はじめに
こんにちは。CDataの技術担当ディレクター桑島です。Webサイトを運用されていたり企業のデジタルマーティングを担当されている方でしたらGoogle Analyticsの画面と睨めっこして「どうやったらSEO増やせるだろうか」」と広告や施策を考えてキャンペーンを打ったり、その結果を分析したりと取り組まれている方も多いのではないでしょうか。私も、この記事を執筆している自社の技術ブログ「CData Software Blog 」を訪れていただけた人が「どのような情報を求めてきたのか」「どのような記事が良く読まれているのか」とブログ管理サイトやGoogleAnalyticsを利用して日々ウォッチしており、時にはセグメント毎に分析しています。
実際のGoogleAnalytics画面の例
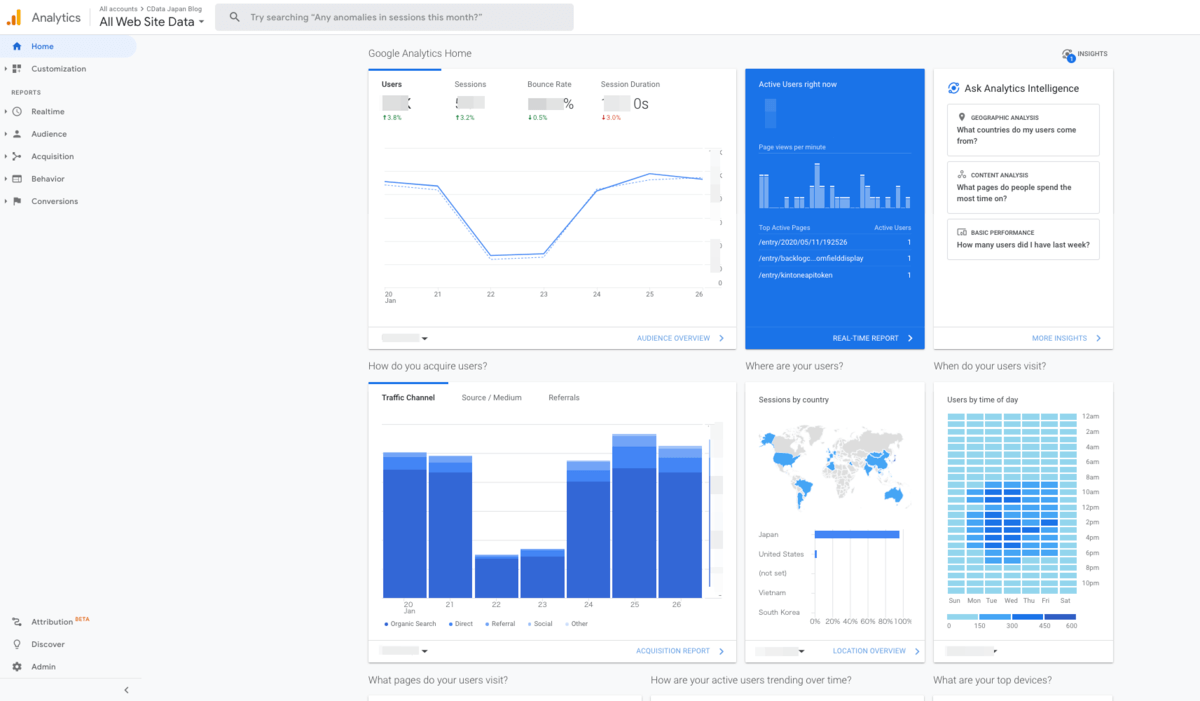
Google Analyticsのダッシュボードは、良く出来ており、Webサイトへの流入を計測するトラフィック(PV, Settion, UU, CTR)などの指標を時系列や代表的なセグメント毎に簡単に可視化することができます。ただし、単体ではデータ分析に必要な前処理は出来ないので、例えば「よく読まれている記事にはどのようなキーワードが含まれているのか?キーワード別に分析したい」「Google AdsだけでなくYahoo広告など他のWeb広告のデータもあわせて分析したい」といった分析をするには、データ準備(Data Preparation)機能や複数データソースを組み合わせた分析ができるような外部のパワフルな分析ツールが欲しくなります。
ノーコード分析Webサービス nehan
