続いて「Incremental(増分)」モードの場合も確認してみましょう。「マテリアライゼーションの作成」章の手順で、別なテーブル(本例では、Microsoft SQL Server Northwindデータベース内のOrdersテーブルを利用)でマテリアライゼーションを作成します。
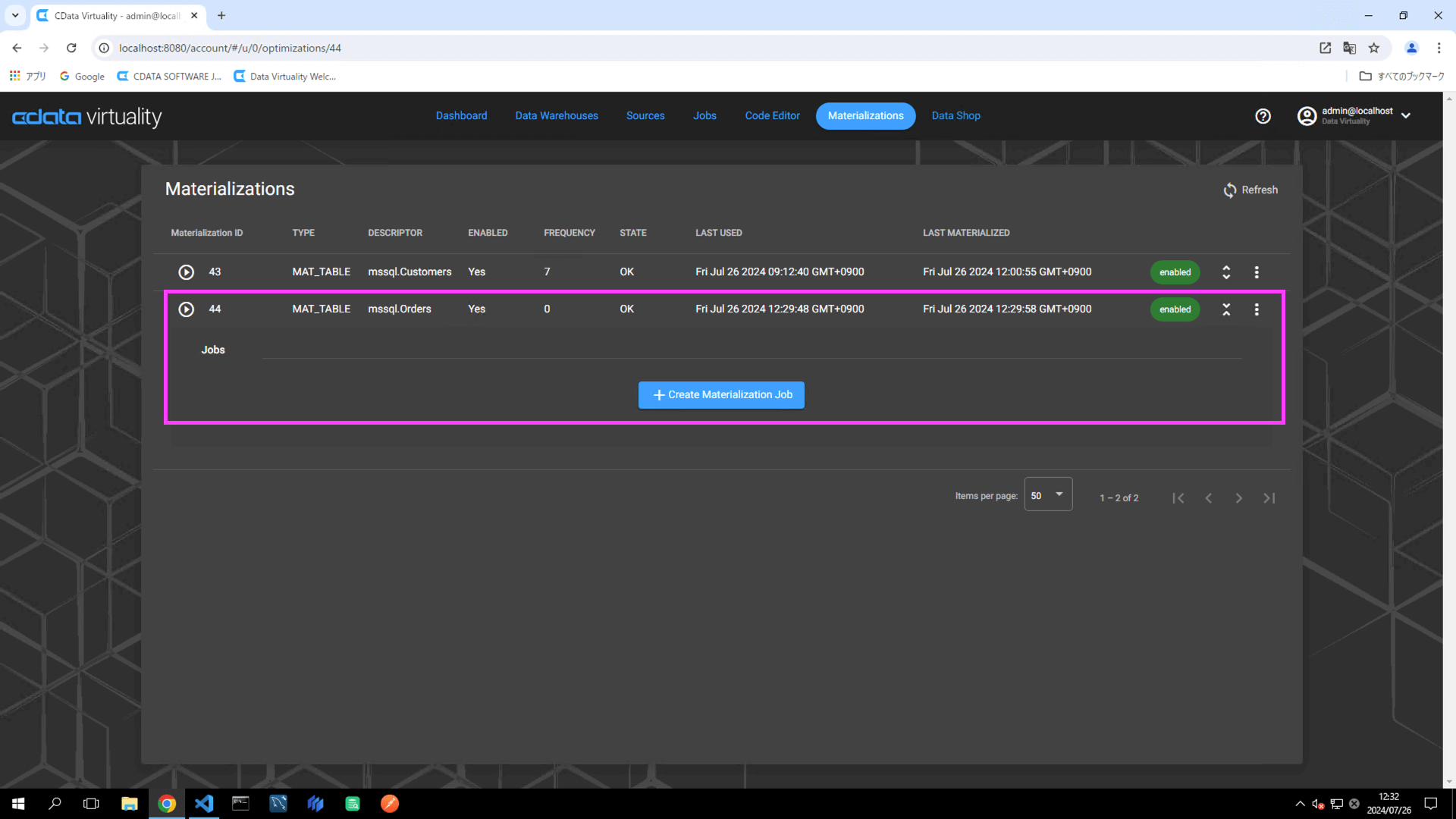
Analytical Storage内にマテリアライズドテーブル用のテーブルが作成されていることを確認します。
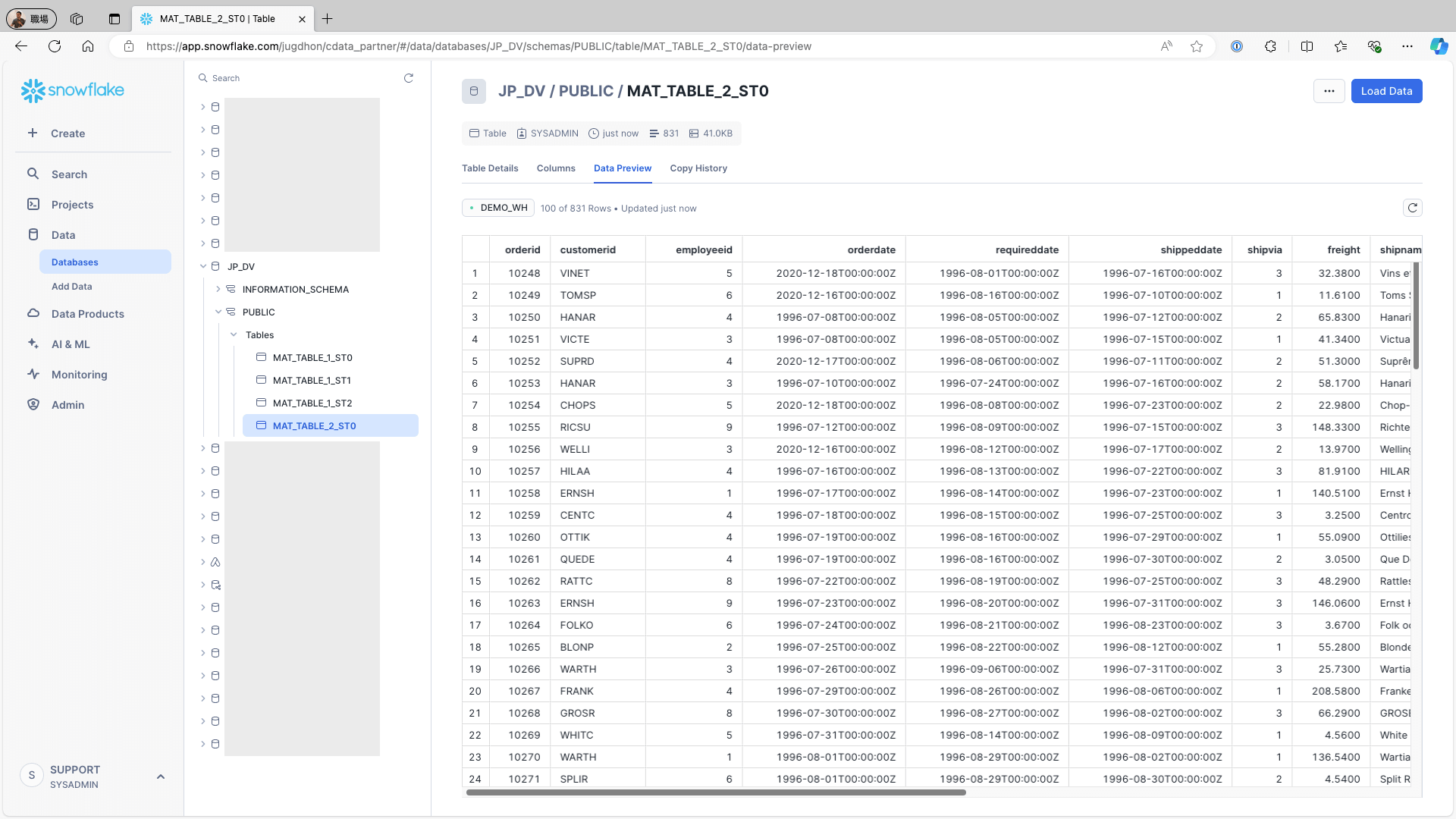
作成したMaterializationからジョブを作成します。タイプ(Complete/Incremental)から「Incremental」を選択、「Use Identity field...」のチェックをONにして、Row check fieldには、増分を確認するフィールド(本例では、OrderDate)を設定、Identity fieldには、一意となるフィールド(本例では、OrderID)を指定して、Schedules内の「+Manage Schedules」ボタンをクリックします。

