
こんにちは。CData Software Japanリードエンジニアの杉本です。
今回はCDataSync 2021で新しく追加された機能の一つである、CSV/TSVファイルの新しい連携方式・ロードフォルダー機能を紹介したいと思います。
www.cdata.com
今までのCSV・TSVファイル連携
今回の機能を紹介する前に、CDataSyncの今までのCSV・TSVファイルをデータソースとして扱う場合の方法について確認しておきましょう。
対象はデータソースから追加できる「CSV」のコネクションになります。

例えば、以下のようなフォルダに入っているCSVファイルを連携したいとしましょう。
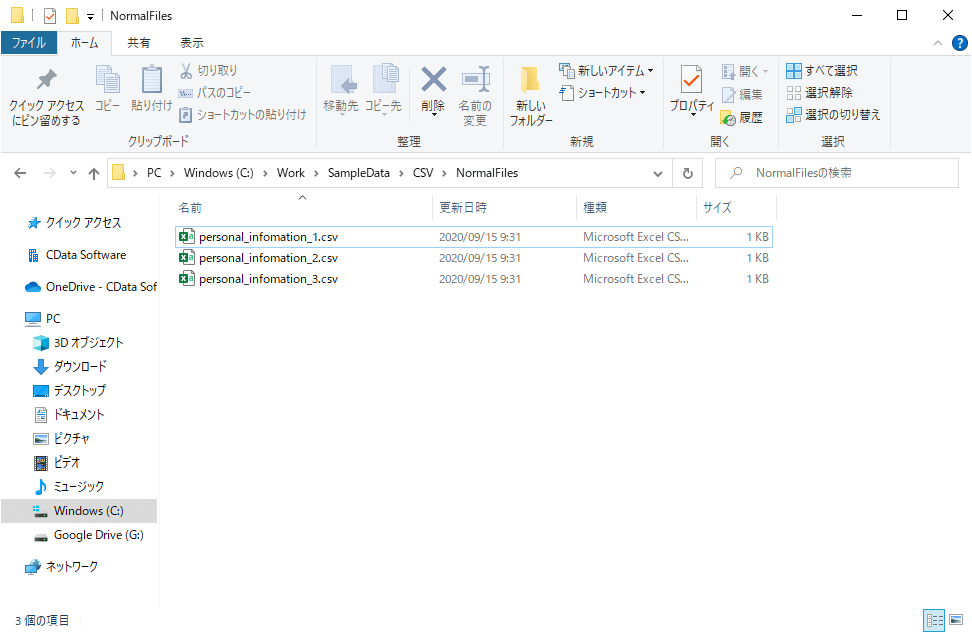
コネクション情報としては、対象のフォルダを指定して、連携ジョブを作成するのですが
