
こんにちは。CData Software Japan リードエンジニアの杉本です。
今日は CData Sync が新しくサポートしたデータ転送先、「Databricks」との連携を紹介したいと思います!
Databricks とは?
Databricks は オープンソースの ビッグデータ処理基盤である Apache Spark をクラウドベースで提供しているサービスです。
databricks.com
通常、Apache Sparkやその周辺のエコシステムのツール・フレームワークを自社で導入しようとすると、インフラ周りの構成で煩わしさが多く発生しますが、Databricksを使うことでそういった煩わしさから脱却し、メインとなる分析作業に注力することができるようになります。
また、Azure・AWS・GCPと任意のクラウドサービス上に展開できる点も魅力的ですね。

CData Sync Databricks Destination で何ができるの?
CData Sync クラウドサービスやRDB・NoSQLなどの様々なサービスからDWHやデータベースへノーコードでデータをレプリケーションすることができるツールです。
https://www.cdata.com/jp/
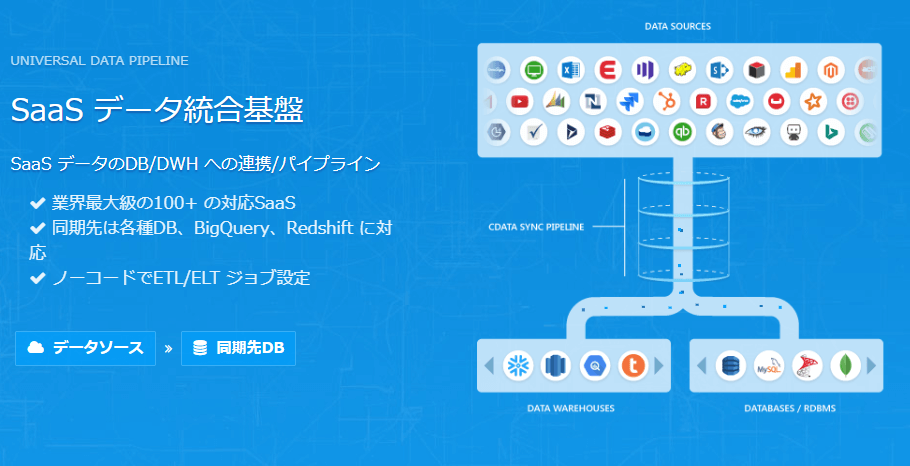
今回 CData Sync ではデータの転送先として、新しく Databricks がサポートされました。
これにより CData Sync でサポートしている250種類を超える kintone や Salesforce、Marketo といったクラウドサービスやRDB・NoSQLなどのデータソースから、Databricks へ手軽にデータのレプリケーションを実現し、Databricks 上でのデータ分析・活用に繋げることができるようになりました。
実体としては、以下のように Databricks 上のテーブルとして自動生成されて
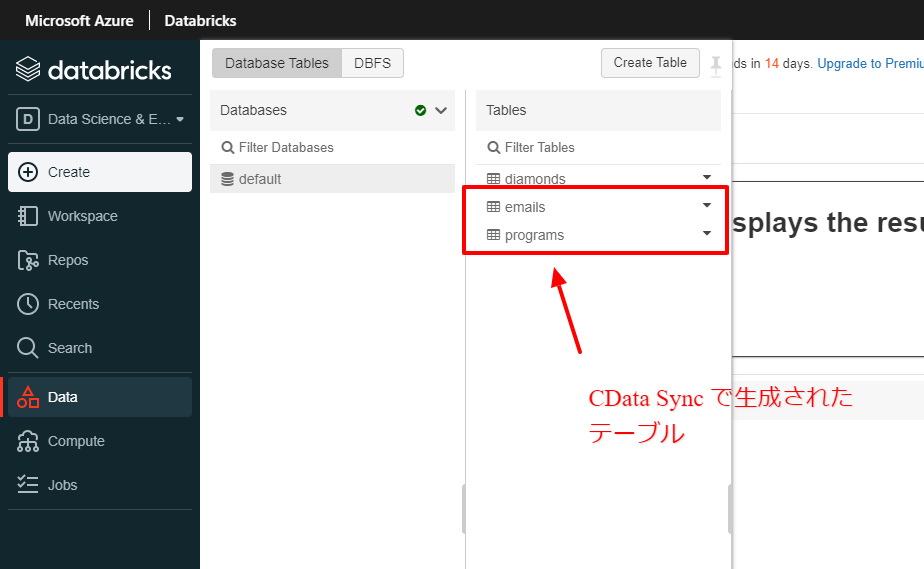
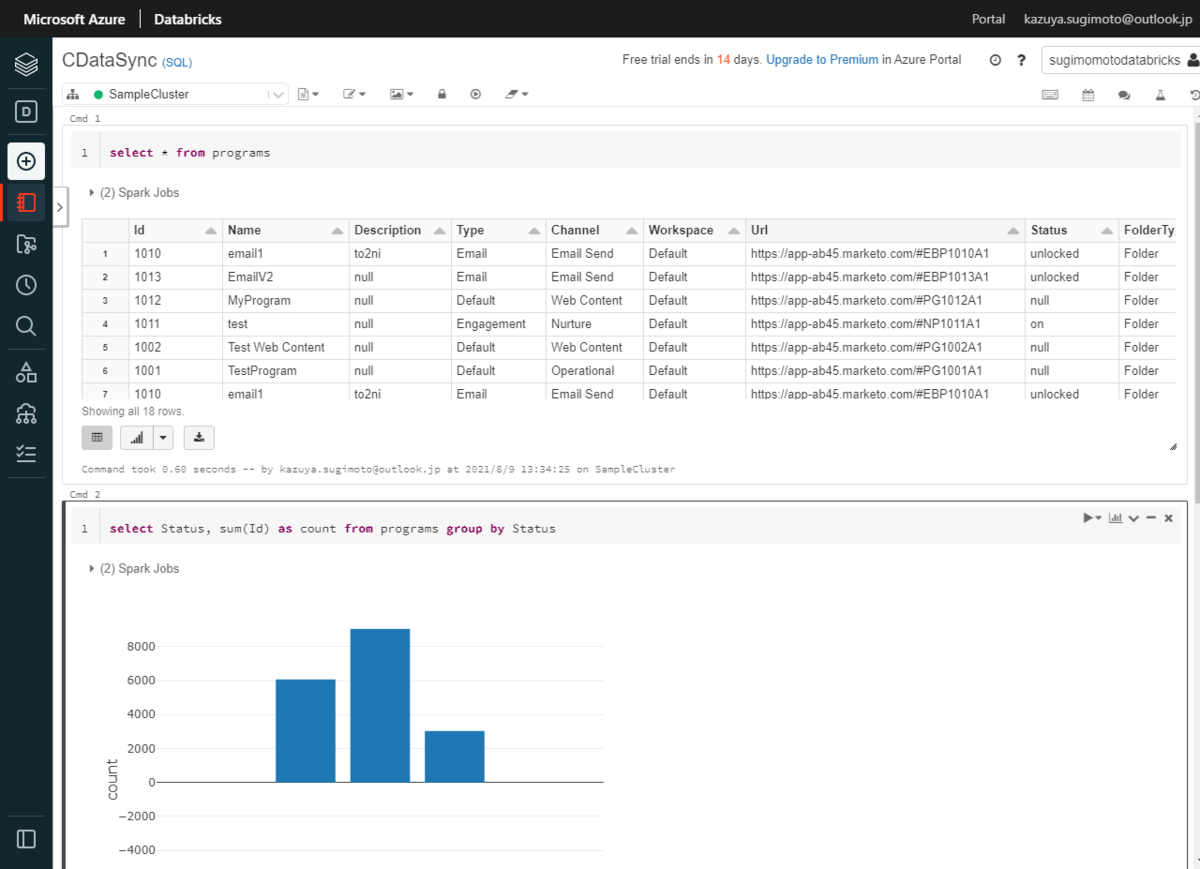
あとは通常通り、Databricks 上のNotebook で登録されたテーブルに対してクエリを実行し、データを集計・加工・分析できます。
CData Sync がサポートしているデータソースの一覧は以下のURLからどうぞ。