Schedulesに追加されていることを確認して「+Create Job」ボタンをクリックします。
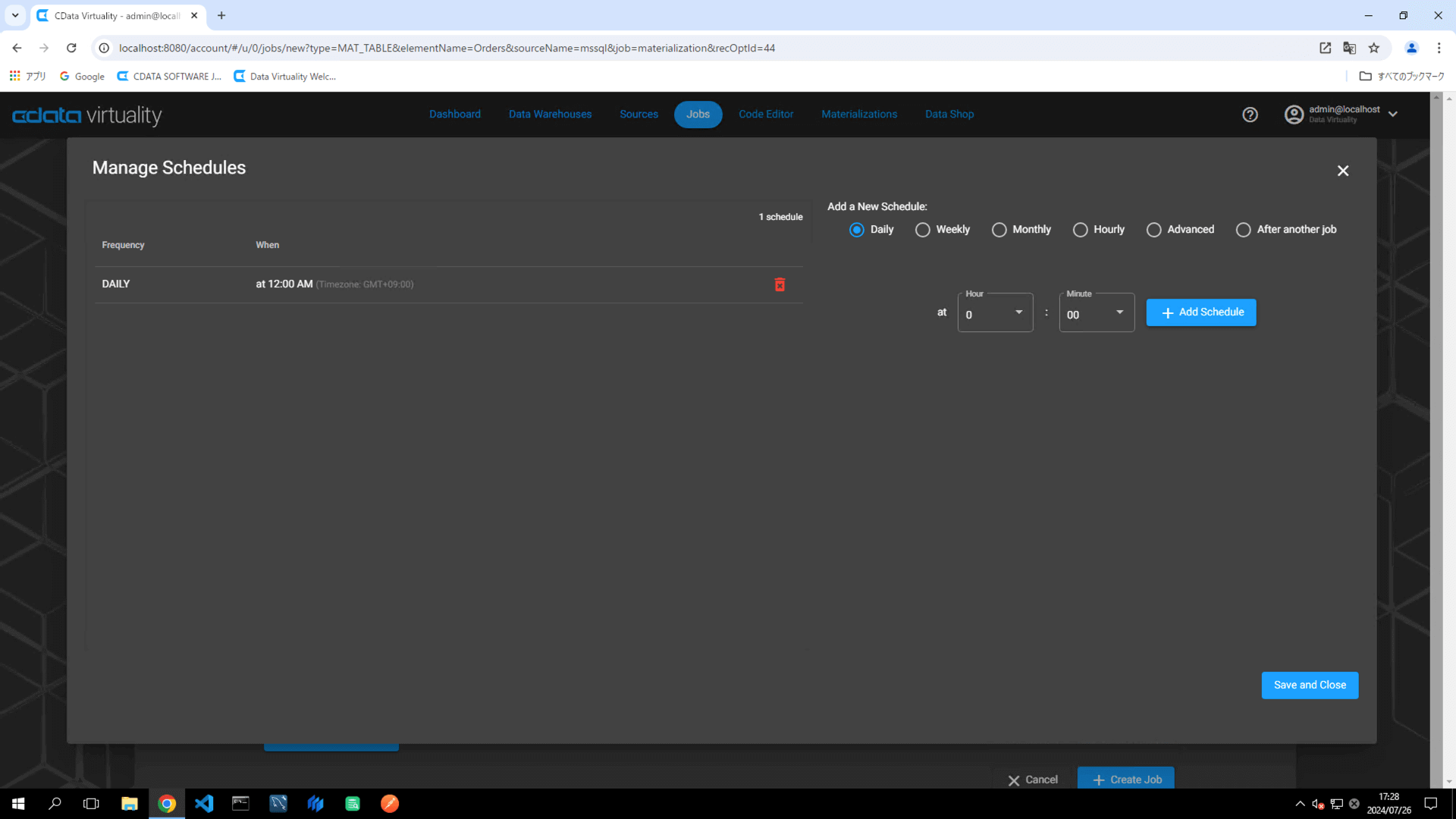
Dashboard画面が開き、追加したJobが表示されていることを確認します。
ここで「Incremental(増分)」での反映を確認するためにデータソース側のテーブル(本例ではMicrosoft SQL ServerのOrdersテーブル)に1レコードを追加してみます。
INSERT INTO Orders (CustomerID, EmployeeID, OrderDate, RequiredDate, ShippedDate, ShipVia, Freight, ShipName, ShipAddress, ShipCity, ShipRegion, ShipPostalCode, ShipCountry) VALUES ('RATTC', 1, '2024/07/26', '', '', 2, 0, '', '', '', '', '', 'USA');
CData Virtuality Web Interfaceに戻り、Jobs画面を開き、作成したジョブを「Run Job Now」アイコンをクリックして手動で実行してみます。