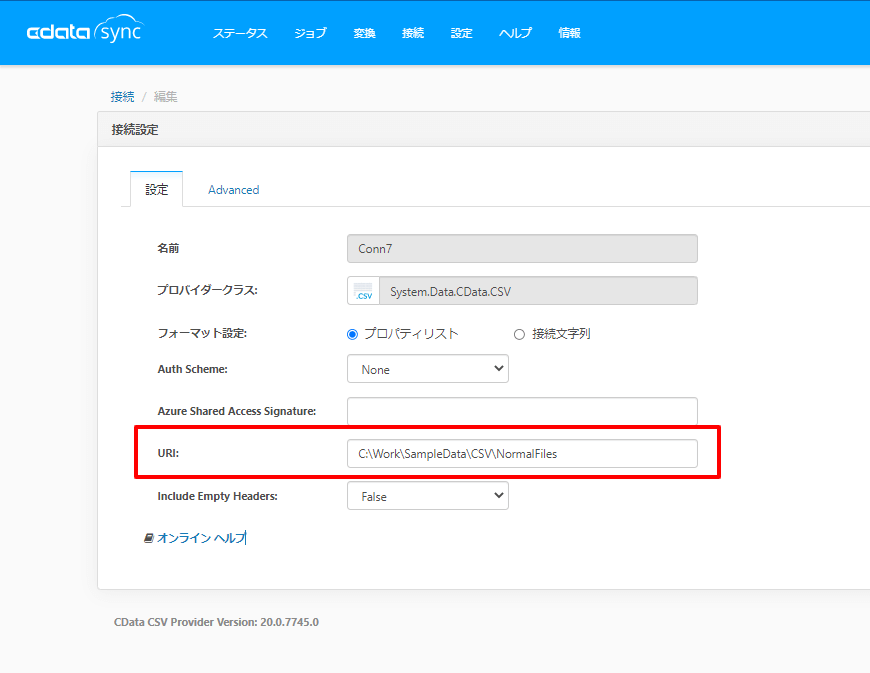
たとえ同じフォーマットのCSVファイルであったとしても、ファイル一つ一つをジョブの中で定義する必要があり、複数ファイルを一気に同じテーブルに取り込みたい場合は手間が多いものとなっていました。
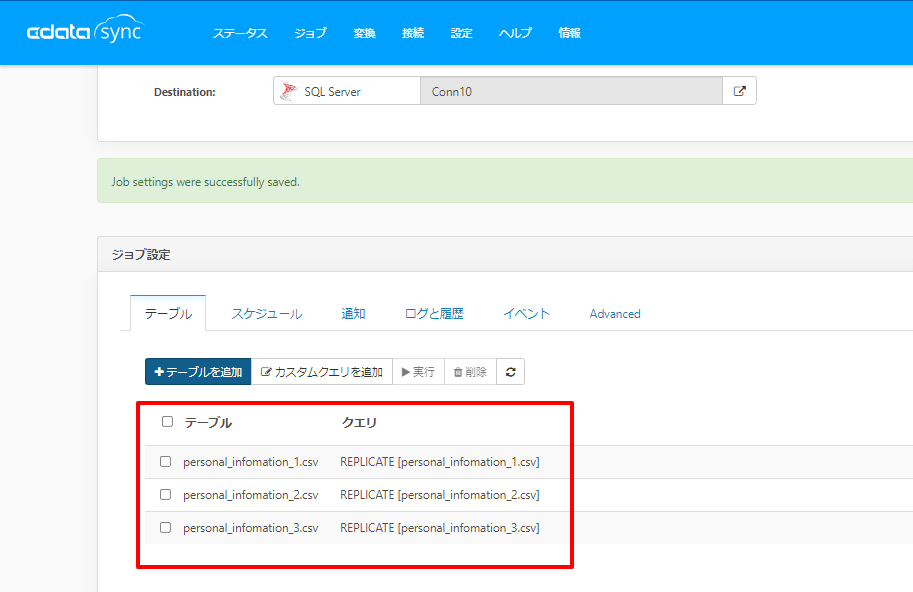
もちろん、単一のCSVファイルが常に更新される場合は特に問題が無いのですが、例えばトランザクションのような形で日付が入ったCSVファイルがどんどん生成されるようなシチュエーションではあまり有効な手段がありませんでした。
新しいCSV/TSVフォルダーデータロード機能の場合