今回、弊社のパートナーでもあるnehan社が提供しているノーコード分析Webサービスnehanを利用して自社の技術ブログサイトのアクセス解析をしてみました。
nehan.io
私がこの分析にnehanが向いていると考えたのは以下の点です。
- 前処理がかなり充実している : 言葉の揺らぎのクレンジングやMetricからカテゴリを生成したりとデータをこねくり回したい。
- テキストマイニングが含まれている : ブログタイトルを形態素解析してキーワードを抽出して人気記事に含まれるキーワードをみてみたい。
- 前処理の途中結果をデータプレビューしたりチャートにビジュアライズできる : (言葉の揺らぎのクレンジングとか)前処理に足りないことがアウトプットを見ながら調整できそう。
Google Analyticsのデータをnehanから読み込んでみる
それでは、まずはnehanにGoogle Analyticsのデータを取り込んでみましょう。nehanの分析Webサービスにログインします。
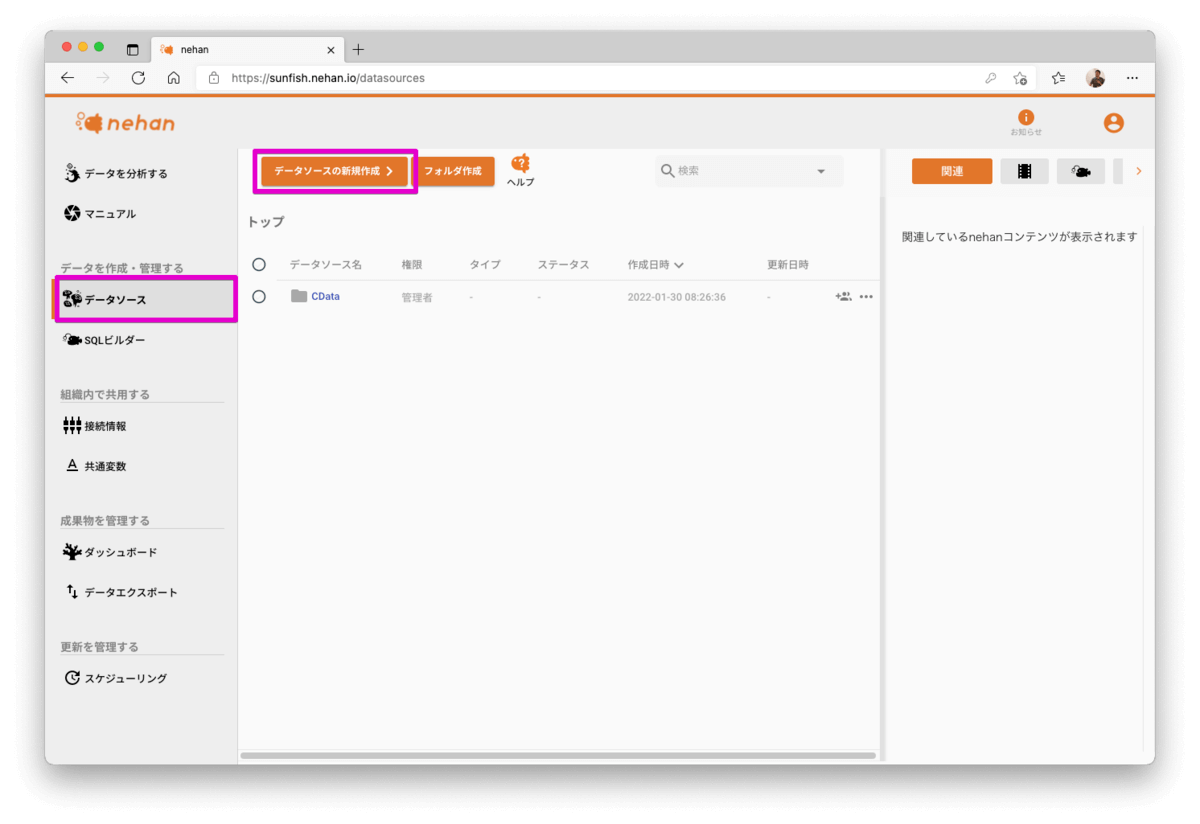
左側メニューにデータソースがあります。データソースを新規作成します。
その他サービス内のGoogle Analyticsを選択します。

新規データソースの画面にて「接続先 新規作成」ボタンをクリックします。
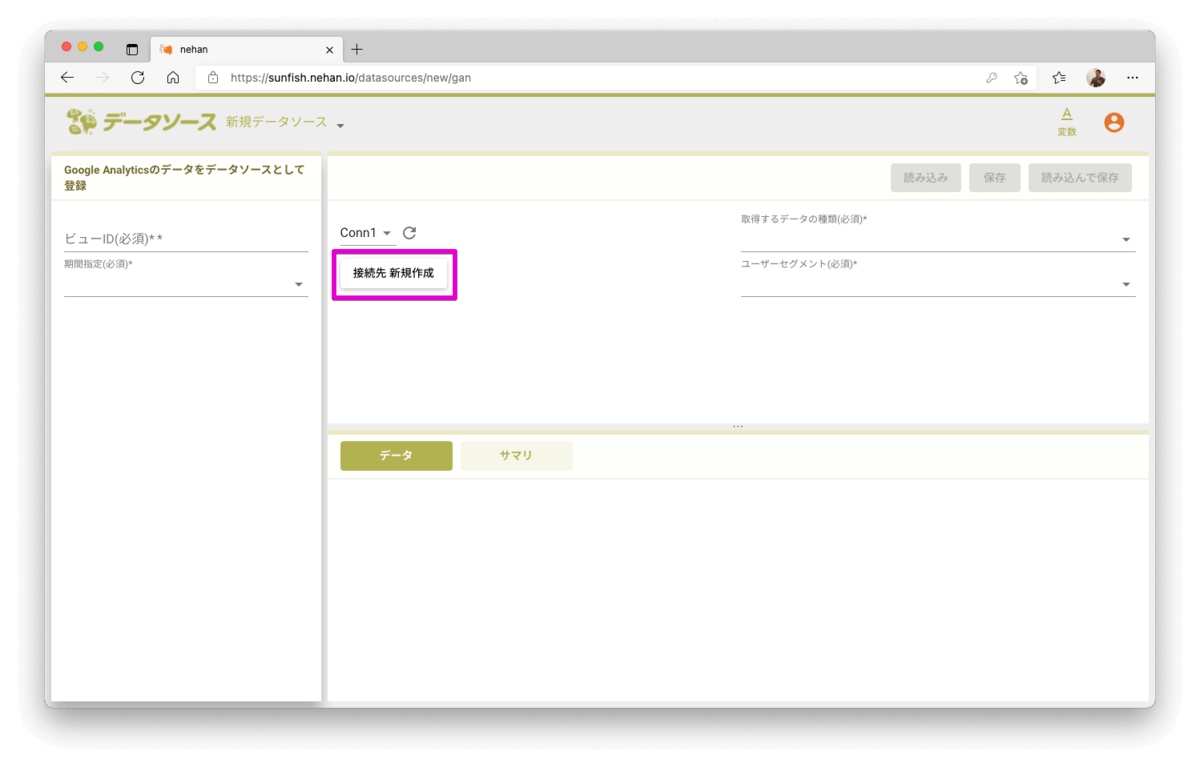
別WindowにてGoogle Analyticsの接続作成画面が表示されます。「Google Analyticsアクセス ServiceAccount JSON」エリアにService AccountのJSON情報(※1)をセットして保存します。
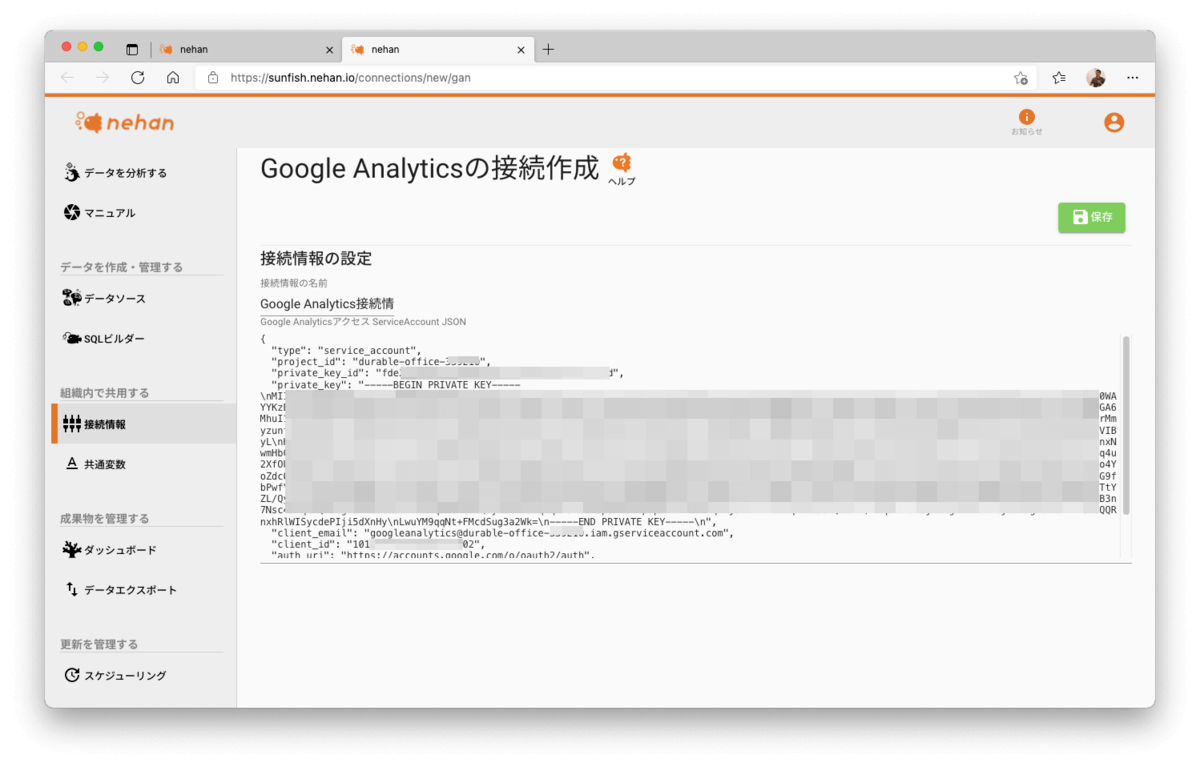