ジョブの実行が成功したことを確認してください。必要に応じて画面をリフレッシュしてください。

materialization画面から同ジョブのMaterializationがEnable(有効)になっていることを確認します。

Code EditorからMaterializationしたデータソースのテーブル(本例では、Microsoft SQL Server内のOrderesテーブル)を選択してGenerate StatementからSQLを生成して以下のように増分を確認するフィールド(本例では、OrderDate)で降順に並び替えた結果を確認します。
SELECT "OrderID", "CustomerID", "EmployeeID", "OrderDate", "RequiredDate", "ShippedDate", "ShipVia", "Freight", "ShipName", "ShipAddress", "ShipCity", "ShipRegion", "ShipPostalCode", "ShipCountry" FROM "mssql.Orders" ORDER BY "OrderDate" DESC;;

データソース側(本例ではMicrosoft SQL Server)に追加したレコードも取得できていることを確認できます。
Analytical Storage内のマテリアライズドテーブルの内容も確認してみましょう。データソース側(本例ではMicrosoft SQL Server)に追加したレコードも取得できていることを確認できます。

まとめ
本記事では、マテリアライゼーションの種類、および、設定方法についてご紹介しました。CData Virtualityはフルマネージドクラウド(SaaS)版、および、インストール版で無償トライアルを提供しています。無償トライアルを始められたい方や設定を進める中でご不明な点が出てきた際には弊社
テクニカルサポートまでお問い合わせください。



