CData Virtuality Web InterfaceからJobsを開き、「New Job」ボタンをクリックします。
データソースの選択画面からレプリケーションするテーブルを選択して「Next」ボタンをクリックします。本手順ではMicrosoft SQL Server内の「Customers」テーブルを選択します。

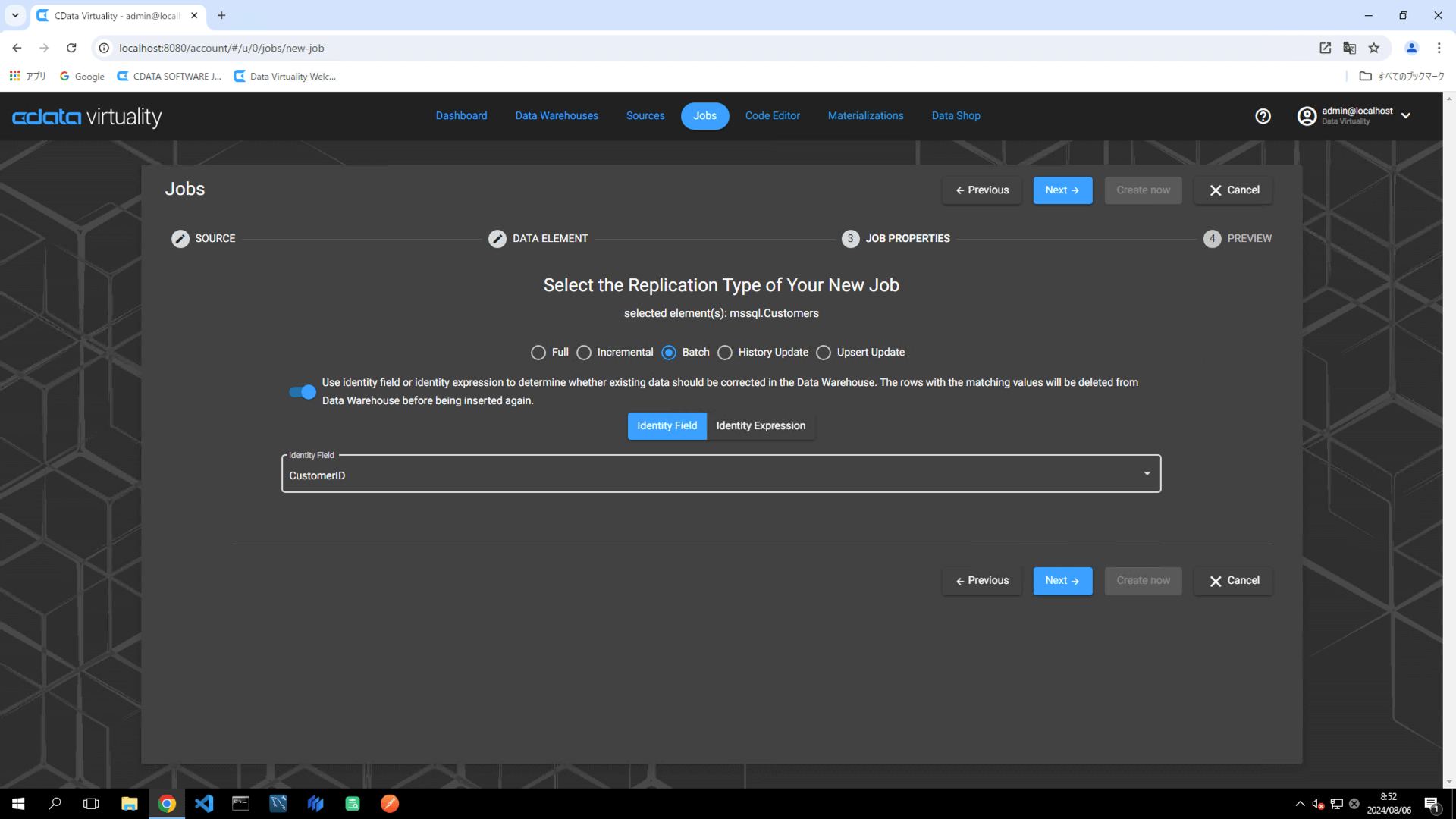
レプリケーションのタイプが選択できますので、本手順では「Batch(バッチ更新)」を選択します。まずはじめに「Use identity field...」をOFFにして実行してみます。