※1 Service AccountのJSON情報の取得方法
Google Developers Console
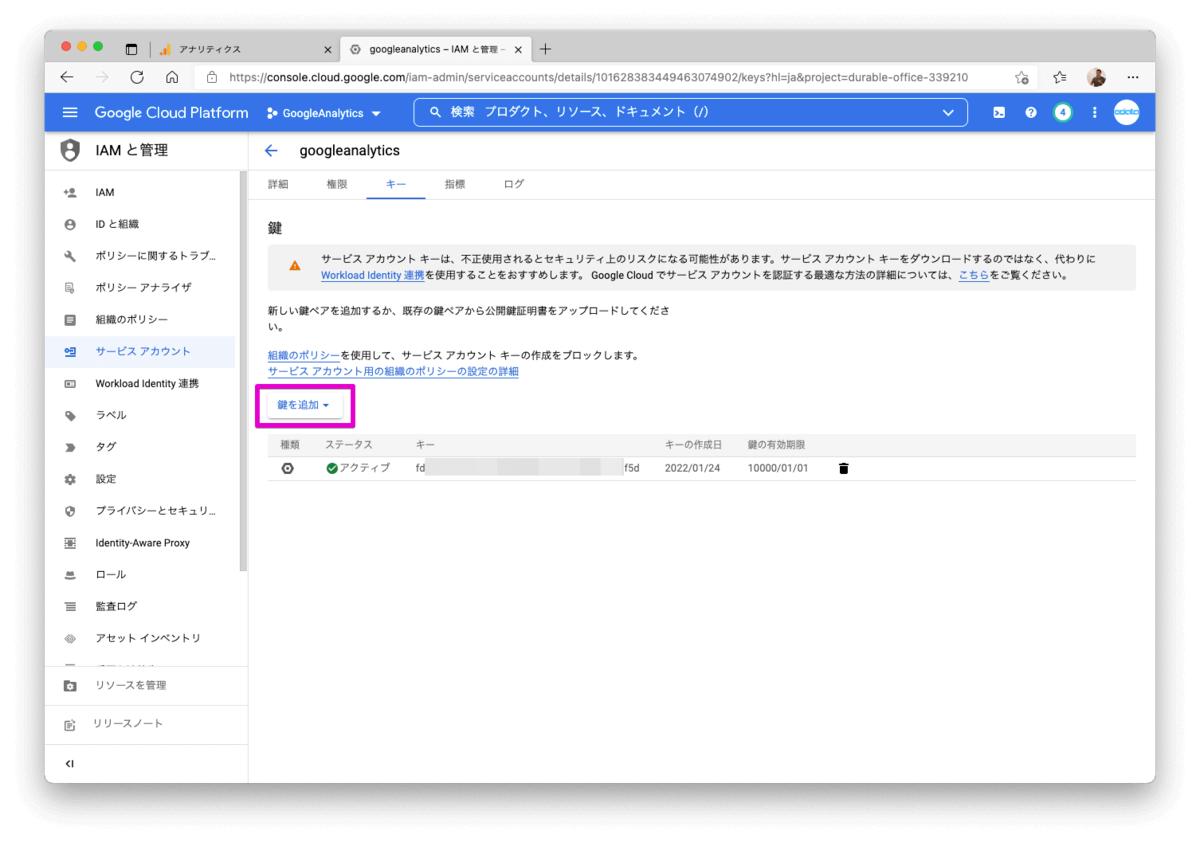
- Google Analytics Reporting APIを有効
- IAMと管理 > サービスアカウント > キー > 鍵を追加
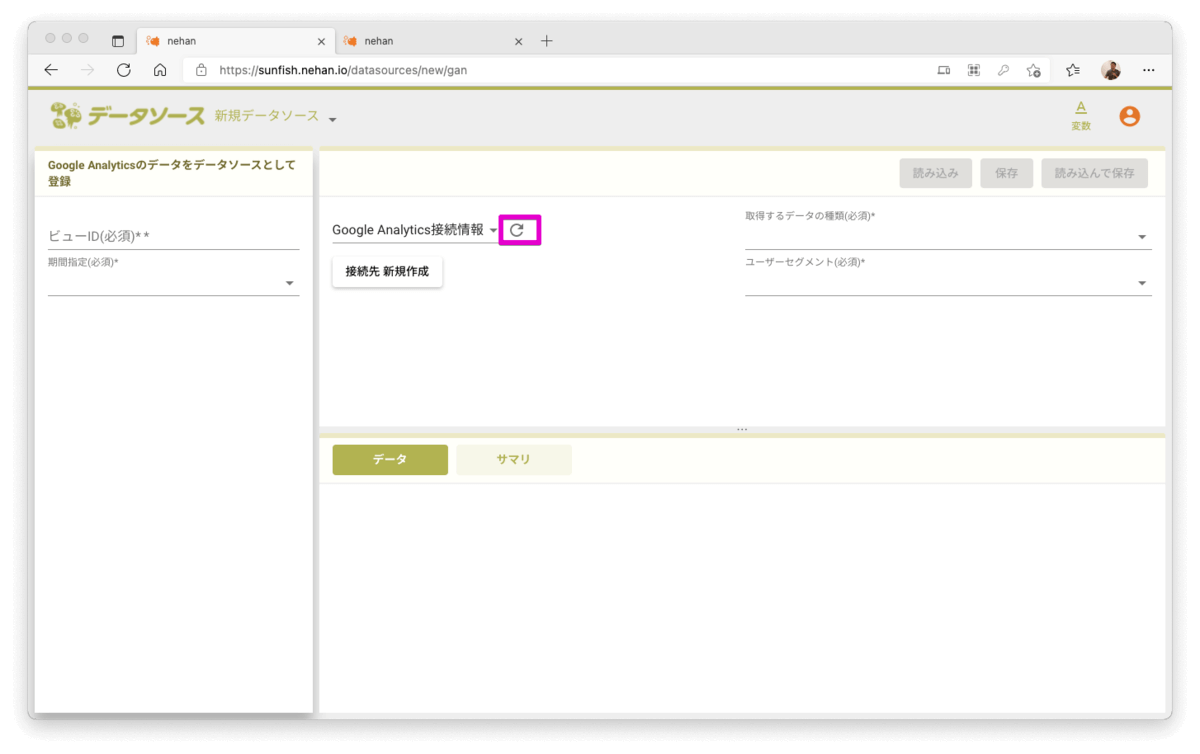
新規データソースの画面にて接続先のリフレッシュボタンをクリックして上記で作成した接続先(デフォルトだとGoogle Analytics接続情報)を選択します。
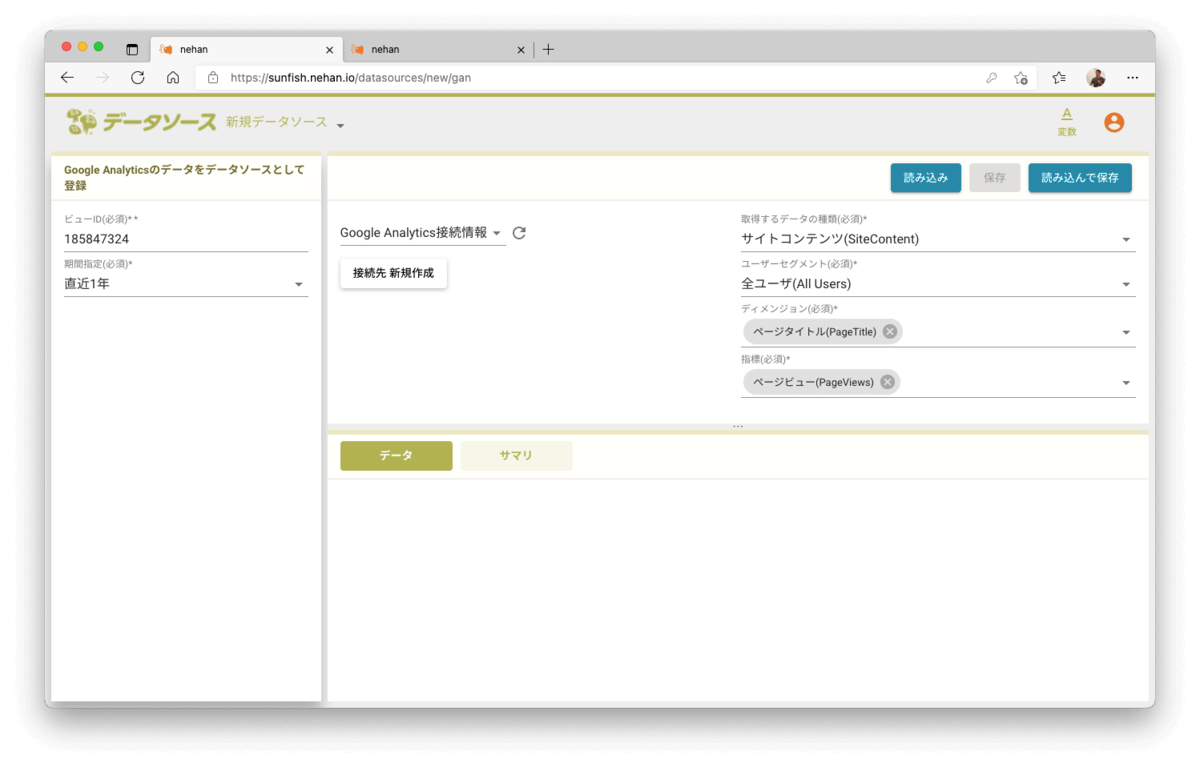
以下の情報をセットします。
- ビューID(必須):GA管理コンソールから確認(※2)
- 期間指定(必須):まずは直近1年でみてみます
- 取得するデータの種類(必須):サイトコンテンツ(SiteContent)
- ユーザセグメント(必須):全ユーザ (All Users)
- ディメンション(必須):ページタイトル(Page Title)
- 指標(必須):ページビュー(PageViews)
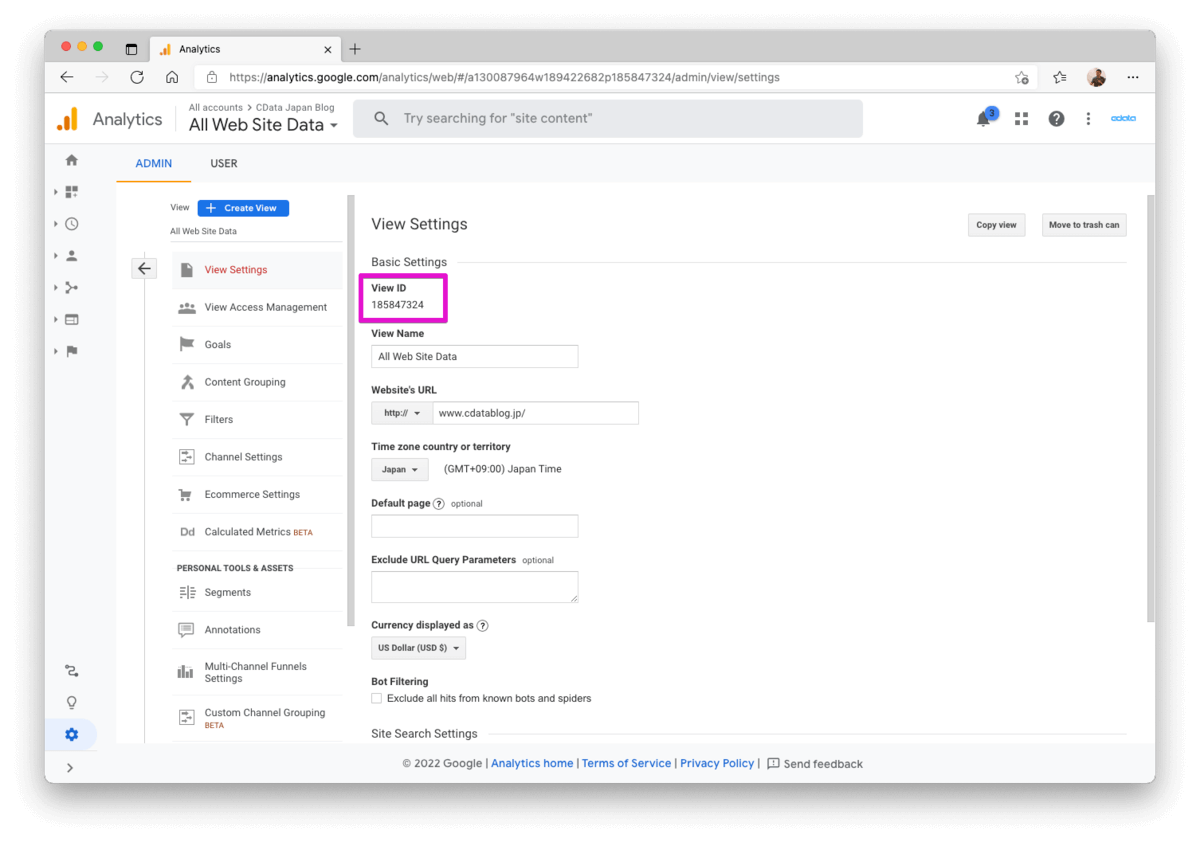
※2 ビューIDの確認方法
Google Analytics管理コンソール
Admin(管理) > Account(アカウント) > Property(プロパティ) > View(ビュー) > ViewSettings(ビューの設定)
読み込むボタンをクリックします。右下のデータにページタイトル毎のページビューが表示されました!
