こんにちは。CData Software Japan リードエンジニアの杉本です。
本記事では 分析基盤向けデータ統合の自動化ツールである CDataSync を使って、HRビジネスクラウド(以降、HRBC) のデータを Google BigQuery に連携し、分析する方法を紹介したいと思います。
HRBC とは?
HRBCは人材ビジネスで事業拡大を目指す企業様に数多く導入されており、少人数から大規模まで現在と将来の事業にフィットできるクラウドベースのアプリケーションです。
https://hrbc.porters.jp/

自社WEBや各種求人媒体と連携し、求職者、スタッフの管理のCRM機能と求人案件管理を中心としたSFAの機能を併せ持ちます。
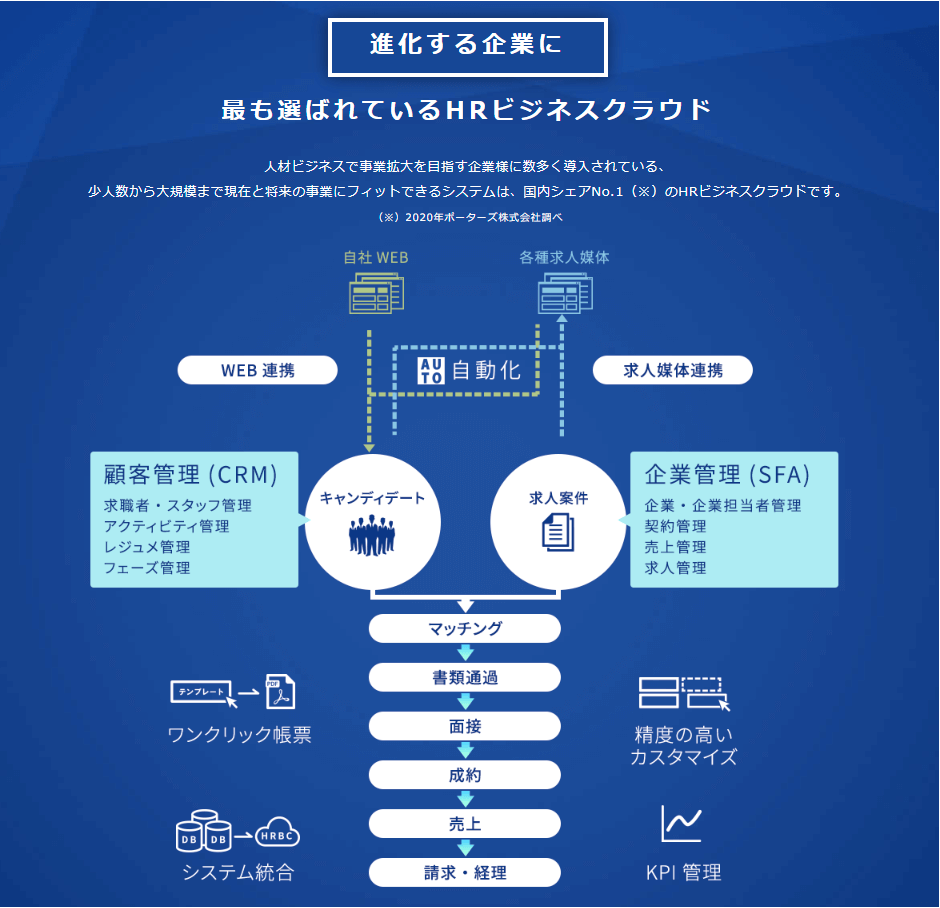
HRBC ではこのような各種データアクセスするためのHTTPベースの REST APIを提供しており、本記事ではこのAPIを活用して、BigQueryに連携を行えるようにします。
https://hrbcapi.porters.jp/hc/ja
実現イメージ
本記事ですすめるシナリオはHRBC のデータをBigQueryに移行する仕組みを構成することだけですが、少し背景をおさえておきたいと思います。
