こんにちは。CData Software Japan リードエンジニアの杉本です。
CData ではBigQuery やSnowflake、PostgreSQL などのRDB やDWH にデータをレプリケーションするためのデータパイプラインツール「CData Sync」を提供しています。
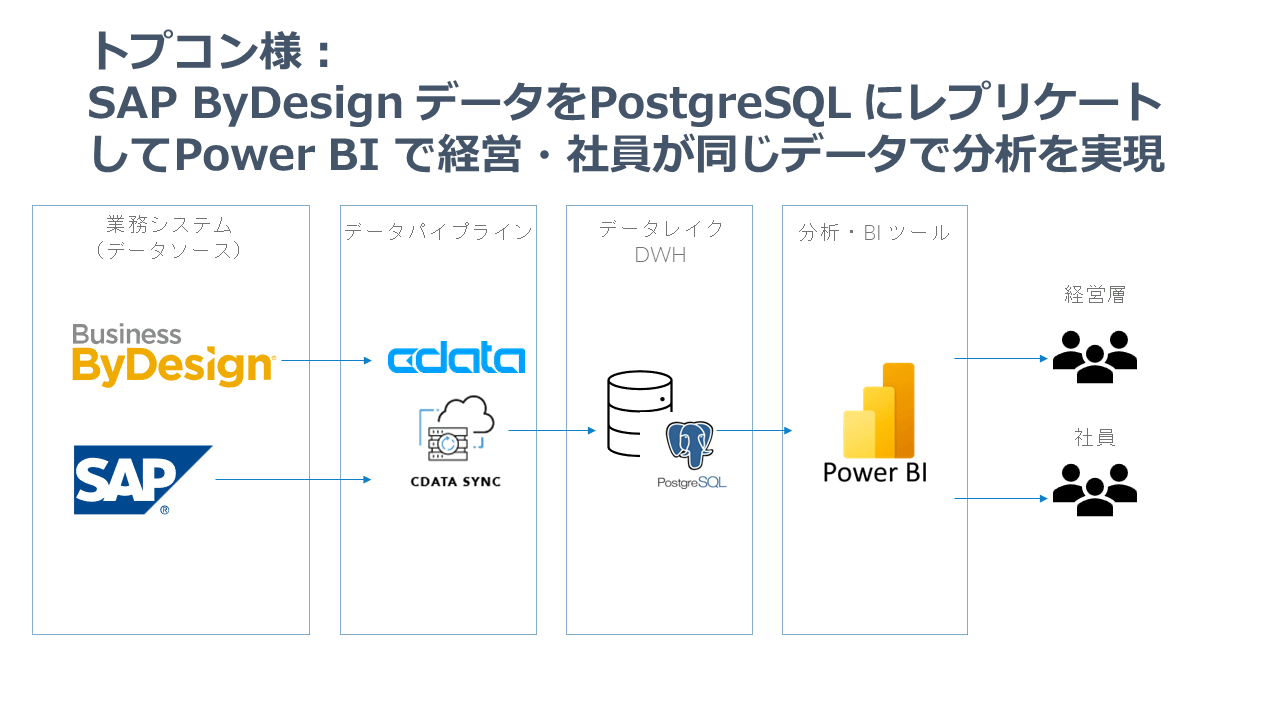
例えば以下のような事例のように活用されています。
https://www.cdata.com/jp/case-study/topcon/
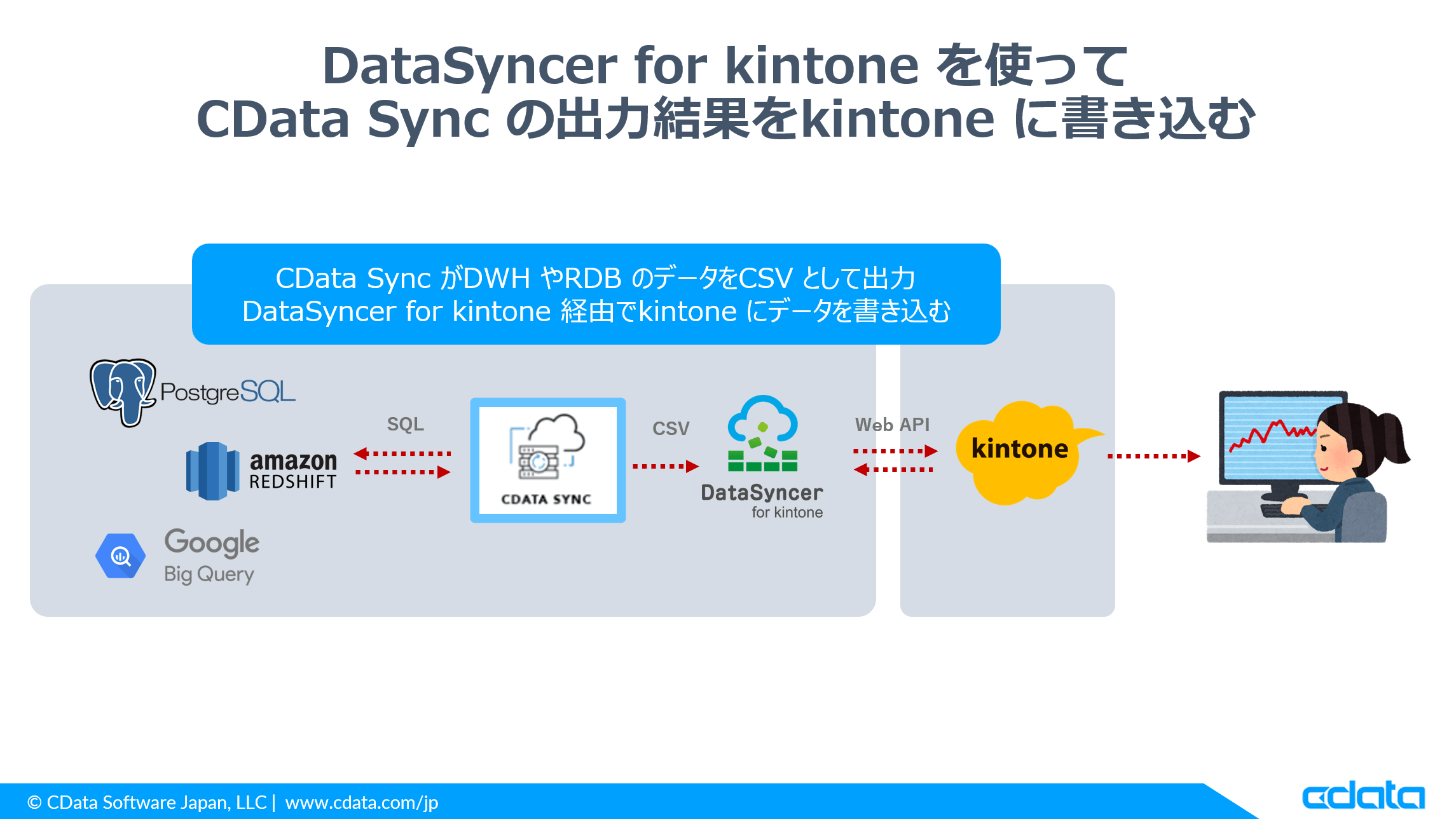
しかしながら、CData Sync はあくまでRDBやDWHにデータを渡すことを主眼としているためSalesforce やkintone に対してデータを書き込むことはできません。
とはいえ、最近レプリケーションしたデータの売上や問い合わせなどの分析結果をもとに顧客ランクなどを計算して、それをkintone に下記戻したいといったニーズもよく伺います。
そこで今回は「DataSyncer for kintone」というサービスとCData Sync を組み合わせて、CData Sync の出力結果をkintone に書き込む方法を紹介したいと思います。
DataSyncer for kintone とは?