これが新しい「CSV/TSVフォルダーデータロード機能」を利用すると、対象のフォルダを常にジョブがウォッチし、新しいファイルが追加されればそれが常に同期の対象として識別されます。テーブルの追加を一つ一つ行う必要がありません。
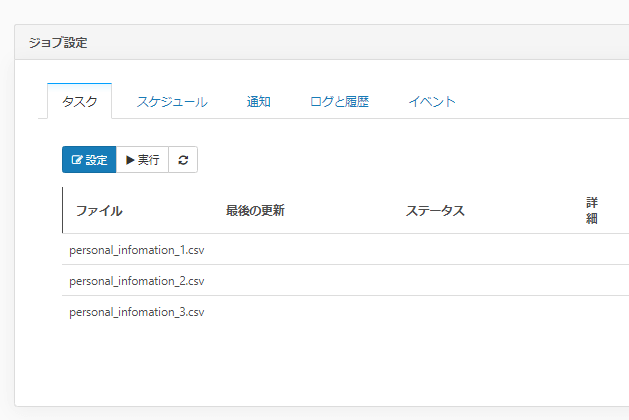
また、同期先のテーブルも一つに統合されてレプリケーションされるので、ジョブ毎にテーブルマッピングをし直す必要がありません。
設定方法
設定方法はジョブ作成時に行います。
ソースをCSV コネクターとして選択すると、以下のように「すべてのファイルを単一のテーブルに読み込みます」というチェックボックスが表示されます。
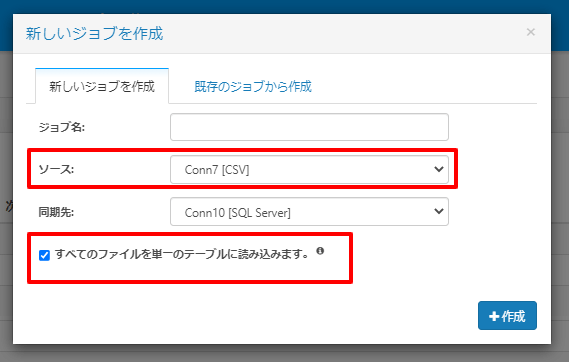
ジョブを作成したら「設定」をクリックし
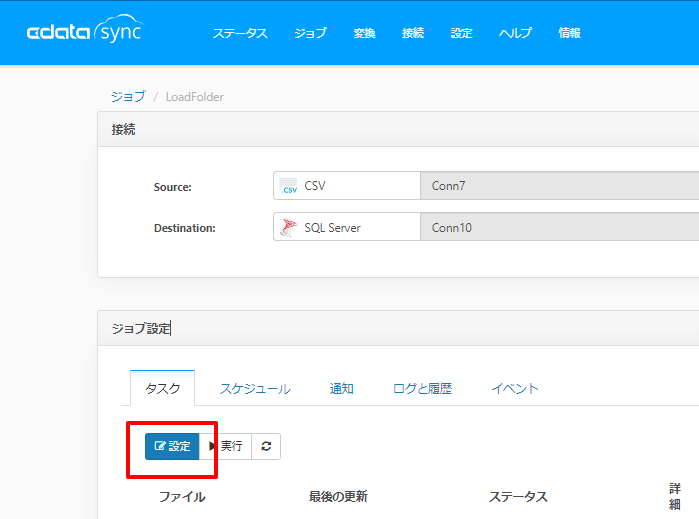