Data Warehouse, Target Schema, Title(「mssql_customers_batch_off」に変更), Schedule, Start Immediately(即時実行:ON)が設定されていることを確認します。
Scheduleについては「Every night(at 12:00 AM)」となっていますがより柔軟なスケジュール設定を行う場合は、「Advanced Scheduling」ボタンをクリックして設定てください。

「Create now」ボタンをクリックしてレプリケーションジョブを実行します。
Dashborad画面が開き、作成したJobが追加されていることを確認します。

しばらく時間が経過してジョブのStatusがSuccessful(成功)になっていることを確認します。画面が更新されない場合はRefreshしてください。

データウェアハウス(本記事ではSnowflake)にアクセスしてテーブルにどのようにデータが格納されているか確認してみましょう。レコードが格納されていることが確認できます。

作成したジョブの詳細はJobs画面から参照・編集することが出来ます。JOB Typeが「sql」、TITLEが「Batch replication from mssql.Customers to snowfl」となっているジョブです。

再度、同じジョブを実行してみて、データウェアハウス(本記事ではSnowflake)にどのようにデータが格納されているか確認してみましょう。「Use identity field...」をOFFにした状態で実行すると、実行の都度、全件、既存テーブルにレコードが追加される動作となりますので重複レコードが登録されます。

ジョブ作成時の設定で「Use identity field...」をONにした状態でジョブを実行した場合どうなるか確認してみましょう。
Jobの作成画面にてテーブル(本手順ではMicrosoft SQL Server内の「Customers」テーブル)を選択、「Batch(バッチ更新)」を選択し、「Use identity field...」をON、「Identity Field」にはデーターソース側のテーブルでユニークなIDナンバーを生成するフィールド(本例ではCustomerID)を指定して次に進みます。
Data Warehouse, Target Schema, Title(「mssql_customers_batch_on」に変更), Schedule, Start Immediately(即時実行:ON)が設定されていることを確認します。

「Create now」ボタンをクリックしてレプリケーションジョブを実行します。
Dashboard画面でジョブの実行が正常に完了することを確認します。

データウェアハウス(本記事ではSnowflake)にアクセスしてレプリケーション先のテーブルを確認します。

それでは、データソース(Microsoft SQL ServerのCustomersテーブル)側に1レコード追加して再度ジョブを実行してみましょう。
INSERT INTO Customers (CustomerID, CompanyName, ContactName, ContactTitle, Address, City, Region, PostalCode, Country, Phone, Fax) VALUES ('BAT01', 'BAT01_CompanyName', 'BAT01_ContactName', '', '', '', '', '', '', '', '');
データウェアハウス(本記事ではSnowflake)にアクセスしてレプリケーション先のテーブルを確認します。データソース側に追加した1レコードがレプリケーション先にも連携されおり、重複レコードも発生していないことが確認できます。

レプリケーション(Batch)の作成手順は以上となります。
Incremental(増分更新)
CData Virtuality Web InterfaceからJobsを開き、「New Job」ボタンをクリックします。
データソースの選択画面からレプリケーションするテーブルを選択して「Next」ボタンをクリックします。本手順ではMicrosoft SQL Server内の「Orders」テーブルを選択します。