DataSyncer for kintone はクラフテクスが提供するCSVファイルのkintone 連携に特化したアプリケーションです。
オンプレミス環境に配置して実行することで所定のフォルダを監視し、そこに配置されたCSVファイルを自動的に対象のkintone アプリに取り込むことができるようになっています。
https://datasyncer.craftex.jp/

対象のCSV ファイルの取り込みアプローチもかなり柔軟にできるようになっており、管理用のkintone アプリでマッピングなどが調整できます。
シナリオ
CData Sync はデータのレプリケーション先の一つとして、ローカルのCSVファイル出力機能を備えています。今回はこのCSV ファイル出力機能とDataSyncer for kintone を組み合わせて、kintone へのデータ書き込みを実現します。

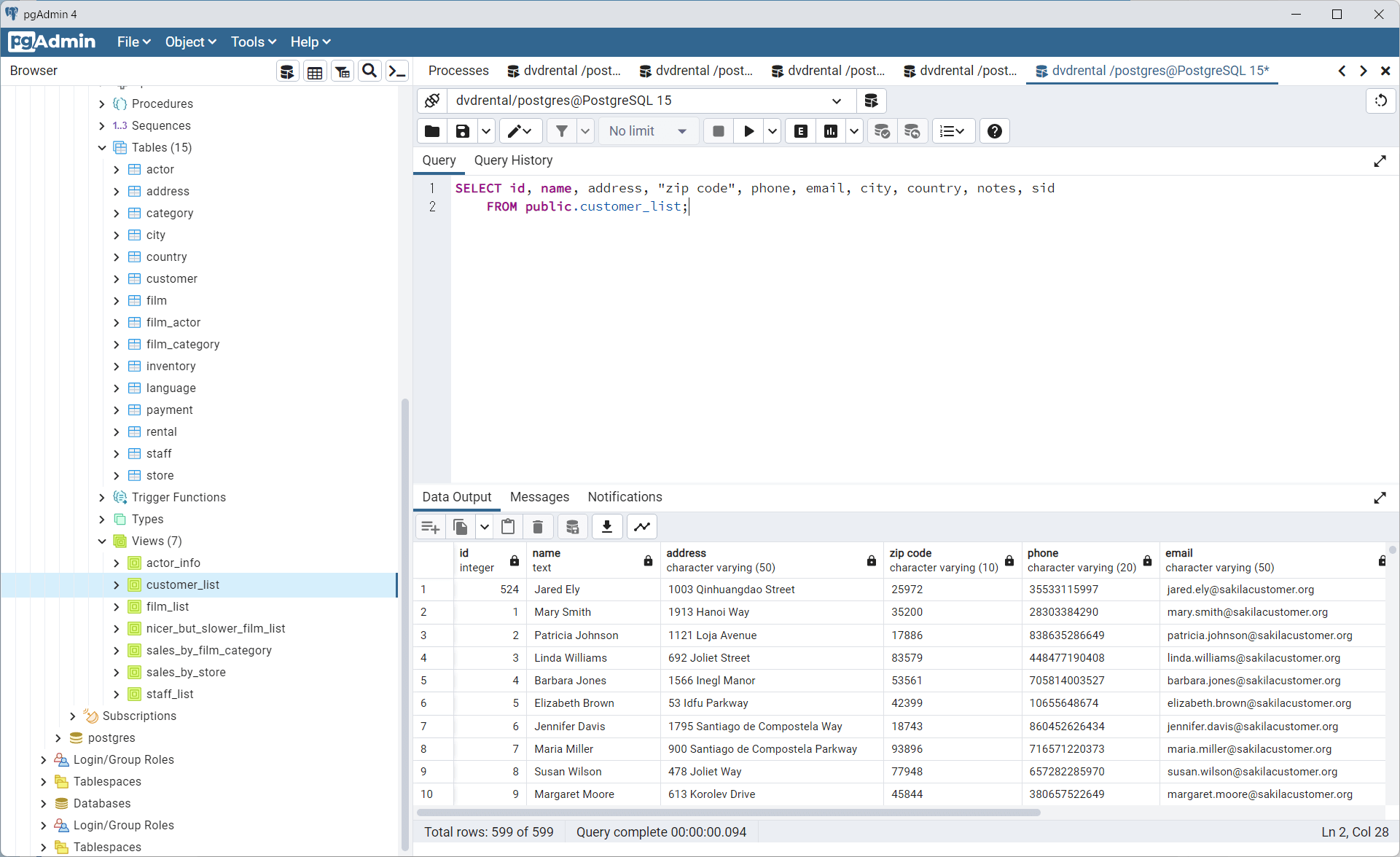