www.cdata.com
(以下、一部抜粋)

使い方
それでは実際にCData Sync を使って、Databricks へのデータレプリケーションを試してみましょう。
CData Sync はサーバー製品になります。以下のURLからトライアル版をダウンロードして、環境をセットアップしておきましょう。
www.cdata.com
以下の記事でセットアップの詳しい手順も解説しています。
www.cdatablog.jp
また AWS ではAMIベースで利用できるプランも提供しています。
aws.amazon.com
今回は私のローカルデスクトップマシン、Windows にインストールした CData Sync からAzure環境に構築したDatabricks に接続してみたいと思います。
Databricks の環境を構築
CData Sync のセットアップが完了したら Databricks 側の環境も準備しましょう。
Azure Databricks についてはこちらのリンクからどうぞ。14日間のトライアルも提供されています。
azure.microsoft.com
以下のようにAzure Databricks 環境を構築したら、クラスターを構成します。
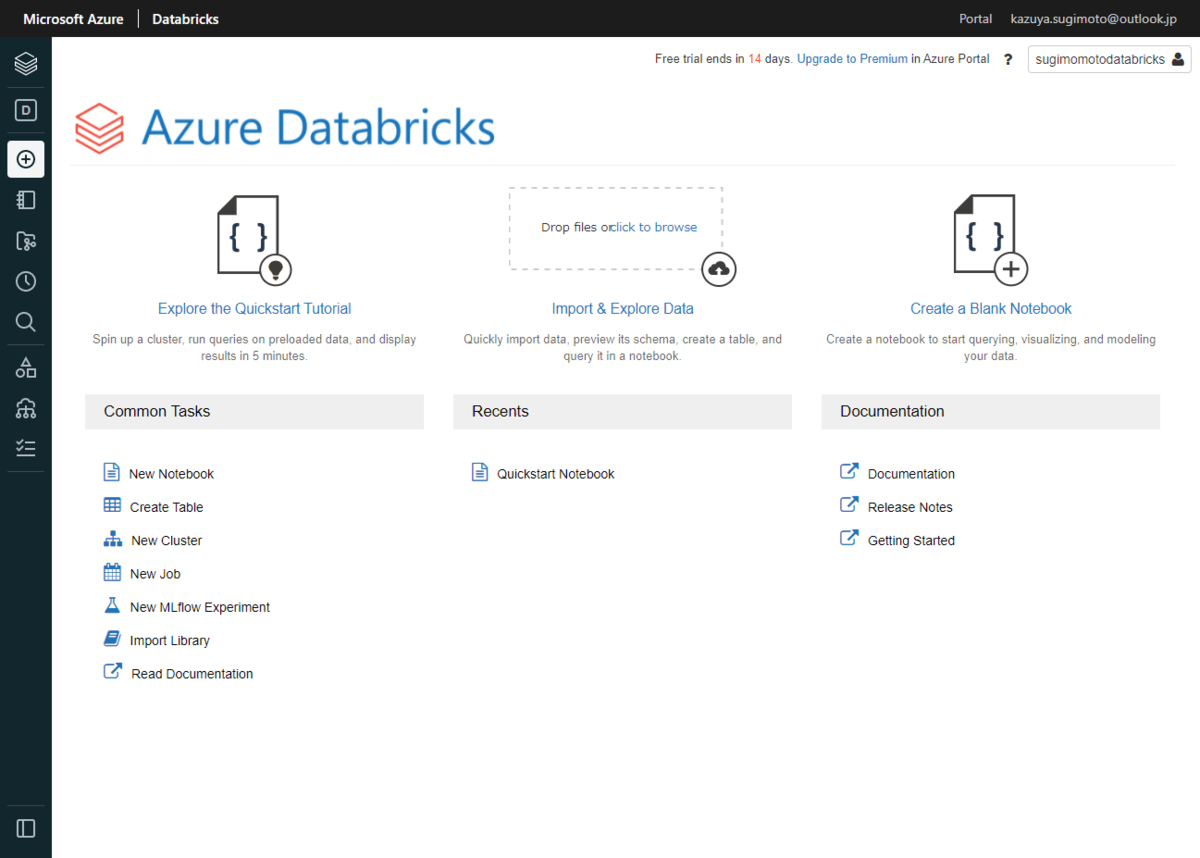
「New Cluster」から任意の名前のCluster を構成します。今回は「Databricks Runtime Version」でLTSの 7.3 を選んで構成しました。
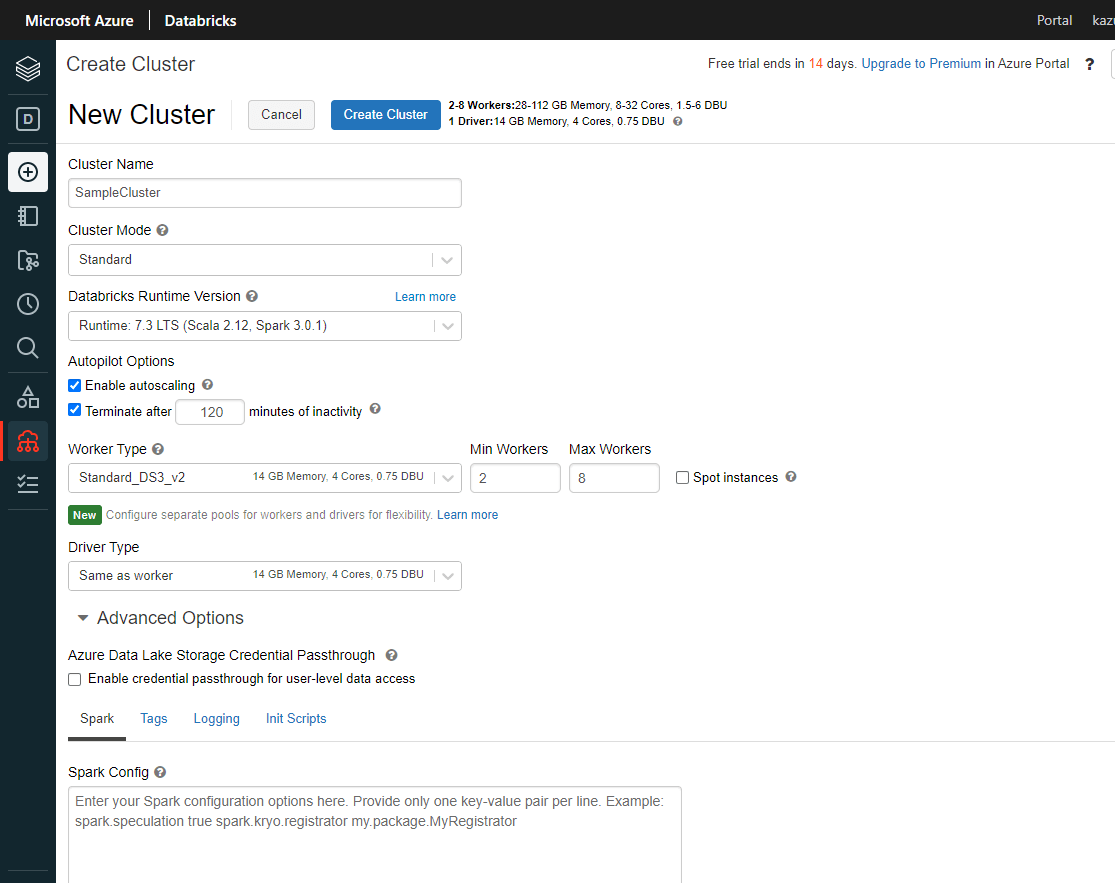
環境が構成できたら、「Advanced Options」の「JDBC/ODBC」を選択し、接続に必要となる「Server Hostname」と「HTTP Path」を控えておきましょう。
Token の生成
併せてDatabricks に接続する際に必要となるTokenを生成します。
画面右上のユーザー名から「User Settings」をクリックし
「Access Tokens」のタブから「Generate New Token」をクリックします。
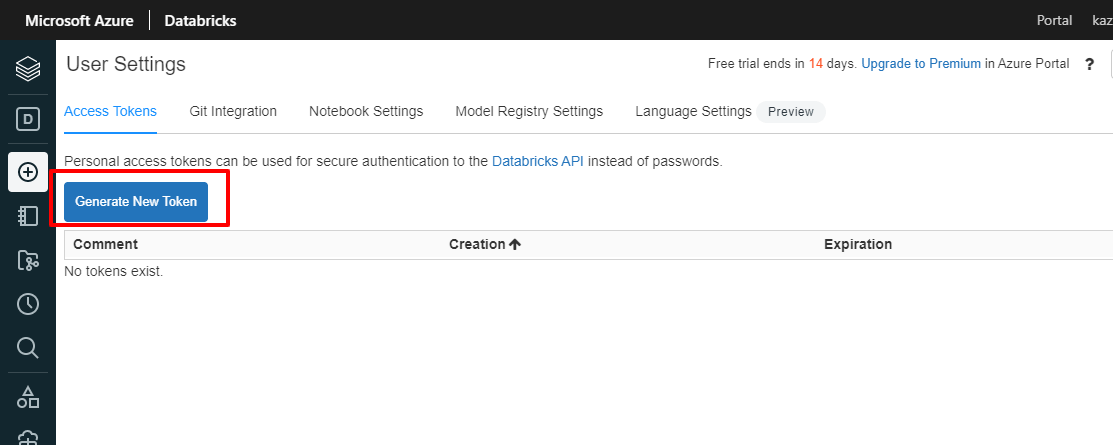
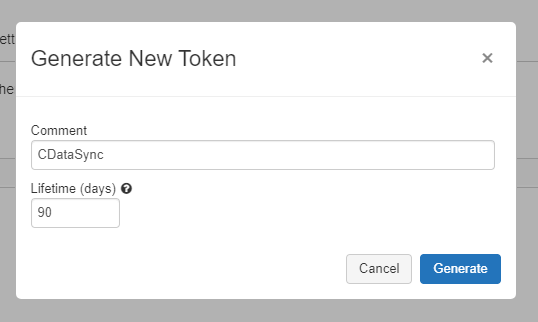
任意のコメントを付けてTokenを生成しましょう。
以下のように生成されたTokenを控えておきます。