以下の記事でも紹介していますが、現在私達の周りには数多くの SaaS が溢れ、10数年前のようなRDBだけ連携していればいいという時代は過ぎ去っています。
https://www.cdata.com/jp/blog/2019-12-10-231629
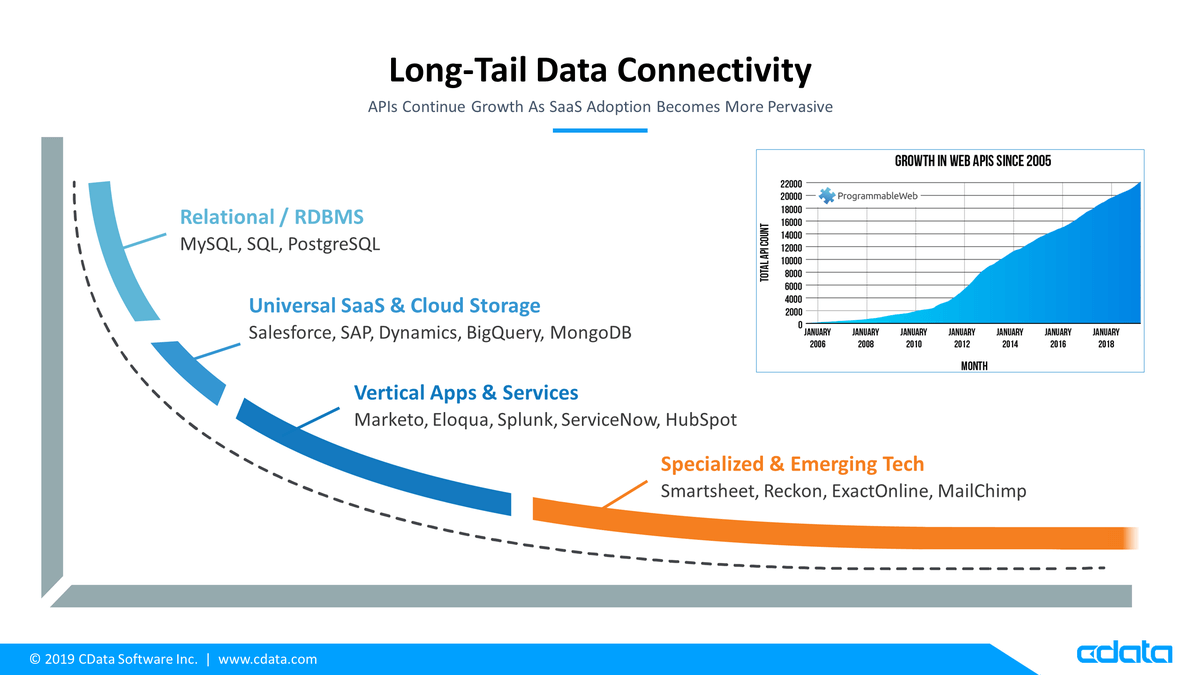
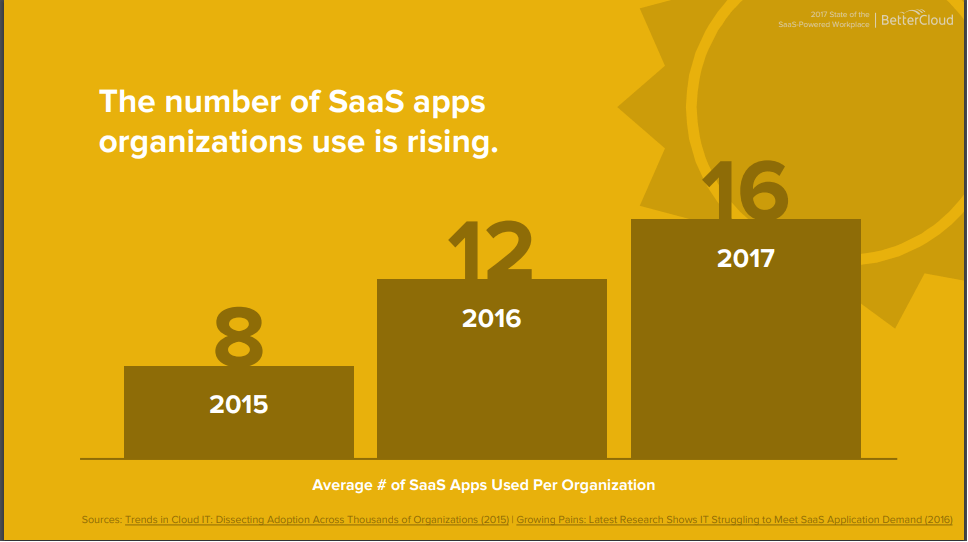
アメリカでは一つの企業で平均10~20程度の SaaS を使っているというレポートも存在し、多種多様なアプリケーションを活用しながら企業のビジネスプロセスが動いていることがわかります。
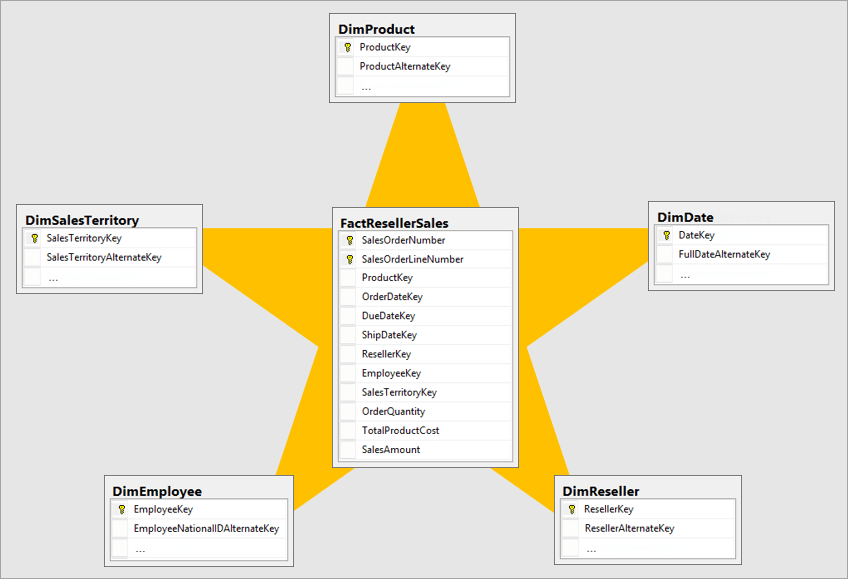
そのような状況では、たとえ「受注データを切り口として分析したい」といった要望があったとしても、ディメンション(BIによる分析でよく用いられるようなスタースキーマ文脈における)が各種アプリケーション・SaaSに分散され、「受注データはこのサービスにあるけれど、ディメンションとして使いたい顧客属性は違うサービスに存在する」ということが頻発してしまいます。