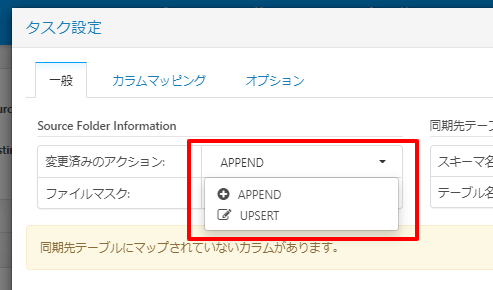
アクションやテーブル名を選択します。アクションでの挙動の違いについては後述します。
テーブル名がデフォルトではジョブ名になってしまうので、変更すると良いでしょう。
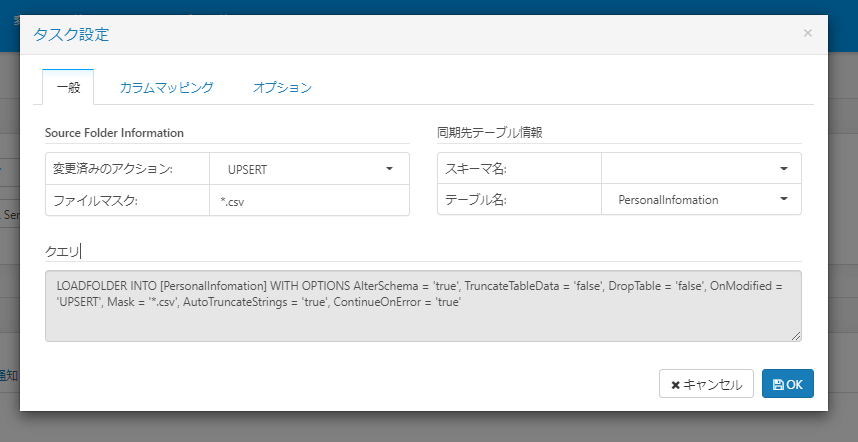
あとはジョブを実行するだけです。
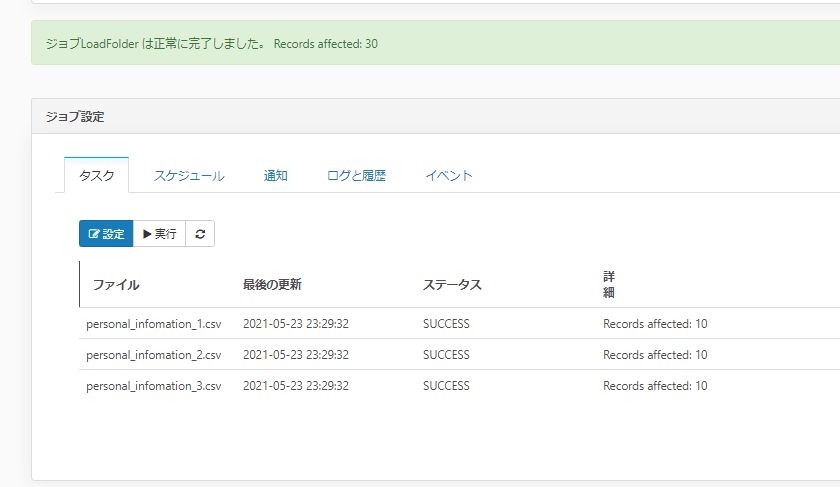
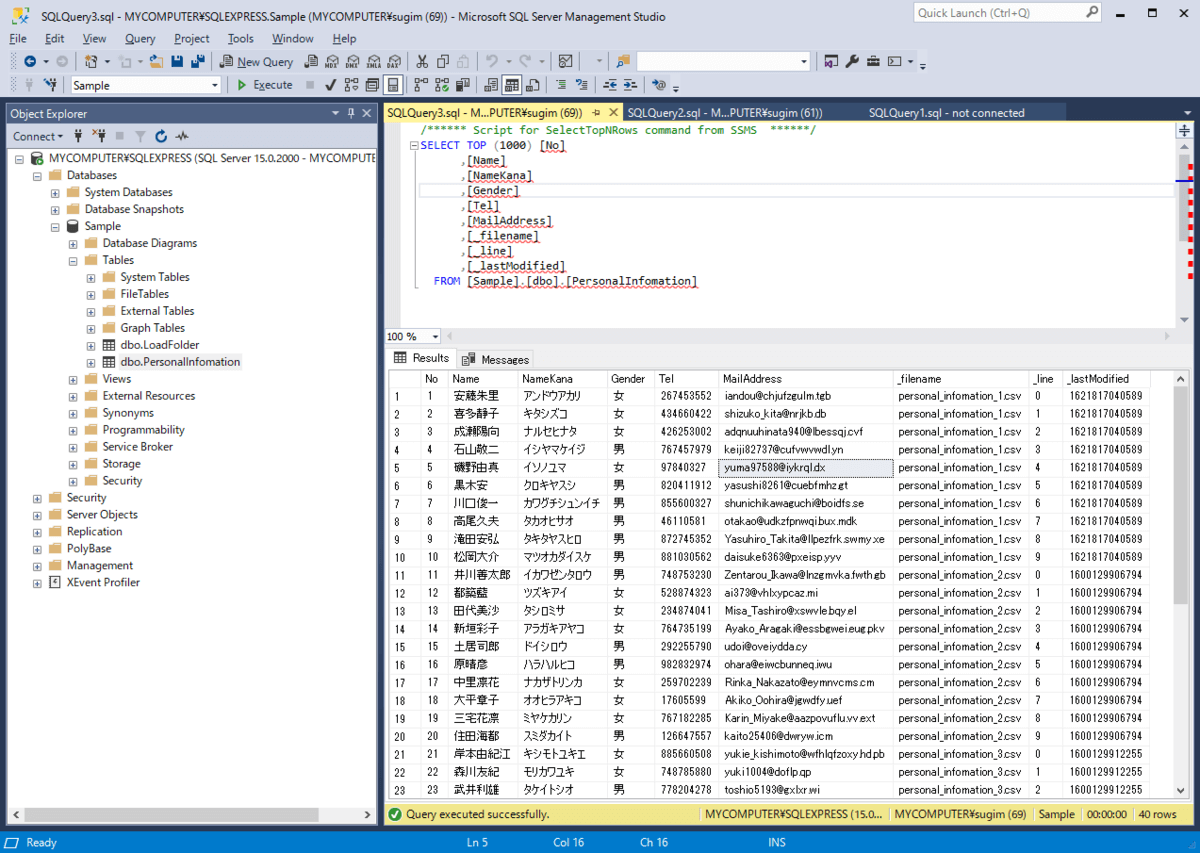
今回はSQL Serverにレプリケーションを行ったので、SQL Server Management Studioから結果を見てみます。
以下のようにテーブルが自動生成されて、データが登録されていることが確認できました。