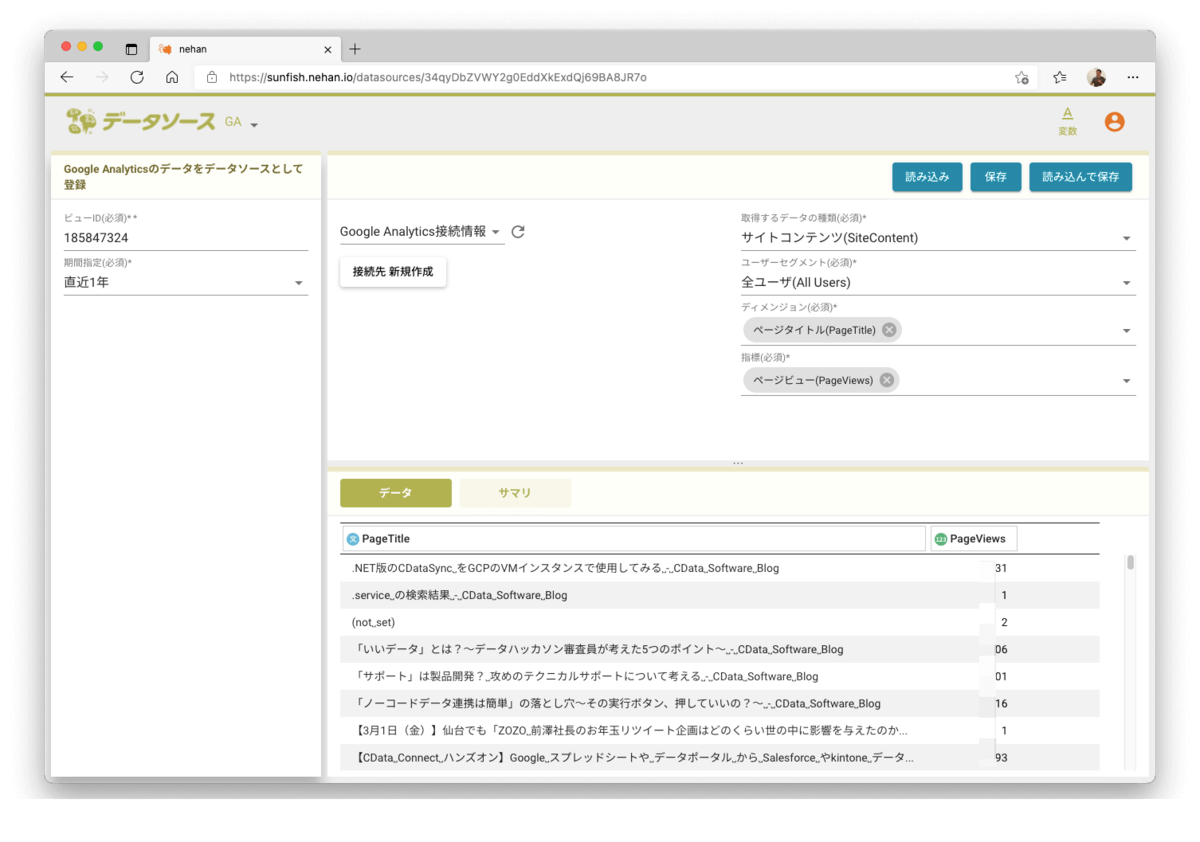
※一部PV数をマスキングしています
これで分析の下準備となるnehanへのGoogleAnalyticsデータの取り込みができました。データソースは任意の名称(本例ではGA)保存しておきましょう。
人気記事ランキングの作成
nehanへのGoogleAnalyticsデータの取り込みが出来たので、まずはどの記事が最も読まれているのかをランキング形式でみてみます。
左のメニューよりデータを分析するを選び、分析プロジェクトを新規に作成します。分析プロジェクト名は任意(本例ではCDataブログランキング)を付与します。
分析プロジェクトが開きました。
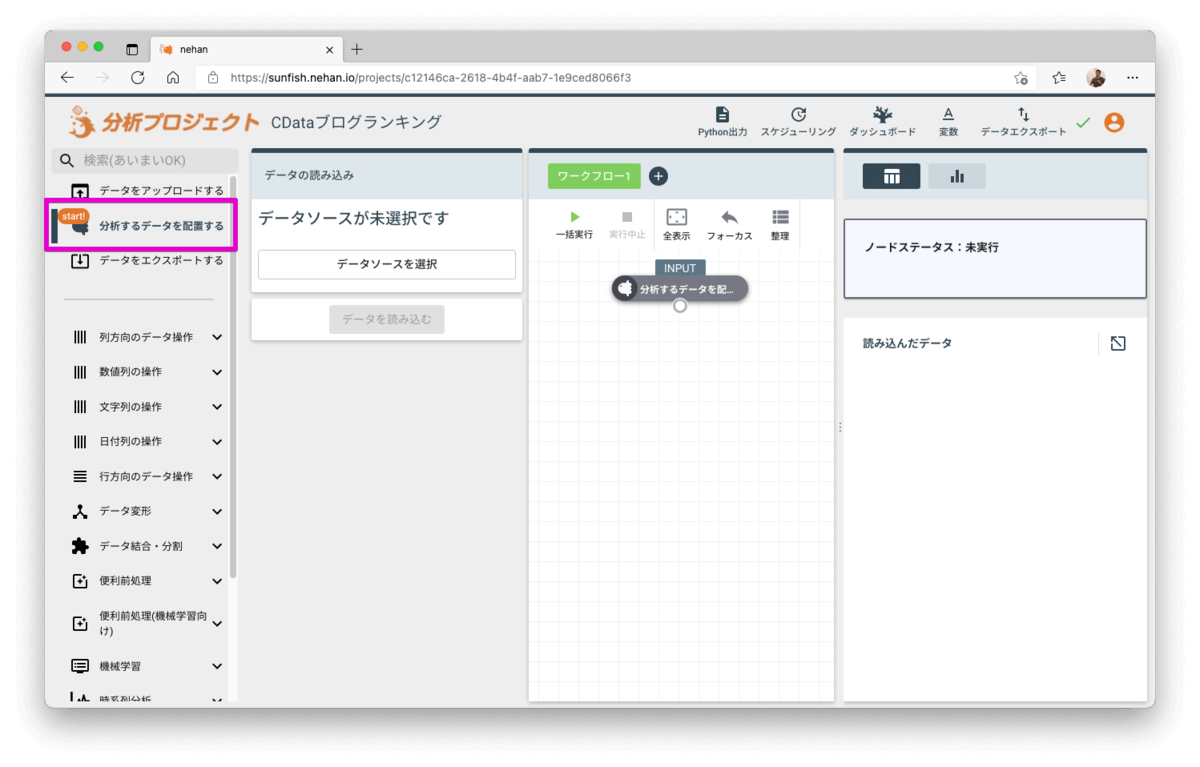
左側のメニューから「分析するデータを配置する」をクリックして先に作成したGoogleAnalyticsのデータソースを選び分析プロジェクトにデータを読み込みます。
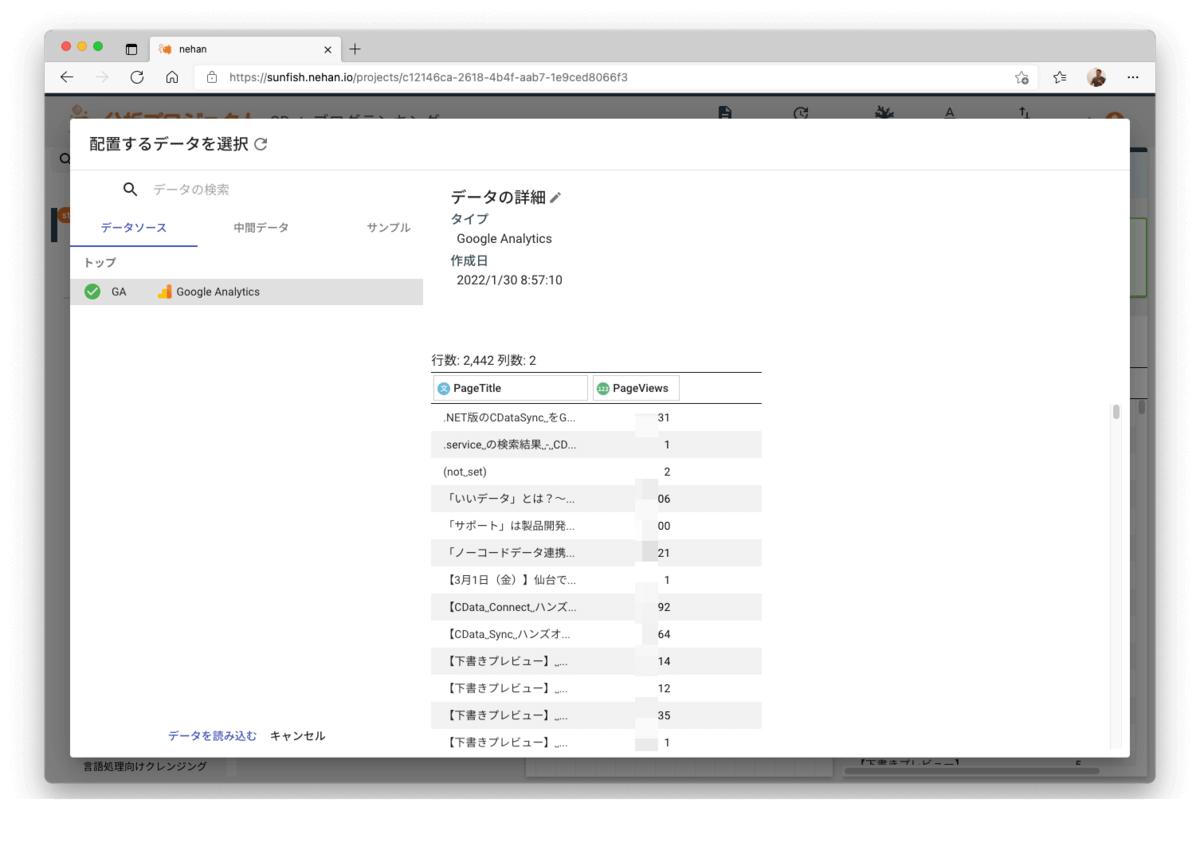
データが読み込まれると中央のワークフローにはINPUTコンポーネントが追加され、その取り込んでデータは右側で確認できます。
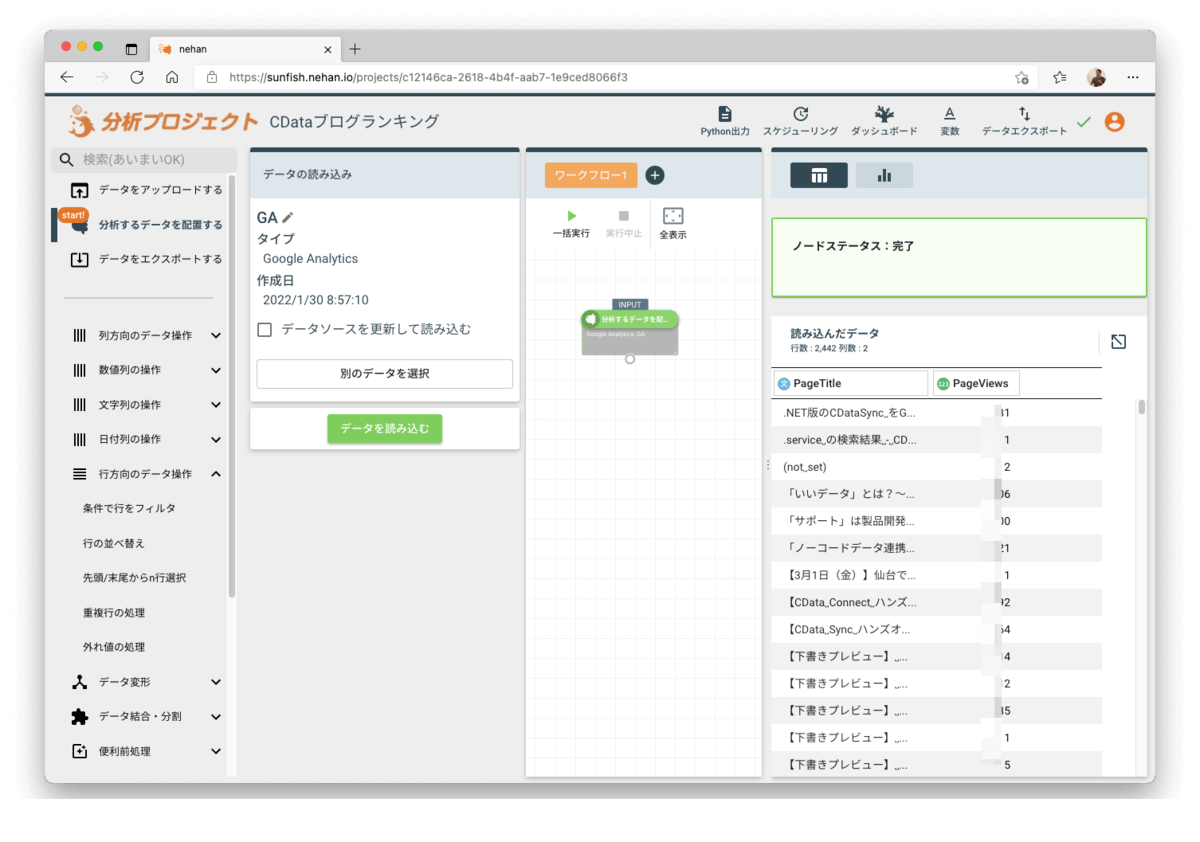
今回はJDBC Driverに関する記事に絞り込んで分析をしてみたいと思います。左メニューから「行方向のデータ操作 > 条件で行をフィルタ」を選択してワークフローに追加、以下の内容を設定して実行します。