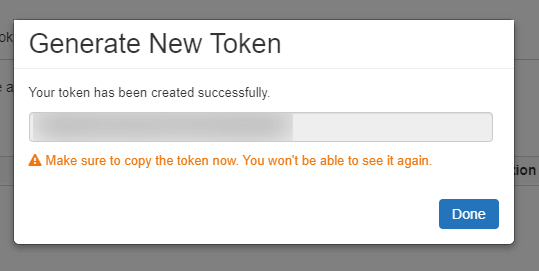
これで Databricks 側の準備は完了です。
CData Sync から Databricks に接続
続いて CData Sync からDatabricks に接続しましょう。
CData Sync の管理画面にログインし「接続」→「同期先」から、「Databricks」を選択します。

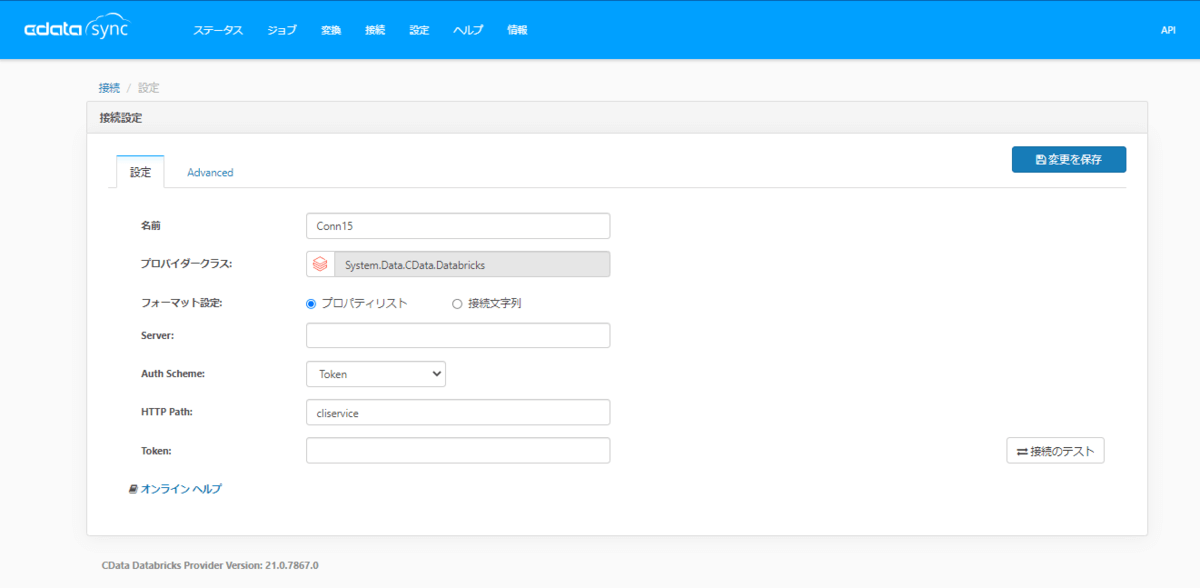
Databricks で構成したそれぞれの情報をもとに、以下のように接続情報を入力します。
| プロパティ名 |
値 |
備考 |
| Server |
例)adb-768087444450513.13.azuredatabricks.net |
クラスターのServer Hostname を指定します。 |
| Auth Scheme |
Token |
認証方法を指定します。 |
| HTTP Path |
例)sql/protocolv1/o/768087444450513/0809-023132-unsay358 |
クラスターのHTTP Pathを指定します。 |