ちなみに「filename」「line」「_lastModified」というフィールドが自動的に追加されています。これを使って、追加データの対応などが行われますのでレプリケーションされたデータをいじる際には注意しましょう。
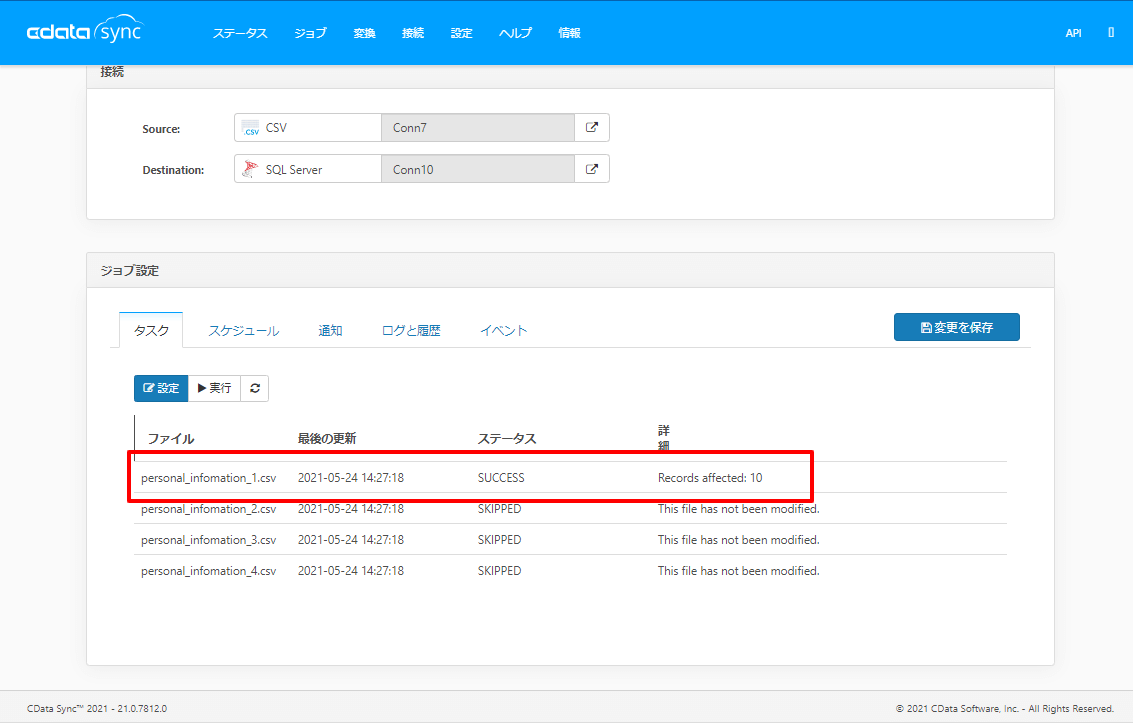
フォルダにファイルが追加された時の挙動
今回の機能はCDataSyncがフォルダをウォッチしているので、ジョブ実行時にファイルが増えていれば、それを自動的に識別して、レプリケーションの対象に加えます。
わかりやすいようにGIFアニメを撮ってみました。

フォルダに追加されたファイルが自動的にジョブに追加されているのがわかりますね。
ここが今回の機能で一番便利なポイントです。
CSVファイルの中が変更されたらどうなるの?