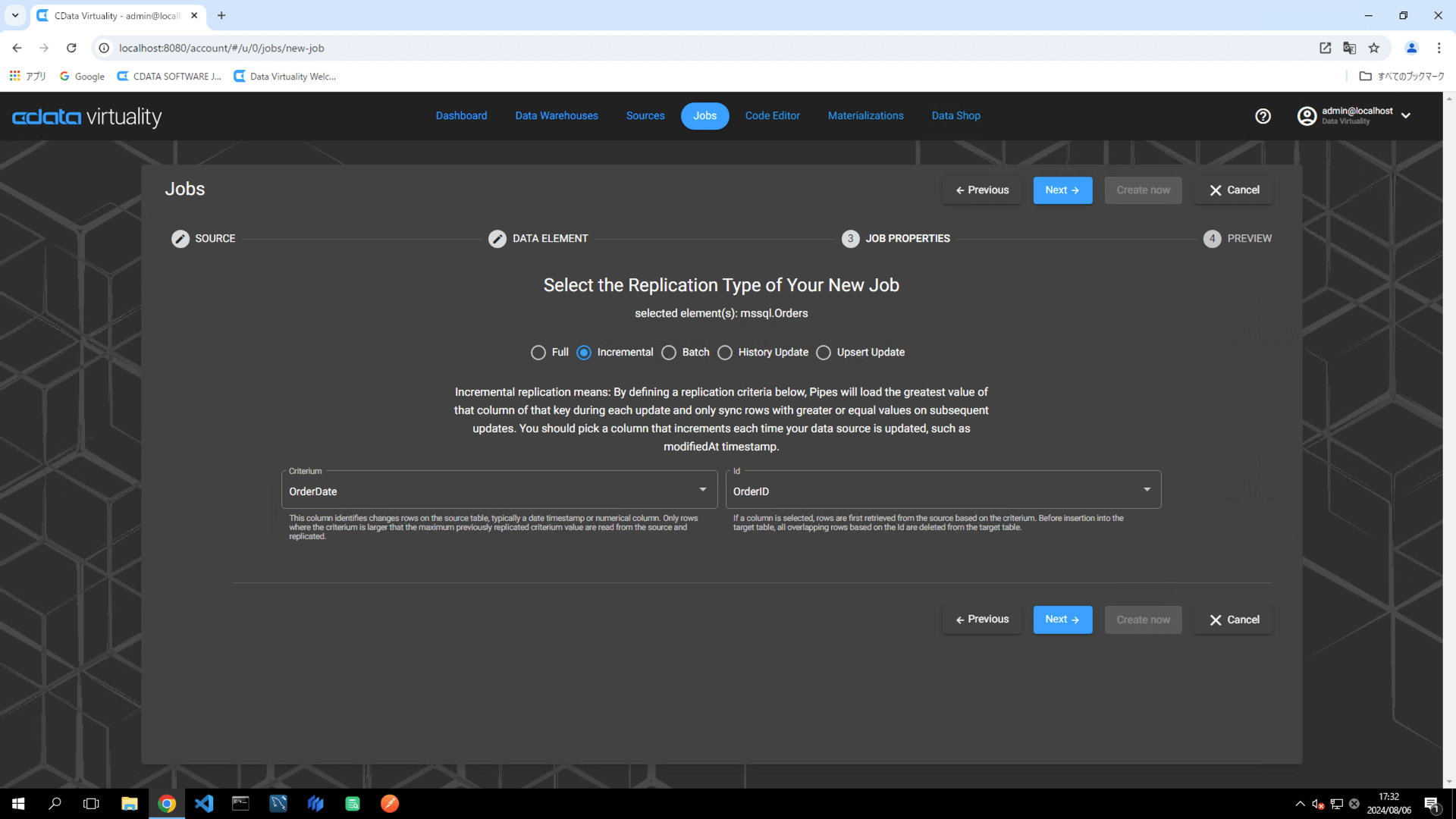
レプリケーションのタイプが選択できますので、本手順では「Incremental(増分更新)」を選択します。Criteriumには、変更行を識別するフィールドで通常は日付タイムスタンプもしくは数値列(本例では OrderDate)、Idにはレコードを一意に特定するフィールド(本例ではOrderID)を指定します。
Data Warehouse, Target Schema, Title(「mssql_orders_incremental」に変更), Schedule, Start Immediately(即時実行:ON)が設定されていることを確認します。
Scheduleについては「Every night(at 12:00 AM)」となっていますがより柔軟なスケジュール設定を行う場合は、「Advanced Scheduling」ボタンをクリックして設定てください。
「Create now」ボタンをクリックしてレプリケーションジョブを実行します。
Dashborad画面が開き、作成したJobが追加されていることを確認します。