| Token |
例)YOUR_TOKEN_123456789123456789 |
User Settings で生成した Access Tokenを指定します。 |
入力完了後、「接続のテスト」をクリックし、正常に接続が完了したら「変更を保存」をクリックしましょう。
データソースの接続を構成
併せて、データの取得元となるデータソースへの接続を構成します。
特にデータソースは何を選んでも構いません。

今回は Marketing Automation のクラウドサービスとして有名な Marketo を選択してみました。
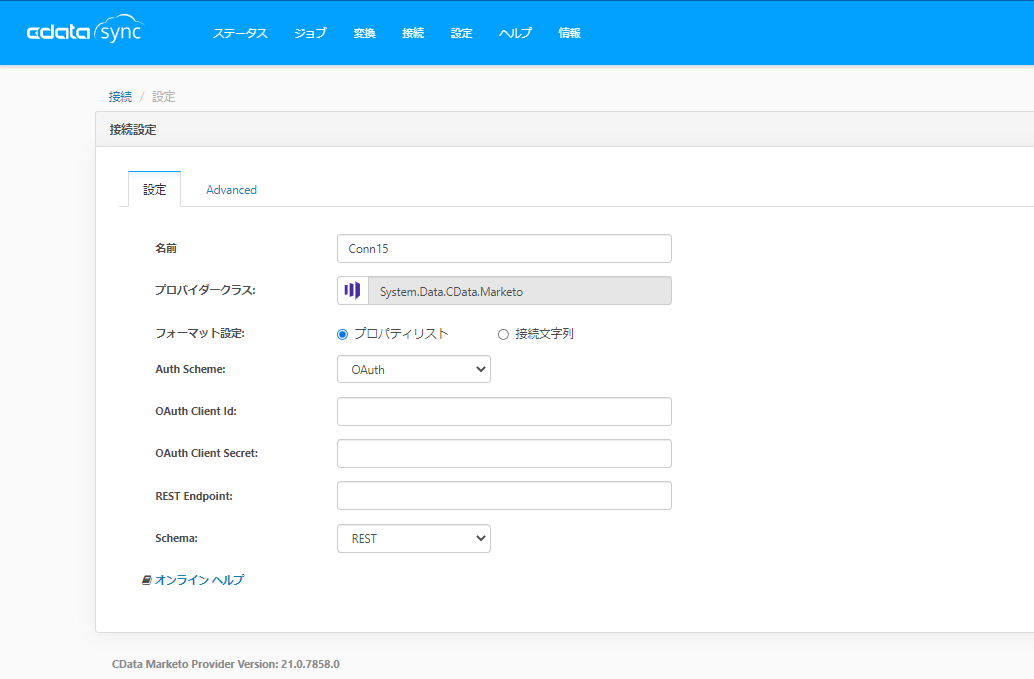
ジョブの作成
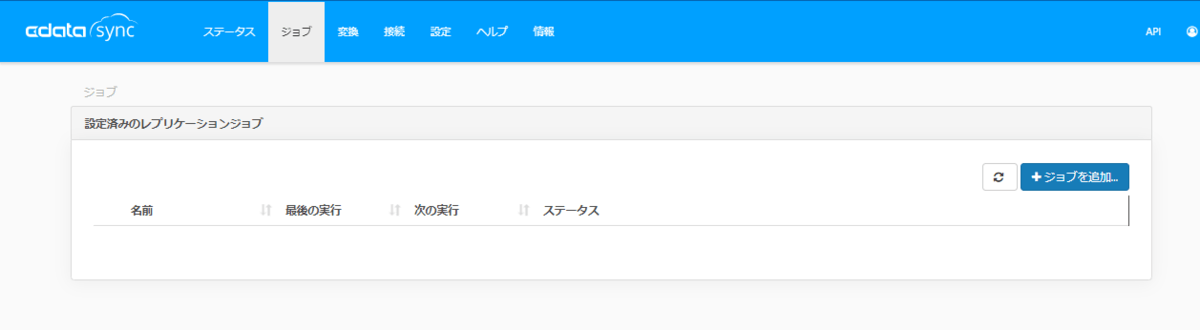
それでは実際にデータのレプリケーションを行います。
CData Sync はジョブという単位でデータのレプリケーションの設定を行います。「ジョブ」に移動して「ジョブを追加」をクリックします。
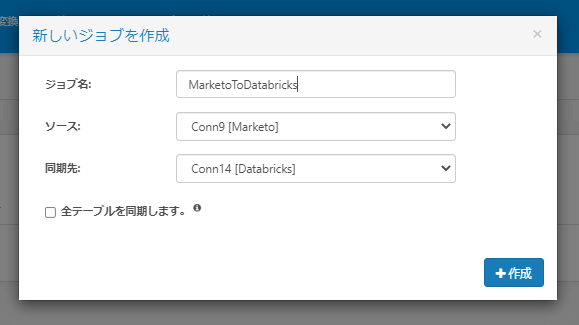
任意の「ジョブ名」と、先程構成したMarketo・Databricks の接続をそれぞれ「ソース」「同期先」で選択します。