CSVファイルの中身の変更については「変更済みのアクション」で指定された挙動によって変わります。
例えば、同期済みのCSVファイルである以下のようなデータを

以下のように変更して、再度同期を行います。

実行結果はどちらも対象のファイルだけが再度処理されます。
もともとのデータの状態は以下のようになっていますが
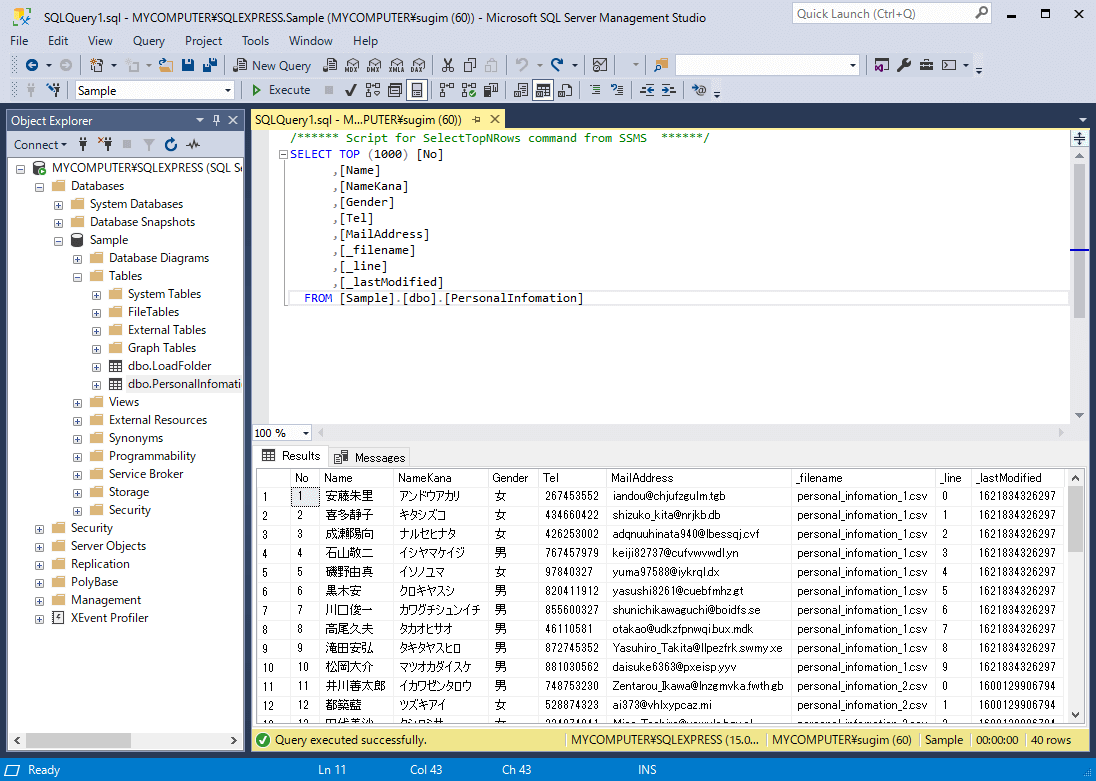
「Append」の場合は以下のように更新されたレコードが新しく追加され
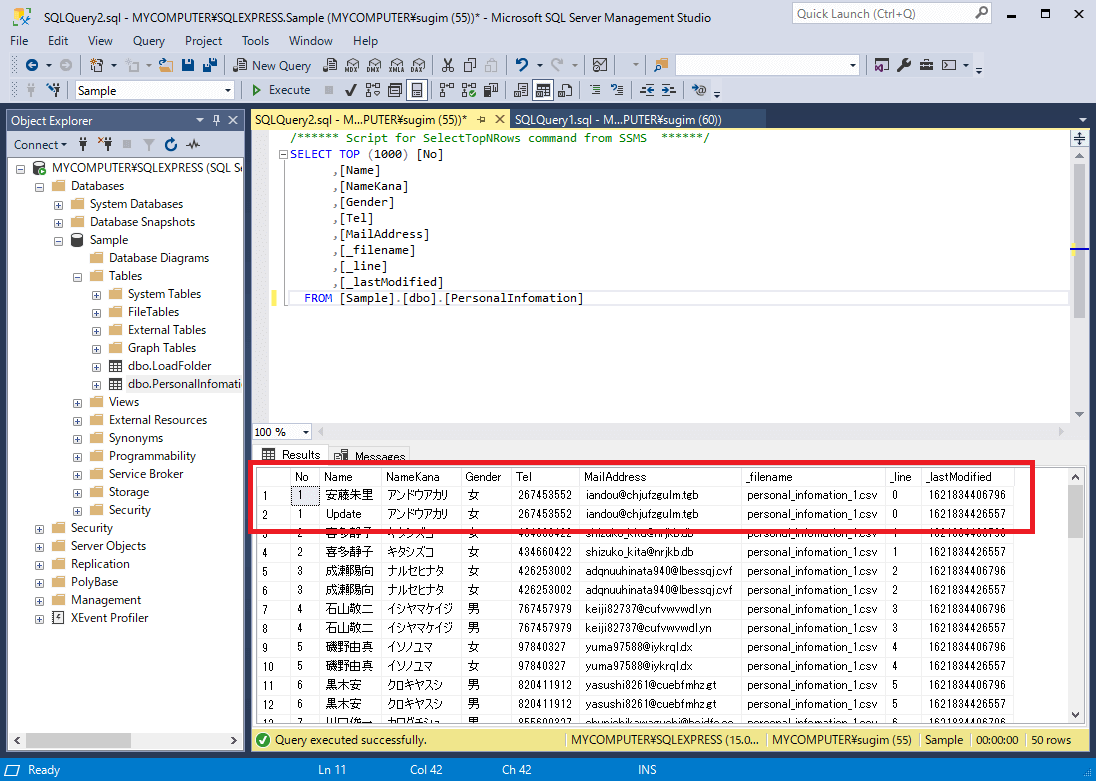
「Upsert」の場合はレコードそのものが更新されます。