https://docs.microsoft.com/ja-jp/power-bi/guidance/star-schema
そのようなビジネス環境で今求められているのが、ELTの考え方です。多種多様なデータソースから、一度DWHにデータをロードし、DWHで分析や変換処理を回していきます。
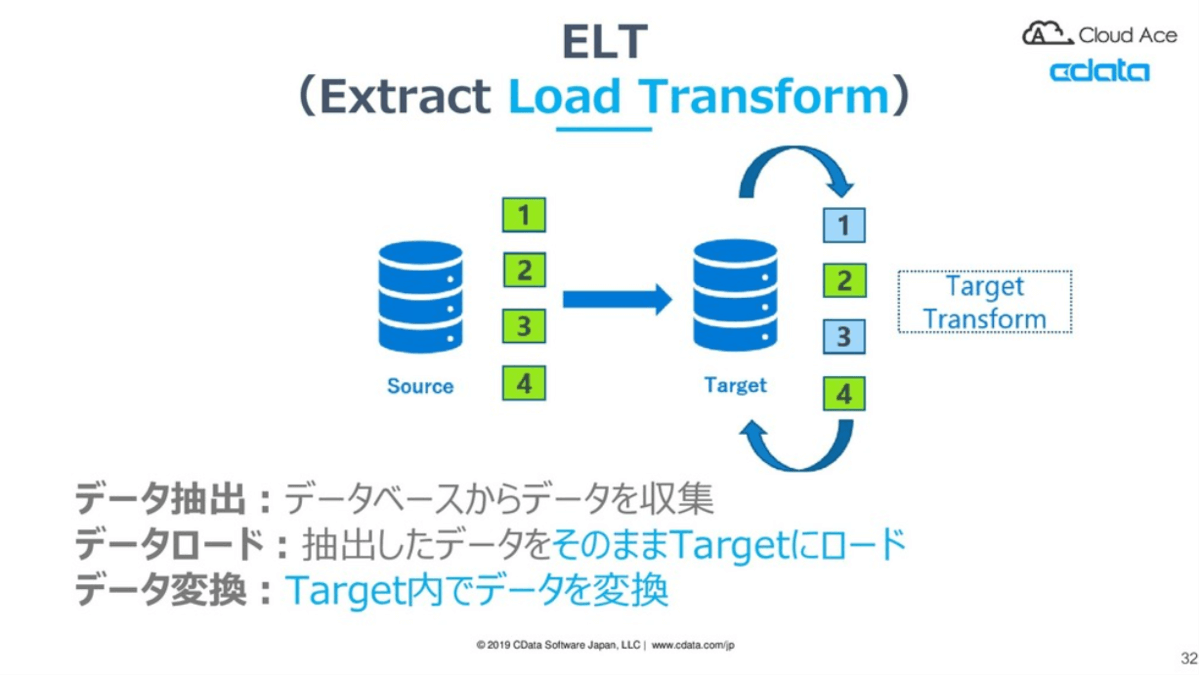
引用元:https://docs.microsoft.com/ja-jp/power-bi/guidance/star-schema
CDataSyncでは、そのような分析基盤向けデータ統合の自動化をノンコーディングで実現することができるようになっています。
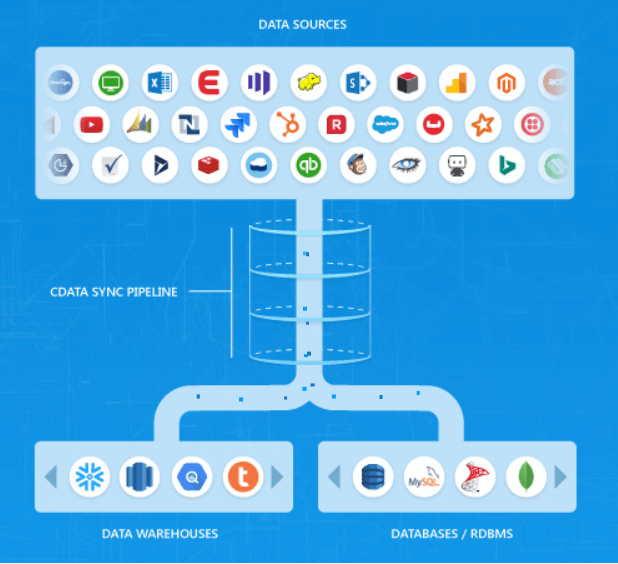
そういった背景を踏まえ、本記事ではデータ分析基盤・DWHとして現在多く使われている Google BigQuery にHRBCの受注データを連携する方法を紹介します。
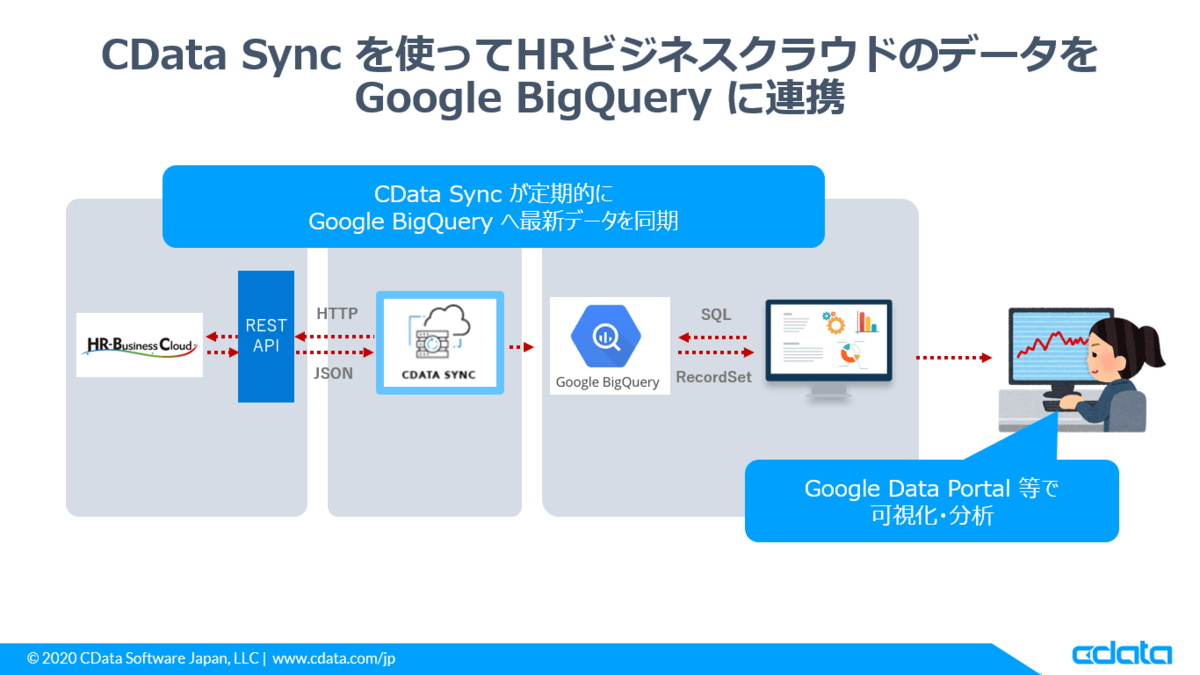
必要なもの
- Google BigQuery・Data Portalが利用可能な GCPアカウント
- HRBC アカウント
- CData Sync