ジョブを作成したら、「テーブルを追加」から、レプリケーション対象となるテーブルを指定します。
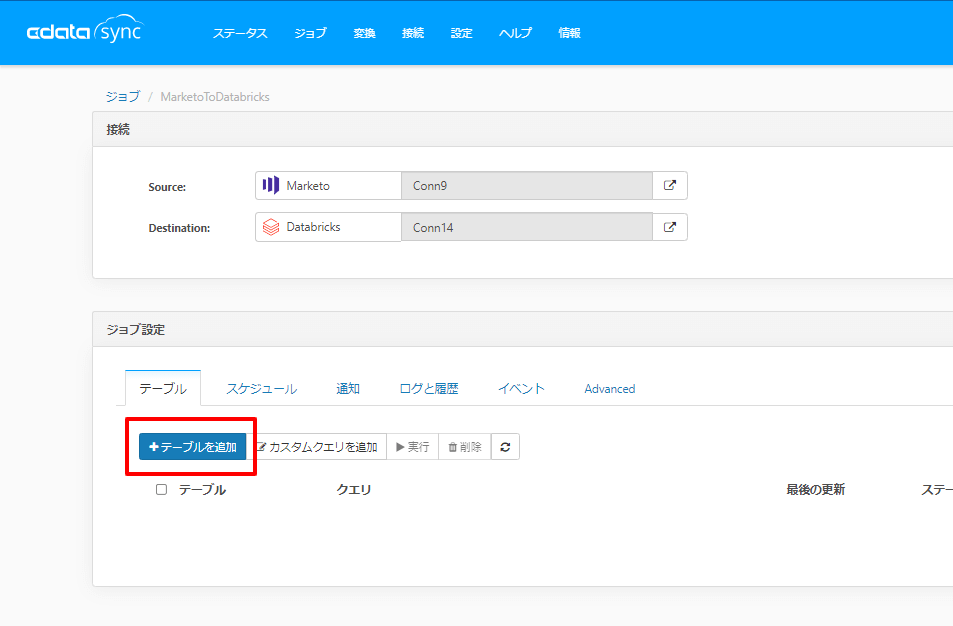
ここでデータソースから取得したいテーブルを指定します。
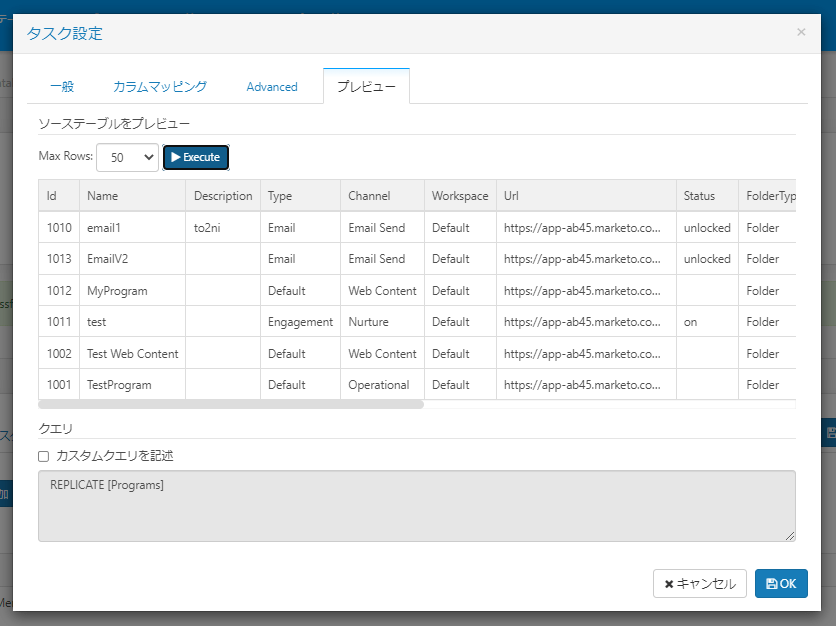
指定したテーブルを設定画面でプレビューすることもできるので、データが正常に取得できるか、どんなデータが取得できるのかをここで確認できます。
あとはジョブの実行時間、頻度をスケジュールから指定します。
レプリケーションの実行
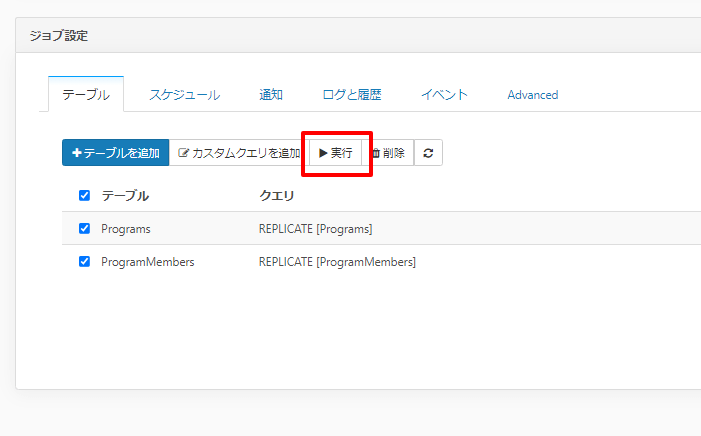
今回はテストとして手動で実行してみましょう。
レプリケーション対象のテーブルを選択して「実行」ボタンをクリックします。
一定時間が経過すると、以下のようにステータス項目にレプリケーション結果が表示されます。
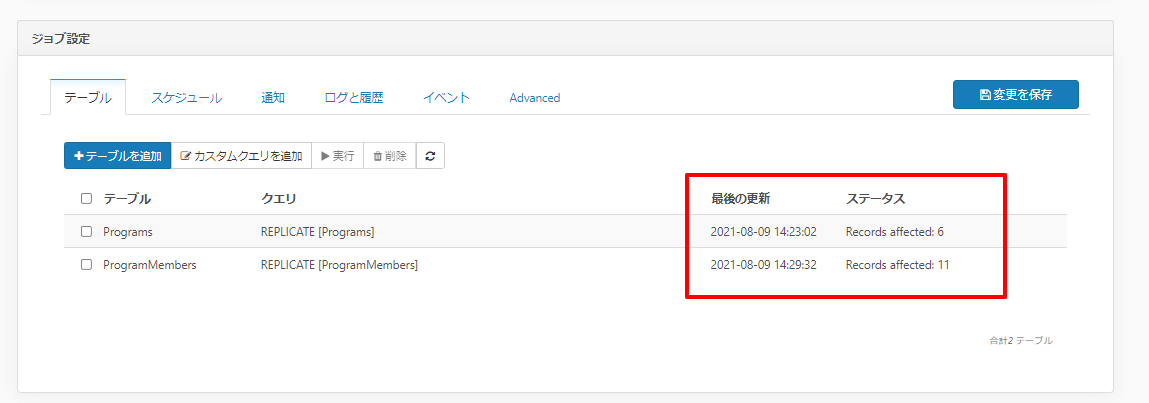
Databricks 側の画面に移動してみると、以下のようにテーブルが追加されていることが確認できました。