しばらく時間が経過してジョブのStatusがSuccessful(成功)になっていることを確認します。画面が更新されない場合はRefreshしてください。

データウェアハウス(本記事ではSnowflake)にアクセスしてテーブルにどのようにデータが格納されているか確認してみましょう。レコードが格納されていることが確認できます。
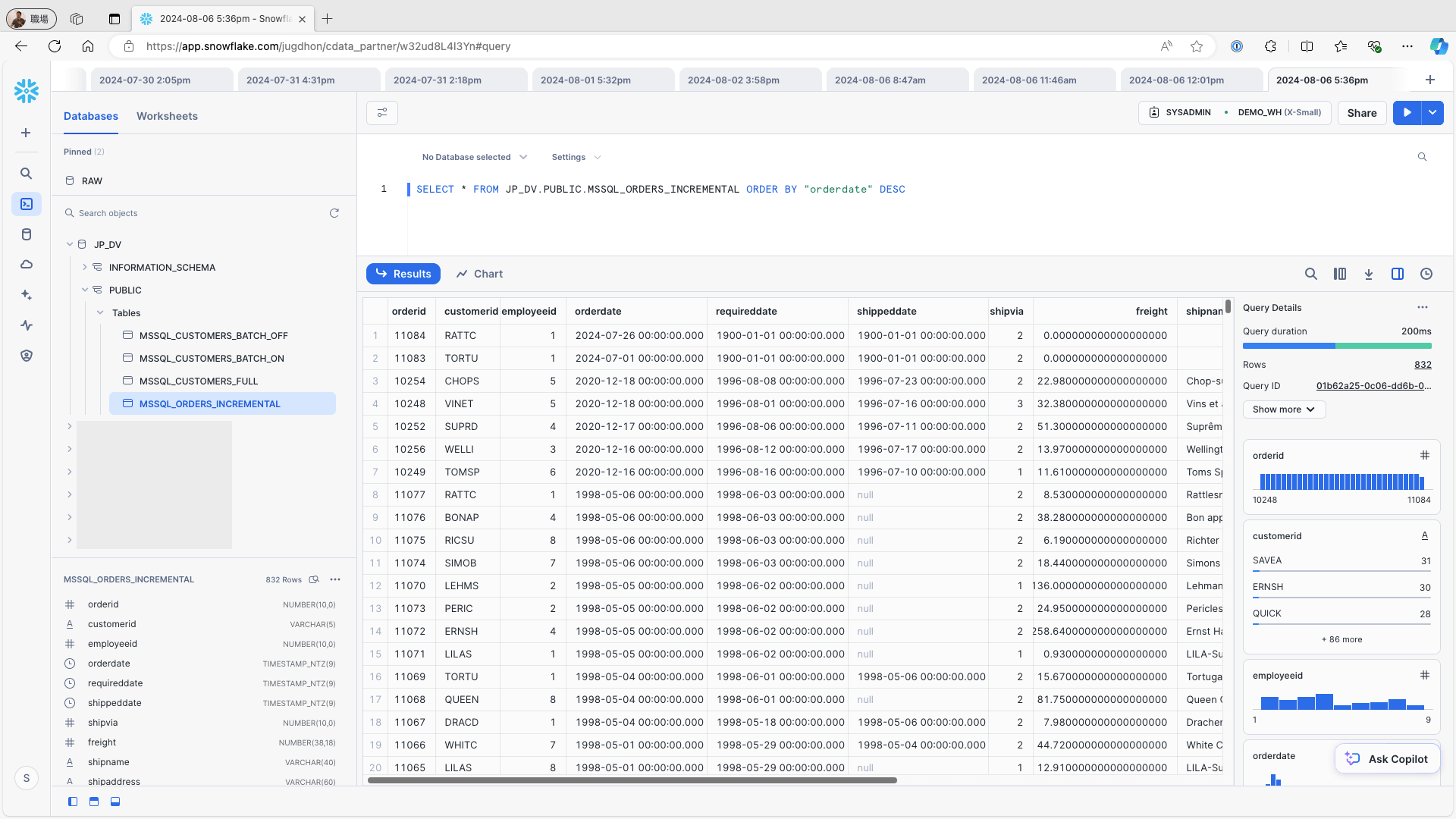
それでは、データソース(Microsoft SQL ServerのOrdersテーブル)側に1レコード追加、1レコードを変更して再度ジョブを実行してみましょう。
INSERT INTO Orders (CustomerID, EmployeeID, OrderDate,ShipCountry) VALUES ('CHOPS', 5, '2024/08/08', 'USA');
UPDATE Orders SET OrderDate = '2024/08/08' WHERE OrderID = 11085;
データウェアハウス(本記事ではSnowflake)にアクセスしてレプリケーション先のテーブルを確認します。データソース側に追加・更新したレコードがレプリケーション先にも連携されていることが確認できます。