- CData API Profile for HRBC
CData API Profile for HRBC のダウンロード
HRBC API を 解釈するためのAPI 定義ファイルを取得します。
以下CData ページからダウンロードできます。
www.cdata.com
保存先フォルダは後ほど使用するので「C:\profiles\HRBC」といった書き込み可能な任意のフォルダに配置してください。
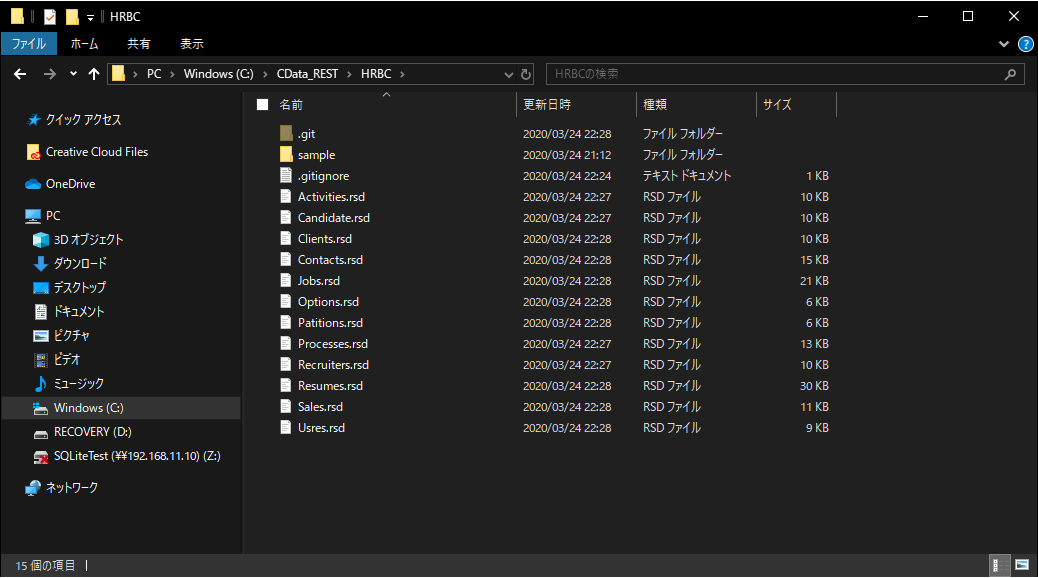
Google BigQuery の準備
まずは、データの格納先となる Google BigQueryのプロジェクトとデータセットを構成しておきます。
なお、今回はあらかじめ専用のアカウントを作って対応しています。
手順は特に難しくありません。GCPの管理コンソールへ移動し、新しいプロジェクトを作成
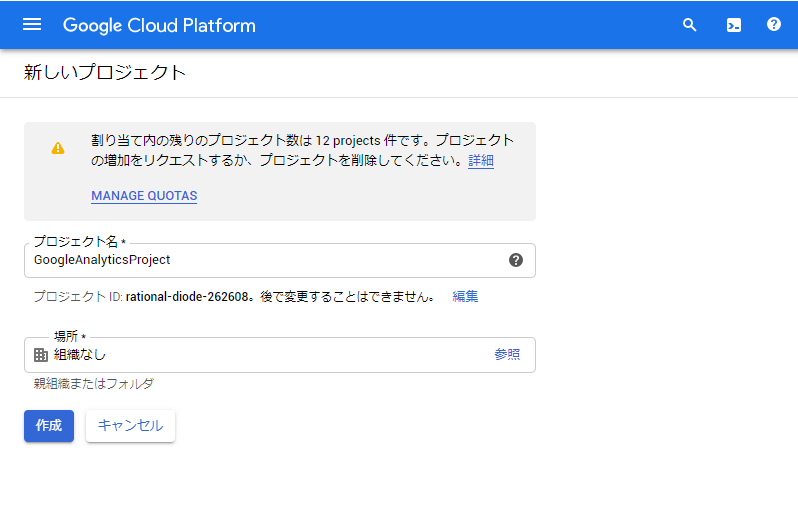
BigQuery に移動し、プロジェクト配下にデータセットを作っておきます。ここに連携結果がテーブルとして格納されます。

以上で BigQuery 側の準備は完了です。
CDataSyncのインストール
それでは、取得した情報を元にCDataSyncの設定を行っていきましょう。