対象のデータはPostgreSQL としました。以下のような顧客情報をCSVとして出力し、DataSyncer for kintone 経由でkintone アプリに登録します。
今回はPostgreSQL で提供されているサンプルデータベースですが、もちろん各種クラウドサービスからレプリケーションした結果を集計などの処理をして、CSV として吐き出すような構成も可能です。
DataSyncer for kintone 実行ファイル、監視フォルダの準備
それでは実際に準備を進めていきましょう。
まずDataSyncer for kintone の実行ファイルを任意のフォルダに配置します。最初の実行時にアプリケーション登録が必要なので、必要な情報を採取してクラフテクスのサポートに連絡しておきます。
次に監視対象となるフォルダを作成しておきます。監視対象の「C:\datasyncer_path\spool」と結果を保存する「C:\datasyncer_path\archive」フォルダを作成しました。
CSV登録設定を作成
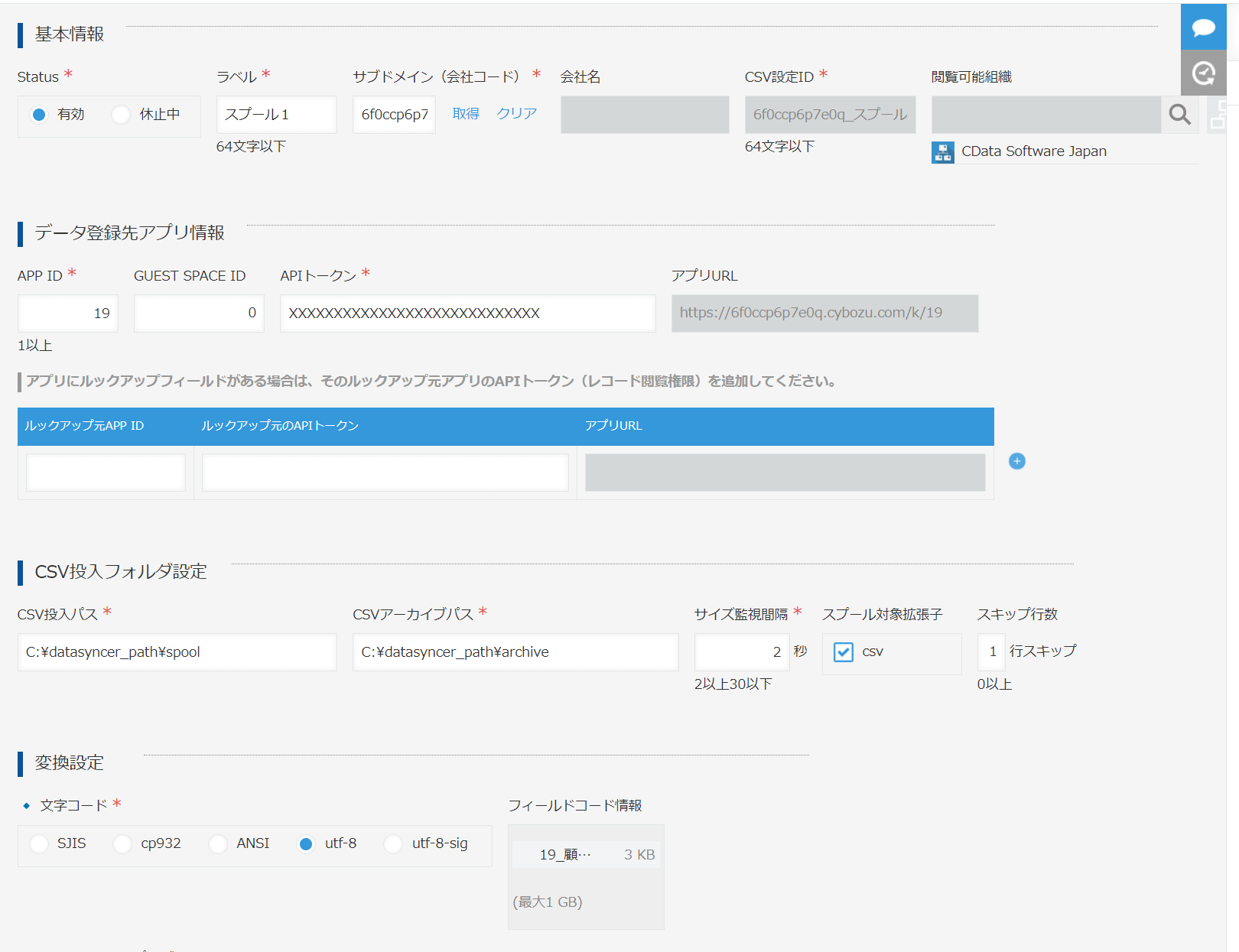