- 条件 - #1
- 対象列を選択:PageTitle
- 比較タイプを選択:文字を含む(grep)
- 条件値を入力:JDBC
- 条件 - #2
- 対象列を選択:PageTitle
- 比較タイプを選択:文字を含まない(ungrep)
- 条件値を入力:下書き
下書き中の記事はノイズとして入らないように除外しておきます。
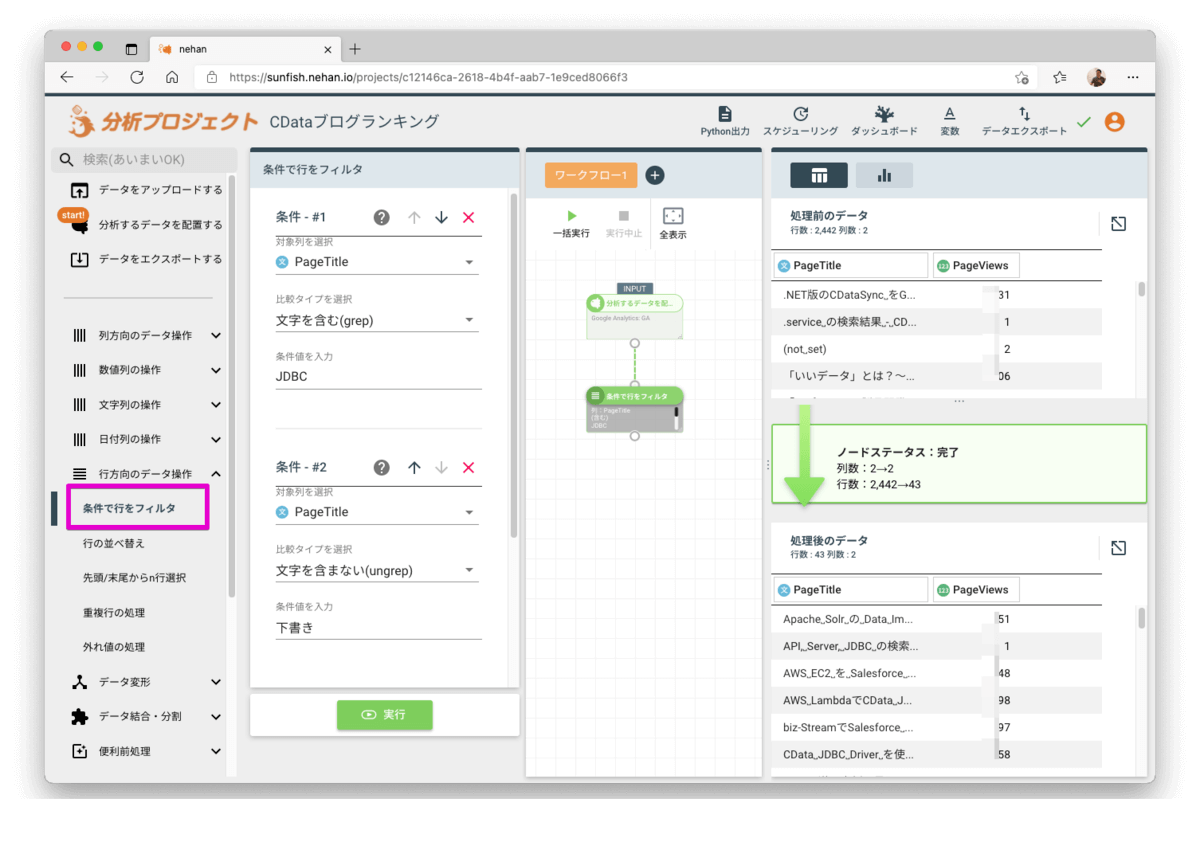
読み込んだデータの行数を見ると43レコードありますので、人気記事に絞るためトップ30のみを抽出してみます。左メニューから「行方向のデータ操作 > 先頭/末尾からn行選択」を選択してワークフローに追加、以下の内容を設定して実行します。右下の処理後のデータの行数を見ると30行に絞り込まれたのが確認できます。ここで表示されているページが人気記事トップ30となります。
- 取得する行数:30
- 並び替えタイプ:降順
- 並び替え対象列を選択:PageViews
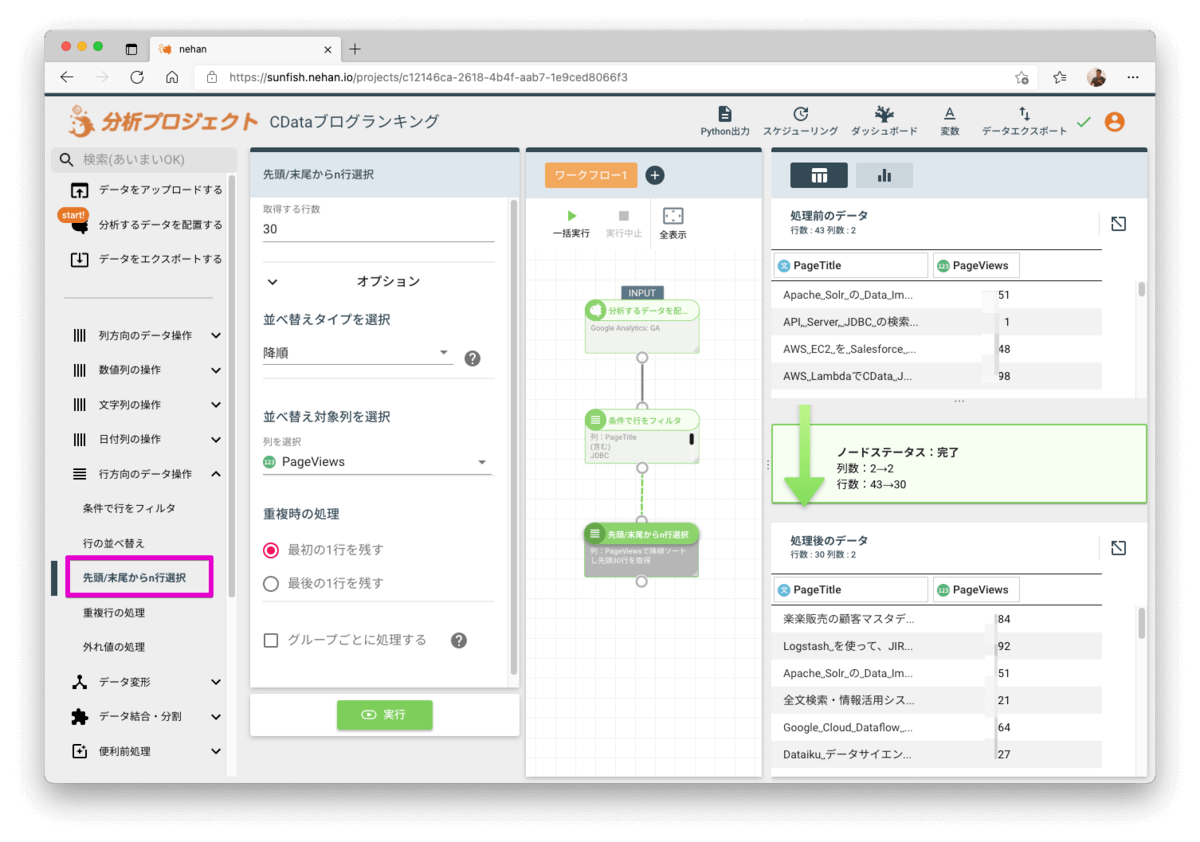
このデータをチャートで見てみましょう。チャートのアイコンをクリックしてビジュアライズを作成します。
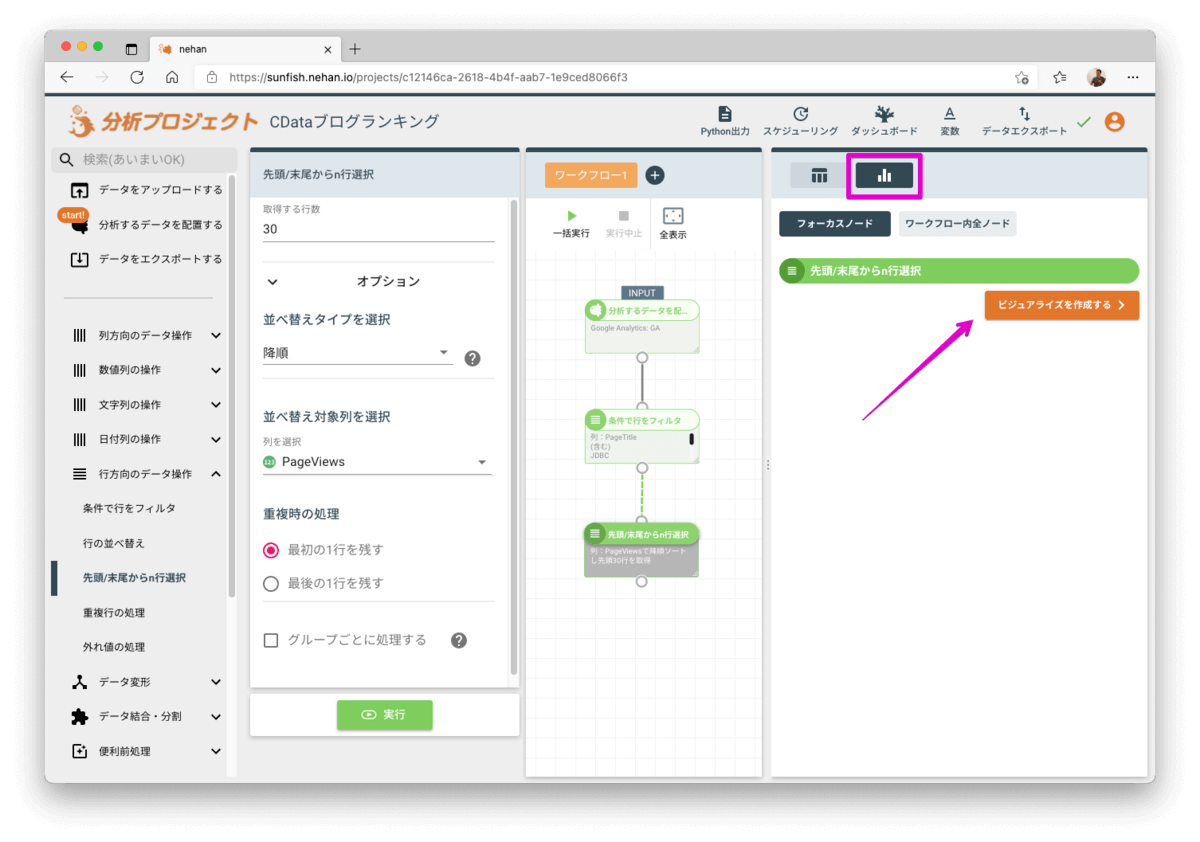
グラフの編集画面が起動します。以下の内容で設定して反映ボタンをクリックします。
- グラフ形 > グラフタイプ : 横棒
- グラフ形 > 横軸: pageviews