CDataSyncはインストール型のソフトウェアなので、以下のURLからダウンロードして、任意のPCでセットアップを行います。
https://www.cdata.com/jp/sync/
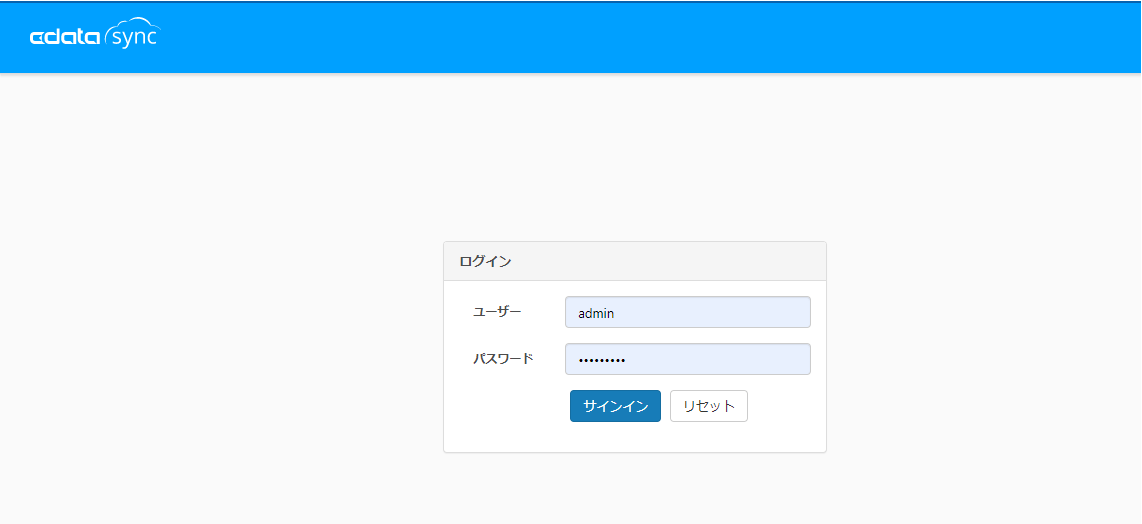
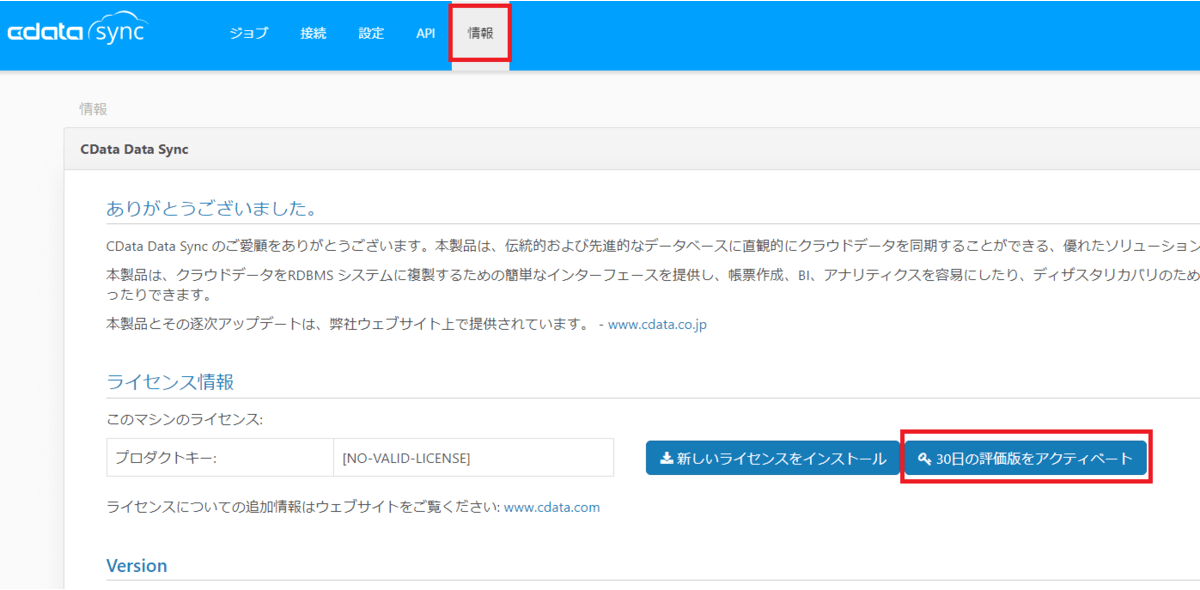
セットアップ後、CData Syncの画面がブラウザで立ち上がるので、セットアップ時に入力したパスワードとユーザー名「admin」を入力して、ログインします。
ログイン後「情報」タブに移動し、「30日間の評価版をアクティベート」を行えば、CDataSyncの初期設定は完了です。
HRBC データソースの設定
まずはデータのSyncを行うためのデータソースの設定を行っていきましょう。
CDataSyncでは任意のデータソースを自由に追加して、連携することが可能です。
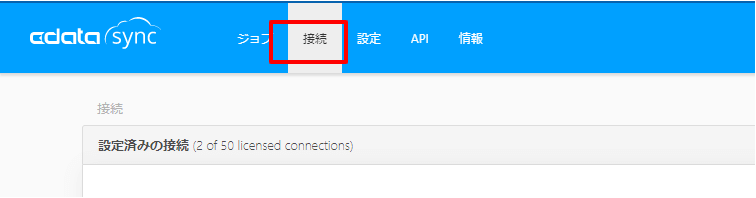
デフォルトでは HRBC データソースが含まれていないため、「接続」に移動し「+ Add More」をクリックし、追加を行います。

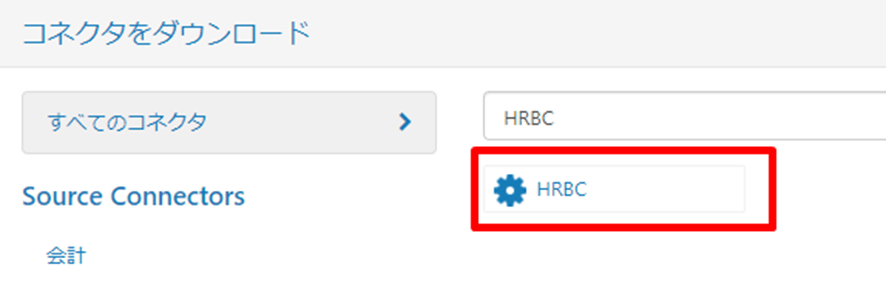