次に「DataSyncer for kintone」のCSV登録設定を専用のkintone ページにて行います。
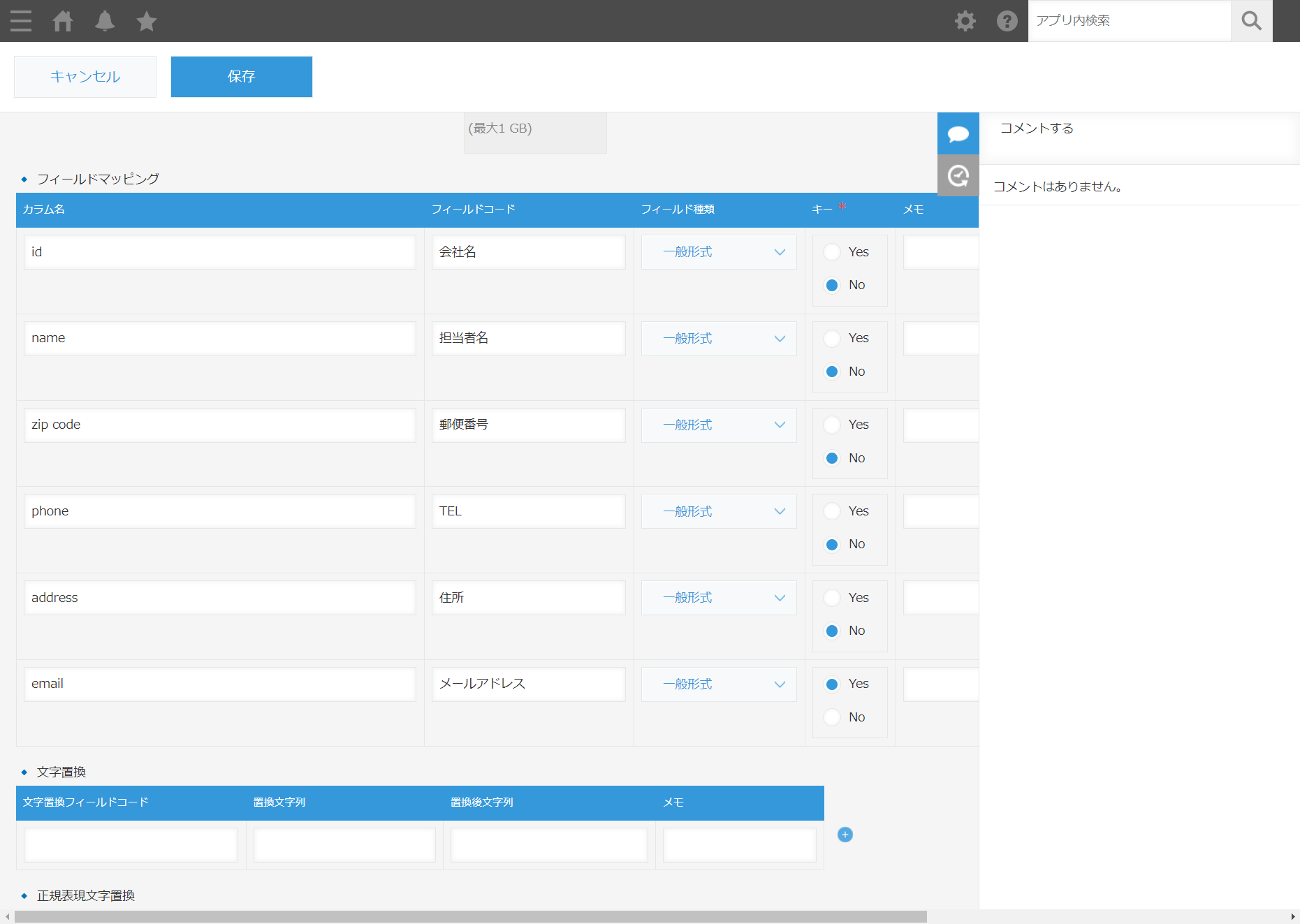
予め対象のkintone アプリからAPP IDとAPI トークンを取得しておき設定します。合わせてCSV 投入パスとCSV アーカイブパスに先程作成したフォルダパスを指定しておきます。
文字コードは「utf-8」を指定します。
次にCSVファイルとのマッピングを作成します。今回は以下のような顧客リストを対象にデータを登録します。
データベースから出力される項目をもとに、フィールドコードを指定します。更新用のキーなども独自に指定できるのが良いですね。kintone はデータを更新する際に予めRecordId を特定する必要があるのですが、このあたりをDataSyncer for kintone が良い具合にやってくれるのがとても良いです。
これで準備は完了です。
CData Sync のセットアップ
