてフラット化し、1テーブルとして扱います。

サンプル接続文字列:
jdbc:json:URI=https://api.myjson.com/bins/13801o;DataModel=FlattenedDocuments;
Relational で構成されたテーブルをJOIN・CROSS JOINしたものであると例えればわかりやすいかもしれません。
最もネストが深いテーブルを軸として、親テーブルをそれぞれ JOIN していき、ユーザーへレコードを提供します。
なお、以下のように、同階層に存在している配列オブジェクトが存在する場合は CROSS JOIN します。

サンプル接続文字列:
jdbc:json:URI=https://api.myjson.com/bins/1a4udo;DataModel=FlattenedDocuments;
また、Relationalと同様に各配列構造毎にidが振り分けられます。
以上が、JSON/XML のDataModel、モデル化アプローチになります。
ネストがあまり深くなく、ある程度フラットなものであれば、Documents
一つのオブジェクトに共通的な配列オブジェクトが含まれていれば、Relational
あまり難しいことを考えずに、すべてフラットな状態で、データを取得したい、という場合は FlattenedDocuments
といった形で、利用頂くのが望ましいのではないかと思います。
なお、上記でも説明している通り、RelationalのモデルをJOIN・CROSS JOINしているのが FlattenedDocuments なので、Relationalで構成しておいて、あとでユーザー側でSQLを使いJOINするといったアプローチもいいかなと思います。
配列構造(JSON/XML Path)の検出方法
もう一つ、このDataModel の大事な設定として、配列構造の検出方法があります。
上記それぞれの DataModel パターンは、それぞれどこの配列を基準として、分解するのか? といった情報(JSON/XML Path)を保持しています。
基本的には、これは自動的に算出され、暗黙的に設定されていますが、この設定は以下のように接続文字列(JSONPath='$.documents.files')で指定することも可能です。
jdbc:json:URI=https://api.myjson.com/bins/13801o;DataModel=Document;JSONPath='$.documents.files;';
ユーザーは直接、JSON/XML Pathを指定することもできますし、JSON/XML Path指定が無い場合、Driverは一律先頭ドキュメントのJSON構造を読み取り、配列を保持しているパスを算出した上で、JSON/XML Pathを生成します。
自動算出方法のベースは以下のようになります。
「Document」は、最初にヒットした配列構造を軸としてテーブル化を行います。
「Relational」は、各ネストされた配列をすべて算出し、各テーブル構造にそれぞれ割り当てます。
「FlattenedDocuments」は、各ネストされた配列構造をすべて算出しJOINのベースとして提供します。
また、若干注意したいのは、各 DataModel ごとの PATH 指定方法による挙動の違いです。
これは「Document」と「Relational、FlattenedDocuments」で動作が大きく変わります。
DocumentのJSON/XML PATH 指定アプローチ
「Document」の場合は、一つのテーブルにするためのアプローチが中心になります。
例えば前述した以下の一番最初の「Documents」配列を軸にする場合は
以下のような接続文字列で「JSONPath='$.documents;'」と指定します。
jdbc:json:URI=https://api.myjson.com/bins/13801o;DataModel=Document;JSONPath='$.documents.files;';
これを「JSONPath='$.documents.files;'」といった形で、深いネストの配列をベースとして、指定することも可能になります。その場合の結果は以下のように「Files」ベースのレコードとなります。ここには「Documents」の要素は含まれません。

Relational・FlattenedDocuments の JSON/XML PATH 指定アプローチ
「Relational・FlattenedDocuments」の場合は、Documentとはちょっと違うアプローチとなります。
例えば、上記「Relational」モデルの結果を出す場合は、
以下のように「JSONPath='$.documents;$.documents.files;'」といった形で「;」区切りで、それぞれの配列パスを指定します。
jdbc:json:URI=https://api.myjson.com/bins/13801o;DataModel=Relational;JSONPath='$.documents;$.documents.files;';
この指定方法は「Relational・FlattenedDocuments」共通で、最終的な出力をそれぞれテーブルとして分けるのか? それとも、フラット化するのか? といった違いになります。
ちなみに、Documentモデルで、複数の配列パスを指定することはできません。
ディレクトリベース、複数ファイル読み取り
また、CData JSON/XML Driver は、1つのJSONファイルの配列構造を分解してテーブル化するだけでなく、複数のJSONファイルをマージして、テーブル化することも可能になっています。
基本的には、最初のファイルをベースとしてモデル化を行い、後続のファイルはスタックしていくイメージとなります。