一覧の中から「HRBC」を検索し、追加します。
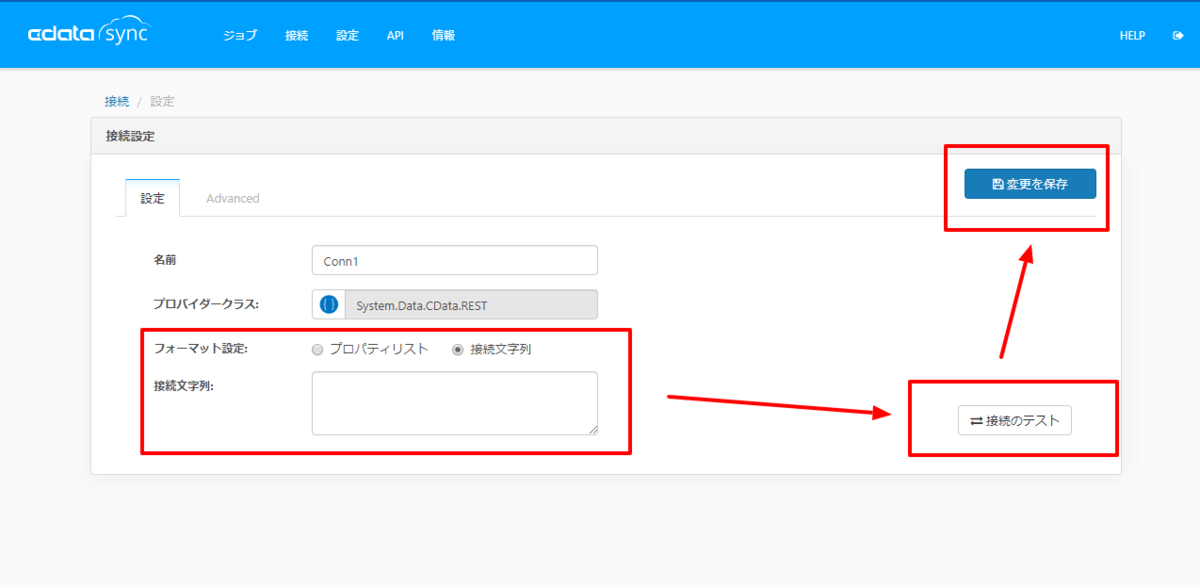
追加後、CDataSyncが再起動します。再起動後、データソースの一覧から「HRBC」が選択できるようになるので、これを選択し接続設定を行います。

接続設定では、「接続文字列」を選択して、以下の項目をセットし、保存します。「app_id」「secret」「partition」にはあらかじめHRBCから受け取った値をセットしてください。
- Profile=C:\profiles\HRBC.apip;ProfileSettings='Partition=xxx;AppID=my_app_id;AppSecret=my_app_secret;'
接続テストを行う前に、以下の手順にある「Company DBへのアクセス権付与」を行っておきます。
Scope は利用したいリソースに応じて指定してください。本API Profile では各リソースの読み込み権限を主に利用するため、特に制限を気にされない場合は読み込み権限をすべて指定してください。
https://hrbcapi.porters.jp/hc/ja/articles/115008017487-OAuth#Scope-List