続いてCData Sync 側の作業を進めます。CData Sync は任意の環境にホスティングして利用できるのが特徴です。そのため、DataSyncer for kintone と同じ環境に配置して利用することができます。
https://www.cdata.com/jp/sync/
以下のURLからWindows 版を選択して、トライアルを入手、対象のマシンにインストールしておきましょう。
https://www.cdata.com/jp/sync/download/
データソースの設定
セットアップが完了したら、接続先を追加していきます。今回はPostgreSQLからCSV出力を行うので、2つの接続先を追加します。
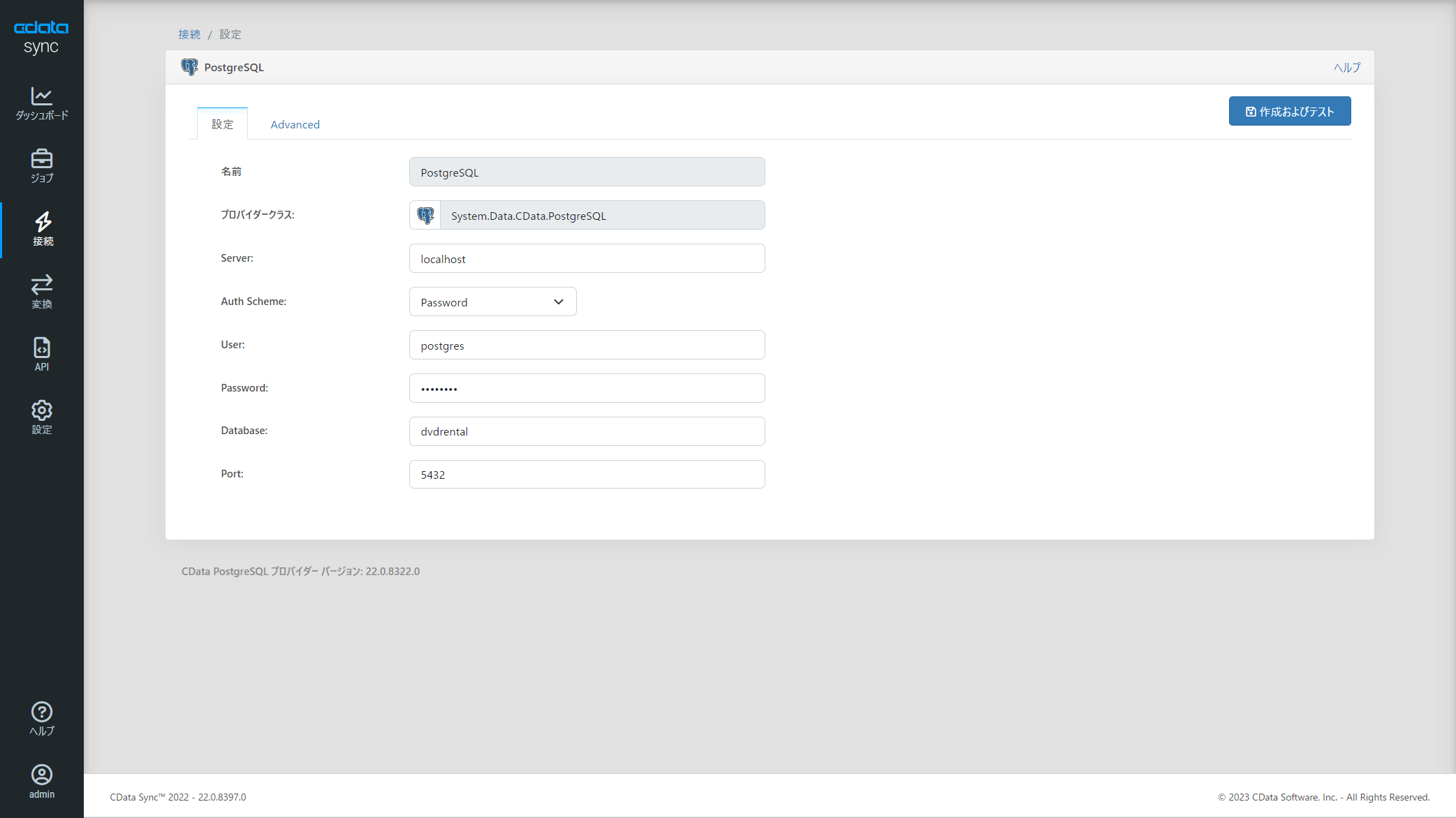
「接続」→「データソース」→「PostgreSQL」を選択し

対象のPostgreSQL の接続情報を入力します。
同期先を設定
続いて同期先となるCSV 接続を追加します。
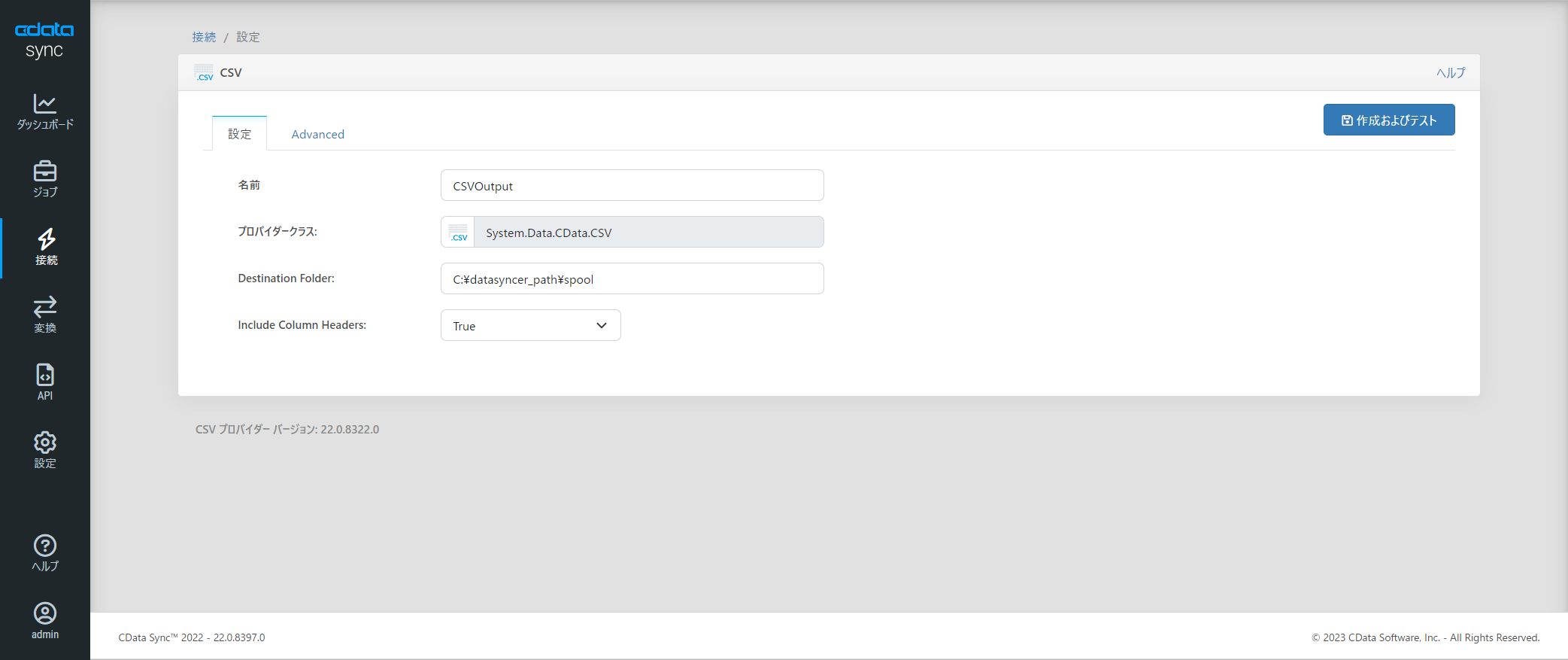
「接続」→「同期先」→「CSV」を選択し