- グラフ形 > 縦軸 : pagetitle
- 並び替え > 順番 : 降順
- 並び替え > 並び替えの基準 : 横軸の値順
加えてグラフ名を任意の名称(本例ではCData JDBCブログランキング)にして保存します。
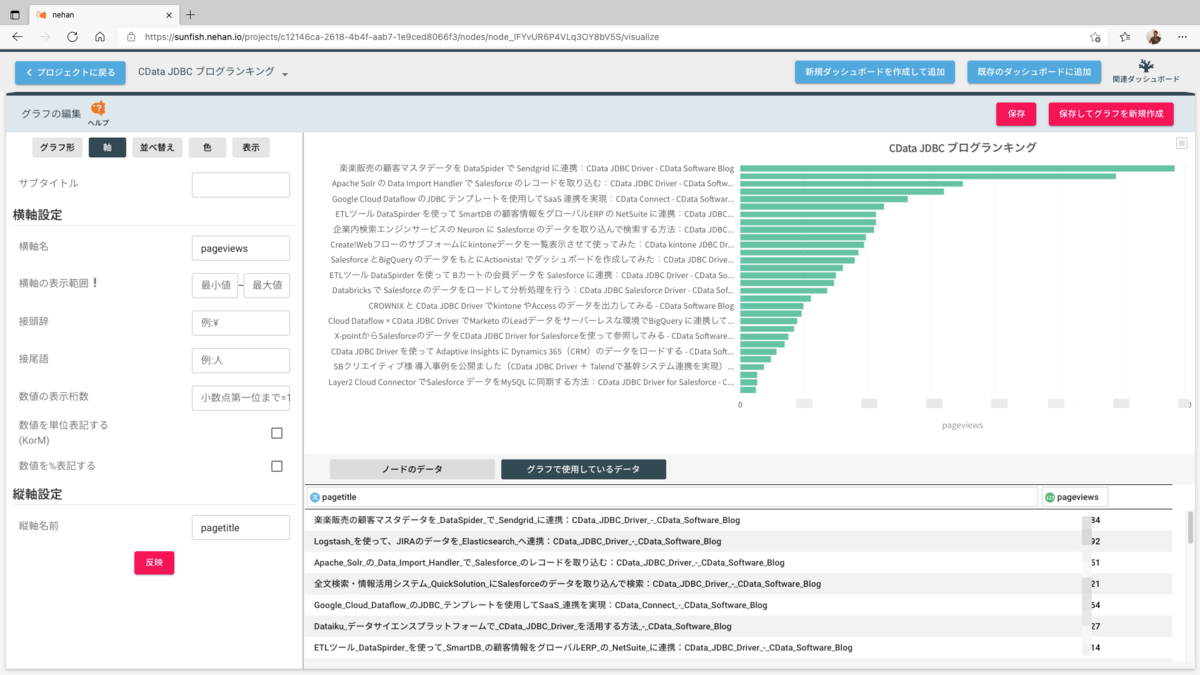
Google Analyticsから取得したデータでWebサイト内のページランキングを作成することができました。
良く読まれている記事のキーワードを抽出してみる
ラインキングの記事のタイトルをみていくと、今度はどのようなキーワードが含まれている記事がよく読まれているのかをみたくなります。キーワードはGoogleAnalytics上はタグ的な情報としては保持されていないのでこのPageTitleから抽出するしかなさそうです。
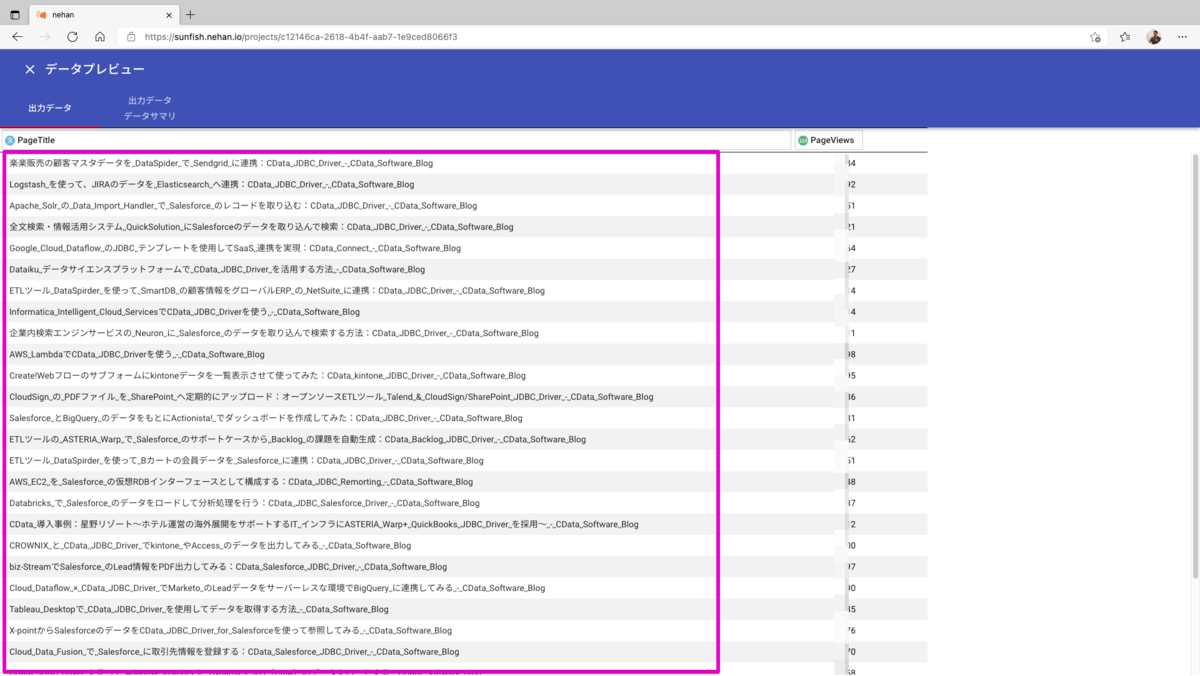
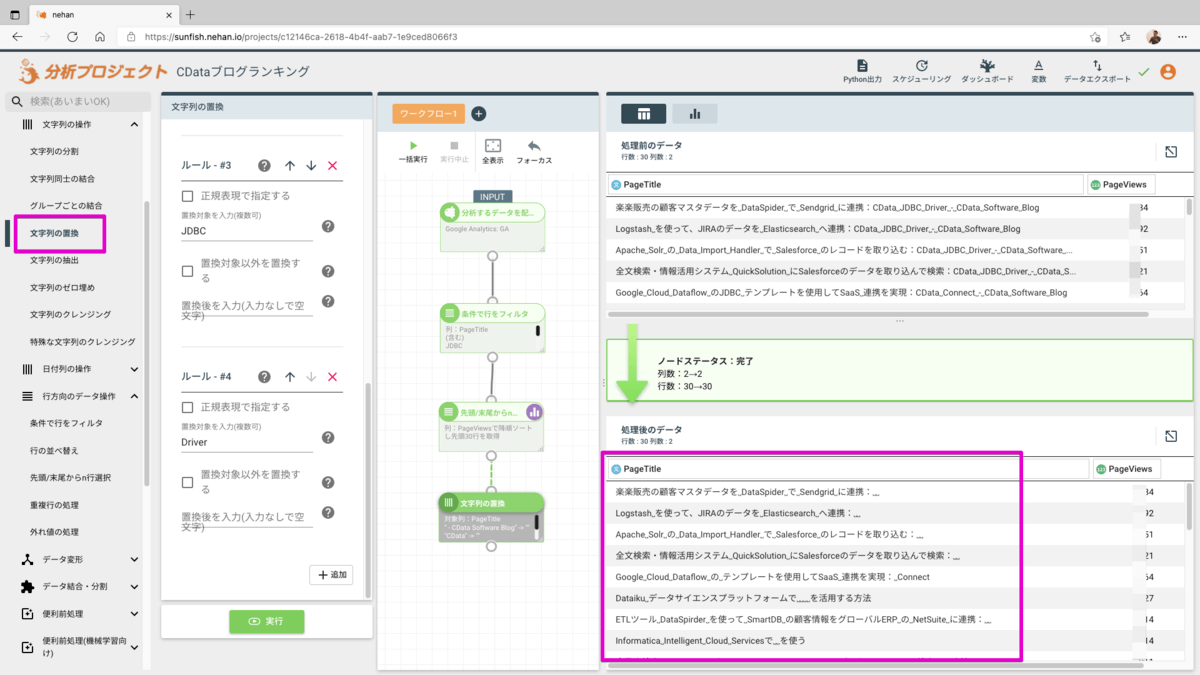
では、先ほどのブログランキングの分析プロジェクトを利用して処理を追加していきましょう。抽出された記事のタイトルをデータプレビューで見ていくと全ての記事に「 - CData Software Blog」というキーワードがついていることに気づきました。これはキーワード分析をする上でノイズとなってしまうので取り除きます。左メニューから文字列の操作 > 文字列の置換を選択して以下の設定で追加します。それと併せて「CData」「JDBC」「Driver」というキーワードも併せて取り除きます。