BigQueryへの同期先設定
続いて、同期先となるBigQueryへの接続を構成します。
「接続」→「同期先」から「Google BigQuery」を選択し
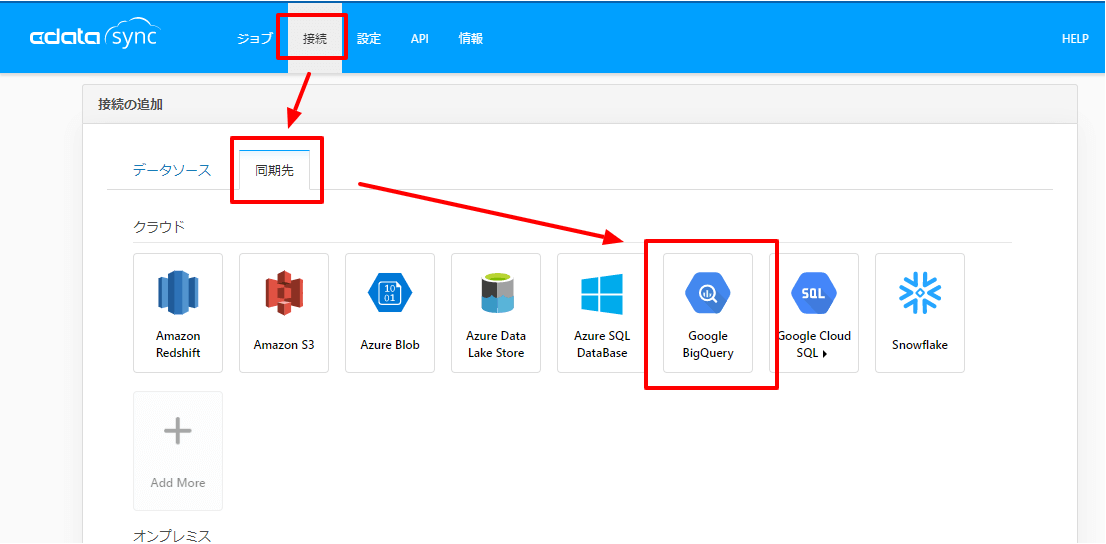
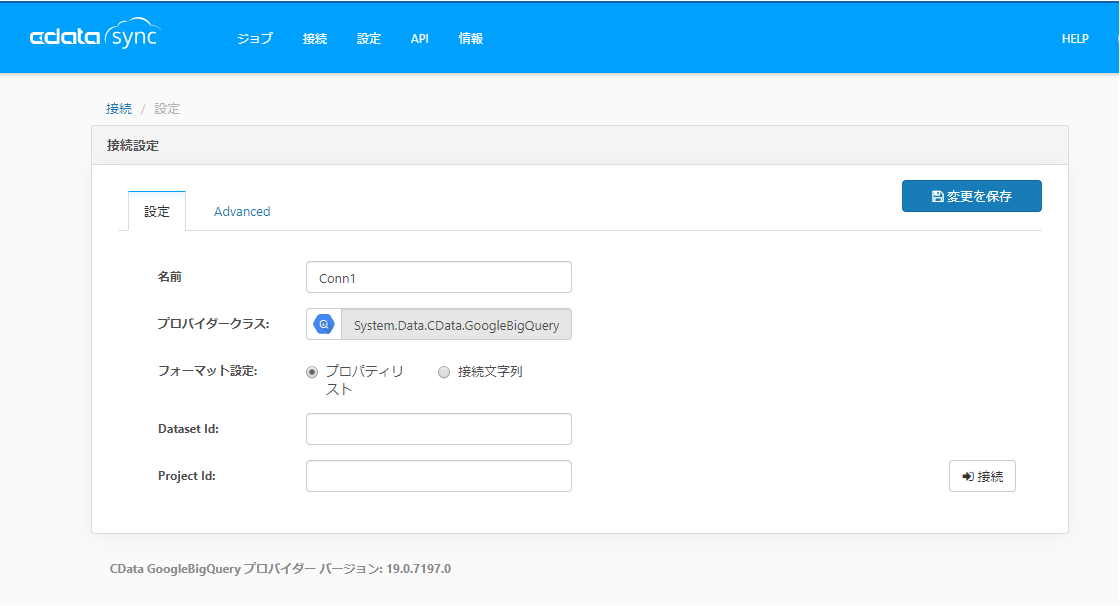
あらかじめ作成しておいた、「ProjectId」と「Dataset Id」を入力し、「接続」をクリックします。
クリックすると、OAuthの認証プロセスが開始されますので、対象アカウントでログインし、アクセス許可を承認してください。承認後、設定を保存すれば準備完了です。
ジョブの作成
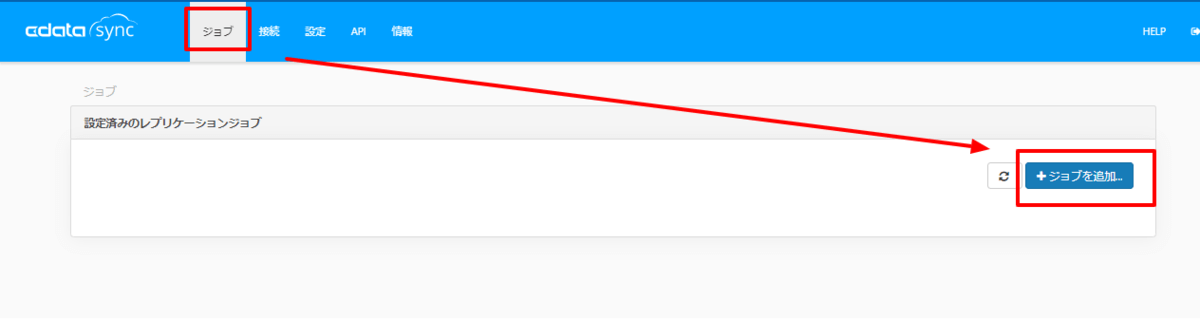
それでは実際にジョブを作成し、データをBigQueryに連携してみましょう。
ジョブのタブから「ジョブを作成」をクリックし
事前に構成した「HRBC」と「BigQuery」を、ソースと同期先としてそれぞれ構成します。
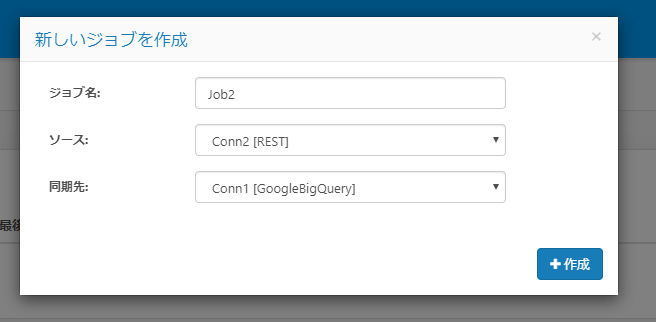
次に連携するデータを決定するために、「テーブルを追加」をクリックし