先程作成しておいた監視対象のフォルダパスを「Destination Folder」に指定します。
ジョブを作成
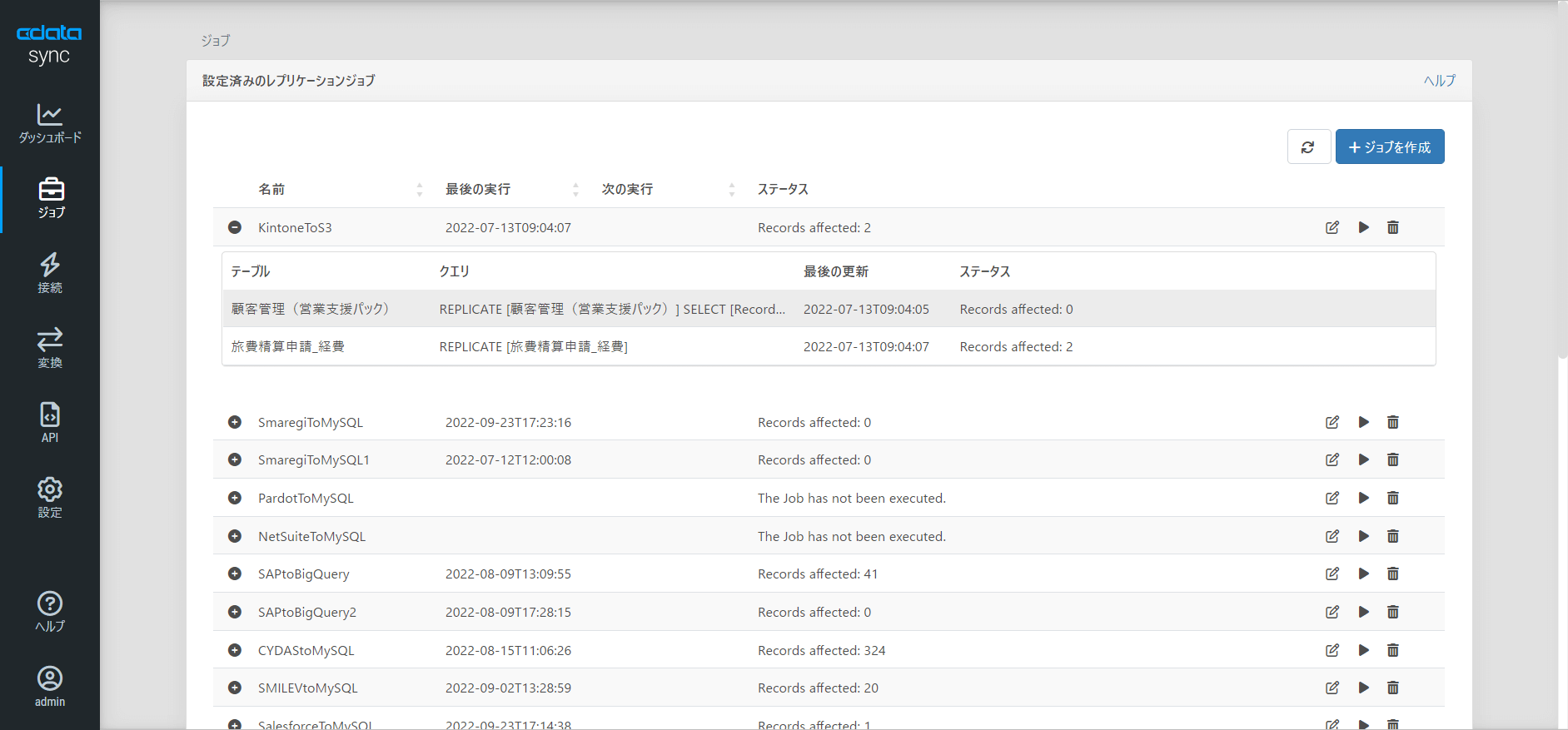
接続の作成が完了したら、ジョブを登録しましょう。
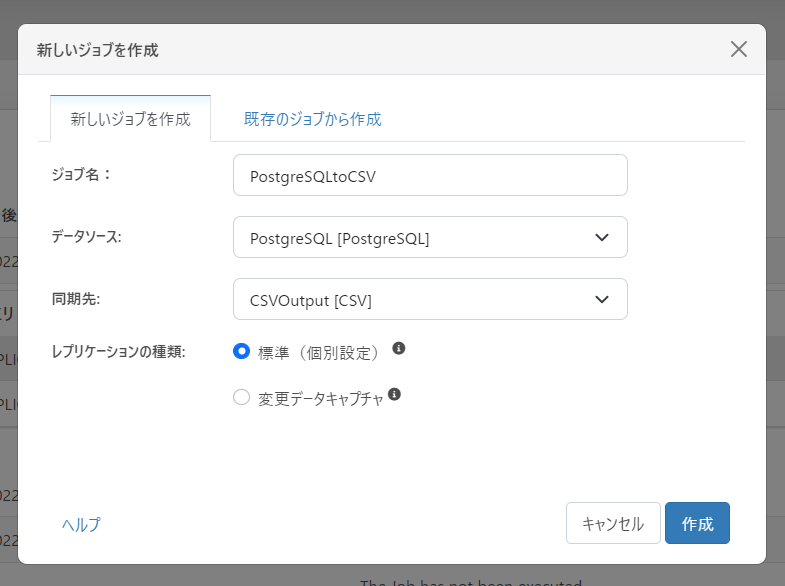
「ジョブ」の画面から「+ジョブを作成」をクリックし
先程作成したPostgreSQL とCSV の接続をそれぞれデータソースと同期先に指定します。
続いてタスクを追加します。「+タスクを追加」をクリックし
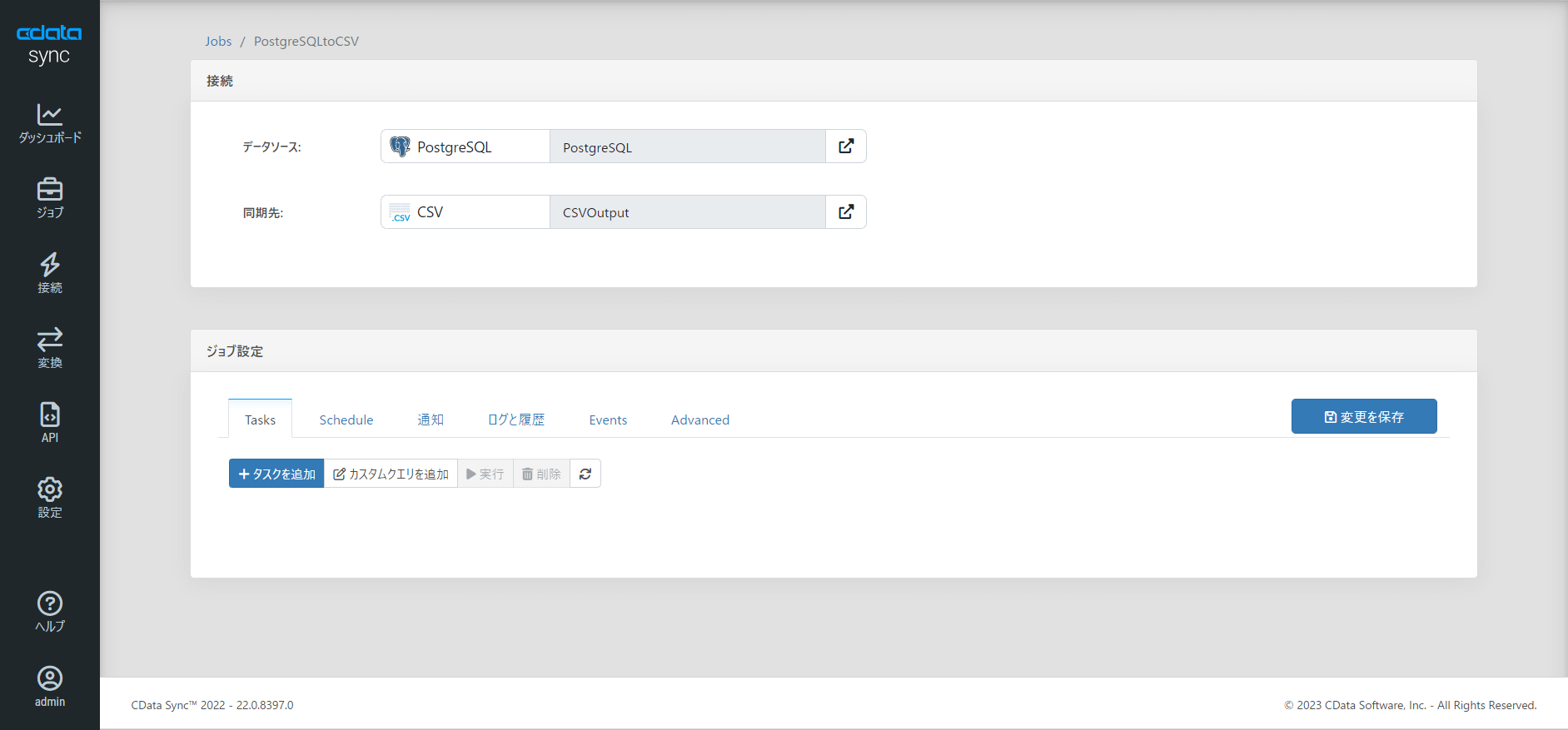
顧客データが表示できる「customer_list」を選択します。
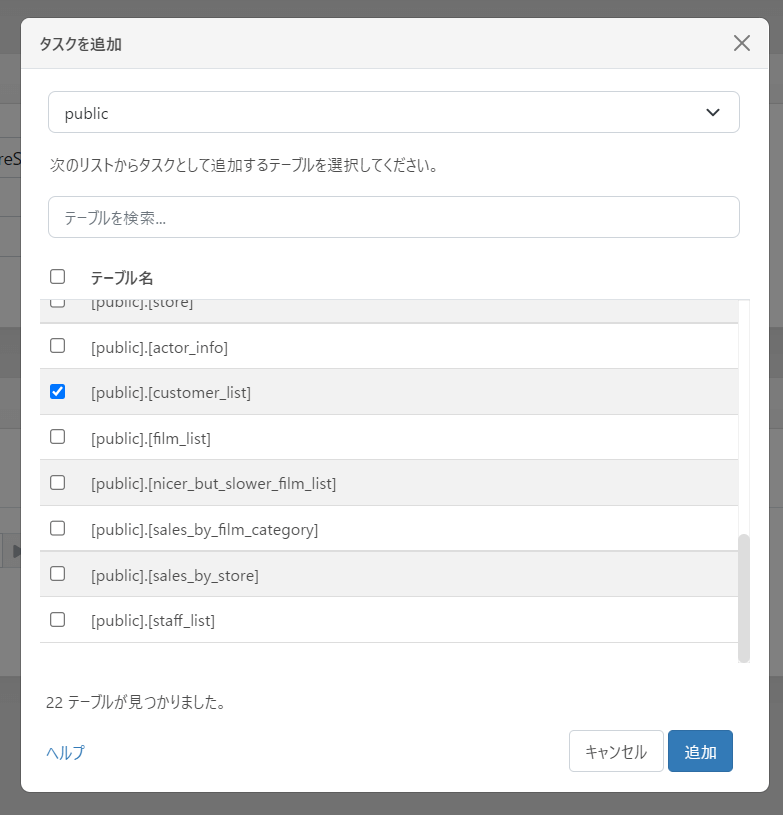
タスクを追加したら、タスクの設定から細かなカラムの設定などが変更できます。ここで不要なカラムを消したり、変換したり、取得条件のフィルターを指定することも可能です。
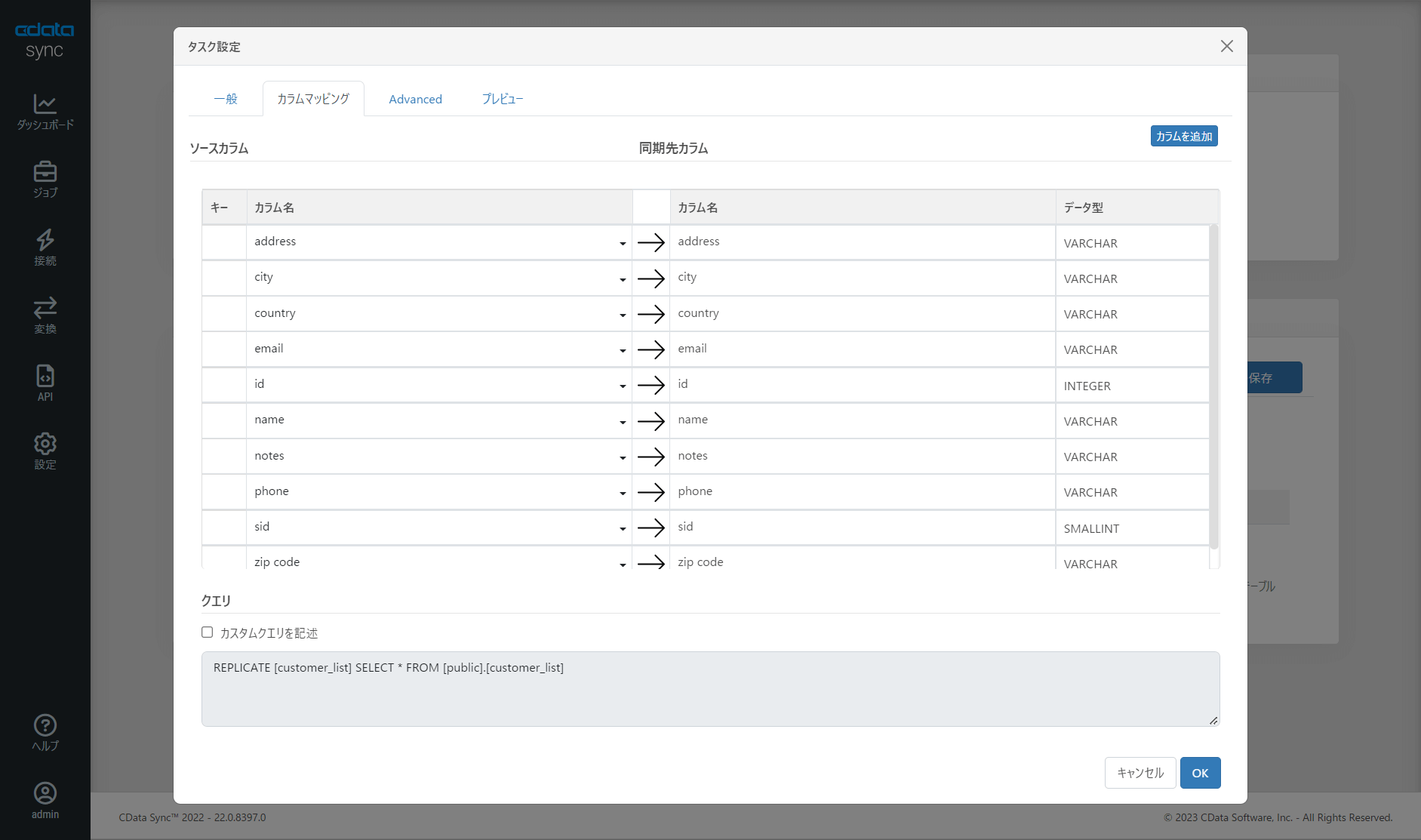