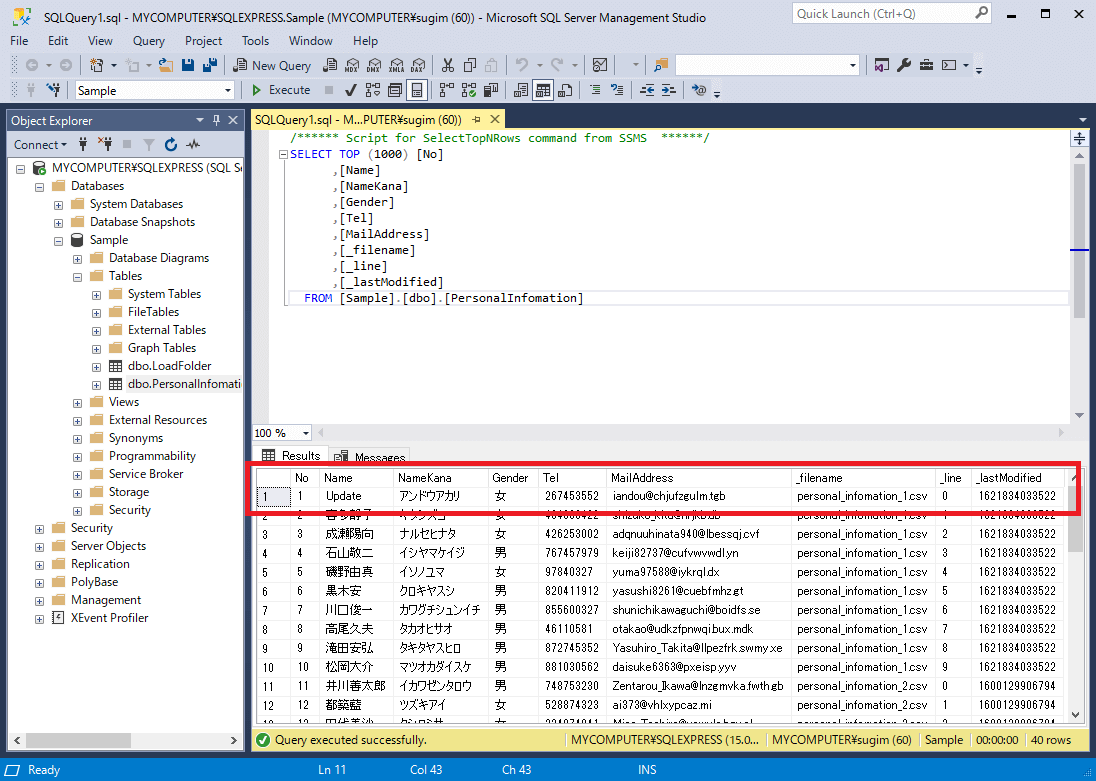
用途に応じて使い分けてみてください。
注意点
今回の機能は対象のCSVファイルがすべて同じフォーマットということを前提に機能します。
フォーマットが異なるファイルが存在するとレプリケーション結果が異なったり、うまくレプリケーションできなかったりするので気をつけてください。
おわりに
ちょっと特殊な機能なので、試している時にわからない部分が出てくるかもしれません。
その場合は、無償のテクニカルサポート窓口があるので、お気軽にお問い合わせください。
https://www.cdata.com/jp/support/submit.aspx
関連コンテンツ