- 結果の挿入先を設定:既存列に上書き
- 文字列を選択:PageTitle
- 置換ルールを設定
- ルール - #1
- 置換対象を入力: - CData Software BLog
- 置換後を入力:空文字
- ルール - #2
- ルール - #3
- ルール - #4
- 置換対象を入力:Driver
- 置換後を入力:空文字
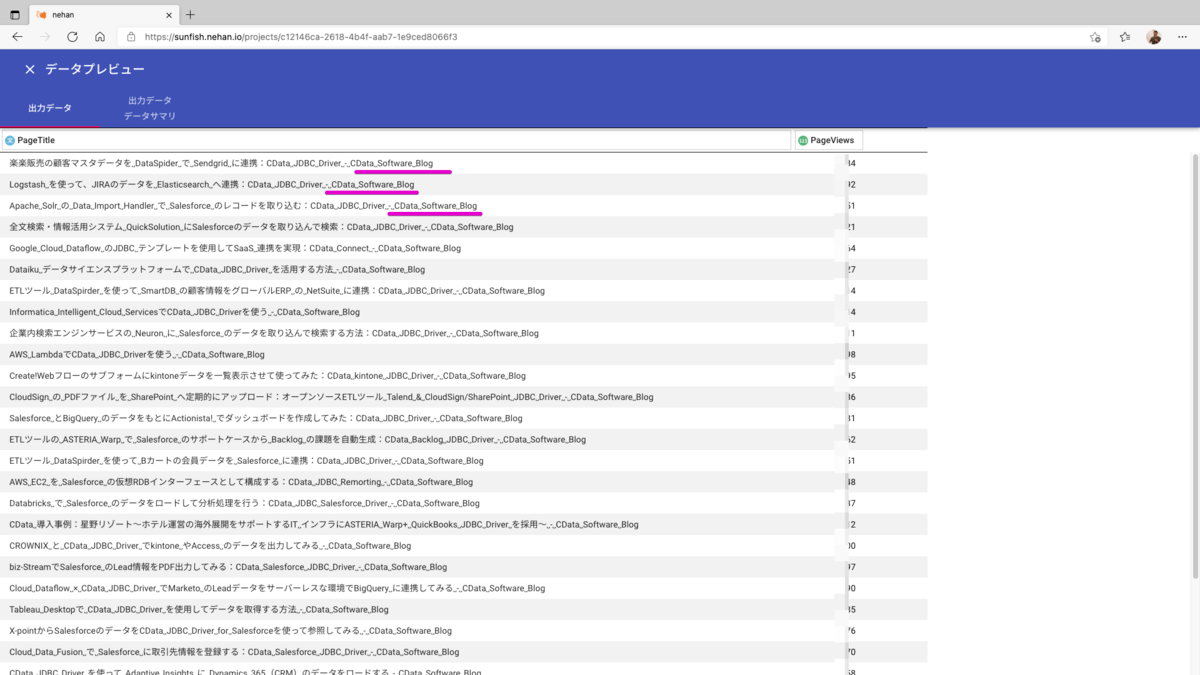
実行して画面右側の処理前後のデータを比較してPageTitle内の「 - CData Software BLog・CData・JDBC・Driver」が取り除かれていることを確認します。
次に日本語のブログタイトルを名詞のみをスペース区切りに分解します(形態素解析といいます)。
例:「kintone データをGoogle スプレッドシートでリアルタイム利用」-> 「kintone データ Googleスプレッドシート リアルタイム 利用」
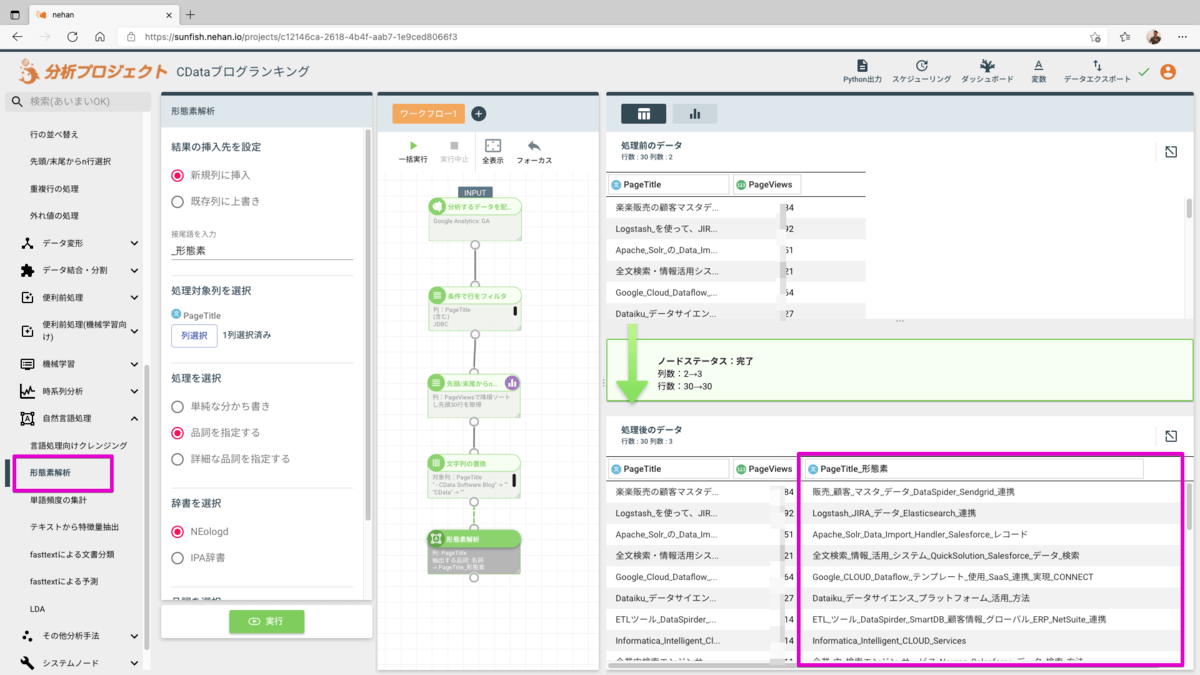
左メニューの自然言語処理 > 形態素解析 を追加して以下の値をセットします。
- 結果の挿入先を設定 : 新規列に挿入
- 処理対象列を選択:PageTitle
- 処理を選択:品詞を特定する
- 辞書を選択:(デフォルトの)NEologd
- 品詞を選択:名詞