取得結果のイメージはプレビュー画面から確認できます。
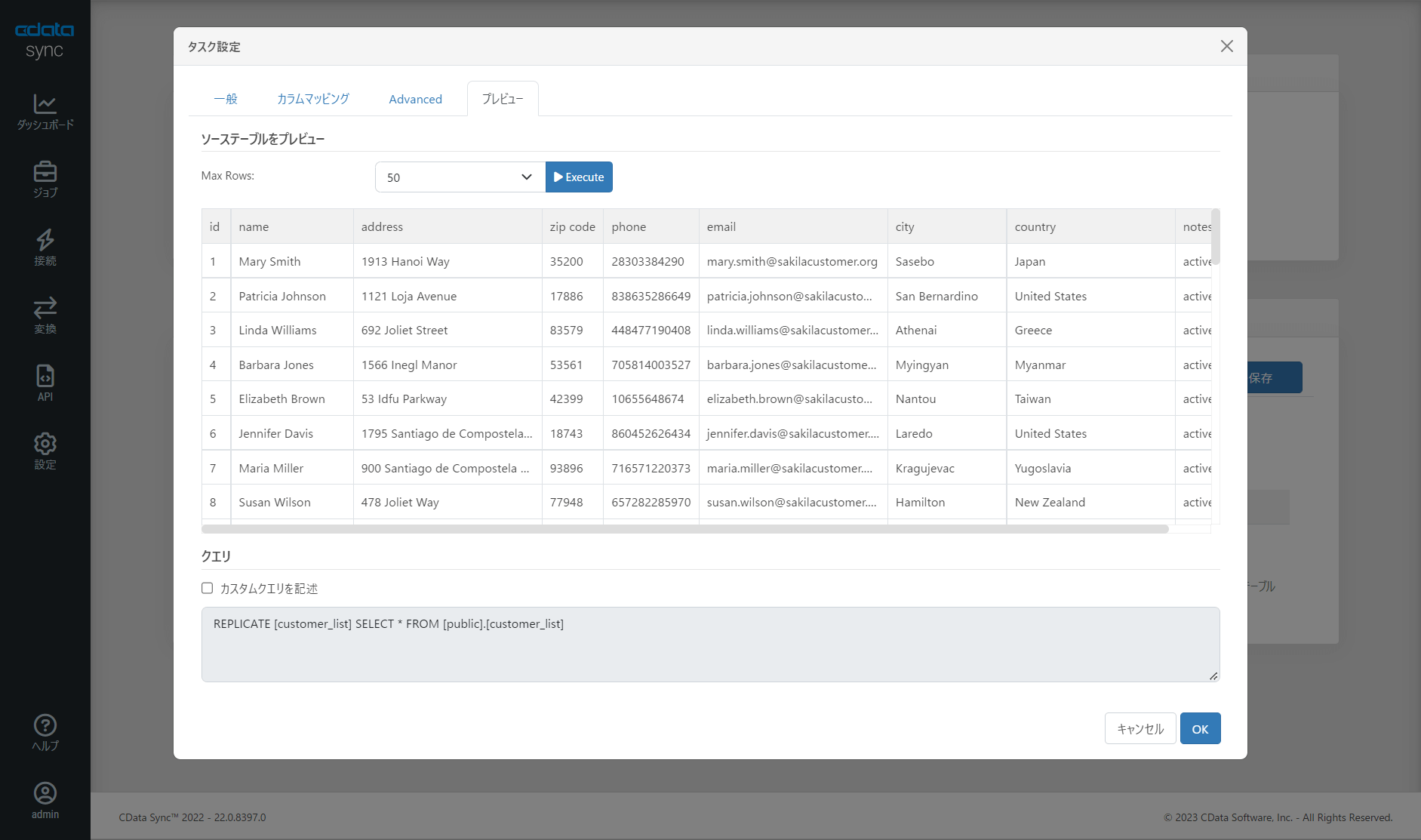
実行・スケジュールの設定
それでは実際に動かしてみましょう。通常CData Sync はスケジュールタブから自動実行のタイミングを登録して利用します。
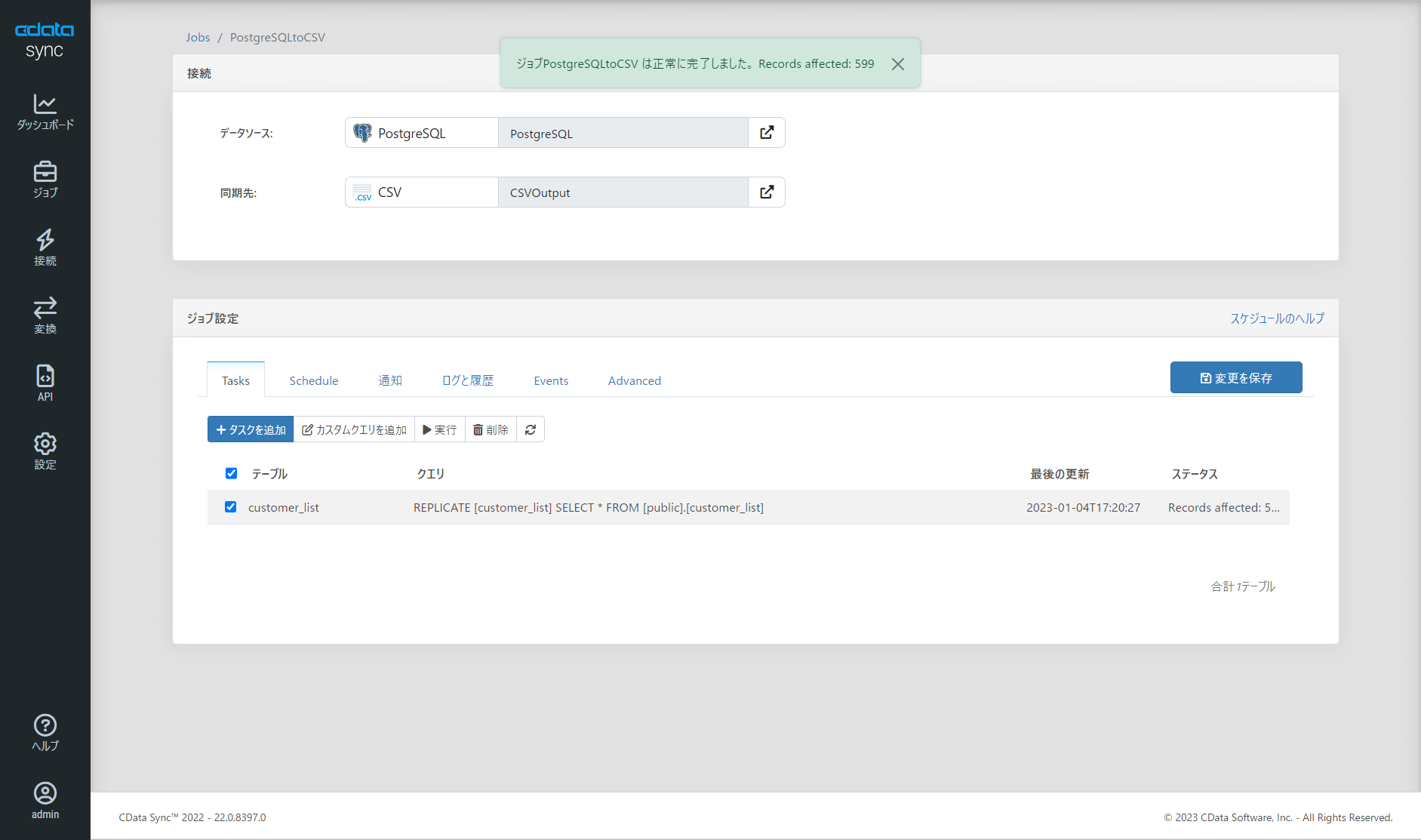
今回はテスト実行なので、タスクの一覧画面から対象のタスクを選択して手動実行しました。成功するとレコードの出力件数が表示されます。
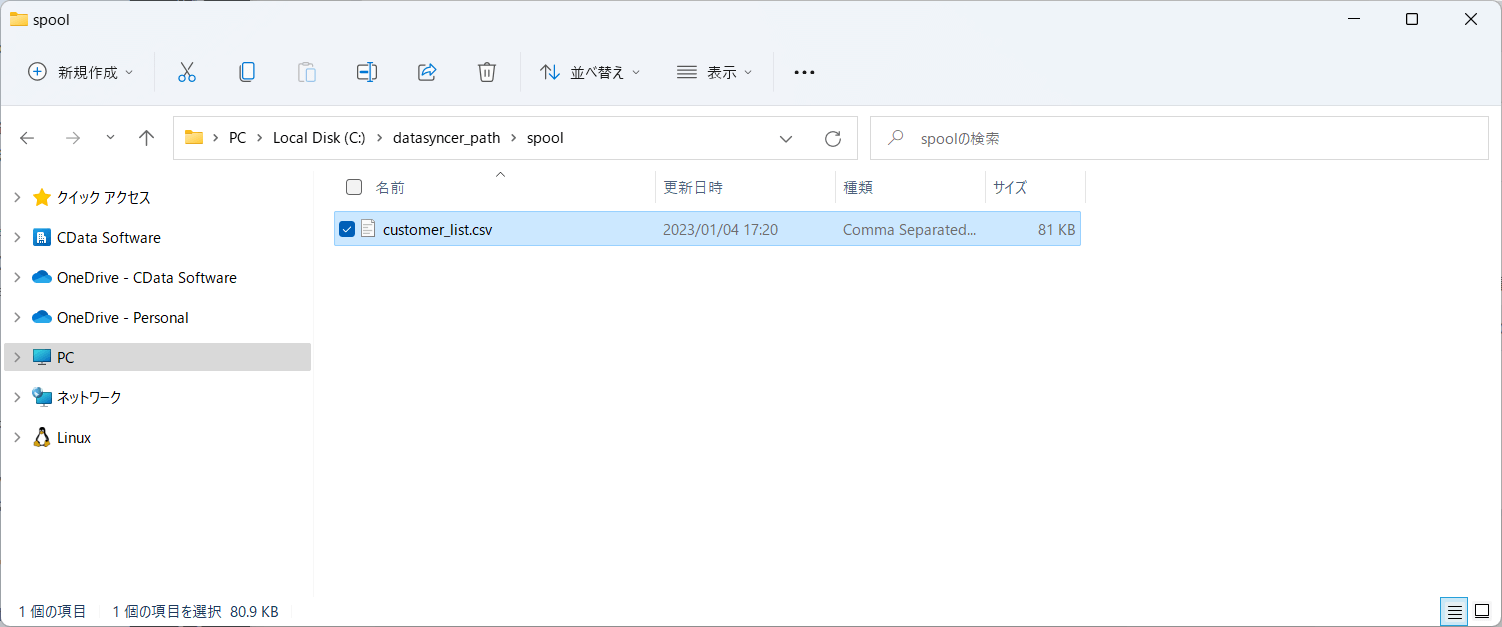
対象のフォルダを確認してみると、以下のようにCSVファイルが生成されていることが確認できました。
DataSyncer for kintone が実行されていると自動的にファイルを読み取って、処理してくれます。
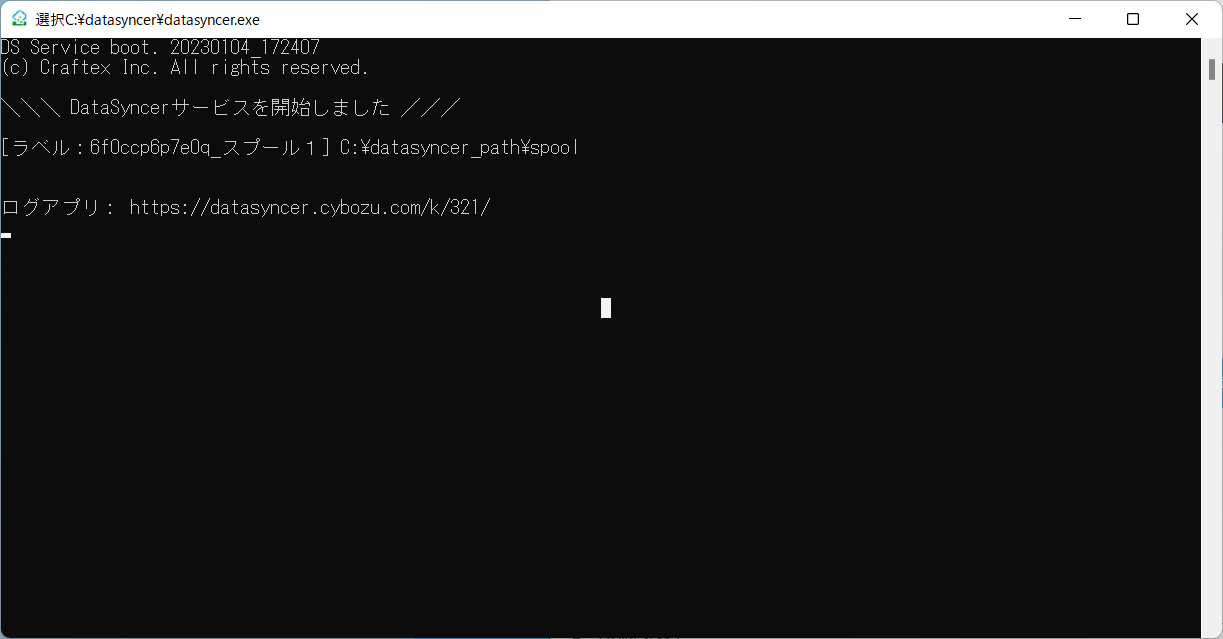
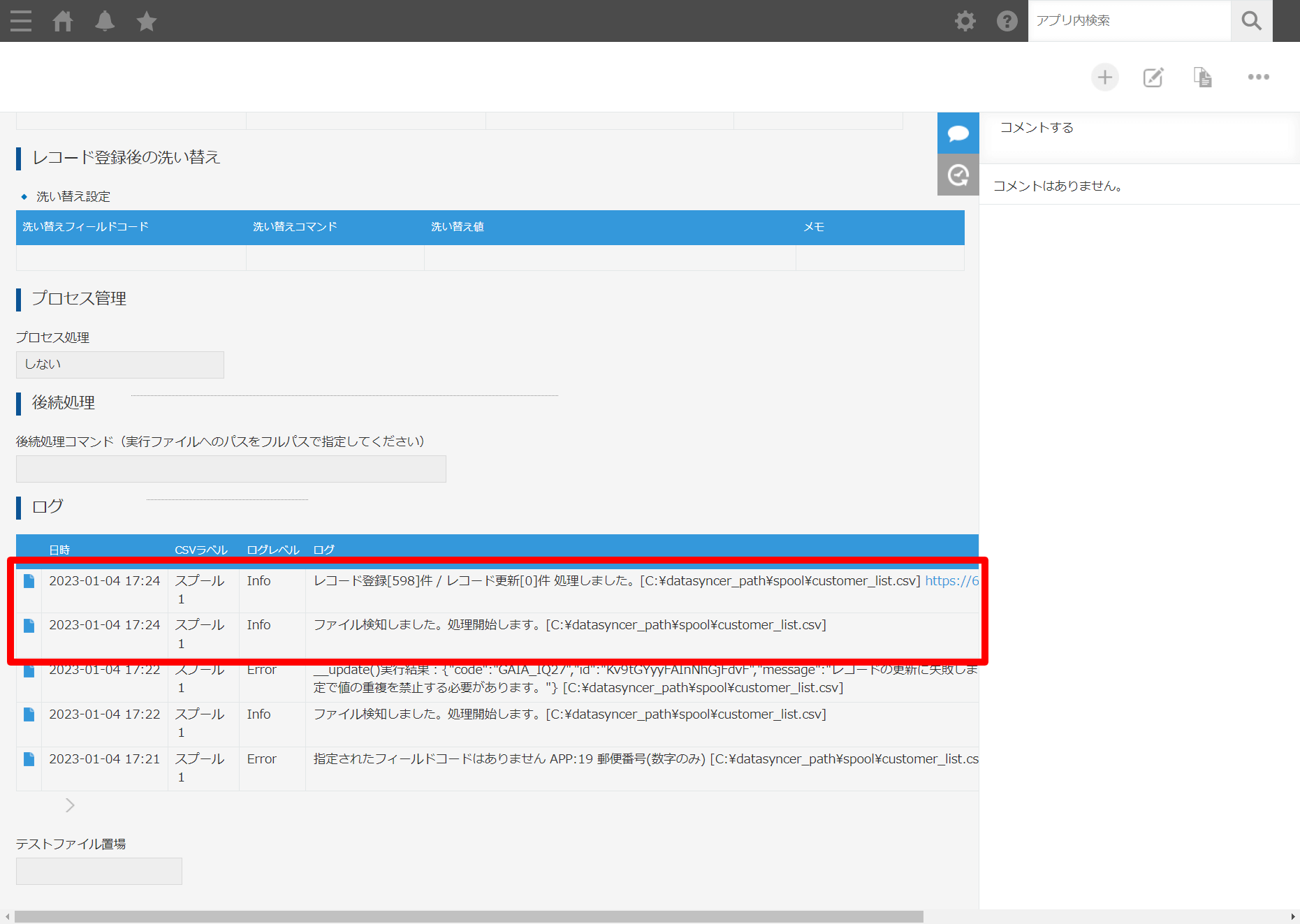