ですので、あまりにも構造が乖離している複数のJSONファイル読み取りには向きません。
接続方法は、以下のようにURIでフォルダパスを指定するだけです。
jdbc:json:URI=C:\Testdata\JSON_Documents\;DataModel=Document;
Tips
細かなカスタマイズをしたい場合:Generate Schema Filesについて
こなれてくると、モデルの細かなカスタマイズを行いたい、という場合が出てくると思います。その場合、Generate Schema Filesというプロパティを使うことで、CData用のスキーマを出力し、調整することが可能となっています。
例えば、以下のような接続文字列で、Generate Schema Filesと、そのスキーマを出力するLocationを指定すると、(Location=C:\JSON;Generate Schema Files=OnStart;)
jdbc:json:URI=https://api.myjson.com/bins/13801o;DataModel=Document;Location=C:\Testdata\JSON;Generate Schema Files=OnStart;
以下のようなRSB拡張子のXMLファイルが生成されます。
これはCDataの利用しているスキーマ情報となっており、以下のリファレンスを参考に独自にカスタマイズすることが可能です。また、自動で生成されたJSON/XML Pathがどのように設定されているか? どこを各columnが参照しているのか? といった情報も読み取ることが可能です。
http://cdn.cdata.com/help/HJD/jdbc/pg_rsbschemaintro.htm
<rsbscript xmlnsrsb="http://www.rssbus.com/ns/rsbscript/2" xmlnsxs="http://www.w3.org/2001/XMLSchema">
<rsbinfo title="documents" desc="Generated schema file." xmlnsother="http://www.rssbus.com/ns/rsbscript/2/other">
name="files" xstype="string" readonly="false" otherxPath="/json/documents/files" />
name="title" xstype="string" readonly="false" otherxPath="/json/documents/title" />
name="updated_at" xstype="datetime" readonly="false" otherxPath="/json/documents/updated_at" />
rsbinfo>
<rsbset attr="DataModel" value="DOCUMENT" />
<rsbset attr="URI" value="https://api.myjson.com/bins/13801o" />
<rsbset attr="JSONPath" value="$.documents" />
<rsbscript method="GET">
<rsbcall op="jsonproviderGet">
<rsbpush/>
rsbcall>
rsbscript>
<rsbscript method="POST">
<rsbset attr="method" value="POST"/>
<rsbcall op="jsonproviderGet">
<rsbthrow code="500" desc="Inserts are not currently supported."/>
<rsbpush/>
rsbcall>
rsbscript>
<rsbscript method="MERGE">
<rsbset attr="method" value="PUT"/>
<rsbcall op="jsonproviderGet">
<rsbthrow code="500" desc="Updates are not currently supported."/>
<rsbpush/>
rsbcall>
rsbscript>
<rsbscript method="DELETE">
<rsbset attr="method" value="DELETE"/>
<rsbcall op="jsonproviderGet">
<rsbthrow code="500" desc="Deletes are not currently supported."/>
<rsbpush/>
rsbcall>
rsbscript>
rsbscript>
Flatten Arrays プロパティについて
その他、JSON/XML Driverでは、様々な便利プロパティがあります。
その中の一つ、「Flatten Arrays」は配列構造を列フラットに持つことができる機能です。
例えば以下のようなDocument DataModelでネストされた配列構造を持つ場合、
jdbc:json:URI=https://api.myjson.com/bins/13801o;DataModel=Document;Flatten Arrays=-1;JSONPath='$.documents;';
以下のように、「files.0.language_code」といったように、カラム名にナンバリングを添えて、フラット化します。Flatten Arraysの数によって、このフラット化する最大値は決まります。(-1をつけた場合は、すべての配列をフラット化します)

ちなみに、RelationalやFlattenedDocumentsは、まず最初に配列をすべてテーブル構造化するので、Flatten Arraysより優先され、これが機能しません。
ただし、JSON/XML Pathで、配列構造を分解しない部分がテーブルに含まれていた場合は、Flatten Arraysの機能が有効化されます。
例えば以下のように「DataModel=Relational」で「JSONPath='$.documents;'」とし、「Filesオブジェクトはテーブル化しない」設定にした状態で、Flatten Arraysを設定すると
jdbc:json:URI=https://api.myjson.com/bins/13801o;DataModel=Relational;Flatten Arrays=-1;JSONPath='$.documents;';
先ほどのDocumentと同じような結果を得ることができます。
また、類似の機能である「Flatten Objects」は、デフォルトでTrueのため、あまり気にする必要はありませんが、Flatten Arraysと組み合わせて、Falseを設定することで、配列構造上のオブジェクトをJSON/XMLオブジェクトのまま扱えるようになります。
jdbc:json:URI=https://api.myjson.com/bins/13801o;DataModel=Document;Flatten Arrays=-1;JSONPath='$.documents;';Flatten Objects=false;

おわりに
いかがでしたでしょうか。
JSON/XML はプログラム上でのやり取りには大変便利ですが、いざBIをするために表形式で扱いたい! という場合には、なかなか敷居が高いものです。
それを、CData Driverはうまくスキーマを与えて、BIはもちろん、各種ツールからも扱いやすいフォーマットにして提供しています。
是非活用してみてください!
他にも様々な機能がありますので、何かあれば質問いただければと思います。
関連コンテンツ