実行するとPageTitle_形態素 という列が追加され、名詞のみの単語毎にスペース区切りの文字列に変換されて格納されていることを確認できます。
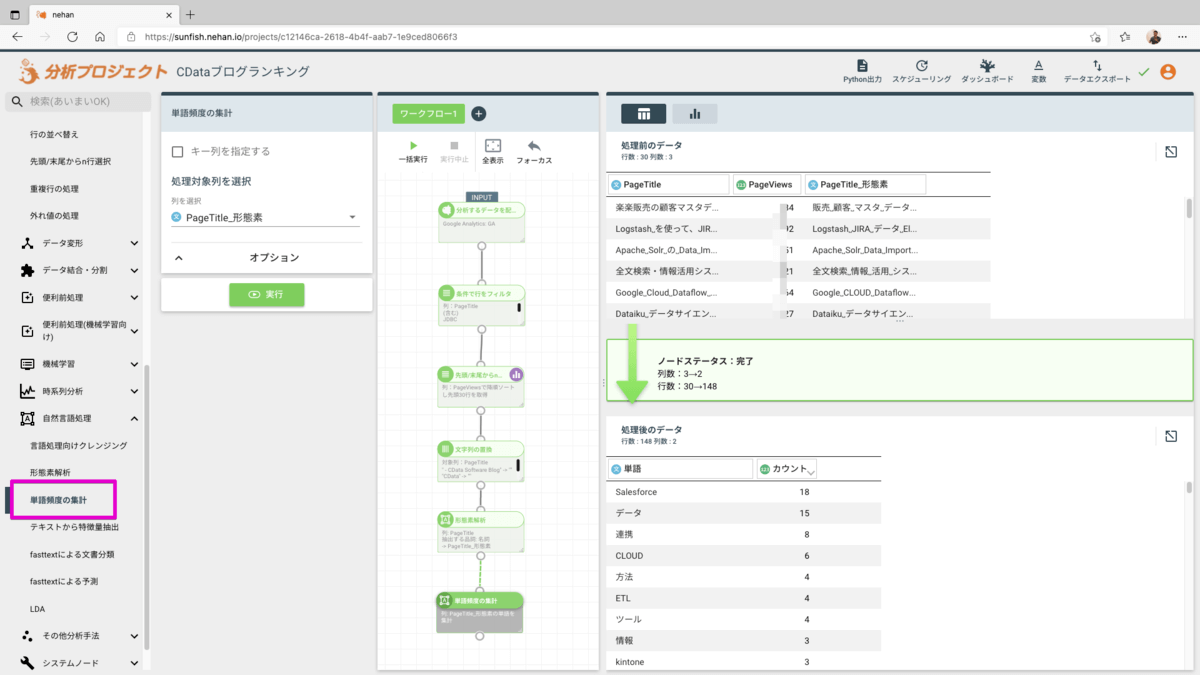
最後に単語頻度を集計してみましょう。左メニューの自然言語処理 > 単語頻度の集計を追加します。処理対象列としてPageTitle_形態素を設定します。実行すると単語が含まれるページ数の集計値を取得することができます。
処理後のデータをプレビュー > グラフで開いてみましょう。ワードクラウドグラフで人気記事に含まれるキーワードを可視化することができます。キーワードを見ていると私たちがよく利用しているキーワードである「データ 連携」に加えて「Salesforce」をはじめとした「kintone・SharePoint・Sendgrid・BigQuery」といった人気のデータソース、更に、JDBCインタフェースを利用できるツールとして「ETL・ASTERIA・DataSpider・Talend」といったキーワードがJDBC関連の人気記事に含まれていることがわかります。

まとめ
本記事では、弊社の技術ブログのアクセス数をnehanからGoogleAnalytics経由で取得して分析した結果をご紹介しました。ノーコードでデータの前処理から可視化までの分析を行えるWebサービスnehanについてはこちらのサイトにより詳しい情報がありますので同じような分析をしたい!という方はnehan社にお問い合わせしてみてはいかがでしょうか。
nehan.io
関連コンテンツ