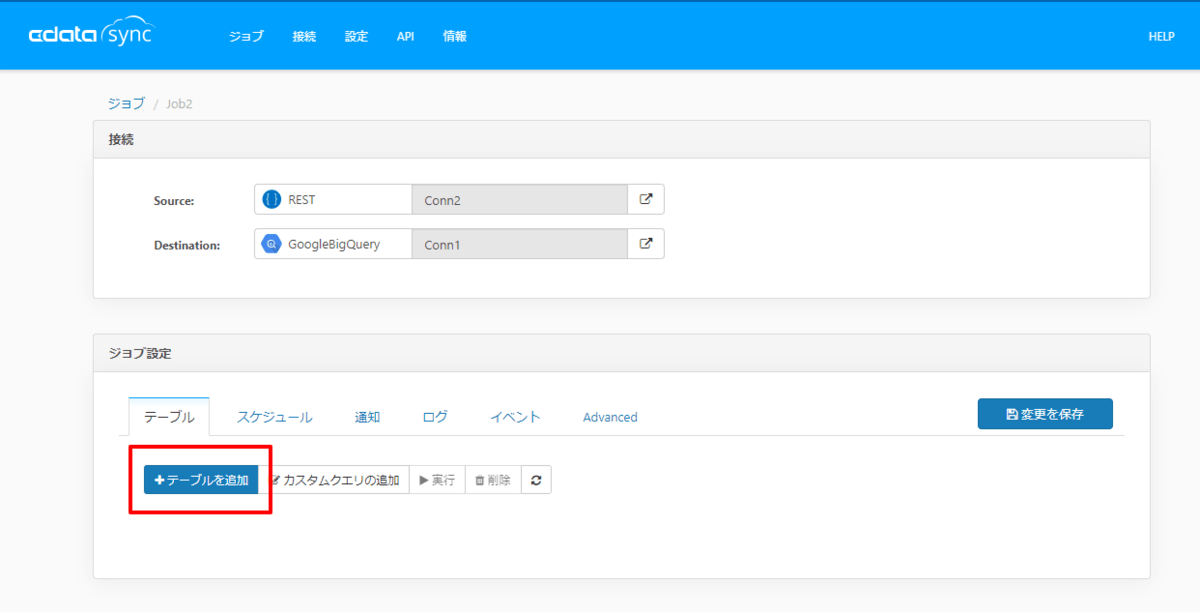
任意のテーブルを選択します。
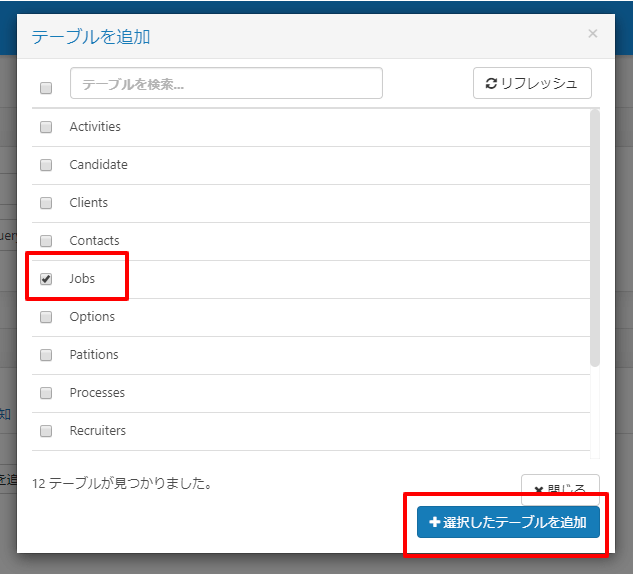
最後にスケジュールタブから定期的に処理にするためにスケジューラーを設定します。以下の設定ですと1日1回、BigQueryへ最新のデータが同期されます。
後は設定を保存すれば、完了です。
テスト実行
テスト実行はテーブルタブから対象となるテーブルを選択し、「実行」ボタンをクリックすることで実施可能です。
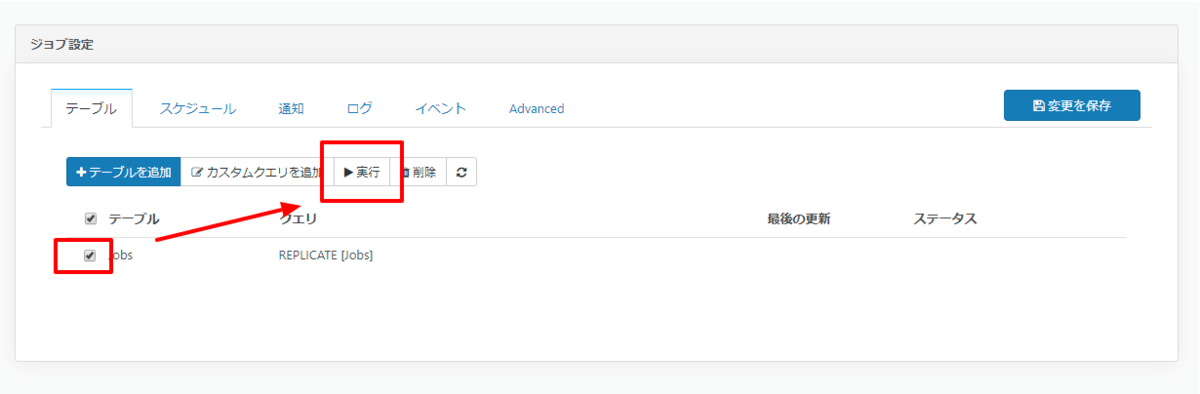
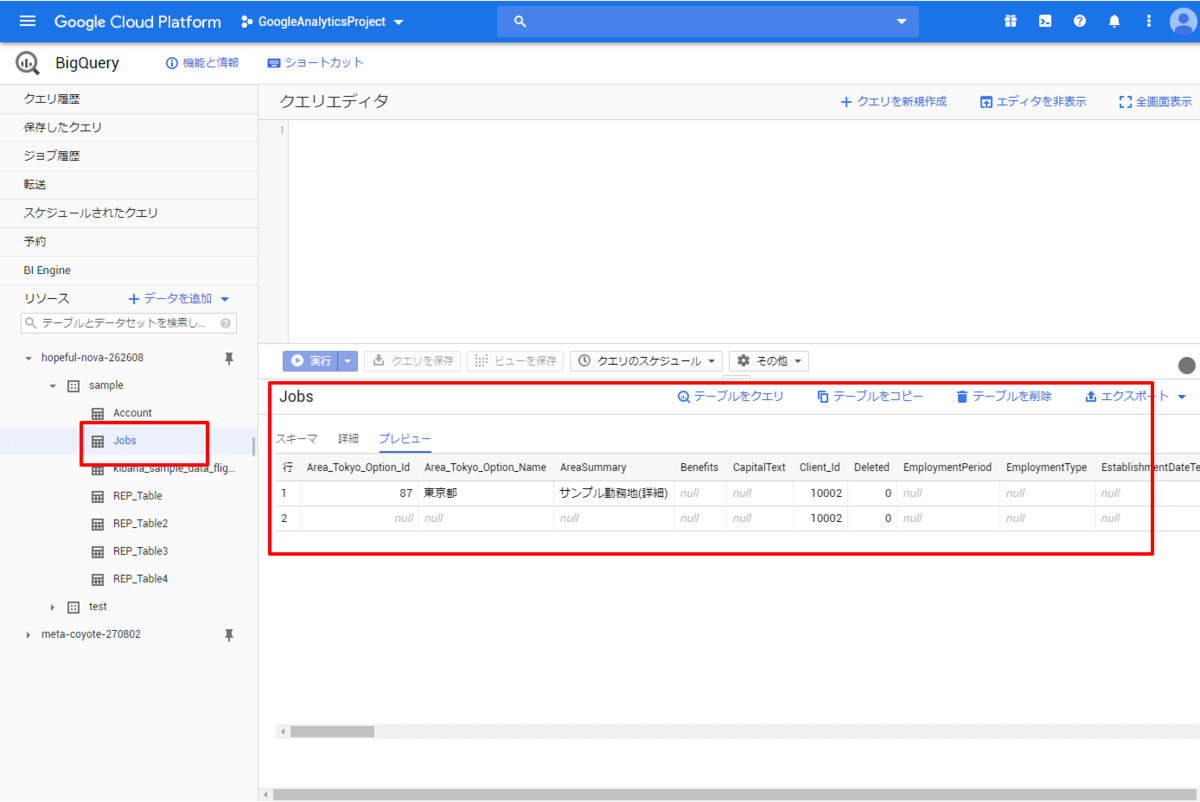
正常に同期されると、以下のようにBigQuery上で自動的にテーブルが生成されデータが閲覧できるようになります。
さいごに
本記事では、HRBC のデータを BigQueryに連携しましたが、CDataSyncではBigQuery以外にも AmazonRedShiftやAzure SQL Serverといった多様な連携先をサポートしています。

是非普段皆さんの会社でお使いのDWH・データベースに同期してみてください。
関連コンテンツ