DataSyncer for kintone の管理画面でも成功したログが表示されています。
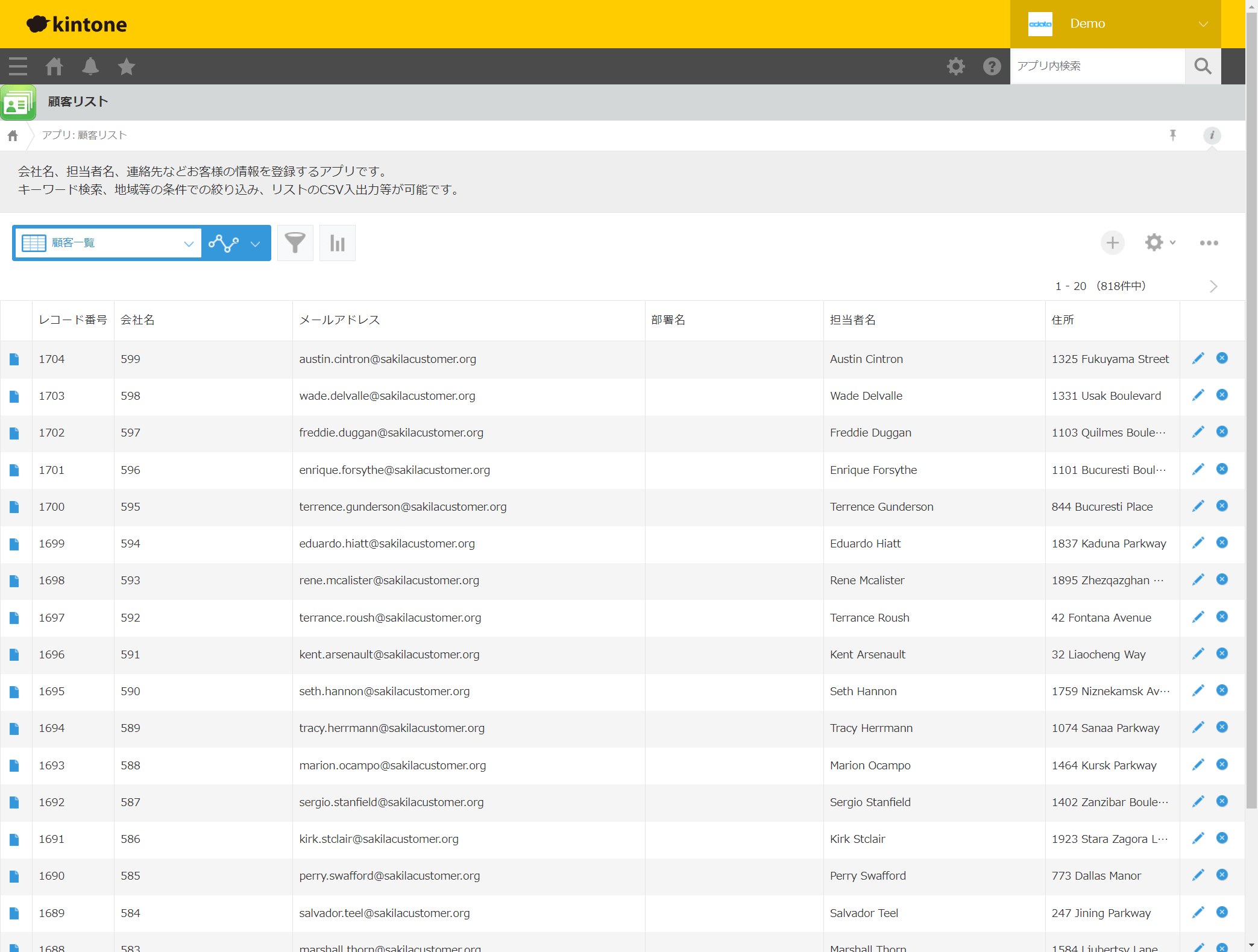
対象のkintone アプリを確認してみると、以下のようにPostgreSQL のデータがkintone に登録されていることが確認できました!
おわりに
このようにDataSyncer for kintone とCData Sync を組み合わせることで、簡単にkintone へのリバースETL 処理が実現できます。
今回はPostgreSQL を対象としましたが、CData Sync ではSAP ERP やDB2 など様々なデータソースに接続できます。
ぜひお好みのサービスと組み合わせて、kintone 連携を実現してみてください。
製品について気になることがあれば、お気軽にテクニカルサポートまでお問い合わせください。
https://www.cdata.com/jp/support/submit.aspx
関連コンテンツ