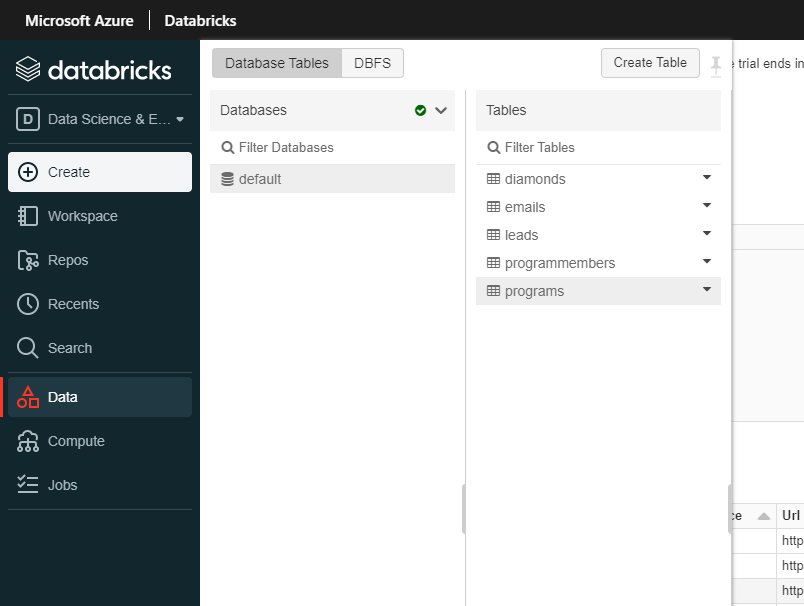
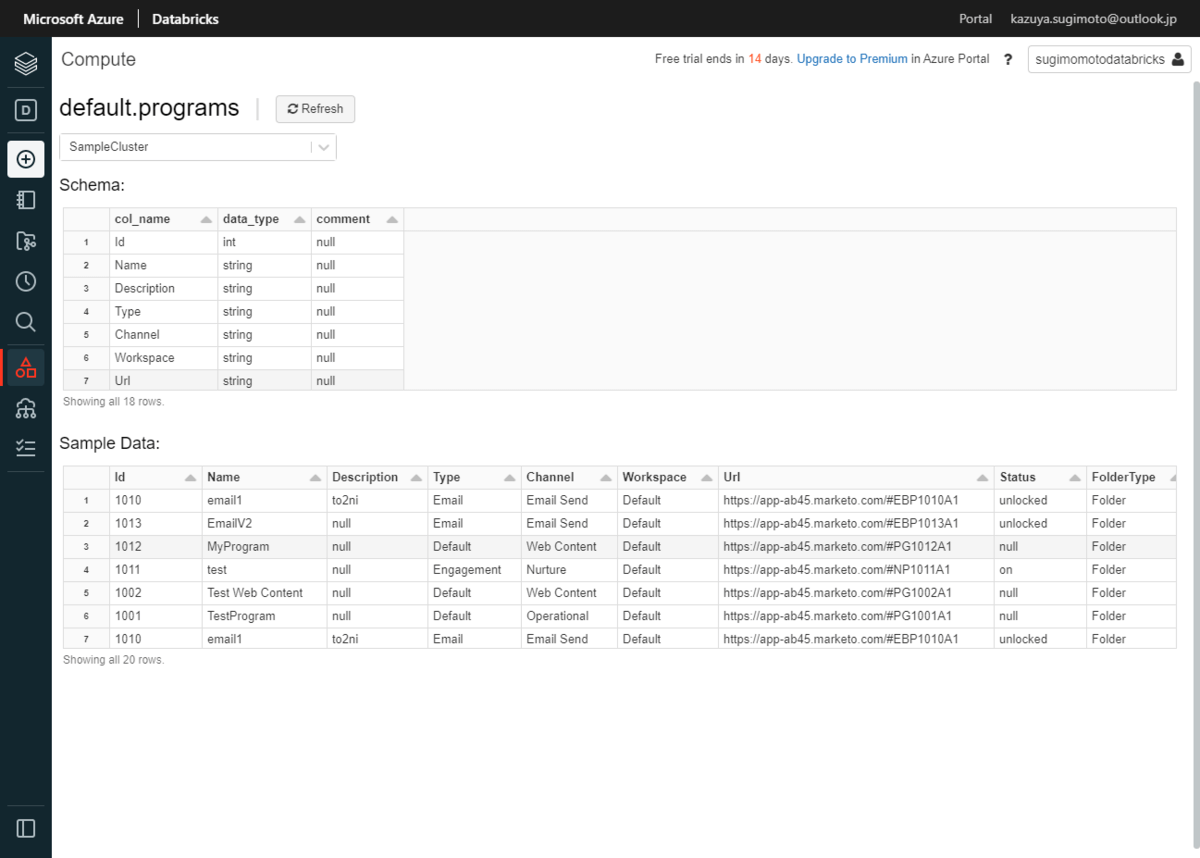
Schemaや実際のデータもプレビューして確認することができます。
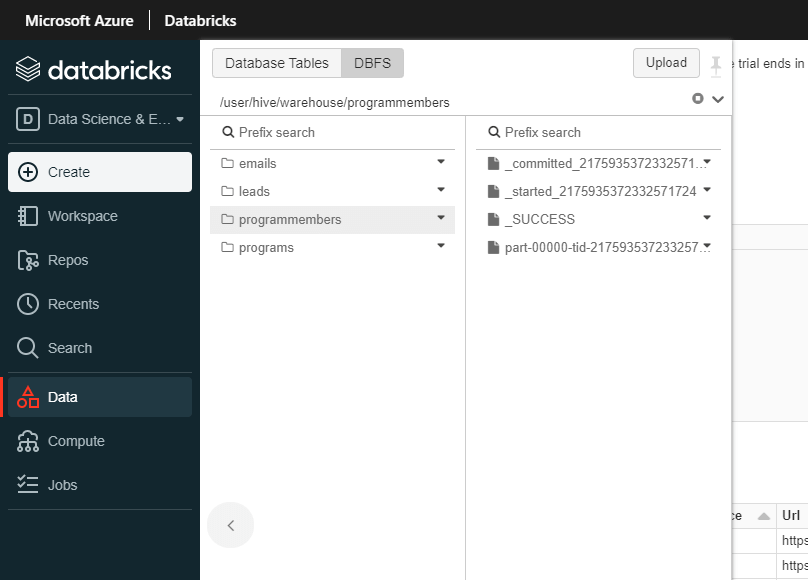
なお、Databricks 上のデータの実体はDBDSブラウザー「/user/hive/warehouse/テーブル名」から確認できます。
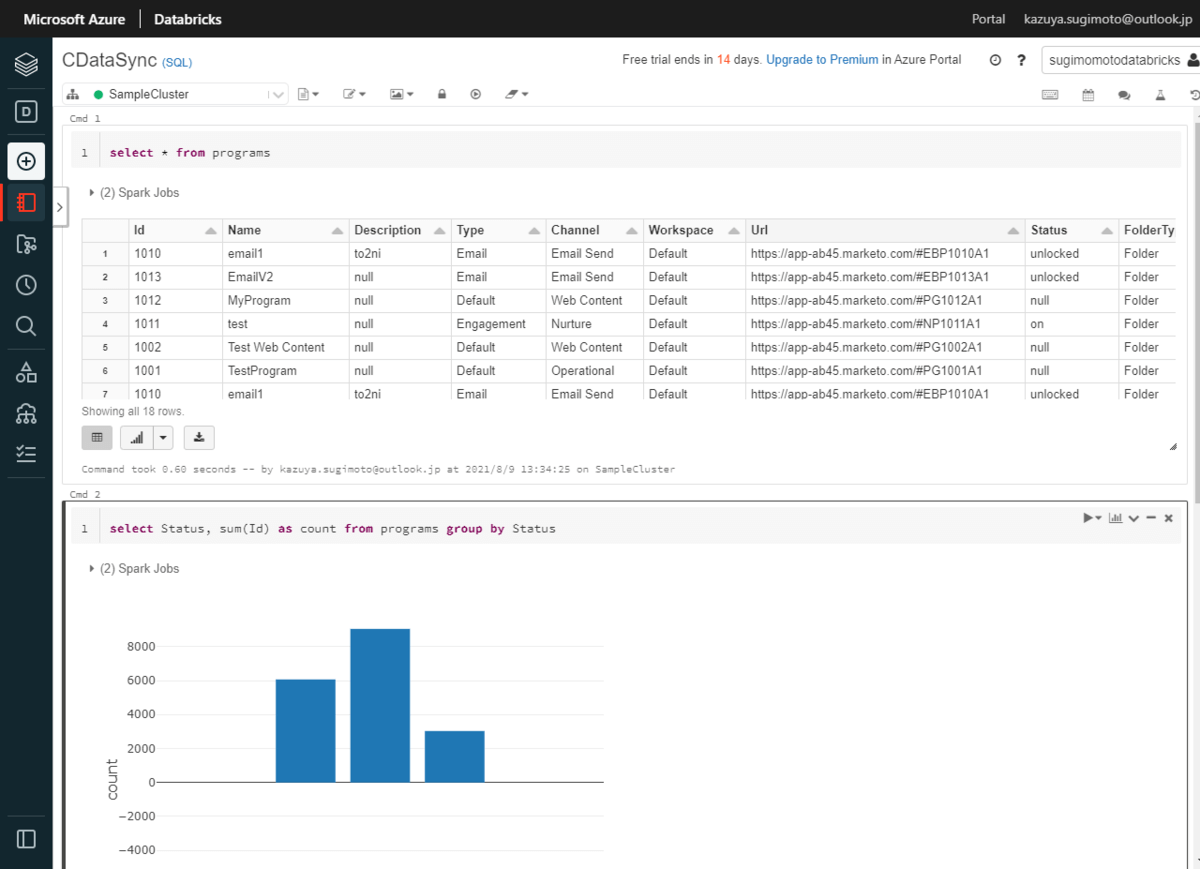
あとは、Databricks の Notebook でテーブルを自由にクエリできます。
おわりに
接続設定さえ正常に完了すれば、簡単にデータのレプリケーションが実施できますね。
今回は Azure で行いましたが、AWS でも GCP でも基本的な利用方法は変わりません。
もし気になる点、よくわからない点があれば、テクニカルサポートも提供しているので、お気軽に問い合わせしてみてください。
https://www.cdata.com/jp/support/submit.aspx
関連コンテンツ