レプリケーション(Incremental)の作成手順は以上となります。
History update(履歴更新)
CData Virtuality Web InterfaceからJobsを開き、「New Job」ボタンをクリックします。
データソースの選択画面からレプリケーションするテーブルを選択して「Next」ボタンをクリックします。本手順ではMicrosoft SQL Server内の「Orders」テーブルを選択します。
レプリケーションのタイプが選択できますので、本手順では「History update(履歴更新)」を選択します。Key Columnにはレコードを一意に特定するフィールド(本例ではOrderID)を指定します。Columns To Checkには、変更をチェックするフィールド(本例ではShipから始まる複数のフィールド)を指定します。
Data Warehouse, Target Schema, Title(「mssql_orders_history_update」に変更), Schedule, Start Immediately(即時実行:ON)が設定されていることを確認します。
Scheduleについては「Every night(at 12:00 AM)」となっていますがより柔軟なスケジュール設定を行う場合は、「Advanced Scheduling」ボタンをクリックして設定てください。
「Create now」ボタンをクリックしてレプリケーションジョブを実行します。
Dashborad画面が開き、作成したJobが追加されていることを確認します。
しばらく時間が経過してジョブのStatusがSuccessful(成功)になっていることを確認します。画面が更新されない場合はRefreshしてください。
データウェアハウス(本記事ではSnowflake)にアクセスしてテーブルにどのようにデータが格納されているか確認してみましょう。fromtimestamp, totimestampフィールドが追加されたレコードが格納されていることが確認できます。
それでは、データソース(Microsoft SQL ServerのOrdersテーブル)側に1レコード変更して再度ジョブを実行してみましょう。
UPDATE Orders SET shipname = 'SHIPNAME_UPDATE' WHERE OrderID = 11087;
データウェアハウス(本記事ではSnowflake)にアクセスしてレプリケーション先のテーブルを確認します。データソース側で更新されたレコードの履歴がレコードとして作成されていることが確認できます。

レプリケーション(History update)の作成手順は以上となります。
Upsert update (アップサート更新)
CData Virtuality Web InterfaceからJobsを開き、「New Job」ボタンをクリックします。
データソースの選択画面からレプリケーションするテーブルを選択して「Next」ボタンをクリックします。本手順ではMicrosoft SQL Server内の「Orders」テーブルを選択します。
レプリケーションのタイプが選択できますので、本手順では「History update(履歴更新)」を選択します。Key Columnにはレコードを一意に特定するフィールド(本例ではOrderID)を指定します。Columns To Checkには、変更をチェックするフィールド(本例ではEmployeeID)を指定します。
Data Warehouse, Target Schema, Title(「mssql_orders_upsert」に変更), Schedule, Start Immediately(即時実行:ON)が設定されていることを確認します。
Scheduleについては「Every night(at 12:00 AM)」となっていますがより柔軟なスケジュール設定を行う場合は、「Advanced Scheduling」ボタンをクリックして設定てください。
「Create now」ボタンをクリックしてレプリケーションジョブを実行します。
Dashborad画面が開き、作成したJobが追加されていることを確認します。
しばらく時間が経過してジョブのStatusがSuccessful(成功)になっていることを確認します。画面が更新されない場合はRefreshしてください。
データウェアハウス(本記事ではSnowflake)にアクセスしてテーブルにどのようにデータが格納されているか確認してみましょう。レコードが格納されていることが確認できます。
それでは、データソース(Microsoft SQL ServerのOrdersテーブル)側に1レコードを追加、1レコードを変更して再度ジョブを実行してみましょう。
INSERT INTO Orders (CustomerID, EmployeeID, OrderDate,ShipCountry) VALUES ('LILAS', 5, '2024/08/09', 'USA');
UPDATE Orders SET employeeid = 4 WHERE OrderID = 11087;
データウェアハウス(本記事ではSnowflake)にアクセスしてレプリケーション先のテーブルを確認します。データソース側で更新されたレコードの履歴がレコードとして作成されていることが確認できます。
レプリケーション(Upsert update)の作成手順は以上となります。
まとめ
本記事では、レプリケーションの種類、および、設定方法についてご紹介しました。CData Virtualityはフルマネージドクラウド(SaaS)版、および、インストール版で無償トライアルを提供しています。無償トライアルを始められたい方や設定を進める中でご不明な点が出てきた際には弊社
テクニカルサポートまでお問い合わせください。



